

深度学习模型部署简要介绍
source link: https://zhuanlan.zhihu.com/p/453313478
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

深度学习模型部署简要介绍
一、模型部署简介
近几年来,随着算力的不断提升和数据的不断增长,深度学习算法有了长足的发展。深度学习算法也越来越多的应用在各个领域中,比如图像处理在安防领域和自动驾驶领域的应用,再比如语音处理和自然语言处理,以及各种各样的推荐算法。如何让深度学习算法在不同的平台上跑的更快,这是深度学习模型部署所要研究的问题。目前主流的深度学习部署平台包含GPU、CPU、ARM。模型部署框架则有英伟达推出的TensorRT,谷歌的Tensorflow和用于ARM平台的tflite,开源的caffe,百度的飞浆,腾讯的NCNN。其中基于GPU和CUDA的TensorRT在服务器,高性能计算,自动驾驶等领域有广泛的应用。
来源:3D视觉工坊
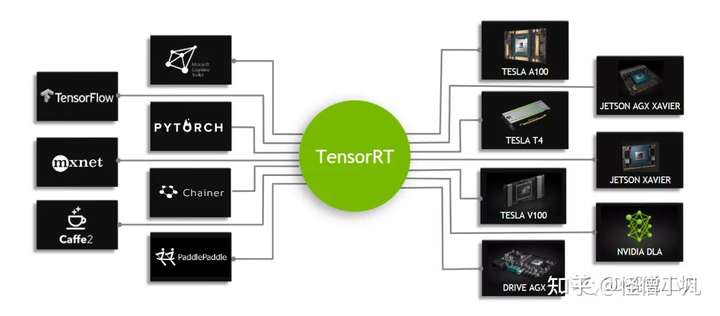
二、使用TensorRT进行推理
1、构建TensorRT Engine
使用TensorRT进行推理,共分为两个阶段。
- 第一个阶段主要是构建TensorRT引擎。目前的主流方式是从onnx转换为TensorRT的引擎。而从各种训练框架都有非常丰富的工具,可以将训练后的模型转换到onnx。

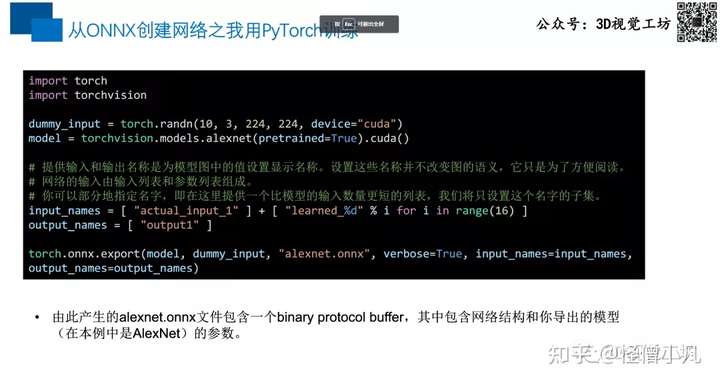
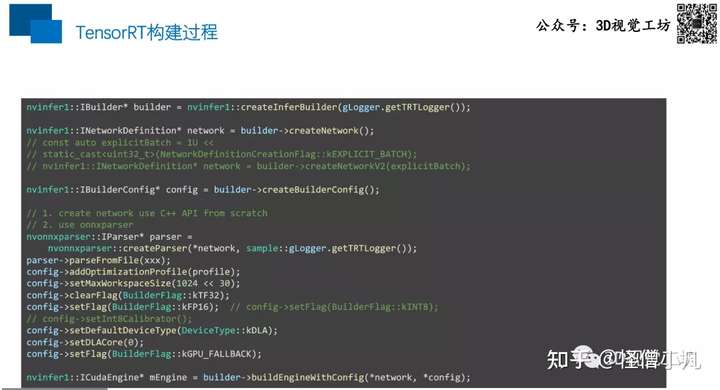
2、运行TensorRT引擎
- 第二阶段主要是运行TensorRT的引擎。ICudaEngine接口持有优化后的引擎,如果要进行推理,还要从ICudaEngine创建IExecutionContext,进而使用IExecutionContext::execute或者IExecutionContext::enqueue函数进行推理。
3、使用混合精度
TensorRT默认使用float32来进行推理,同时也支持fp16和int8的推理。使用fp16进行推理,可以得到几乎和float32相同精度的结果,但是计算量会比float32少的多,和float32推理的区别仅仅在于多设置一个flag。而使用int8进行推理,则需要首先对模型进行量化,得到每一层的动态范围,以便于在运行时进行设定。
4、动态尺寸
TensorRT还支持动态尺寸。动态尺寸是指在构建引擎时不指定全部的输入尺寸,而是以-1作为占位符,等到运行时再设定具体的尺寸。这种情况下一般需要在构建时,添加优化配置文件。更多关于动态尺寸的说明可以参考相关课程《自动驾驶中的深度学习模型部署实战》。
三、TensorRT的优化
1、性能度量工具
在优化代码之前,首先必须要对代码进行度量。最简单直接的度量方法是使用c++标准库的chrono中的API来测量两个时间点的差值。但是TensorRT代码多数为并行代码,因此在CUDA中引入了CUDA Event的概念,可以更方便地对并行代码进行计时。另外还有一些官方的工具,比如trtexec和nvprof,都可以对TensorRT进行剖析。
2、TensorRT优化方法
主要优化方法包含使用batch和stream。batch是指将多个尺寸相同数据组合在一起,送入网络中进行推理。这样比每次只处理一个数据要快的多。使用stream则可以增加更多的并行性。stream也可以和线程一起使用。更详细的TensorRT优化方法介绍可以参考相关课程《自动驾驶中的深度学习模型部署实战》。
四、TensorRT自定义层
TensorRT并不支持所有的深度学习算子。有些算子,还需要我们自己去实现。TensorRT提供了layer plugin接口,我们只需要继承该接口,并实现其中相应的函数即可。一般建议自定义层的第一步是首先使用CUDA实现自定义层的主要功能,然后再将其和layer plugin的接口进行组合。
五、CUDA编程
为了进一步加速深度学习运行时间,我们一般也会将深度学习模型的前处理和后处理放在GPU上来做。因此我们还需要更深入的学习如何用CUDA C进行编程。为了方便编写在GPU上运行的代码,英伟达推出了CUDA编程模型,扩展了原始C++。CUDA编程模型主要有两个部分,一个是如何组织线程层次结构,更好地利用GPU的并行性,一个是如何访问设备内存。
1、线程层次结构
CUDA C++对C++进行了扩展,允许程序员定义C++函数,称为CUDA kernel。kernel是用__global__声明指定的,在给定的内核调用中,执行该内核的CUDA线程数量是用新的<<...>>执行配置语法指定的。多个线程组成线程块,而多个线程块进一步组成线程网格。一个块内的线程可以通过一些共享内存来共享数据,并通过同步它们的执行来协调内存访问。
2、内存层次结构
设备内存可以分为全局内存,共享内存,常量内存和纹理内存。每个线程都有私有的本地内存。每个线程块都有共享内存,对该块的所有线程都是可见的,并且与该块具有相同的生命周期。所有线程都可以访问相同的全局内存。全局、常量和纹理内存空间针对不同的内存使用情况进行了优化。纹理内存还为一些特定的数据格式提供了不同的寻址模式,以及数据过滤。更详细的内容可以参考相关课程《自动驾驶中的深度学习模型部署实战》。
3、CUDA编程优化
1)内存优化
一般来说GPU上的计算比CPU快的多,但是将原本CPU代码移植到GPU之后,不仅仅要对比代码的执行速度,还要考虑内存传输的问题。毕竟在GPU运算之前,需要将主机内存中的数据传输到设备内存,这通常是比较耗时的。优化传输速度的一种方法是使用页面锁定内存。锁页内存由cudaMallocHost申请,由cudaFreeHost释放,它既可以被CPU代码访问,也可以被GPU代码访问。另外一种方法是重叠数据传输和kernel执行。cudaMemcpyAsync可以进行异步数据传输,而在调用kernel时可以使用指定的CUDA stream进行调用。如下图所示,实现同一功能的代码执行顺序不一样时可能产生完全不同的并行效果。更详细的对比说明参考相关课程《自动驾驶中的深度学习模型部署实战》。
2)执行配置优化
所谓执行配置优化指的是在执行cuda kernel时,究竟应该使用多大的线程块以及多大的线程网格才能充分利用硬件性能。我们可以在具体平台上,通过试验来确定block size和grid size。但是有些经验也是可以参考的,比如block size最好是thread warp size的整数倍等。更详细的优化策略参考《自动驾驶中的深度学习模型部署实战》。备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习
、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:CV_LAB,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK