

单目深度估计方法综述
source link: https://zhuanlan.zhihu.com/p/439239999
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
单目深度估计方法综述
一 相关概念介绍
1. 深度估计

深度估计,就是获取图像中场景里的每个点到相机的距离信息,这种距离信息组成的图我们称之为深度图,英文叫Depth map。
作者:塔塔酱|来源:微信公众号:3D视觉工坊
2. 视差

两张图像中相同物体的像素坐标不同,较近的物体的像素坐标差异较大,较远的物体的差异较小。同一个世界坐标系下的点在不同图像中的像素坐标差异,就是视差。不同图像之间的视差,可以换算出物体和拍摄点之间的距离,也就是深度。
二 单目深度估计的研究现状
下图[1]展示了单目深度估计的发展历程,从传统方法发展到深度学习方法,深度学习又分为有监督、半监督和无监督方法。
注:这里也给大家推荐系统介绍单目深度估计原理的精品课程:单目深度估计方法:算法梳理与代码实现
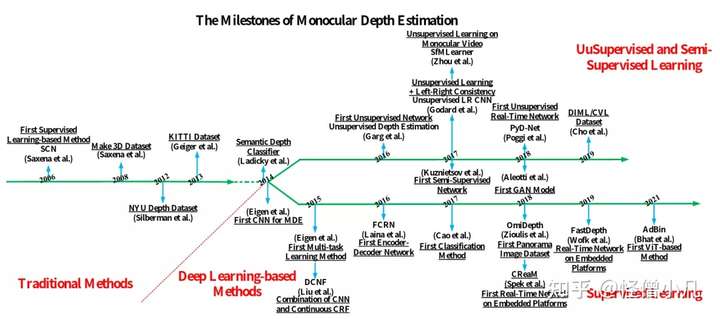
我们将单目深度估计方法分为:基于线索的传统方法、基于机器学习的传统方法、基于有监督的深度学习方法和基于无监督的深度学习方法。
2.1 基于线索的传统方法
人类在观察周围环境时,除了依靠双目获得立体感外,大脑还能根据经验仅从单个视角捕获的各种启发式线索感知深度。常用的单目深度线索有:线性透视[2]、聚焦/散焦[8]、大气散射[7]、阴影[3]、纹理[4]、遮挡[5]和相对高度[6]等。
线性透视线索的例子
大气散射线索的例子
SFS (Shape from shading)方法
根据运动线索求解深度是最常用的一个方法。这里包含两种运动类型:一类是物体自身的运动,一类是摄像机的运动。
基于物体自身运动的深度估计方法是利用运动视差近大远小的原理。利用摄像机的运动进行深度估计,称为运动恢复结构(Structure From Motion, SFM)[9]。假定场景静止不变,仅存在摄像机的运动,SFM 技术可以从拍摄的图像序列中恢复出摄像机的内外参数和场景的深度信息。
2.2 基于机器学习的传统方法
基于统计模式的深度估计算法由于不受特定的场景条件的限制,并且具有较好的适用性,得到了越来越广泛的研究。该类算法主要通过机器学习的方法,将大量有代表性的训练图像集和对应的深度集输入定义好的模型中进行有监督的学习,训练完成之后,将实际输入图像输入到训练好的模型中进行深度的计算。
基于传统机器学习的单目深度估计方法可分为参数学习方法与非参数学习方法。
参数学习方法是指能量函数中含有未知参数的方法,训练的过程是对这些参数的求解。
2005年,斯坦福大学的Saxena[10-11]等人利用马尔科夫随机场(Markov Random Field,MRF) 学习输入图像特征与输出深度之间的映射关系。
上述方法需人为假设RGB图像与深度之间的关系满足某种参数模型,而假设模型难以模拟真实世界的映射关系,因此预测精度有限。非参数学习方法使用现有的数据集进行相似性检索推测深度,不需要通过学习来获得的参数。
基于非参数学习的深度估计算法是一种数据驱动算法。给定一幅测试图像,该类方法通过融合RGBD数据库中与其三维场景内容相似的图像的深度得到测试图像的深度[12-15]。
非参数学习流程图
2.3 基于有监督的深度学习方法
随着深度学习技术的广泛应用,基于深度学习的单目深度估计方法成为了研究的热点。然而,此时的单目深度估计方法都是基于监督学习的,在模型训练时需要依赖真实深度,同时需要依赖庞大的数据进行网络模型的训练,数据集一般包括单目图像和对应的深度真值。
2014年,Eigen等人[16]使用Deep CNN估计单幅图像的深度。两个分支以 RGB 图片作为输入,第一个分支网络粗略预测整张图像的全局信息,第二个分支网络细化预测图像的局部信息。
2015年,Eigen 等人[17]基于上述工作,提出了一个统一的多尺度网络框架。使用了更深的基础网络 VGG,利用第3个细尺度的网络进一步增添细节信息,提高分辨率。
考虑到场景由远及近的特性,可以利用分类的思想。Cao 等人( 2018)[18] 将深度估计问题看作像素级的分类问题。
2.4 基于无监督的深度学习方法
基于有监督学习的单目深度估计方法中,网络模型的训练需要依赖真实深度值。真实深度值的获取成本高昂,且范围有限,需要精密的深度测量设备和移动平台,而且,采集的原始深度标签通常是稀疏点,不能与原图很好的匹配。
基于无监督学习的单目深度估计方法由于在网络训练时不依赖深度真值,因此成为了单目深度估计研究中的热点。无监督学习根据图像对之间的几何关系重建出对应的图像,从而通过图像重建损失监督网络的训练。
Garg 等人( 2016) [19]提出利用立体图像对实现无监督单目深度估计,不需要深度标签,其工作原理类似于自动编码机。
Godard 等人( 2017) [20]对上述方法进行了进一步改进,利用左右视图的一致性实现无监督的深度预测。
Chen 等人( 2016 )[21] 创建了一个新的数据集“Depth in the Wild”,包含任意图像以及图像中随机点对之间的相对深度关系,同时也提出了一个利用相对深度关系估计数值深度的算法。
相对于传统计算机视觉算法和有监督学习算法,基于无监督学习的单目深度估计方法在网络模型训练时只依赖多帧图像,不需要深度真值,在预测深度时只需输入单目图像,具有数据集易获得、结果准确率高和易于应用等优点。
参考文献:
[1] Towards Real-Time Monocular Depth Estimation for Robotics: A Survey
[2] Block-Based Vanishing Line and Vanishing Point Detection for 3d Scene Recostruction
[3] Shape from Shading
[4] Computing Local Surface Orientation and Shape from Texture Forcurved Surfaces
[5] Recovering Occlusion Boundaries from a Single Image
[6] A Novel 2d-to-3d Conversion Technique Based on Relative Height-Depth Cue
[7] Adaptive Estimation of Depth Map for Two-Dimensional to Three-Dimensional Stereoscopic Conversion
[8] Depth Recovery and Refinement from a Single Image Using Defocus Cues
[9] Semantic Structure from Motion
[10] Learning depth from single monocular images
[11] Depth estimation using monocular and stereo cues
[12] 2d-to-3d image conversion by learning depth from examples
[13] Depth Extraction from Video Using Non-parametric Sampling
[14] DepthTransfer: Depth extraction from video using non-parametric sampling
[15] Discrete-Continuous Depth Estimation from a Single Image
[16] Depth map prediction from a single image using a multi-scale deep network
[17] Predicting depth,surface normals and semantic labels with a common multi-scale convolutional architecture
[18] Estimating depth from monocular images as classification using deep fully convolutional residual networks
[19] Unsupervised CNN for single view depth estimation: geometry to the rescue
[20] Unsupervised monocular depth estimation with left-right consistency
[21] Single-image depth perception in the wild
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
10.单目深度估计方法:算法梳理与代码实现11.自动驾驶中的深度学习模型部署实战12.相机模型与标定(单目+双目+鱼眼)
更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:CV_LAB,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK