

人工智能安全的隐忧:深度伪造技术的挑战与应对
source link: https://www.51cto.com/article/768418.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

人工智能安全的隐忧:深度伪造技术的挑战与应对
近几年,人工智能技术呈现蓬勃发展之势,成为引领新一轮科技革命和产业变革的战略性技术,习总书记更是强调“加快发展新一代人工智能是事关我国能否抓住新一轮科技革命和产业变革机遇的战略问题”。人工智能技术正在推动经济社会各领域向智能化加速发展。但“每个硬币都有正反面”,人工智能在为社会生活带来智能便利的同时,也出现了泄露个人隐私、AI技术滥用、危害公共安全等问题,给社会治理带来全新挑战。
深度伪造技术(Deepfake)就是近几年出现的一种利用人工智能等新兴技术操纵音视频、图像或文本内容,意图产生误导效果的技术,其生成的伪造图像和视频可以模仿目标的面部表情、动作和语音的音调、色调等信息,生成足以“以假乱真”的图像和视频,肉眼难以辨识,颠覆了人们对“眼见为实”观念的认知,引发公众对人工智能安全的普遍担忧,对个人、社会和国家的安全存在巨大的技术风险。
二、深度伪造技术
2017年,美国Reddit新闻网站上一位名为deepfakes的用户上传了经过技术篡改的色情视频,将视频中的演员人脸替换成一位电影明星的脸,由此“深度伪造(Deepfake)”技术引发人们关注。深度伪造目前仍然没有公认统一的定义, 美国在其发布的2018 年《恶意伪造禁令法案》中将“Deepfake”定义为“以某种方式使合理的观察者错误地将其视为个人真实言语或行为的真实记录的方式创建或更改的视听记录”, 其中“视听记录”即指图像、视频和语音等数字内容。本文认为深度伪造技术是一种利用深度学习等新兴技术创建或更改图像、视频、语音和文本等数字内容,意图产生误导效果的技术。

01视频图像深度伪造生成技术
目前的视频图像深度伪造技术主要源于深度学习技术在计算机视觉方向的应用和发展。伪造生成主要使用深度神经网络有自编码器网络AE(auto-encoder)和生成式对抗网络GAN(Generative Adversarial Networks)两大类。
初期视频图像的伪造主要依靠自编码器网络,自编码器网络由一个编码器网络和一个解码器网络组成,编码器通过提取人脸特征将人脸图像进行编码压缩,解码器从压缩的编码表示中重构原始人脸。网络在训练阶段,编码器网络学习捕捉人脸的关键特征,利用对应的解码器网络重构形成学习的人脸图像。伪造生成人脸时,只需将任意人脸输入统一的编码器,再将编码后的人脸通过目标人脸的解码器解码,所生成的人脸图像就会具有目标人脸的特征同时保留输入源人脸的表情、特征属性。

自编码器网络为了提高伪造的逼真程度,需要刻意逼近真实样本数据概率分布,造成网络泛化性能不足,生成的逼真程度受限。为了解决这些问题,有研究人员提出使用GAN网络提升伪造生成逼真程度的思路。GAN是一种采用博弈论思路的网络结构,网络由生成模型和判别模型两部分组成,训练学习的过程就是生成器和判别器相互博弈的过程,生成器通过给定输入信息,随机生成样本数据,判别器则要判别生成的样本数据是否属于真实训练样本,两者通过对抗式训练提升其生成器的能力,最终达到生成器能够生成足以“以假乱真”的数据样本。
当前主流的视频图像深度伪造技术主要基于GAN网络思路,衍生出多种基于GAN的变种网络,比如去除了池化层的DCGAN网络、引入EM(Earth-Mover)距离的Wasserstein GNA网络、使用两个不同领域图像学习的CycleGAN网络和引入进化策略优化网络的E-GAN网络、利用条件生产对抗网络的paGAN、结合层叠式网络的SCANs和大规模生成对抗网络等,用于对人脸面部表情、特征进行更精细的操作和渲染,以生成更逼真的人脸图像。
目前深度伪造视频图像主要表现在人脸部属性的修改或生成,主要分为人脸重现、人脸替换、人脸属性操作和人脸生成四个方面。人脸重现是指使用源身份人物的表情、面部动作、头部及躯体动作驱动目标身份的相应动作,目标身份人脸不变,伪造或迁移特定表情、动作到目标人脸,以实现目标身份表情或动作的伪造。人脸替换就是换脸伪造,是指交换源身份人脸和目标身份人脸,以实现人身份修改的目的。人脸属性操作是指添加、编辑或删除目标身份人脸属性,比如发型、肤色、年龄、种族等,以实现目标身份修改的目的。人脸生成是指使用模型完全创建一整个不存在的人脸图像。

02音频深度伪造生成技术
音频的伪造生成主要是指利用AI合成虚假语音,一般表现为从文本合成语音(text-to-speech synthesis)和语音转换(voice conversion)两种形式。
文本到语音合成技术主要是完成从指定文本生成对应的语音数据,主要的方法分为基于语音片段的语音合成方法和基于参数估计的语音合成方法。在基于语音片段的语音合成方法中,生成音频主要通过对语音索引词典中预先录制的语音片段进行排序。基于参数估计的语音合成方法则通过将文本映射到语音的显著参数,从而基于声码器来合成语音。
语音转换是指转换源目标的语音音色到目标对象语音音色的过程。随着人工智能技术的发展,不同的学者借鉴图像视频生成的技术思路,引入自编码器网络、GAN网络、自回归模型等,辅助合成更加逼真的真人语音数据。Santiago等人引入GAN 网络过滤语音的噪音,提升生成语音的质量。Vasquez等人基于频谱图和细粒度的自回归模型设计了一种端到端的语音生成模型,能够同时捕获局部和全局结构,生成的语音内容不仅可以重现人类的语调, 而且可以像真人一样说话。百度通过使用低维度可训练的说话者编码来增强文本到语音的转换,扩展Deep voice,提出Deepvoice2,使得单个模型能生成不同的声音。Ping等人提出基于注意力机制的全卷积TTS模型,扩展生成Deep voice3,能够实现在不降低合成性能的情况下完全并行计算。
三、深度伪造检测技术
01深度伪造视频图像检测技术
随着深度生成对抗网络等技术在图像视频伪造领域的应用,视频图像篡改和合成的能力门槛变得越来越低,特别是人脸生成、人脸属性修改、人脸替换、表情操纵等多种深度伪造工具的应用,使得对伪造视频图像的检测和识别变得越来越困难,仅仅依靠传统视频图像真实性检测和鉴定方法难以支撑多样化的伪造手段。
目前深度伪造视频图像的检测方法研究者主要提出了基于视频图像本身成像特征分析的方法和基于数据驱动的深度学习分析方法两类。
基于视频图像本身成像特征的检测方法主要包括通过分析视频图像中的光照不连续性、阴影不连续性或几何位置不一致等图像的物理特征来辨别图像的真实性。还有提出通过分析视频图像成像设备传感器噪声差异性特征、色差差异性特征来判别图像真实性的方法,还有提出通过分析查找视频图像的压缩痕迹(DCT系数、块状效应等)特征或图像重采样特征以发现视频图像伪造的痕迹,还有研究者提出利用人的生理信号特征如眨眼频率、脉搏、心率等的不协调性和不一致性检测判别视频图像的真伪。基于这类特征的检测方法大多只能检测特定伪造类型“痕迹”,肉眼容易识别的篡改,检测结果的可解释性比较好。
随着深度学习技术的发展,研究人员也提出基于数据驱动的深度学习检测方法。有研究者提出利用对比损失函数,在大量的虚假与真实图像数据上进行训练,从而学习到有效区分真假图像特征表示,达到分析识别真假图像的目的。也有通过分析和提取真伪图像自身差异化特征,进而训练分类器实现深度伪造图像的检测,还有应用各种卷积神经网络、循环神经网络和胶囊网络等深度神经网络结构的视频图像真伪检测方法。
由于深度伪造技术主要基于生成对抗网络,所以,研究者也广泛关注生成对抗网络产生的图像在色彩分布上是否有别于自然图像,提出基于各种颜色特征进行检测识别的方法,也有提出寻求不同GAN网络在生成视频图像时留下的网络指纹特征作为分类识别的依据,用于识别和溯源不同的伪造方法。此类基于GAN指纹特征的方法会依赖GAN的结构,随着GAN技术迅速发展,基于GAN指纹的方法所提取的GAN指纹特征并不具有持久性和通用性,方法的泛化能力不足。
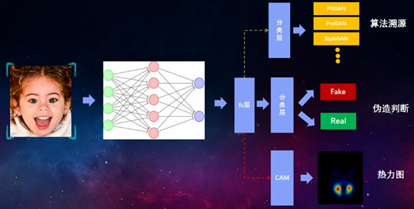
针对深度伪造视频,目前的检测方法仍聚焦于“换脸”技术检测。由于视频在被压缩后,帧数据会产生严重的退化现象且视频帧组之间的时序特征存在一定的变化,故多数基于静态特征的深度伪造图像检测方法无法直接用于深度伪造视频的检测。由于深度伪造模型经常使用静态的面部图像集进行训练,生成模型对人脸先验知识建模不足,难以实现对眨眼、呼吸和心跳等生理信息的准确伪造。因此,很多研究者提出各种基于生理信息的合理性来构建深度伪造视频检测的方法,比如利用不自然的眨眼动作、不一致的面部和头部的朝向、面部区域的视觉伪影等特征实现视频真伪检测。还有研究者关注到伪造生成的视频在时空域上很难做到人脸、皮肤在不同光照和相机视角下的完美融合,提出基于视频帧间不一致性、光响应非均匀性(PRNU)模式差异 、帧间光流的不连续性、面部和周边区域的分辨率不一致等伪造特征痕迹的检测方法。

02深度伪造音频检测技术
随着人工智能技术的应用,音频合成和转换能力不断提升,生成的音频越发逼真,单凭人的听觉判断已经难以主观分辨,因此,研究针对恶意使用的音频深度伪造检测识别方法变得就愈发重要。目前,深度伪造音频的检测识别主要通过基于音频信号分析的方法和基于语速、声纹和频谱分布等生物信息特征的深度学习方法两类。
音频真伪的检测识别研究起初主要基于音频信号处理的思路,研究者有提出对频谱特征建模,使用常量Q倒谱系数(constant-Q cepstral coefficients) 、归一化余弦相位和修正的群延迟等方法进行检测识别,这类方法对采用特定音频处理技术的音频识别效果较好,但方法的泛化性能不佳。
随着深度学习技术的发展,基于数据驱动的深度学习检测方法逐渐被研究者所关注。Gomez-Alanis等人通过融合轻量级卷积神经网络和循环神经网络, 提出一种由光卷积门控递归神经网络提取伪造音频深度特征的检测方法。Li 等人提出融合梅尔频率倒谱系数(Mel frequency cepstrum coefficient)、常量Q倒谱系数(Constant Q cepstral coefficient)和FBank 等多种声学特征的多任务学习检测思路。Monteiro等人提出将声音表征为视觉的频谱图,利用时间卷积网络对频谱图的清晰度进行识别分析以判断音频是否伪造。
伪造语音的检测从传统信号处理方法发展到深度学习方法,在应对语音欺骗领域取得了一定的成果,但是现有方法还是依赖特定攻击类型,对未知类型攻击检测的泛化性提升还有很大的空间。
总之,随着人工智能的技术发展与应用深入,深度伪造检测技术在保护个人隐私、维护公共安全、促进司法公正等方面越来越显示其重要性,应当引起社会各界的充分重视。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK