

推荐系统简介
source link: https://dingfen.github.io/miscellaneous/2023/02/06/recommender_systems.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

推荐系统简介——对主要推荐算法的概述Permalink
本文翻译并整理自 Baptiste Rocca 的文章 Introduction to recommender systems.
引言Permalink
在过去的几十年里,随着 Youtube、亚马逊、Netflix 和许多其他此类网络服务的崛起,推荐系统在我们的生活中占据了越来越多的位置。从电子商务(向客户推荐他们感兴趣的文章)到在线广告(向用户推荐正确的内容,符合他们的喜好),推荐系统在我们的日常网络冲浪中已经不可避免。
用最通俗易懂的语言讲,推荐系统指的是旨在向用户推荐相关物品的算法(这物品可以是要看的电影,要阅读的文本,要购买的产品或其他取决于行业的东西)。
推荐系统在某些行业中非常重要,因为它们可以带来大量收入,或者令某项产品从竞争对手中脱颖而出。提一个可以证明推荐系统的重要性的例子,几年前,Netflix组织了一次挑战赛(“Netflix奖”),目标是参加者要制作一个比Netflix自己的算法表现更好的推荐系统,奖金为100万美元。
在本文中,我们将介绍不同的推荐系统范例。对于它们中的每一个,我们将介绍它们是如何工作的,描述它们的理论基础,并讨论它们的优缺点。
大纲Permalink
在第一节中,我们将概述两种主要的推荐系统范式:协同过滤(collaborative filtering)和基于内容的方法(content based methods)。接下来的两节将描述协同过滤的各种方法,例如用户——用户、物品——物品和矩阵分解。下面的部分将专门讨论基于内容的方法及其工作方式。最后,我们将讨论如何评估一个推荐系统。
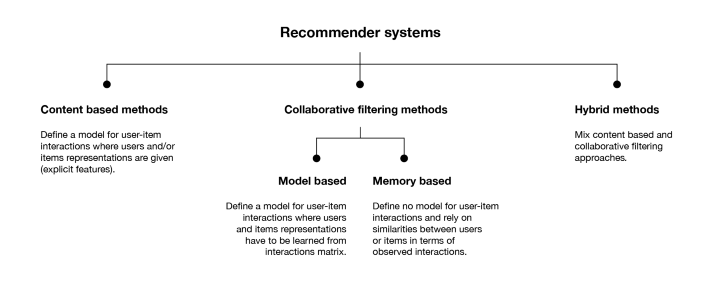
协同过滤 VS 基于内容Permalink
推荐系统的目的是向用户推荐相关的物品。为了实现这一任务,主要有两大类方法:协同过滤方法和基于内容的方法。在深入研究特定算法的细节之前,让我们简要讨论一下这两种主要的范式。
协同过滤算法Permalink
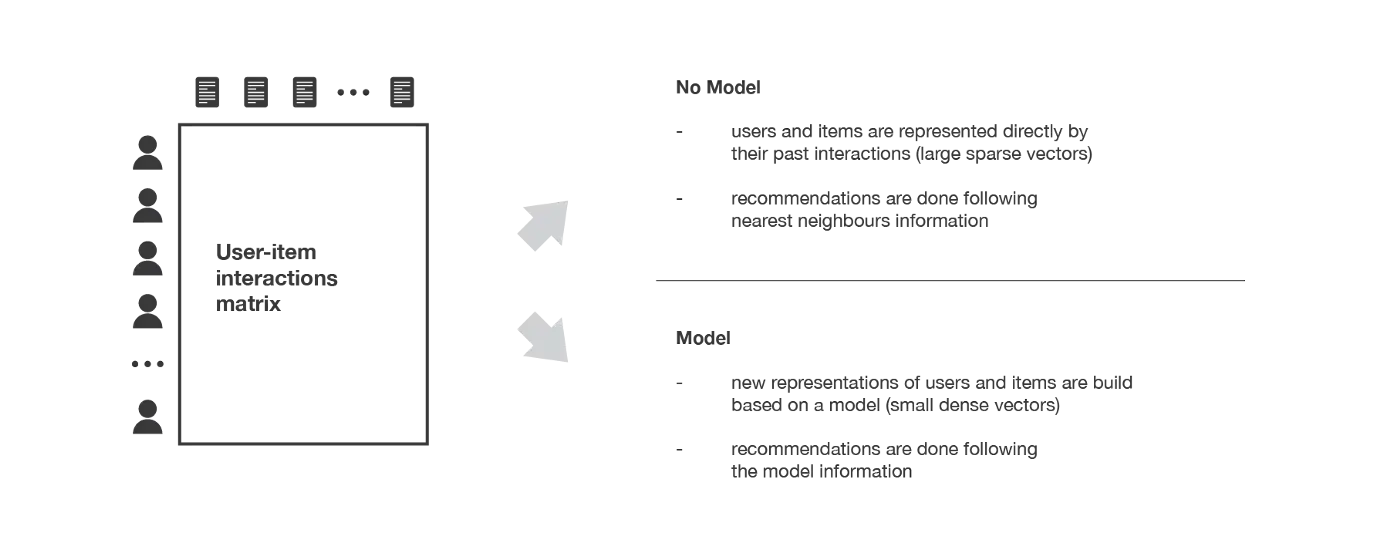
协同过滤方法凭借用户和物品之间的历史交互记录,从而产生新的推荐的方法。这些交互记录被存储在所谓的“用户-物品交互矩阵”(user-item interactions matrix)中。

然后,协同过滤算法主要基于以下认识:过去的用户——物品交互记录足以检测出相似的用户和/或相似的物品,并可以基于这些估计的相似性做出准确的预测。
协同过滤算法分为两个子类别,通常称为基于内存的方法和基于模型的方法。基于内存的方法直接使用记录的交互值,若没有任何模型时,基本上使用最近邻居搜索(例如,从感兴趣的用户中找到最接近的用户,并将最受欢迎的物品推荐给该用户)。基于模型的方法假设了一个潜在的“生成”模型,该模型解释了用户与物品之间的交互关系,并试图以此做出新的预测。
协同过滤的主要优点是,它们不需要用户或物品的相关信息,只需要用户与物品之间发生的互动关系,因此可以在许多情况下使用。此外,用户与商品的互动越多,新的推荐就越准确:对于固定的用户和商品集,随着时间的推移,新的互动记录会带来新的信息,使系统越来越有效。
然而,协同过滤只考虑过去的交互记录进行推荐。上述优点存在的同时也会带来“冷启动问题”:算法不可能向新用户推荐任何东西,也不可能向任何用户推荐一个新物品,许多用户或物品的交互太少,无法有效处理。这一缺陷可以通过不同的方式解决:向新用户推荐随机物品或向随机用户推荐新物品(随机策略),向新用户推荐热门物品或向最活跃用户推荐新物品(最大期望策略),向新用户推荐一组不同的物品或向一组不同的用户推荐新物品(探索策略),最后,对用户或物品的早期使用非协同过滤的方法。
基于内容的方法Permalink
与仅依赖用户-物品交互的协同过滤方法不同,基于内容的方法使用与用户和/或物品有关的额外信息。面对一个推荐电影的算法系统,那么这些额外的信息可以是,用户的年龄、性别、工作或任何其他个人信息,以及类别、主要演员、时长或电影的其他特征。
然后,基于内容的方法的核心思想是尝试建立一个模型,基于上述可用的“特征”,解释所观察到的用户——物品交互关系。仍沿用上例,我们将尝试模拟这样一个事实,年轻女性倾向于给一些电影评分更高,年轻男性倾向于给另一些电影评分更高,等等。如果我们设法得到这样的模型,那么,对用户进行新的预测是非常容易的:我们只需要查看该用户的个人资料(年龄、性别等),并根据这些信息确定要推荐的相关电影。
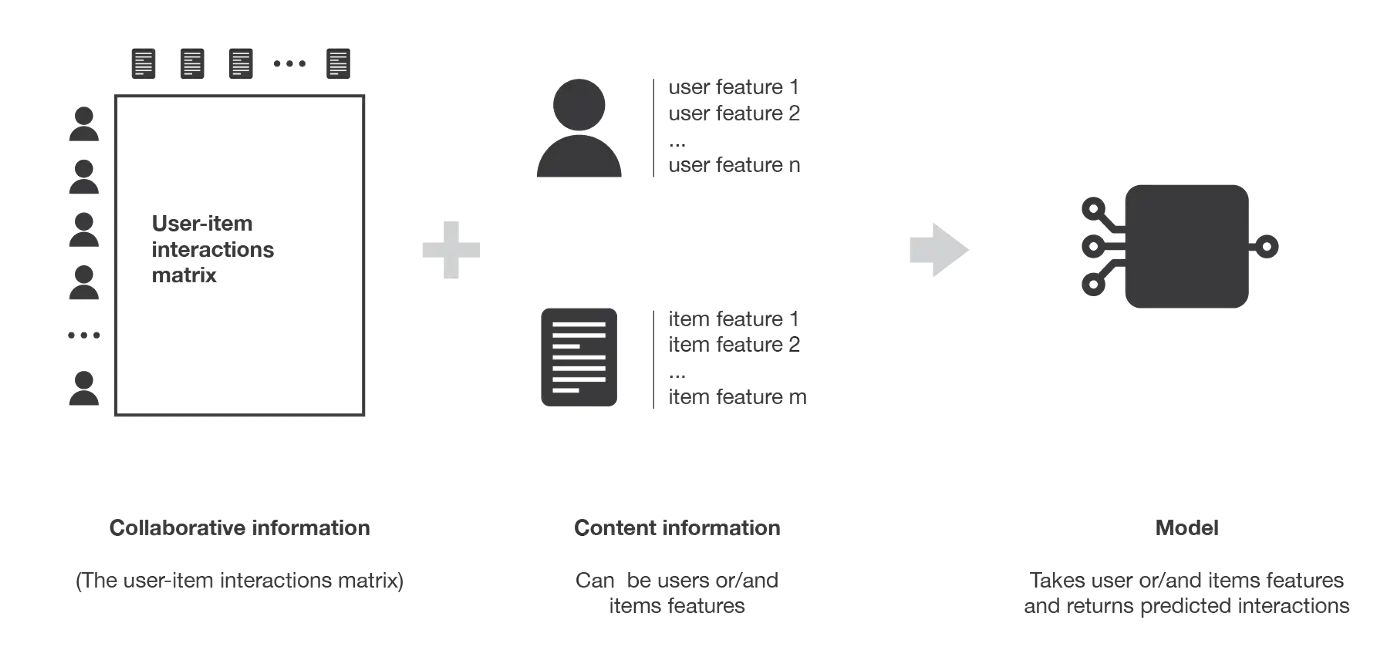
与协同过滤相比,基于内容的方法较少受到冷启动问题的困扰:新用户或物品可以通过其特征(内容)进行描述,因此可以为这些新实体提供相关建议。只有新用户或具有之前未见功能的道具才会受到这种缺陷的影响,但一旦系统足够老,这种情况几乎不会发生。
模型,偏差与方差Permalink
让我们更多地关注一下前面提到的方法之间的主要区别。特别地,让我们看看建模水平对偏差和方差的影响。
在基于内存的协同过滤方法中,不存在潜在模型。算法直接作用与用户-物品交互记录:例如,用户由他们与物品的交互作用表示,并使用对这些表示的最近邻居搜索来产生建议。由于没有假定潜在模型,这些方法理论上具有低偏差但高方差。
在基于模型的协同过滤中,存在一些潜在的交互模型。该模型经过训练,可以从它自己的用户和物品表示中重建用户——物品交互值。然后根据这个模型提出新的建议。由模型提取的用户和物品潜在特征联系,具有难以为人类解释的数学意义。由于假设了用户——物品交互的(相当自由的)模型,该方法理论上比假设没有潜在模型的方法有更高的偏差,但方差更低。
最后,在基于内容的方法中,也存在一些潜在的交互模型。然而,这里的模型提供了定义用户和/或物品表示的内容:例如,用户由给定的特征表示,我们尝试为每个物品建模喜欢或不喜欢该物品的用户配置文件类型。对于基于模型的协作方法,本文假设了一个用户-物品交互模型。然而,该模型受到更多约束(因为给出了用户和/或物品的表示),因此,该方法倾向于具有最大的偏差但方差最小。
基于内存的协同过滤方法Permalink
用户——用户和物品——物品方法的主要特征是,他们只使用来自用户——物品交互矩阵的信息,并且他们假设没有模型来产生新的推荐。
用户——用户Permalink
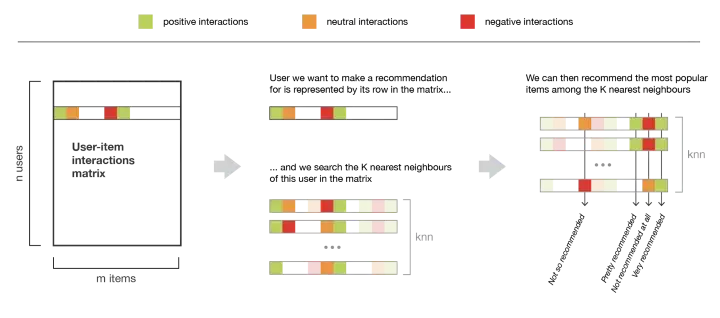
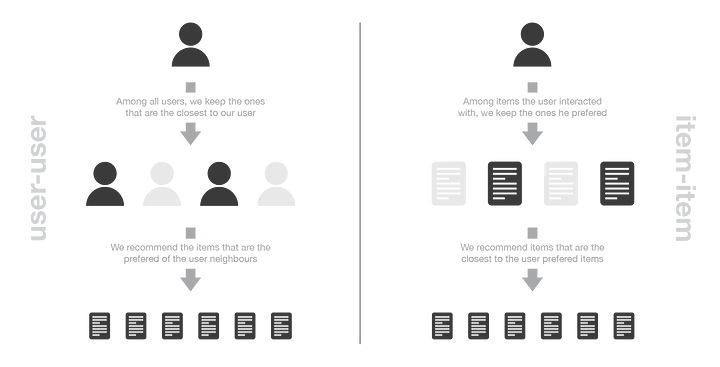
为了给用户做出新的推荐,用户——用户方法粗略地去识别具有最相似的“交互信息”(最近的邻居)的用户,以便将这些邻居中最受欢迎的物品(并且对该用户来说是“新”的)推荐给他。这种方法被称为“以用户为中心”,因为它基于用户与物品的交互来表示用户,并评估用户之间的距离。
假设我们要为某位用户进行推荐。首先,用户的交互记录数据组成的向量就可以表示该用户(交互矩阵中的“一行”)。然后,我们可以计算该用户和所有其他用户之间的某种“相似性”。相似度衡量是这样的,在相同的物品上有相似交互数据的两个用户,就应该被认为是相似的。一旦计算出每个用户的相似度,我们就可以保留该用户的 K 个最邻近邻居,然后将其中最受欢迎的商品推荐给他(当然不包含该用户已经与之交互的物品)。
请注意,在计算用户之间的相似度时,应该仔细考虑“共同交互”的数量(两个用户已经考虑了多少项?)实际上,大多数时候,我们希望避免以下情况:该用户与只有一次共同交互的人有100%的匹配,比其与有100次共同交互的用户但“只有”98%匹配的人“更接近”。所以,我们认为两个用户是相似的,如果他们以相同的方式与许多共同的物品进行交互(相似的评级,相似的悬停时间……)。
物品——物品Permalink
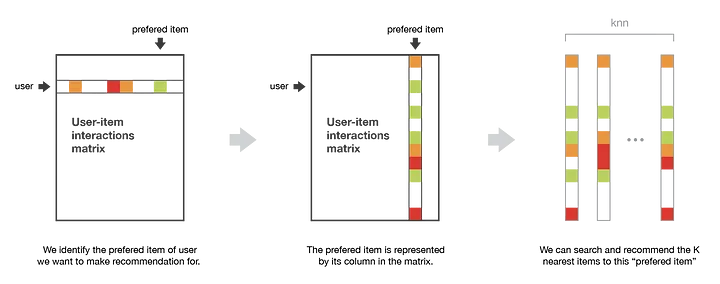
要向用户推荐新的物品,物品——物品的思想是寻找与用户已经“积极”交互过的物品的相似物。如果大多数用户以类似的方式与两个物品进行交互,则认为两个物品是相似的。这种方法被称为“以物品为中心”,因为它基于用户与物品的交互来表示物品,并评估这些物品之间的距离。
假设我们要为给定的用户提供推荐。首先,我们考虑这个用户最喜欢的物品,用该物品与每个用户的交互向量(即它的列)表示它。然后,我们可以计算“最佳物品”和所有其他商品之间的相似度。一旦计算出相似度,我们就可以保留与所选“最佳商品”的k个最近邻居,这些物品对我们感兴趣的用户是新的,并推荐这些物品。
请注意,为了获得更多相关的推荐,我们可以对用户喜欢的其他物品进行做类似的工作,即考虑n个最喜欢的物品。在这种情况下,我们可以推荐与这些首选物品中的几个接近的物品。
比较用户——用户和物品——物品Permalink
用户——用户方法是搜索与物品交互的相似用户。而一般来说,每个用户只与几个物品进行交互,这使得该方法对任何记录的交互都非常敏感(高方差)。另一方面,由于最终的推荐仅基于与我们感兴趣的用户相似的用户的交互记录,因此我们获得了更个性化的结果(低偏差)。
相反,物品——物品方法是搜索用户——物品交互方面的相似物品。一般来说,很多用户都与某件物品进行了交互,因此邻域搜索对单个交互的敏感度要低得多(方差更低)。对应地,来自各种用户的交互信息会被推荐系统考虑,因此方法不那么个性化(更有偏差)。但是,这种方法更加健壮。
复杂性和副作用Permalink
基于内存的协同过滤的最大缺陷之一是它们不容易扩展:对于大系统来说,生成一个新的推荐可能非常耗时。事实上,对于拥有数百万用户和数百万物品的系统,如果不仔细设计,最近邻搜索步骤可能会变得难以处理。KNN算法的复杂度为O(ndk),其中n为用户数量,d为项数量,k为考虑的邻居数量。为了使大型系统的计算更易于处理,我们可以在设计算法时利用交互矩阵的稀疏性,或者使用近似最近邻方法(ANN)。
在大多数推荐算法中,有必要极其小心地避免受欢迎商品的“马太效应”,以避免让用户陷入所谓的“信息茧房”。换句话说,我们不希望我们的系统倾向于只推荐越来越多的流行商品,我们也不希望我们的用户只收到与他们已经喜欢的商品非常接近的商品的推荐,而没有机会了解他们可能也喜欢的新商品,因为这些商品“不够接近”而不能被推荐。如果像我们提到的,这些问题会出现在大多数推荐算法中,那么对于基于内存的协作推荐算法来说尤其如此。的确,由于缺乏规范的模式,这种现象会更加突出和频繁地被观察到。
基于模型的协同过滤算法Permalink
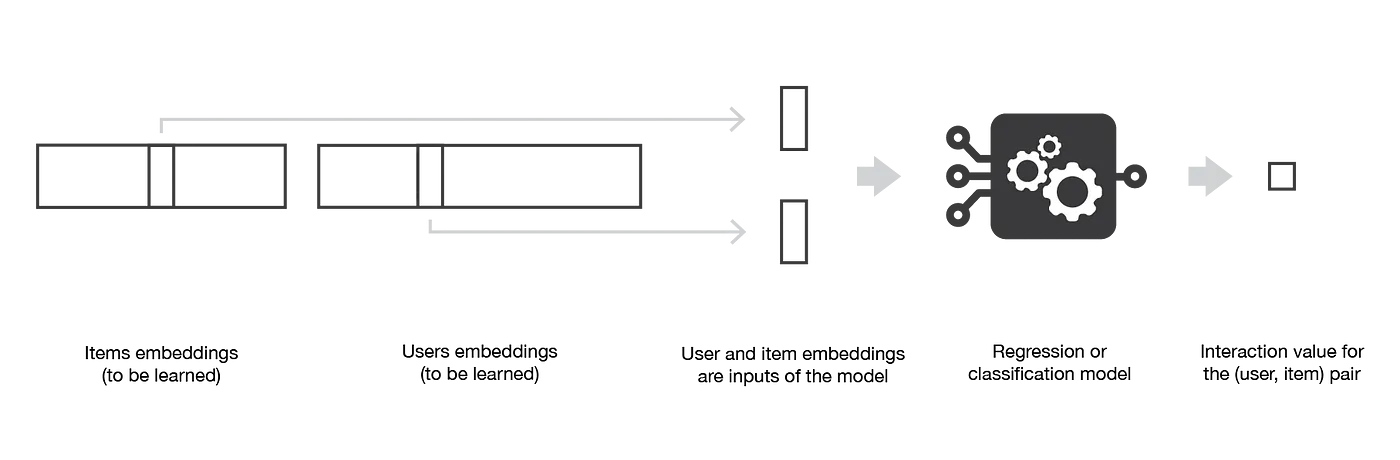
基于模型的协作过滤算法只依赖于用户——物品交互信息,并使用一个潜在的模型来解释这些交互。例如,矩阵分解(Matrix Factorisation)将庞大而稀疏的用户——物品交互矩阵分解为两个较小而密集的矩阵的乘积:一个用户——因素矩阵(包含用户表示)乘以一个因素——物品矩阵(包含物品表示)。
矩阵分解Permalink
矩阵分解算法主要的假设是,存在一个相当低维的潜在特征空间,使得可以在其中表示用户和物品的特征。于是,用户和物品之间的交互信息可以通过计算该空间中相应密集向量的点积来获得。
例如,假设我们有一个用户——电影评级矩阵。为了模拟用户和电影之间的交互,我们可以假设:
- 有一些特征可以很好地描述(和区分)电影
- 有一些特征也可以用来描述用户偏好
然而,我们不太可能为该模型显式地提供这些特征(稍后介绍的基于内容的方法是这样做)。相反,让系统自己发现这些有用的特征,并对用户和物品做出自己的表示才是我们想要的。由于这些特征是学习得到的,而不是开发者给定的,单独提取的特征具有特殊的数学意义,但没有直观的解释(因此人类很难理解)。然而,从这种算法中产生的结构非常接近人类可以想到的直观分解。事实上,这种分解的结果是,在偏好方面接近的用户,以及在特征方面接近的物品,最终在潜在空间中具有相近的特征。
矩阵分解的数学表示Permalink
在这一小节中,我们将给出矩阵分解的简单数学表示。更特别的是,我们描述了一种基于梯度下降的经典迭代方法,它可以在不将所有数据同时加载到计算机内存的情况下获得非常大的矩阵的因式分解。
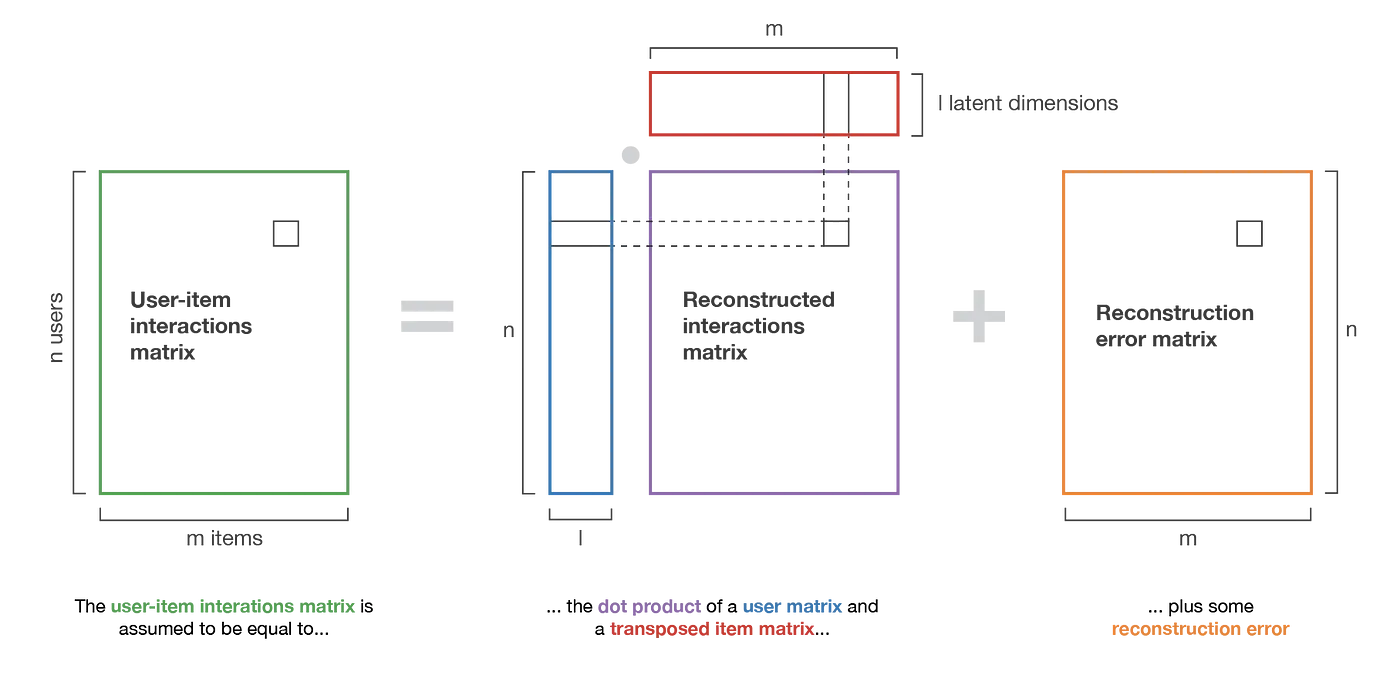
给定一个交互矩阵 M(n×m),一共有n个用户和m个物品。其中每个用户只对一些物品进行了评分(因此大多数项被设置为None 以表示缺乏此项评分)。而我们要因式分解该矩阵: M≈XYT
其中,X(n×l) 是用户矩阵,Y(m×l)是物品矩阵,并定义物品向量和用户向量: useri≡Xi ∀i∈{1,...,n} itemj≡Yj ∀j∈{1,...,m}
这里l是表示用户和物品的潜在空间的维度。因此,我们搜索矩阵X和Y,让它们的点积最接近现有的交互信息。我们使用E表示对用户i和物品j的二元组(i,j)的非空集合,用Mij表示该评分,显然,我们想要能将真实的评分与矩阵分解模型计算的评分误差尽可能减到最小的X和Y。用数学表示即为: (X,Y)=argminX,Y∑(i,j)∈E[(Xi)(Yj)T−Mi,j]2
为防止过拟合和欠拟合问题,再加上一个正则化因子,再除以2,得到
(X,Y)=argminX,Y12∑(i,j)∈E[(Xi)(Yj)T−Mi,j]2+λ2(∑i,k(Xi,k)2+∑j,k(Yj,k)2)
矩阵X和Y可以在梯度下降优化过程中获得,在此有两件事值得注意。首先,每一步的梯度计算并不需要所有E中的元素,我们可以只考虑它的子集,以便“批量”优化我们的目标函数。其次,X和Y中的值不必同时更新,梯度下降算法可以在每一步中对X和Y进行交替优化(如此可认为其中一个矩阵是固定的,而下一次迭代就换一个矩阵进行优化)。
一旦矩阵被分解,我们就可以使用更少的信息来做出新的推荐:我们可以简单地将用户向量乘以任何物品向量,以估计相应的评分。注意,我们还可以使用用户——用户和物品——物品的办法来表示新的用户和物品:近似。因为最近邻搜索不方便在巨大的稀疏向量上运行,但在较小的密集向量上可以运行,这使得一些近似技术更容易处理。
矩阵分解的拓展Permalink
最终我们可以更进一步地理解矩阵分解的基本含义。其实,分解的概念可以扩展到更复杂的模型,例如,对更一般的神经网络的“分解”。我们能想到的第一个就是布尔交互(Boolean interaction)。如果我们想重建布尔相互作用,一个简单的点积不太适合。然而,如果我们在这个点积上加上一个logistic函数,我们就会得到一个在[0,1]中取值的模型,这样就能更好地拟合这个问题。在这种情况下,要优化模型的公式是:
(X,Y)=argminX,Y12∑(i,j)∈E[f((Xi)(Yj)T)−Mi,j]2+λ2(∑i,k(Xi,k)2+∑j,k(Yj,k)2)
其中,f()是 logistic 函数,在复杂的推荐系统中,更深层的神经网络模型经常被用来达到最先进的性能。
基于内容的方法Permalink
在前两节中,我们主要讨论了用户——用户、物品——物品和矩阵分解方法。这些方法只考虑用户——物品交互矩阵,属于协同过滤方法。现在让我们描述基于内容的范例。
基于内容方法的概念Permalink
在基于内容的方法中,推荐问题被转换为分类问题(预测用户是否“喜欢”某个物品)或回归问题(预测用户对某个物品的评分)。在这两种情况下,我们都将设置一个基于用户和/或物品特征的模型,即“基于内容”方法的“内容”。
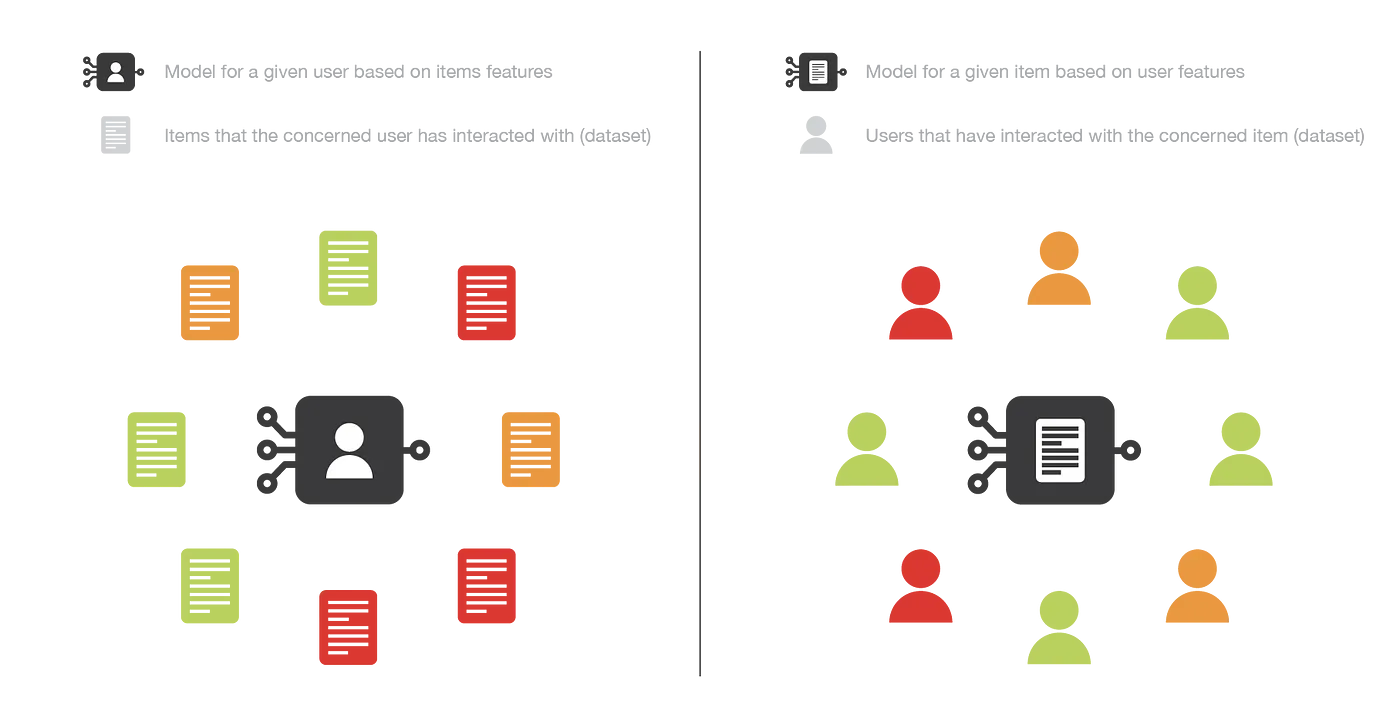
如果我们的分类(或回归)是基于用户的特征,那么这种方法是以物品为中心的:建模、优化和计算可以“按物品”完成。为此,我们根据用户的特征建立并学习一个模型,试图回答这个问题:“每个用户喜欢这个商品的概率是多少?”(或“每个用户对这个物品给出的评分是多少?”,表示回归)。与每个商品相关联的模型自然是在与该商品相关的数据上进行训练的,通常情况下,当许多用户与该商品进行交互时,它会导致相当健壮的模型。然而,考虑学习模型的交互来自每个用户,即使这些用户具有相似的特征,他们的偏好也可能不同。这意味着即使这种方法更加健壮,它也可以被认为比以用户为中心的方法更不个性化,或者说更有偏见。
如果我们处理的是物品特性,那么方法是以用户为中心的:建模、优化和计算可以“由用户”完成。然后,我们根据商品的特征按用户训练一个模型,该模型试图回答这个问题:“这个用户喜欢每件商品的概率是多少?”(或者“这个用户给每件物品的价格是多少?”,表示回归)。然后,我们可以为每个经过数据训练的用户附加一个模型:因此,获得的模型比以物品为中心的模型更个性化,因为它只考虑来自该用户的交互。然而,大多数时候,用户只会与相对较少的物品进行交互,因此,我们获得的模型远不如以物品为中心的模型健壮。
从实际的角度来看,我们应该强调,大多数时候,向一个新用户询问一些信息是很困难的,因为用户不想回答太多问题,而询问关于一个新物品的大量信息很简单,因为添加它们的人有兴趣填充这些信息,以便将他们的物品推荐给正确的用户。注意到,根据要表达的关系的复杂性,我们构建的模型可以或多或少地复杂,从基本模型(用于分类/回归的逻辑/线性回归)到深度神经网络。最后,让我们提一下基于内容的方法也可以既不以用户为中心,也不以物品为中心:关于用户和物品的信息都可以用于我们的模型,例如,通过堆叠两个特征向量并使它们通过神经网络架构。
物品中心的贝叶斯分类器Permalink
让我们首先考虑以物品为中心的分类:对于每个物品,我们希望训练一个贝叶斯分类器,它将用户特征作为输入,并输出“喜欢”或“不喜欢”。因此,为了实现分类任务,我们需要计算
Pitem(like|user_features)Pitem(dislike|user_features)
具有特定特征的用户喜欢该物品的概率与不喜欢该物品的概率之间的比值。定义我们的分类规则的条件概率的比值可以用贝叶斯公式来表示:
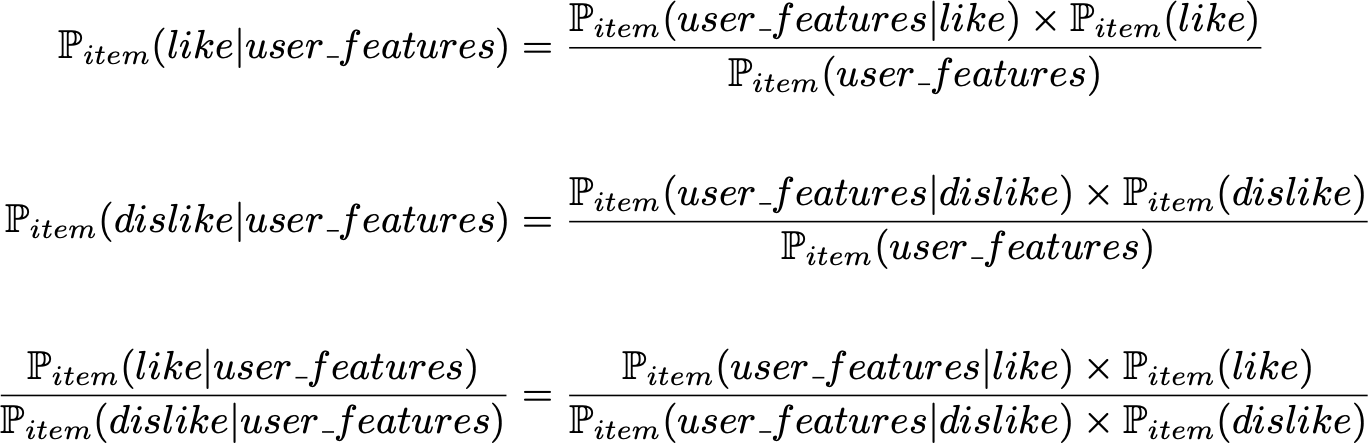
其中, Pitem(like) Pitem(dislike) 是从数据中计算得到的先验,基于数据由高斯分布的假设,可从数据中计算得到的概率: Pitem(⋅|like) Pitem(⋅|dislike) 对于这两个似然分布的协方差矩阵(无假设、矩阵相等、矩阵相等、特征独立)可以做各种假设,从而得到各种广为人知的模型(二次判别分析、线性判别分析、朴素贝叶斯分类器)。我们可以再次强调,在这里,可能性参数只能根据与所考虑物品相关的数据(相互作用)来估计。

用户为中心的线性回归Permalink
现在让我们考虑以用户为中心的回归:对于每个用户,我们希望训练一个简单的线性回归,将物品特征作为输入,并输出该物品的评分。我们仍然将M表示为用户——物品交互矩阵,将用户行向量堆叠成矩阵X,表示要学习的用户系数,将物品向量堆叠成矩阵Y,表示给定的物品特征。然后,对于给定的用户i,我们通过解决以下优化问题来学习Xi中的系数:
Xi=argmin12∑(i,j)∈E[(Xi)(Yj)T−Mij]2+λ2∑k(Xik)2
其中i是固定的,因此,第一个求和只针对与用户i有关的物品。我们可以观察到,如果同时为所有用户解决这个问题,优化问题与我们在“交替矩阵分解”中解决的问题完全相同!这种观察强调了我们在第一节中提到的联系:基于模型的协同过滤(如矩阵分解)和基于内容的方法都假设用户——物品交互的潜在模型,但基于模型的协同过滤方法必须学习用户和物品的潜在表示,而基于内容的方法则基于人为定义的用户和/或物品的特征构建模型。
最后,在基于内容的方法中,也存在一些潜在的交互模型。然而,这里的模型提供了定义用户和/或物品表示的内容:例如,用户由给定的特征表示,我们试着为每一件商品建立喜欢或不喜欢该商品的用户档案类型的模型。对于基于模型的协同过滤,本文假设了一个用户——物品交互模型。然而,该模型受到更多约束(因为给出了用户和/或物品的表示),因此,该方法倾向于具有最大的偏差但方差最小。
对推荐系统的评估方法Permalink
对于任何机器学习算法,我们都需要能够评估我们的推荐系统的性能,以便决定哪种算法最适合我们的情况。推荐系统的评价方法主要分为两种:基于明确指标的评价和基于人的判断和满意度估计的评价。
基于指标的评价Permalink
如果我们的推荐系统是基于输出数值(如评分预测或匹配概率)的模型,那么我们可以使用误差测量度量(例如均方误差MSE)以非常经典的方式评估这些输出的质量。在这种情况下,模型只在可用交互的一部分上进行训练,并在其余的交互上进行测试。
如果我们的推荐系统是基于一个预测数值的模型,我们也可以用经典的阈值方法将这些值二值化,高于阈值的值为正,低于阈值的值为负,并以一种更“分类的方式”评估模型。实际上,由于用户——物品过去交互的数据集也是二进制的(或者说是通过阈值化变为二进制的),我们可以在不用于训练的交互测试数据集上评估模型二值化输出的准确性(以及精度和召回率)。
最后,如果我们现在考虑一个不基于数值的推荐系统,并且只返回一个推荐列表(例如基于KNN方法的用户——用户或物品——物品),我们仍然可以通过估计真正适合我们用户的推荐项目的比例来定义一个类似度量的精度。为了估计这个精度,我们不能考虑用户没有交互过的推荐项目,我们应该只考虑来自测试数据集中有用户反馈的项目。
基于人的判断的评价Permalink
在设计推荐系统时,我们不仅希望获得能够产生我们非常确定的推荐的模型,而且还希望获得一些其他良好的特性,如推荐的多样性和可解释性。
正如在协同过滤算法中提到的,我们希望避免用户被困在信息茧房中。“惊喜发现”的概念经常被用来表达一个模型是否有这样一个限制区域的倾向,即建议的多样性。其实,我们可以通过计算推荐物品之间的距离来估算这种偶然性,它不应该太低,因为这会产生信息茧房,但也不应该太高,因为这意味着我们在推荐时没有充分考虑用户的兴趣。因此,为了在建议的选择中带来多样性,我们希望推荐既非常适合我们的用户,又彼此不太相似的项目。例如,与其推荐用户“Start Wars 1、2和3”,不如推荐“Star Wars 1”、“Start trek into darkness”和“Indiana Jones and the raiders of the lost ark”:之后这两件商品可能会被我们的系统认为不太可能引起用户的兴趣,但推荐三件看起来太相似的商品并不是一个好的选择。
可解释性是推荐算法成功的另一个关键。事实上,事实证明,如果用户不理解为什么他们被推荐为特定的项目,他们往往会对推荐系统失去信心。所以,如果我们设计了一个可以清楚解释的模型,我们可以在推荐的时候添加一个小句子,说明一个商品被推荐的原因(“喜欢这个商品的人也喜欢这个”,“你喜欢这个商品,你可能会对这个感兴趣”)。
最后,除了多样性和可解释性本质上难以评估这一事实之外,我们注意到,评估不属于测试数据集的推荐的质量也相当困难:在实际向用户推荐一个新的推荐之前,如何知道它是否相关?由于所有这些原因,在“真实情况”中测试模型有时很有诱惑力。由于推荐系统的目标是生成一个动作(看电影、购买产品、阅读文章等),我们确实可以评估它生成预期动作的能力。例如,系统可以按照A/B测试方法投入生产,也可以只在用户样本上进行测试。然而,这样的过程需要对模型有一定程度的信心。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK