

DETR源码解读
source link: https://nicehuster.github.io/2022/07/24/DETR%E4%BB%A3%E7%A0%81%E8%A7%A3%E8%AF%BB/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

DETR源码解读
2022-07-24
transformer由encoder和decoder俩部分组成。
Encoder
一个encoder由多个encoder_layer组成,在detr中默认是6层。
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers) # Encoder包含num层,每层具有相同结构encoder_layer
self.num_layers = num_layers
self.norm = norm # 归一化
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# src 对应backbone最后一层输出的feature maps,并且维度已经映射到(h*w,bs, hidden_dim)
# mask 一般为空
# pos 对应backbone最后一层输出的feature maps对应的位置编码,shape是(h*w,bs,c)
# src_key_padding_mask 对应backbone最后一层输出的feature maps对应的mask,shape是(bs,h*w)
output = src
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
return output
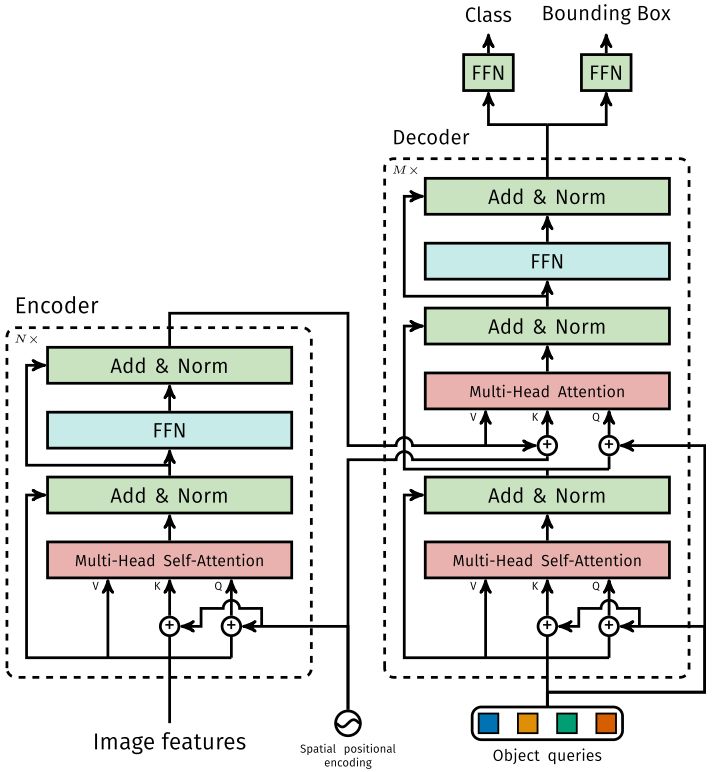
EncoderLayer 的前向过程分为两种情况,一种是在输入多头自注意力层和前向反馈层前先进行归一化,另一种则是在这两个层输出后再进行归一化操作。对应实现可以参考如下图左侧部分:
{kind=link}
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
#多头自注意力模块
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
# 是否需要在输入多头自注意力层之前进行归一化
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# 输入多头自注意力层前进行归一化
src2 = self.norm1(src)
# q,k在输入attn之前需要结合位置编码
q = k = self.with_pos_embed(src2, pos)
# self.self_attn是nn.MultiheadAttention的实例,其前向过程返回两部分,第一个是自注意力层的输出,第二个是自注意力权重,因此这里取了输出索引为0的部分即代表自注意力层的输出。
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# 俩种不同的前向过程
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
需要注意的是,在输入多头自注意力层时需要先进行位置嵌入,即结合位置编码。注意仅对query和key实施,而value不需要。query和key是在图像特征中各个位置之间计算相关性,而value作为原图像特征,使用计算出来的相关性加权上去,得到各位置结合了全局相关性(增强/削弱)后的特征表示。
Query Embedding
在解析Decoder前,有必要先简要地谈谈query embedding,因为它是Decoder的主要输入之一。query embedding 有点anchor的味道,而且是自学习的anchor,作者使用了nn.Embedding实现:
self.query_embed = nn.Embedding(num_queries, hidden_dim)
其中num_queries 代表图像中有多少个目标(位置),默认是100个,对这些目标(位置)全部进行嵌入,维度映射到 hidden_dim,将 query_embedding 的权重作为参数输入到Transformer的前向过程,使用时与position encoding的方式相同:直接相加。
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
而这个query embedding应该加在哪呢?当然是我们需要预测的目标(query object)咯!可是网络一开始还没有输出,我们都不知道预测目标在哪里呀,如何将它实体化?作者也不知道,于是就简单粗暴地直接将它初始化为全0,shape和query embedding 的权重一致(从而可以element-wise add)。
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
...
def forward(self, src, mask, query_embed, pos_embed):
...
# (num_queries,bs,hidden_dim)
tgt = torch.zeros_like(query_embed) #
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
Decoder
Decoder的结构和Encoder十分类似。
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
# tgt 是query embedding,shape是(num_queries,bs,hidden_dim)
# query_pos 是对应tgt的位置编码,shape和tgt一致
# memory是encoder的输出,shape是(h*w,bs,hidden_dim)
# memory_key_padding_mask是对应encoder的src_key_padding_mask,shape是(bs,h*w)
# pos 对应输入到encoder的位置编码,这里代表memory的位置编码,shape和memory一致
output = tgt
intermediate = []
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0)
注意,在detr中,tgt_mask和memory_mask并未使用。需要注意的是intermediate中记录的是每层输出后的归一化结果,而每一层的输入是前一层输出(没有归一化)的结果。
DecoderLayer与Encoder的实现类似,只不过多了一层cross attention,其实质也是多头自注意力层,但是key和value来自于Encoder的输出。
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
# 进行位置嵌入
q = k = self.with_pos_embed(tgt2, query_pos)
# 多头自注意力层,输入不包含encoder的输出
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
# cross attention,key,value来自encoder,query来自上一层输出
# key,query均需进行位置嵌入
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
注意,在tgt在输入到self_attn之前,需要经过position embedding,tgt+query_pos。在第二个多头注意力模块multihead_attn上,key和value均来自Encoder的输出。同样地,query和key要进行位置嵌入(而value不用)。这里cross attention计算的相关性是目标物体与图像特征各位置的相关性,然后再把这个相关性系数加权到Encoder编码后的图像特征(value)上,相当于获得了object features的意思,更好地表征了图像中的各个物体。从上面encoder和decoder的实现可以看出,作者非常强调位置嵌入的作用,每次进行attention计算前都需要进行position embedding,究其原因是因为transformer的转置不变性,即对排列和位置是不care的,然而在detection任务中却是十分重要的。
Transformer
将Encoder和Decoder封装在一起构成Transformer。
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
# 构建encoder layer
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
#构建decoder layer
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model # 输入的embedding的特征维度
self.nhead = nhead #
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
# 将backbone输入的feature maps进行flatten成序列,
# src: (h*w,bs,c)
src = src.flatten(2).permute(2, 0, 1)
# pos: (h*w,bs,hidden_dim)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
# query_embed: (num_queries, bs, hidden_dim)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
# mask: (bs, h*w)
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed) # 每次forward时,tgt都会初始化为0
# memory: (h*w, bs, c)
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
# TransformerDecoderLayer中return_intermediate设置为true,因此decoder包含了每层的输出结果,因此hs的shape是(6, num_queries,bs,hidden_dim)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
注意,tgt是与query embedding形状一直且设置为全0的结果,意为初始化需要预测的目标。因为一开始并不清楚这些目标,所以初始化为全0。其会在Decoder的各层不断被refine,相当于一个coarse-to-fine的过程,但是真正要学习的是query embedding,学习到的是整个数据集中目标物体的统计特征,而tgt在每次迭代训练(一个batch数据刚到来)时会被重新初始化为0。
DETR包含backbone,encoder, decoder, prediction heads四个部分。encoder和decoder通常会用一个transformer来实现。prediction heads部分包括分类和回归。
class DETR(nn.Module):
""" This is the DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
"""
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
hidden_dim = transformer.d_model
# class分类
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
# box回归,包含3层nn.linear(),最后一层维度映射为4,代表bbox的中心点横、纵坐标和宽、高。
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
# query_embed用于在Transformer中对初始化query以及对其编码生成嵌入
self.query_embed = nn.Embedding(num_queries, hidden_dim)
# input_proj是将CNN提取的特征维度映射到Transformer隐层的维度;
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
self.backbone = backbone
self.aux_loss = aux_loss
def forward(self, samples: NestedTensor):
# 将sample转换成nestedTensor类型
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
# 输入cnn提取特征,并输出pos encoding
features, pos = self.backbone(samples)
# 取出最后一层特征及对应mask
src, mask = features[-1].decompose()
assert mask is not None
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
# 生成分类与回归的预测结果
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
# 由于hs包含transformer中decoder每层输出,因此索引-1表示取最后一层输出
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
Postprocess
一部分DETR的输出并不是最终预测结果的形式,还需要进行简单的后处理。但是这里的后处理并不是NMS哦!DETR预测的是集合,并且在训练过程中经过匈牙利算法与GT一对一匹配学习,因此不存在重复框的情况。
class PostProcess(nn.Module):
""" This module converts the model's output into the format expected by the coco api"""
@torch.no_grad()
def forward(self, outputs, target_sizes):
out_logits, out_bbox = outputs['pred_logits'], outputs['pred_boxes']
assert len(out_logits) == len(target_sizes)
assert target_sizes.shape[1] == 2
# out_logits : (bs, num_queries,num_classes)
prob = F.softmax(out_logits, -1)
scores, labels = prob[..., :-1].max(-1)
# convert to [x0, y0, x1, y1] format
boxes = box_ops.box_cxcywh_to_xyxy(out_bbox)
# and from relative [0, 1] to absolute [0, height] coordinates
img_h, img_w = target_sizes.unbind(1)
scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
boxes = boxes * scale_fct[:, None, :]
results = [{'scores': s, 'labels': l, 'boxes': b} for s, l, b in zip(scores, labels, boxes)]
return results
Loss Fuction
这一部分主要介绍一下和损失函数相关的部分源码。先看一下与损失函数相关的代码:
matcher = build_matcher(args)
weight_dict = {'loss_ce': 1, 'loss_bbox': args.bbox_loss_coef}
weight_dict['loss_giou'] = args.giou_loss_coef
if args.masks:
weight_dict["loss_mask"] = args.mask_loss_coef
weight_dict["loss_dice"] = args.dice_loss_coef
# TODO this is a hack
if args.aux_loss:
aux_weight_dict = {}
for i in range(args.dec_layers - 1):
aux_weight_dict.update({k + f'_{i}': v for k, v in weight_dict.items()})
weight_dict.update(aux_weight_dict)
losses = ['labels', 'boxes', 'cardinality']
if args.masks:
losses += ["masks"]
criterion = SetCriterion(num_classes, matcher=matcher, weight_dict=weight_dict,
eos_coef=args.eos_coef, losses=losses)
matcher是将预测结果与gt进行匹配的匈牙利算法,weight_dict是各部分loss设置的权重参数,包括分类与回归损失。分类使用的是CE loss,回归包括l1 loss和giou loss。如果包含分割任务,还有mask相关损失函数,另外如果设置了aux_loss,则代表计算decoder中间层预测结果对应的loss。 loss函数的实例化使用SetCriterion进行构建的。
class SetCriterion(nn.Module):
""" This class computes the loss for DETR.
The process happens in two steps:
1) we compute hungarian assignment between ground truth boxes and the outputs of the model
2) we supervise each pair of matched ground-truth / prediction (supervise class and box)
"""
def __init__(self, num_classes, matcher, weight_dict, eos_coef, losses):
""" Create the criterion.
Parameters:
num_classes: number of object categories, omitting the special no-object category
matcher: module able to compute a matching between targets and proposals
weight_dict: dict containing as key the names of the losses and as values their relative weight.
eos_coef: relative classification weight applied to the no-object category
losses: list of all the losses to be applied. See get_loss for list of available losses.
"""
super().__init__()
self.num_classes = num_classes
self.matcher = matcher
self.weight_dict = weight_dict
# 针对背景分类的loss权重
self.eos_coef = eos_coef
self.losses = losses
empty_weight = torch.ones(self.num_classes + 1)
empty_weight[-1] = self.eos_coef
self.register_buffer('empty_weight', empty_weight)
"""
'''
"""
def get_loss(self, loss, outputs, targets, indices, num_boxes, **kwargs):
loss_map = {
'labels': self.loss_labels,
'cardinality': self.loss_cardinality,
'boxes': self.loss_boxes,
'masks': self.loss_masks
}
assert loss in loss_map, f'do you really want to compute {loss} loss?'
return loss_map[loss](outputs, targets, indices, num_boxes, **kwargs)
def forward(self, outputs, targets):
""" This performs the loss computation.
Parameters:
outputs: dict of tensors, see the output specification of the model for the format
targets: list of dicts, such that len(targets) == batch_size.
The expected keys in each dict depends on the losses applied, see each loss' doc
"""
outputs_without_aux = {k: v for k, v in outputs.items() if k != 'aux_outputs'}
# Retrieve the matching between the outputs of the last layer and the targets
# 将预测结果与GT进行匹配,indices是一个与bs长度相等的多元组的list
# 每个元组为(ind_i,ind_j),前者是匹配的预测预测索引,后者是gt的索引
indices = self.matcher(outputs_without_aux, targets)
# Compute the average number of target boxes accross all nodes, for normalization purposes
num_boxes = sum(len(t["labels"]) for t in targets)
num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
if is_dist_avail_and_initialized():
torch.distributed.all_reduce(num_boxes)
num_boxes = torch.clamp(num_boxes / get_world_size(), min=1).item()
# Compute all the requested losses
# 计算所有相关的损失,其中self.losses = ['labels', 'boxes', 'cardinality']
losses = {}
for loss in self.losses:
losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))
"""
'''
"""
return losses
从forward函数可以看出,首先进行匈牙利匹配的是decoder最后一层的输出,之后再计算匹配后的损失函数包括losses = [‘labels’, ‘boxes’, ‘cardinality’],具体计算部分可以看get_loss方法中映射的对应计算方法,其中包括self.loss_labels,self.loss_cardinality,self.loss_boxes。
匈牙利匹配
匈牙利算法,在这里用于预测集(prediction set)和GT的匹配,最终匹配方案是选取“loss总和”最小的分配方式。注意,这里计算的loss与损失函数中计算loss并不相同,在这里是用来作为代价cost,cost大小决定匹配程度。
class HungarianMatcher(nn.Module):
def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float = 1):
"""Creates the matcher
Params:
cost_class: This is the relative weight of the classification error in the matching cost
cost_bbox: This is the relative weight of the L1 error of the bounding box coordinates in the matching cost
cost_giou: This is the relative weight of the giou loss of the bounding box in the matching cost
"""
super().__init__()
self.cost_class = cost_class
self.cost_bbox = cost_bbox
self.cost_giou = cost_giou
assert cost_class != 0 or cost_bbox != 0 or cost_giou != 0, "all costs cant be 0"
@torch.no_grad()
def forward(self, outputs, targets):
bs, num_queries = outputs["pred_logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes
tgt_ids = torch.cat([v["labels"] for v in targets])
tgt_bbox = torch.cat([v["boxes"] for v in targets])
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be ommitted.
cost_class = -out_prob[:, tgt_ids]
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
# Compute the giou cost betwen boxes
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu()
sizes = [len(v["boxes"]) for v in targets]
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
从上面可以看到,匈牙利匹配在前向计算过程中,是不需要梯度的。其中分类cost是直接采用1减去预测概率的形式,同时由于1是常数,于是作者甚至连1都省去了,在box上计算了l1和giou两种cost,之后对各部分进行加权求和得到总的cost。匹配方法使用的是 scipy 优化模块中的 linear_sum_assignment(),其输入是二分图的度量矩阵,该方法是计算这个二分图度量矩阵的最小权重分配方式,返回的是匹配方案对应的矩阵行索引和列索引。
至此,DETR所有相关源码均已解读完毕。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK