

ALBEF方法详解
source link: https://nicehuster.github.io/2022/08/18/ALBEF/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ALBEF方法详解
2022-08-18
这篇文章介绍一篇多模态预训练相关的论文,Align before Fuse: Vision and Language Representation Learning with Momentum Distillation,单位是Salesforce Research,下面大致的介绍一下两篇论文的具体工作。这篇paper提出了一个新的视觉-语言表征学习框架,通过在融合之前首先对齐单模态表征来实现最佳性能。
现有的VLP方法存在如下三个限制:
Limitation 1:以CLIP和ALIGN为代表的方法分别独立学习单模态的图像encoder和文本encoder,缺乏对图像和文本之间的复杂互动进行建模的能力,因此它们不擅长于需要细粒度图像-文本理解的任务;
Limitation 2:以UNITER为代表的方法使用多模态编码器联合学习图像与文本,然而,从区域中提取的图片特征和文本词向量是没有对齐的;
Limitation 3:现有用于预训练的数据集大多是由从网络上收集的嘈杂的图像-文本对组成。广泛使用的预训练目标,如掩码语言建模(MLM),容易对噪声文本过度拟合,这将损害表示学习。
为了解决这些限制,我们提出了ALign BEfore Fuse(ALBEF),ALBEF在多个视觉-语言下游任务上取得了SOTA的性能,如图像-文本检索、视觉问题回答(VQA)和自然语言视觉推理(NLVR)。
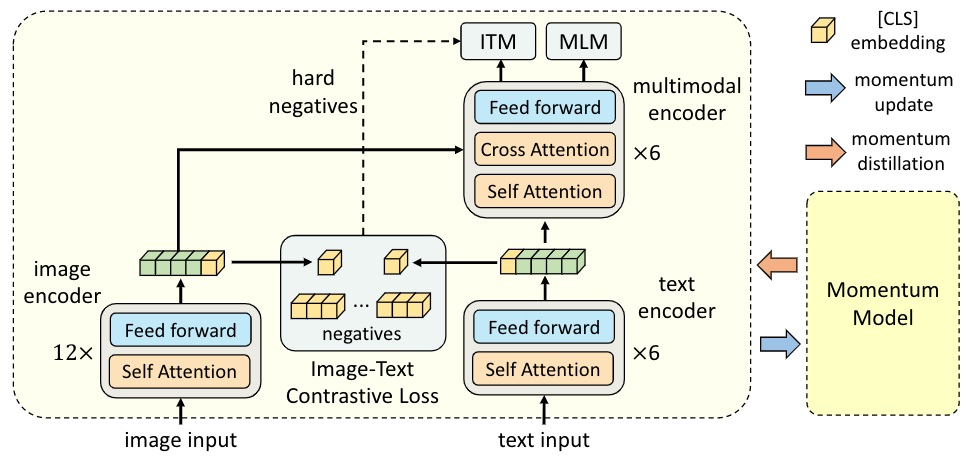
上图展示了ALBEF的整体框架结构,ALBEF包含一个image encoder(ViT-B/16),一个text encoder(BERT的前6层),以及一个multimodal encoder(BERT的后6层与额外的交叉注意力层)。我们通过共同优化以下三个目标来对ALBEF进行预训练:
Objective 1:图像-文本对比学习应用于单模态的image encoder和text encoder。它使图像特征和文本特征相一致,同时训练单模态编码器更好地理解图像和文本的语义;
Objective 2:图像-文本匹配应用于多模态编码器,预测一对图像和文本是否匹配。我们还使用了难样本挖掘,选择具有较高相似度的样本进行学习;
Objective 3:在多模态编码器上应用掩码语言建模(MLM)进行训练;
Momentum Distillation
从网络上收集的图像-文本对往往是弱相关的:文本可能包含与图像无关的词,或者图像可能包含文本中没有描述的实体。为了从嘈杂的数据中学习,我们提出了动量蒸馏法,即使用动量模型为图像-文本对比学习和掩码语言建模生成伪目标。
下游任务上的应用
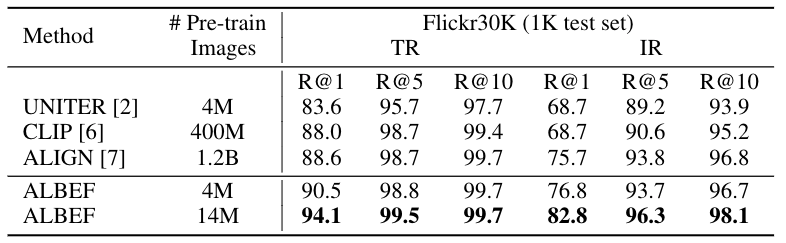
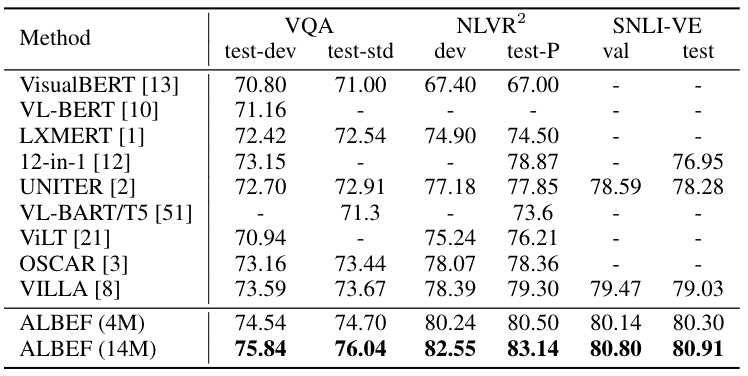
ALBEF在多个下游任务上取得了最先进的性能,如下表所示。在图像-文本检索方面,ALBEF优于在更大数量级的数据集上进行预训练的方法(CLIP[2]和ALIGN[3])。在VQA、NLVR和VE方面,ALBEF优于那些使用预先训练的物体检测器、额外的物体标签或对抗性数据增强的方法。
Visual Grounding
有意思的是,ALBEF还隐含的学习了物体、属性和关系。使用Grad-CAM对multimodal encoder的交叉注意力进行可视化,在弱监督的visual grounding任务上取得很不错的结果,如下示例:



Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK