

最简单的多模态VLP模型ViLT
source link: https://nicehuster.github.io/2022/09/03/ViLT/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

最简单的多模态VLP模型ViLT
2022-09-03
本文介绍一篇发表在ICML2021上有关多模态预训练相关的论文,ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision,ViLT不需要使用预训练的ViT来初始化多模态交互的transformer,直接用用交互层来处理视觉特征,无需额外增加视觉encoder,比如提取region features的object detector。
Taxonomy of Vision-and-Language Models
在这篇论文中,作者依据:1)在参数或者计算上,俩种模态是否保持平衡;2)俩种模态是否是在深度网络中进行交互;将现有的VLP模型大致划分为以下四种:
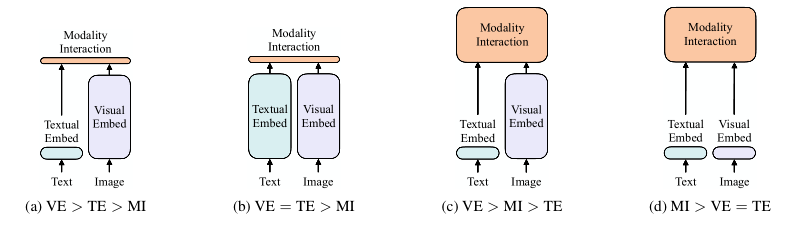
其中每个圆角矩形的大小表示相对计算量大小,VE、TE和MI分别是visual embedding、text embedding和modality interaction的简写。
Visual Embedding Schema

现有的VLP模型的text embedding大多是使用类BERT结构,但是visual embedding存在着差异。在大多数情况下,visual embedding是现有VLP模型的瓶颈。visual embedding的方法总共有三大类,其中region feature方法通常采用Faster R-CNN二阶段检测器提取region的特征,grid feature方法直接使用CNN提取grid的特征,patch projection方法采用类似ViT将输入图片切片投影提取特征。
Vision-and-Language Transformer
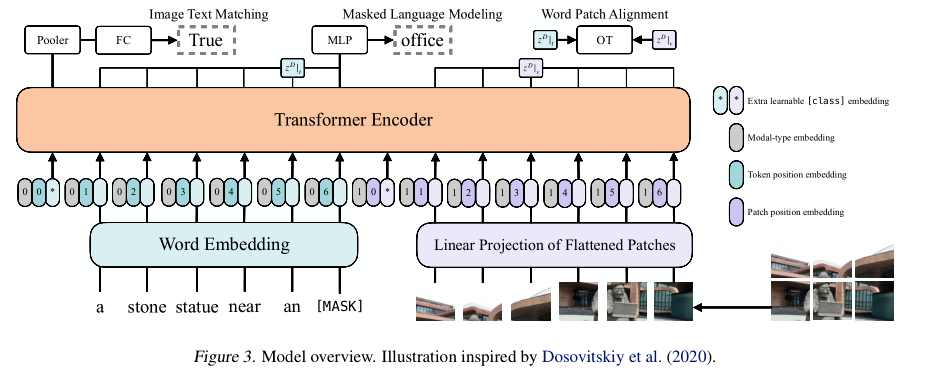
上图展示的是ViLT结构,采用的是single-stream结构,对visual和text进行concat后进行交互操作。在文本特征提取部分采用的是word embedding得到text embedding而没有使用类似bert结构,在图像特征提取部分采用的是ViT那套对图像切块然后拼成序列通过线性映射得到visual embedding,最后俩个embedding都会结合各自的position embedding和modal-type embedding输入到transformer encoder中进行交互;其中modal-type embedding用于区分text embedding和visual embedding;此外,需要注意的是,text embedding和visual embedding分别都嵌入了额外的[cls] embedding用于后续的下游任务;
Pre-training Objectives
ViLT的预训练目标函数包括俩个:image text matching (ITM) and masked language modeling (MLM);
ImageText Matching:随机以0.5的概率将文本对应的图片替换成不同的图片,然后对文本标志位对应输出使用一个线性的ITM head将输出feature映射成一个二值logits,用来判断图像文本是否匹配。
Masked Language Modeling:MLM的目标是通过文本的上下文信息去预测masked的文本tokens。随机以0.15的概率mask掉tokens;
此外,在ViLT中还使用了whole word masking技巧;将连续的子词tokens进行mask的技巧,避免了只通过单词上下文进行预测。比如,使用bert-base-uncased预训练的tokenizer对“giraffe”进行分词,就会得到[“gi”, “##raf”, “##fe”],可以mask成[“gi”, “[MASK]”, “##fe”],模型会通过mask的上下文信息[“gi”,“##fe”]来预测mask的“##raf”,就会导致不利用图像信息。
Experiments
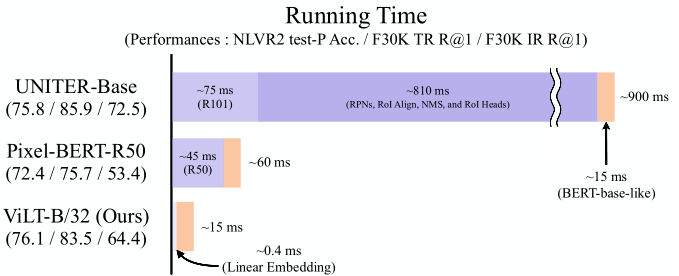
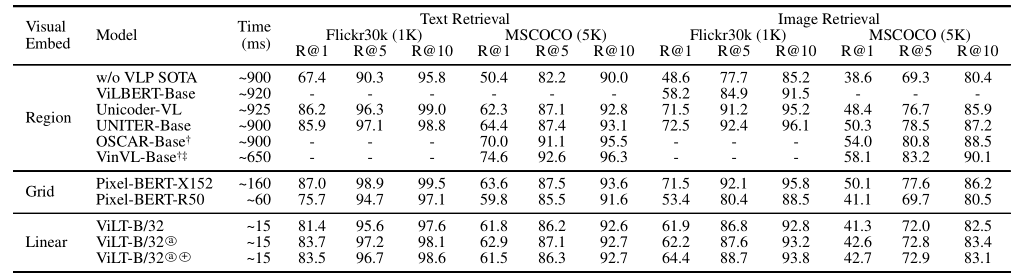
如上图所示,相比于基于region feature方法和grid feature方法,在速度上分别快60倍和4倍。在下游任务上也取得不错的性能。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK