

Rethinking Positional Encoding In Language Pre-Training
source link: https://nicehuster.github.io/2022/09/18/tupe/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Rethinking Positional Encoding In Language Pre-Training
2022-09-18
本文介绍一篇有关transformer中位置编码的论文,论文发表自ICLR2021,该论文主要探究了俩个问题:1)在transformer中,处理位置编码时,直接将word embedding和position embedding相加后送入multi-head attention是否合理;2)在序列分类任务中,通常会在句首附加[CLS] token用于捕捉全局信息是否合理;针对改俩个问题对position encoding和[cls]token进行改进和修正。
Motivation
Position和word关系解耦
在作者看来,word embedding和position embedding属于俩种异构信息,直接进行相加,会造成mixed correlations。以绝对位置编码为例,计算attention过程如下:
其中w是word embedding,p是position embedding,对attention进行分项,我们可以看到上式中包含4种不同的相关系数:word-to-word, word-to-position, position-to-word, and position-to-position。
第一项和最后一项分别描述了word embedding之间的互相关性和position embedding之间的互相关性;在这里,俩项的权重矩阵WQ,WKWQ,WK是共享的,在作者看来,俩种不同信息使用相同的projection是不合理;中间俩项描述的是word embedding和position embedding之间的相关性。作者分别对四项的结果进行了可视化,证明其俩种不同信息之间几乎没有任何相关性;

针对上述问题,作者对attention的计算进行了修正:
作者直接移除了中间俩项,并对word embedding和position embedding之间的互相关性使用了不同的权重进行projection,其中UQ,UKUQ,UK在不同layers之间是权重共享的;
从positions中解耦[CLS]
在BERT及其变体中,[CLS]通常可以存储全局信息,并用于下游任务中。但已有研究表明,这类regular words(与natural words相对)在句子中具有很强的局部依赖性,如果像对待natural words的位置信息一样对待[CLS]的位置信息,则[CLS]很可能会倾向于只关注整个句子的前几个单词,这对于下游任务显然是有害的。针对这个问题,作者对上面αijαij中的最后一项,position embedding之间的互相关性进行了修改:
其中,vij=12d√(piUQ)(pjUK)Tvij=12d(piUQ)(pjUK)T,其中,θ1,θ2θ1,θ2均为可学习参数,从上可以看出,针对[CLS]与其他位置的相关性计算做了专门处理,如下图所示:
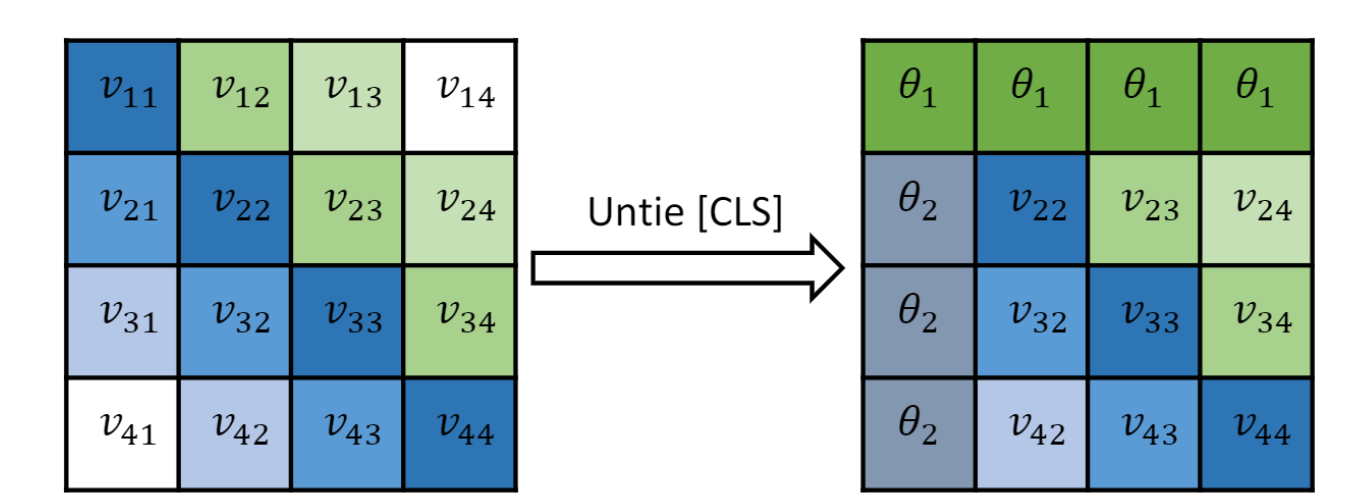
相当于把[CLS]标识符对应的位置信息进行了抹除,其他位置与[CLS]的相对位置都一致;
Experiments
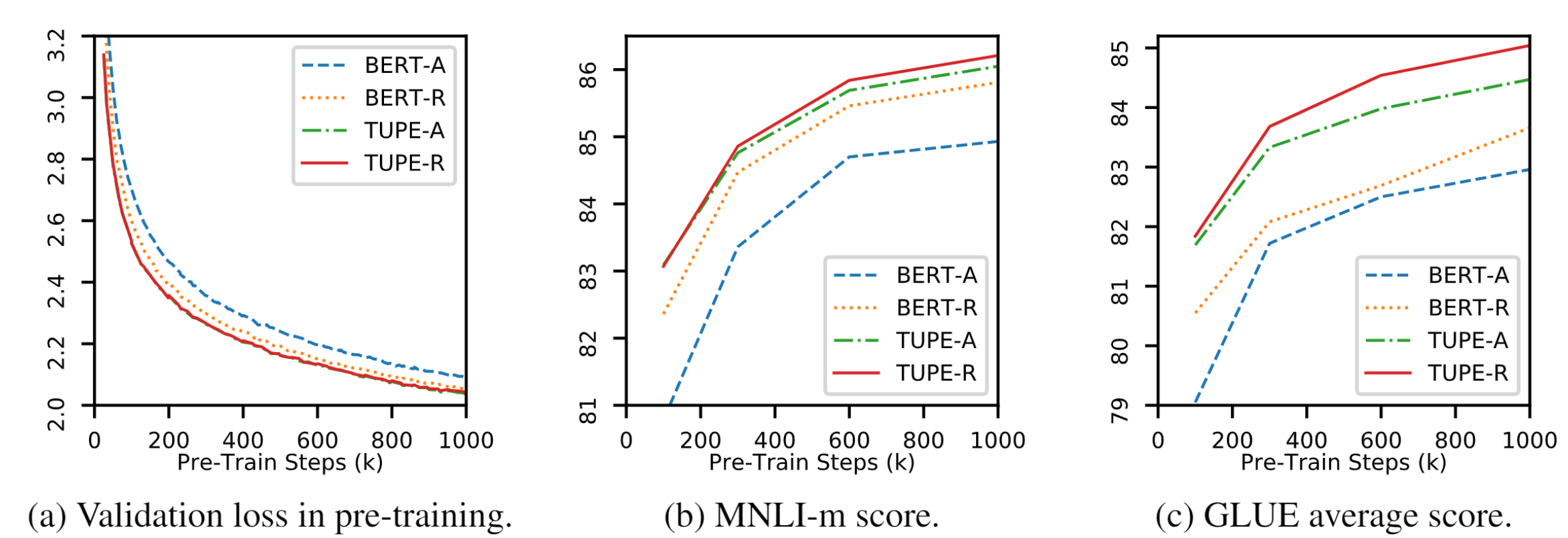
修正以后收敛更快,性能更好,其中TUPE是修正方法的简称,A指绝对位置编码、R指相对位置编码。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK