

一起打怪升级呀
source link: https://nicehuster.github.io/2022/11/02/tokenize/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

文本分词详解
2022-11-02
在对文本进行处理时,我们需要进行文本预处理 ,而最重要的一步就是分词(Tokenize) 。一个完整的分词流程如下:
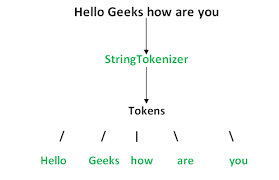
其中,执行分词的算法模型称为分词器(Tokenizer) ,划分好的一个个词称为 Token (为啥不直接叫 Word?接着往后看),这个过程称为 Tokenization 。我们将一个个的 token(可以理解为小片段)表示向量,我们分词的目的就是尽可能的让这些向量蕴含更多有用的信息,然后把这些向量输入到算法模型中。由于一篇文本的词往往太多了,为了方便算法模型训练,我们会选取出频率 (也可能是其它的权重)最高的若干个词组成一个词表(Vocabulary) 。
古典分词方法
分词,顾名思义,就是把一句话分词一个个词,这还不简单?直接把词与词直接加一个空格不就行了?那如果真这么简单我们也不用讨论了,还有什么办法呢,再想一想?或许还能按标点符号分词 ,或者按语法规则分词 。
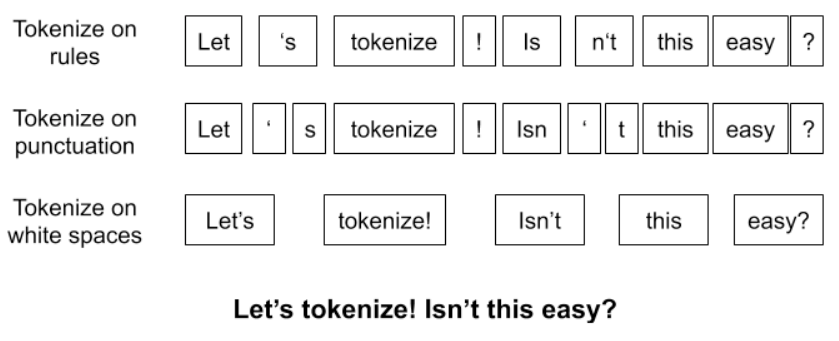
面提到的这些方法,统称为古典分词方法 ,区别不是很大。一个句子,使用不同的规则,将有许多种不同的分词结果。古典分词方法的缺点非常明显:
- 对于未在词表中出现的词(Out Of Vocabulary, OOV ),模型将无法处理(未知符号标记为
[UNK])。- 词表中的低频词/稀疏词在模型训无法得到训练(因为词表大小有限,太大的话会影响效率);
- 很多语言难以用空格进行分词,例如英语单词的多形态,“look”衍生出的”looks”, “looking”, “looked”,其实都是一个意思,但是在词表中却被当作不同的词处理,模型也无法通过 old, older, oldest 之间的关系学到 smart, smarter, smartest 之间的关系。这一方面增加了训练冗余,另一方面也造成了大词汇量问题。
字符级分词方法
这种方法称为 Character embedding,是一种更为极端的分词方法,直接把一个词分成一个一个的字母和特殊符号。虽然能解决 OOV 问题,也避免了大词汇量问题,但缺点也太明显了,粒度太细,训练花费的成本太高,但这种思想或许我们后面会用到。

基于子词的分词方法
基于子词的分词方法(Subword Tokenization),简称为 Subword 算法,意思就是把一个词切成更小的一块一块的子词。如果我们能使用将一个 token 分成多个 subtokens,上面的问题就能很好的解决。这种方法的目的是通过一个有限的词表*来解决所有单词的分词问题,同时尽可能将结果中 token 的数目降到最低。例如,可以用更小的词片段来组成更大的词,例如:
“unfortunately ” = “un ” + “for ” + “tun ” + “ate ” + “ly ”。
可以看到,有点类似英语中的词根词缀拼词法,其中的这些小片段又可以用来构造其他词。可见这样做,既可以降低词表的大小,同时对相近词也能更好地处理。Subword 与传统分词方法的比较:
- 传统词表示方法无法很好的处理未知或罕见的词汇(OOV 问题);
- 传统词 tokenization 方法不利于模型学习词缀之间的关系,例如模型学到的“old”, “older”, and “oldest”之间的关系无法泛化到“smart”, “smarter”, and “smartest”;
- Character embedding 作为 OOV 的解决方法粒度太细;
- Subword 粒度在词与字符之间,能够较好的平衡 OOV 问题;
目前有三种主流的 Subword 算法,它们分别是:Byte Pair Encoding (BPE)、WordPiece 和 Unigram Language Model。
BPE是一种数据压缩 算法,用来在固定大小的词表中实现可变⻓度的子词。该算法简单有效,因而目前它是最流行的方法。BPE 首先将词分成单个字符,然后依次用另一个字符替换频率最高的一对字符 ,直到循环次数结束。实例如下:
#Byte Pair Encoding Data Comperssion Example
1. aaabdaaabac --> ZabdZabac # replace Z=aa
2. ZabdZabac --> ZYdZYac # replace Y=ab
3. ZYdZYac --> XdXac # replace X=ZY
4. XdXac # Final Compressed string
接下来详细介绍 BPE 在分词中的算法过程:
- 准备语料库,确定期望的 subword 词表大小等参数;
- 通常在每个单词末尾添加后缀
</w>,统计每个单词出现的频率,例如,low的频率为 5,那么我们将其改写为"l o w </ w>”:5- 将语料库中所有单词拆分为单个字符,用所有单个字符建立最初的词典,并统计每个字符的频率,本阶段的 subword 的粒度是字符;
- 挑出频次最高的符号对 ,比如说
t和h组成的th,将新字符加入词表,然后将语料中所有该字符对融合(merge),即所有t和h都变为th;- 重复遍历 2 和 3 操作,直到词表中单词数达到设定量 或下一个最高频数为 1 ,如果已经打到设定量,其余的词汇直接丢弃;
注:停止符 </w> 的意义在于标明 subword 是词后缀。举例来说:st 不加 </w> 可以出现在词首,如 st ar;加了 </w> 表明该子词位于词尾,如 we st</w>,二者意义截然不同;
import re, collections
def get_vocab(filename):
vocab = collections.defaultdict(int)
with open(filename, 'r', encoding='utf-8') as fhand:
for line in fhand:
words = line.strip().split()
for word in words:
vocab[' '.join(list(word)) + ' </w>'] += 1
return vocab
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
def get_tokens(vocab):
tokens = collections.defaultdict(int)
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens[token] += freq
return tokens
# vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
# Get free book from Gutenberg
# wget http://www.gutenberg.org/cache/epub/16457/pg16457.txt
vocab = get_vocab('pg16457.txt')
print('==========')
print('Tokens Before BPE')
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
num_merges = 1000
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print('Iter: {}'.format(i))
print('Best pair: {}'.format(best))
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
输出如下:
==========
Tokens Before BPE
Tokens: defaultdict(<class 'int'>, {'\ufeff': 1, 'T': 1610, 'h': 26094, 'e': 59152, '</w>': 101830, 'P': 780, 'r': 29540, 'o': 34983, 'j': 857, 'c': 13891, 't': 44258, 'G': 300, 'u': 13731, 'n': 32499, 'b': 7428, 'g': 8744, 'E': 901, 'B': 1163, 'k': 2726, 'f': 10469, 'A': 1381, 'l': 20632, 'd': 17576, 'M': 1206, ',': 8068, 'y': 8812, 'J': 80, 's': 28320, 'V': 104, 'i': 31435, 'a': 36692, 'w': 8133, 'm': 9812, 'v': 4880, '.': 4055, 'Y': 250, 'p': 8040, '-': 1128, 'L': 429, ':': 209, 'R': 369, 'D': 327, '6': 77, '2': 158, '0': 401, '5': 131, '[': 32, '#': 1, '1': 295, '4': 104, '7': 65, ']': 32, '*': 44, 'S': 860, 'O': 510, 'F': 422, 'H': 689, 'I': 1432, 'C': 863, 'U': 170, 'N': 796, 'K': 42, '/': 52, '"': 4086, '!': 1214, 'W': 579, '3': 105, "'": 1243, 'Q': 33, 'X': 49, 'Z': 10, '?': 651, '8': 75, '9': 38, '_': 1426, 'à': 3, 'x': 937, 'z': 365, '°': 41, 'q': 575, ';': 561, '(': 56, ')': 56, '{': 23, '}': 16, 'è': 2, 'é': 14, '+': 2, '=': 3, 'ö': 2, 'ê': 5, 'â': 1, 'ô': 1, 'Æ': 3, 'æ': 2, '%': 1, '@': 2, '$': 2})
Number of tokens: 98
==========
Iter: 0
Best pair: ('e', '</w>')
Tokens: defaultdict(<class 'int'>, {'\ufeff': 1, 'T': 1610, 'h': 26094, 'e</w>': 17749, 'P': 780, 'r': 29540, 'o': 34983, 'j': 857, 'e': 41403, 'c': 13891, 't': 44258, '</w>': 84081, 'G': 300, 'u': 13731, 'n': 32499, 'b': 7428, 'g': 8744, 'E': 901, 'B': 1163, 'k': 2726, 'f': 10469, 'A': 1381, 'l': 20632, 'd': 17576, 'M': 1206, ',': 8068, 'y': 8812, 'J': 80, 's': 28320, 'V': 104, 'i': 31435, 'a': 36692, 'w': 8133, 'm': 9812, 'v': 4880, '.': 4055, 'Y': 250, 'p': 8040, '-': 1128, 'L': 429, ':': 209, 'R': 369, 'D': 327, '6': 77, '2': 158, '0': 401, '5': 131, '[': 32, '#': 1, '1': 295, '4': 104, '7': 65, ']': 32, '*': 44, 'S': 860, 'O': 510, 'F': 422, 'H': 689, 'I': 1432, 'C': 863, 'U': 170, 'N': 796, 'K': 42, '/': 52, '"': 4086, '!': 1214, 'W': 579, '3': 105, "'": 1243, 'Q': 33, 'X': 49, 'Z': 10, '?': 651, '8': 75, '9': 38, '_': 1426, 'à': 3, 'x': 937, 'z': 365, '°': 41, 'q': 575, ';': 561, '(': 56, ')': 56, '{': 23, '}': 16, 'è': 2, 'é': 14, '+': 2, '=': 3, 'ö': 2, 'ê': 5, 'â': 1, 'ô': 1, 'Æ': 3, 'æ': 2, '%': 1, '@': 2, '$': 2})
Number of tokens: 99
==========
Iter: 1
Best pair: ('t', 'h')
Tokens: defaultdict(<class 'int'>, {'\ufeff': 1, 'T': 1610, 'h': 12065, 'e</w>': 17749, 'P': 780, 'r': 29540, 'o': 34983, 'j': 857, 'e': 41403, 'c': 13891, 't': 30229, '</w>': 84081, 'G': 300, 'u': 13731, 'n': 32499, 'b': 7428, 'g': 8744, 'E': 901, 'B': 1163, 'k': 2726, 'f': 10469, 'A': 1381, 'l': 20632, 'd': 17576, 'th': 14029, 'M': 1206, ',': 8068, 'y': 8812, 'J': 80, 's': 28320, 'V': 104, 'i': 31435, 'a': 36692, 'w': 8133, 'm': 9812, 'v': 4880, '.': 4055, 'Y': 250, 'p': 8040, '-': 1128, 'L': 429, ':': 209, 'R': 369, 'D': 327, '6': 77, '2': 158, '0': 401, '5': 131, '[': 32, '#': 1, '1': 295, '4': 104, '7': 65, ']': 32, '*': 44, 'S': 860, 'O': 510, 'F': 422, 'H': 689, 'I': 1432, 'C': 863, 'U': 170, 'N': 796, 'K': 42, '/': 52, '"': 4086, '!': 1214, 'W': 579, '3': 105, "'": 1243, 'Q': 33, 'X': 49, 'Z': 10, '?': 651, '8': 75, '9': 38, '_': 1426, 'à': 3, 'x': 937, 'z': 365, '°': 41, 'q': 575, ';': 561, '(': 56, ')': 56, '{': 23, '}': 16, 'è': 2, 'é': 14, '+': 2, '=': 3, 'ö': 2, 'ê': 5, 'â': 1, 'ô': 1, 'Æ': 3, 'æ': 2, '%': 1, '@': 2, '$': 2})
Number of tokens: 100
==========
Iter: 2
Best pair: ('t', '</w>')
Tokens: defaultdict(<class 'int'>, {'\ufeff': 1, 'T': 1610, 'h': 12065, 'e</w>': 17749, 'P': 780, 'r': 29540, 'o': 34983, 'j': 857, 'e': 41403, 'c': 13891, 't</w>': 9271, 'G': 300, 'u': 13731, 't': 20958, 'n': 32499, 'b': 7428, 'g': 8744, '</w>': 74810, 'E': 901, 'B': 1163, 'k': 2726, 'f': 10469, 'A': 1381, 'l': 20632, 'd': 17576, 'th': 14029, 'M': 1206, ',': 8068, 'y': 8812, 'J': 80, 's': 28320, 'V': 104, 'i': 31435, 'a': 36692, 'w': 8133, 'm': 9812, 'v': 4880, '.': 4055, 'Y': 250, 'p': 8040, '-': 1128, 'L': 429, ':': 209, 'R': 369, 'D': 327, '6': 77, '2': 158, '0': 401, '5': 131, '[': 32, '#': 1, '1': 295, '4': 104, '7': 65, ']': 32, '*': 44, 'S': 860, 'O': 510, 'F': 422, 'H': 689, 'I': 1432, 'C': 863, 'U': 170, 'N': 796, 'K': 42, '/': 52, '"': 4086, '!': 1214, 'W': 579, '3': 105, "'": 1243, 'Q': 33, 'X': 49, 'Z': 10, '?': 651, '8': 75, '9': 38, '_': 1426, 'à': 3, 'x': 937, 'z': 365, '°': 41, 'q': 575, ';': 561, '(': 56, ')': 56, '{': 23, '}': 16, 'è': 2, 'é': 14, '+': 2, '=': 3, 'ö': 2, 'ê': 5, 'â': 1, 'ô': 1, 'Æ': 3, 'æ': 2, '%': 1, '@': 2, '$': 2})
Number of tokens: 101
==========
可以有效地平衡词典大小和编码后的token数量;随着合并的次数增加,词表大小通常先增加后减小。迭代次数太小,大部分还是字母,没什么意义;迭代次数多,又重新变回了原来那几个词。所以词表大小要取一个中间值。
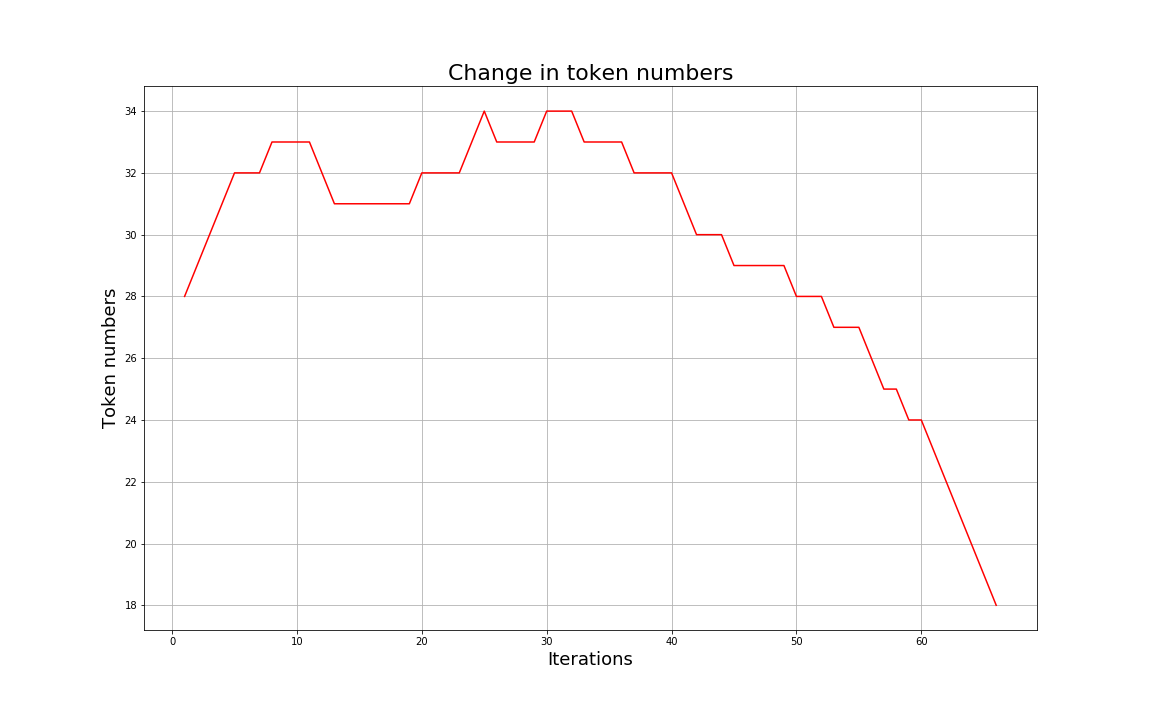
BPE 一般适用在欧美语言拉丁语系中,因为欧美语言大多是字符形式,涉及前缀、后缀的单词比较多。而中文的汉字一般不用 BPE 进行编码,因为中文是字无法进行拆分。对中文的处理通常只有分词和分字两种。理论上分词效果更好,更好的区别语义。分字效率高、简洁,因为常用的字不过 3000 字,词表更加简短。
WordPiece
WordPiece与BPE非常相似,也是每次从词表中选出两个子词合并成新的子词,区别在于,BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。假设句子S=(t1,t2,…tn)S=(t1,t2,…tn) 是由n个字词组成,titi表示字词,且假设各个字词之间是独立存在的,则句子的语言模型似然值等价于所有字词概率的乘积:
设把相邻位置的x和y两个子词进行合并,合并后产生的子词为z,此时句子S似然值的变化可表示为:
可以看见似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息,也就是两个子词在语言模型上具有较强的关联性,它们经常在语料中以相邻的方式同时出现。
Unigram Language Model
Unigram与BPE和WordPiece的区别在于,BPE和Worpiece算法的词表都是一点一点增加,由小到大的。而Unigram则是先初始化一个非常巨大的词表,然后根据标准不断的丢弃,知道词表大小满足限定条件。Unigram算法考虑了句子的不同分词可能,因而能够出输出带概率的子词分段。详细算法可以看原文:https://arxiv.org/pdf/1804.10959.pdf
SentencePiece
上述的所有算法都有一个前提:输入以空格来进行区分。然而并不是所有语言的词语都是使用空格来进行分割(比如中文、日文),一种比较常见的做法是使用预分词。为了更加一般化的解决这个问题,谷歌推出了开源工具包SentencePiece 。SentencePiece是把一个句子看做一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把space也当做一种特殊的字符来处理,再用BPE或者Unigram算法来构造词汇表。比如,XLNetTokenizer就采用了_来代替空格,解码的时候会再用空格替换回来。目前,Tokenizers库中,所有使用了SentencePiece的都是与Unigram算法联合使用的,比如ALBERT、XLNet、Marian和T5.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK