

Yufan's Blog - Graph 图节点的重要性 ( Network Centrality ) 分析
source link: https://alphafan.github.io/posts/graph_centrality.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

[Graph] 图节点的重要性 ( Network Centrality ) 分析
介绍几种最常见的节点重要性的衡量方法以及在实际中的实现方法
Posted by Yufan Zheng on May 10, 2018在真实生活中,我们经常会碰到一些需要从一个网络中挖掘出重要的节点的情况。举几个例子:
- 1. 在社交网络中,挖掘出最具有影响力的人。
- 2. 从流行病传播的网络中,找到重要的病毒扩散的节点。
- 3. 从运输网络中寻找交通枢纽。
- 4. 搜索引擎中,据 Web 页面的重要程度进行排序。
- 5. 寻找防止网络中断的节点。
上述例子中的提到的需要找的节点都是重要的节点,并且很多都是我们在一个图中需要额外关注的地方?
那么问题来了,如何在网络中寻找这样的点呢?比如,下图是一个俱乐部 34 个会员的关系图,哪一些节点比较重要呢?
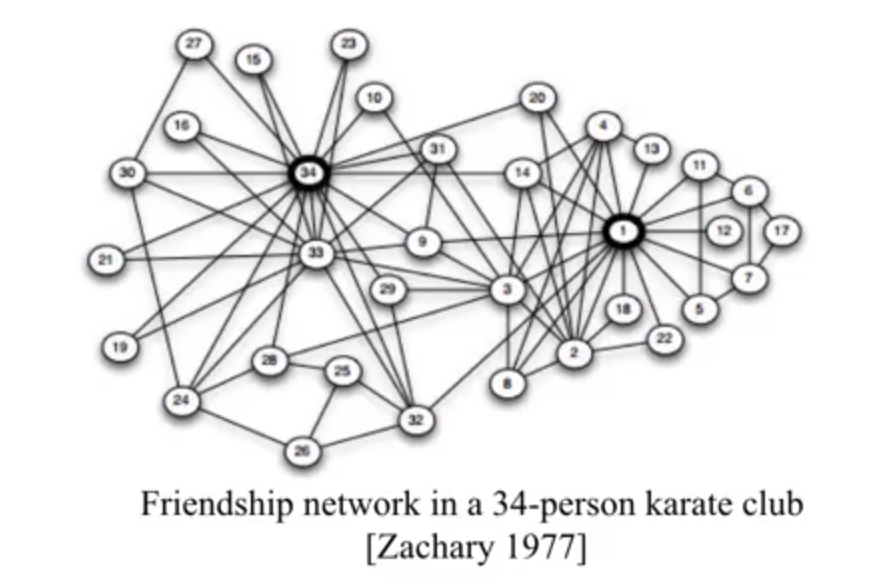
第一种情况,也是最常见的答案,我们可能会觉得 34 号节点和 1 号节点比较重要,因为他们有着最多的连接,意味着他们和最多的人是朋友,所以他们比较重要。
换另外一个角度我们思考了一下,如果我们将这个图聚类成两个部分的话,左边和右边的节点就是靠着 31, 9,和 29 号这几个节点链接起来的,没有他们的话,网络就会断开掉,这么说来的话,他们看上去也很重要。
所以不难看出,如果基于不同的判别条件,找到的图的重要节点也不尽相同。这篇博客将会介绍几种最常见的衡量图节点重要性的参数( Network Centrality ),以及在真实的环境中一些寻找他们的 practical implementation 的做法。
Degree Centrality
Degree 指的是节点的连接数。用一个节点与多少个其他的节点相连来衡量节点重要性的方法叫做 Degree Centrality,这也是最简单有效的方法。它的计算公式如下:

需要稍微注意一下的是,对于有向图,Degree Centrality 分为 in-degree 和 out-degree,它的计算方法通常可以是采用其中一个指标,或者选择两个指标相加。
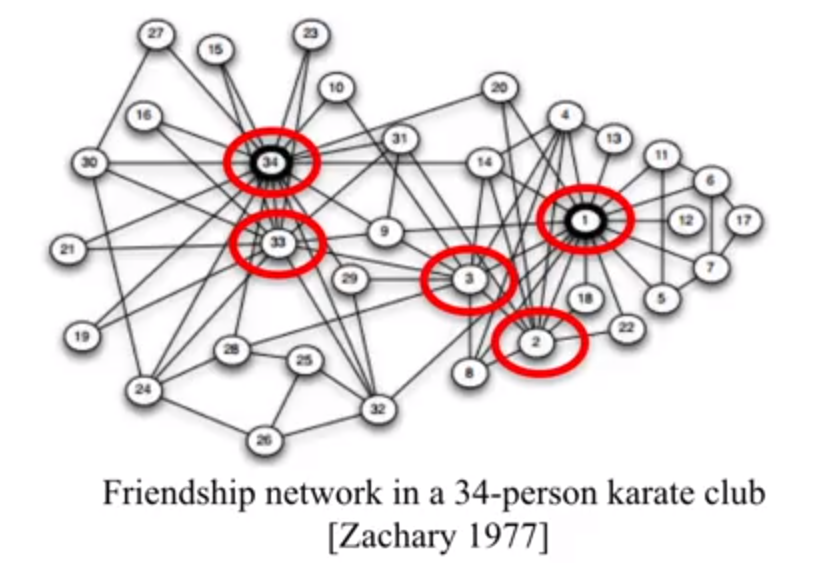
那么根据 Degree Centrality,上图中最重要的五个节点是:34,1,33,3,2。
Clossness Centrality
Closeness Centrality 假设重要的节点会和其他的节点更近一些,评判的指标则是根据该节点到所有其他节点的最小距离的平均值,计算公式如下:

一个特殊情况是,如果一个图中的节点并不能连接到所有其他的节点,那么这个时候,某些只与很少节点连接的节点将会得到很高的权重,这个时候怎么办呢?解决方法是在上面公式前面加上一个 normalizer:
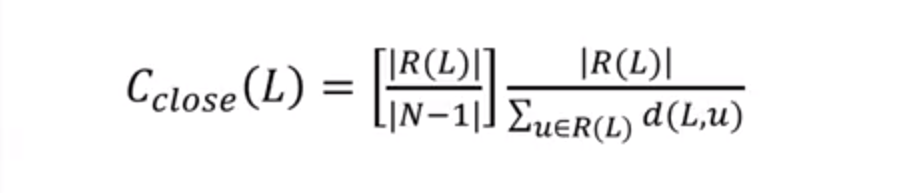
在上图中, R( L ) 指的是节点 L 能连接到的节点数,N 则是在图中节点的总数。加上这个参数后,那些以很短的距离连接很少的节点的重要性就得到了抑制。
Betweenness Centrality
Betweenness Centrality 是根据有多少最短路径有经过该节点,来判断一个节点是否重要的。为什么有这个指标,举个栗子,考虑三国时期的荆州为什么有着那么重要的战略意义,因为它是枢纽嘛,荆州处于孙曹刘三家之间的最短路径上,不走它就意味着绕很多弯路,战略意义不言而喻。

它的计算方法也很简单,计算所有节点对 s 和 t 之间的最短路径中有多少经过了节点 v。计算公式如上图。下面说几个在实际应用中的问题。
第一个问题是关于 normalization 的问题,因为最短路径是两两连接的,所以我们要把上式中计算出来的值,除以图中的边个个数,得到的就会是一个归一化之后的值了:

第二个问题,是有些时候,我们并不想要找连接整个图的重要节点,而只想看连接两个 group 的重要节点,如下图中,我们感觉两个圆圈中对应的是两个不同的团体,我们需要找到是连接这两个 community 的连接点
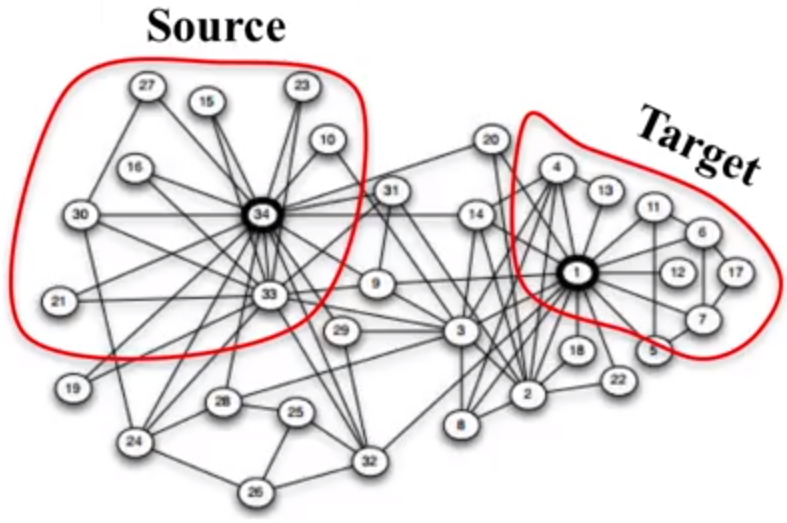
实际上它的计算方法,也是很类似的,只不过就是将最短路径的起点和终点的选择限定在两个 group 中来计算就是了。
第三个问题,关于计算效率。计算 Betweenness Centrality 的复杂度是 O (N3),这个效率非常低下,想象如果一个图中有 1000 个节点的话,需要计算的次数就会达到十亿次。在实际中,我们的做法通常是 做一个 sampling,只计算在这些 sample 中各个节点的 betweenness centrality,用它来估计真正的值。这种方法在 sample 数量稍微多一点的时候,我们也能够得到和计算全部类似的结果。
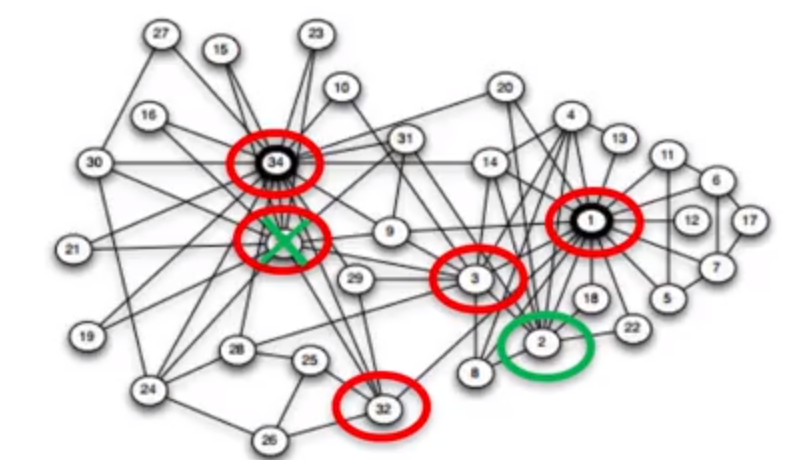
如上图中,我们利用 sampling 找到 betweenness centrality 最大的五个点,只有一个和真实的有出入。
Page Rank
Page Rank 这个算法太有名了,由 Google 的两位创始人发明的算法,当时是为了解决搜索引擎网站排序的难题,解决方案的基本思路是根据有多少重要的网站有链接指向该网站,来决定该网站的重要性,这里就不累述了,基本的计算过程如下图。

这里想详细说一下的是 PageRank 算法在真实应用中的应用版本:random walker。Random walker 算法的核心思路是从任意节点出发,随机的走向它连接的节点,然后重复的一直走着,最后根据访问每个节点的次数计算概率,这个概率的值就是Page Rank的值。
但是Random walker 有一个问题,他会卡在某些死循环的图链接中,举个栗子,在下图中的节点 F 和节点 G 会陷入死循环,一旦进入后,他们会一直不停的指向对方而使得其他的节点在之后的步骤中访问不到,那么最后 F 和 G 计算的 PageRank 的值都会是 0.5 而其他的节点都会是0。
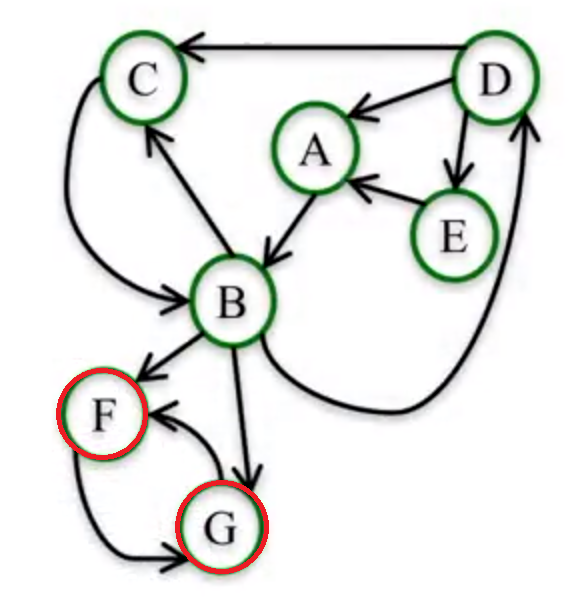
这个问题的解决方案是,在计算 PageRank 的值的时候,额外加上一个参数 dumping parameter,就是说在一定的概率情况下,random walker 会不根据链接的指向来走,而是随机的选择节点访问。这种思路很像遗传退火算法了。正常情况下,这个 dumping parameter 的值,我们会设定为 0.8 到 0.95 之间。
Authorities and Hubs
与 PageRank 类似,Authorities and Hubs 也是根据节点之间的指向来判定节点的重要性的,但它的将这种描述分成了两个部分:Authorities and Hubs
- 所谓“Authority”页面,是指与某个领域或者某个话题相关的高质量网页,比如搜索引擎领域, Google和百度首页即该领域的高质量网页,比如视频领域,优酷和土豆首页即该领域的高质量网页。
- 所谓“Hub”页面,指的是包含了很多指向高质量“Authority”页面链接的网页, 比如hao123首页可以认为是一个典型的高质量“Hub”网页。
所以我们不能看出:
- 1:一个好的“Authority”页面会被很多好的“Hub”页面指向;
- 2:一个好的“Hub”页面会指向很多好的“Authority”页面;
Hubs and Authorities 与 PageRank 的区别是,首先只关注某一部分的网络,然后一点一点的扩展开

那么如何计算页面的 Authorities and Hubs 的值呢?这就涉及到了非常有名的 HITS 算法了
HITS 算法
算法过程如下图
- I.为每个节点分配 Authorities 和 Hubs 初始分数 1.
- 2.应用 Authorities 更新规则:每个节点的 Authorities 分数是指向它的每个节点的 Hubs 分数的总和。
- 3.应用 Hubs 更新规则:每个节点的 Hubs 分数是它指向的每个节点的 Authorities 分数的总和。
- 4.Normalize Authorities 和 Hubs 的分数
- 5.重复k次。
这么说确实太抽象了,我们来看一个计算的例子吧,以计算两遍为例。
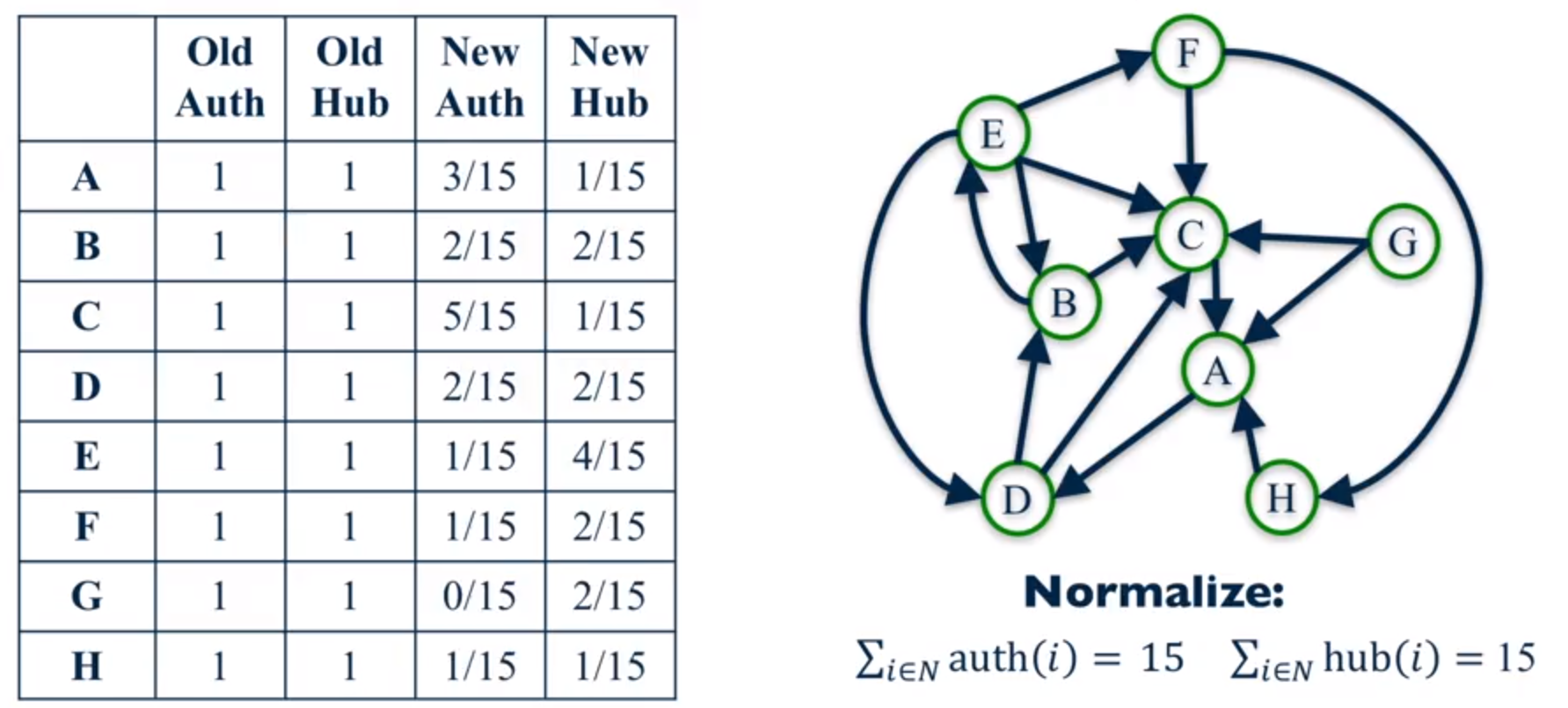
上图是第一遍计算的结果。第一次的初始的 Authority 和 Hub 值都是1,由图的指向性信息算出第一次迭代的值来,最后归一化处理得到最后的值。
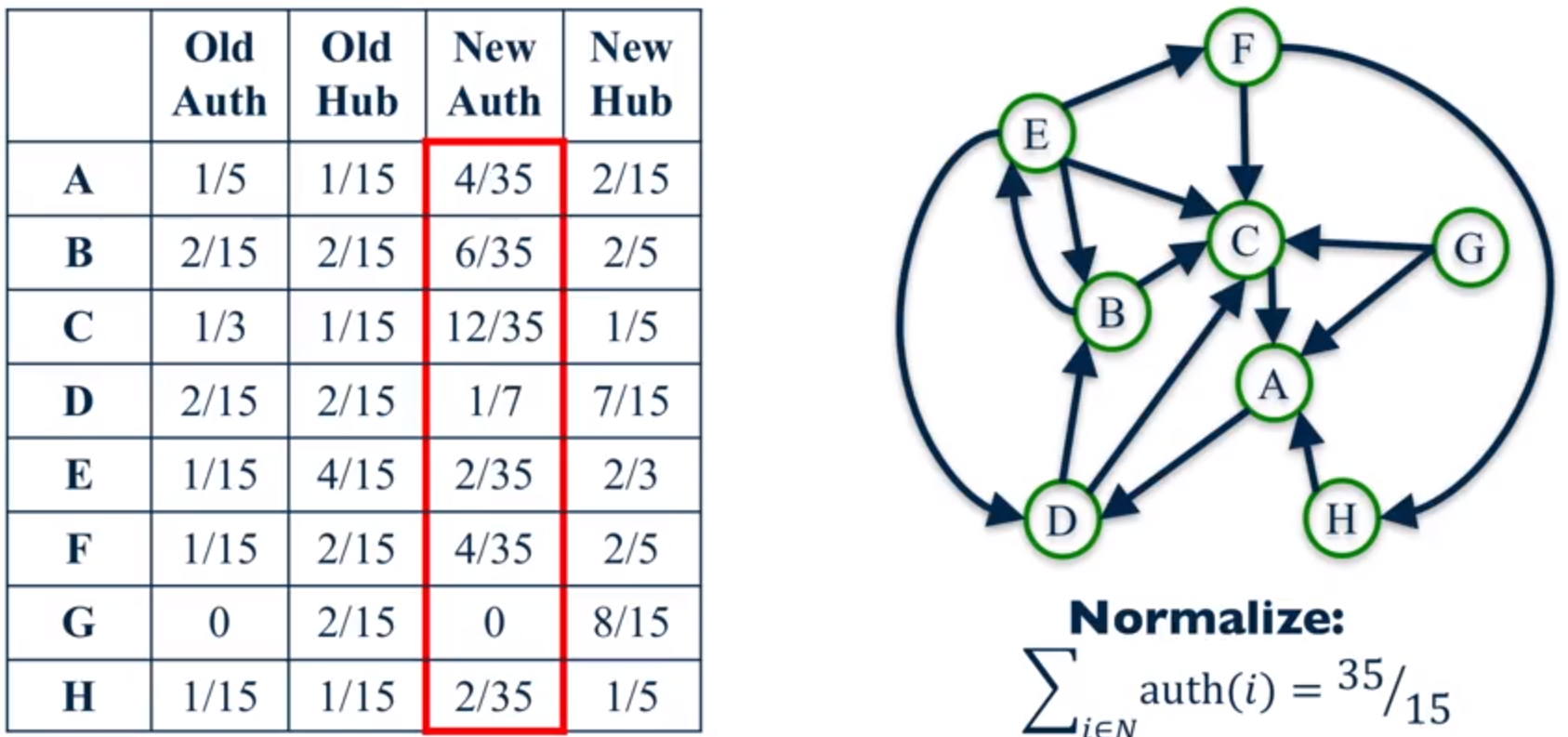

这是第二遍时计算的结果。它的计算过程和第一次类似,也是根绝指向来计算得到的。
HITS算法存在的问题
HITS算法整体而言是个效果很好的算法,目前不仅应用在搜索引擎领域,而且被“自然语言处理” 以及“社交分析”等很多其它计算机领域借鉴使用,并取得了很好的应用效果。尽管如此, 最初版本的HITS算法仍然存在一些问题,而后续很多基于HITS算法的链接分析方法, 也是立足于改进HITS算法存在的这些问题而提出的。
归纳起来,HITS算法主要在以下几个方面存在不足:
1.计算效率较低
因为HITS算法是与查询相关的算法,所以必须在接收到用户查询后实时进行计算, 而HITS算法本身需要进行很多轮迭代计算才能获得最终结果,这导致其计算效率较低, 这是实际应用时必须慎重考虑的问题。
2.主题漂移问题
如果在扩展网页集合里包含部分与查询主题无关的页面,而且这些页面之间有较多的相互链接指向, 那么使用HITS算法很可能会给予这些无关网页很高的排名,导致搜索结果发生主题漂移, 这种现象被称为“紧密链接社区现象”(Tightly-Knit CommunityEffect)。
3.易被作弊者操纵结果
HITS从机制上很容易被作弊者操纵,比如作弊者可以建立一个网页,页面内容增加很多指向高质量网页 或者著名网站的网址,这就是一个很好的Hub页面,之后作弊者再将这个网页链接指向作弊网页, 于是可以提升作弊网页的Authority得分。
4.结构不稳定
所谓结构不稳定,就是说在原有的“扩充网页集合”内,如果添加删除个别网页或者改变少数链接关系, 则HITS算法的排名结果就会有非常大的改变。
HITS算法与PageRank算法比较
HITS算法和PageRank算法可以说是搜索引擎链接分析的两个最基础且最重要的算法。从以上对两个算法的介绍可以看出,两者无论是在基本概念模型还是计算思路以及技术实现细节都有很大的不同,下面对两者之间的差异进行逐一说明。
1.HITS算法是与用户输入的查询请求密切相关的,而PageRank与查询请求无关。所以,HITS算法可以单独作为相似性计算评价标准,而PageRank必须结合内容相似性计算才可以用来对网页相关性进行评价;
2.HITS算法因为与用户查询密切相关,所以必须在接收到用户查询后实时进行计算,计算效率较低;而PageRank则可以在爬虫抓取完成后离线计算,在线直接使用计算结果,计算效率较高;
3.HITS算法的计算对象数量较少,只需计算扩展集合内网页之间的链接关系;而PageRank是全局性算法,对所有互联网页面节点进行处理;
4.从两者的计算效率和处理对象集合大小来比较,PageRank更适合部署在服务器端,而HITS算法更适合部署在客户端;
5.HITS算法存在主题泛化问题,所以更适合处理具体化的用户查询;而PageRank在处理宽泛的用户查询时更有优势;
6.HITS算法在计算时,对于每个页面需要计算两个分值,而PageRank只需计算一个分值即可;在搜索引擎领域,更重视HITS算法计算出的Authority权值,但是在很多应用HITS算法的其它领域,Hub分值也有很重要的作用;
7.从链接反作弊的角度来说,PageRank从机制上优于HITS算法,而HITS算法更易遭受链接作弊的影响。
8.HITS算法结构不稳定,当对“扩充网页集合”内链接关系作出很小改变,则对最终排名有很大影响;而PageRank相对HITS而言表现稳定,其根本原因在于PageRank计算时的“远程跳转”。
Conslusion
这篇博客主要介绍了 5 种不同的衡量节点重要性的指标,并对在实际应用中的计算进行了介绍。注意
- 中心性度量对于作为“中心”节点的含义做出了不同的假设。 因此,他们产生不同的排名。
- 尽管基本没有一对中心度量度生成完全相同的节点排名,但它们有一些共同点。
- 最好的中心性度量取决于人们正在分析的网络环境。
- 选择最重要的中心节点时,通常最好使用多重中心度量,而不是依赖单一中心度量。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK