

Yufan's Blog - NLP 文本关键词的自动抽取
source link: https://alphafan.github.io/posts/kw_extract.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

关键字是一个或多个词的序列,在理想的情况下,关键字以简明形式表示文档的基本内容。它被广泛于各种信息检索系统中,如搜索引擎等。关键词还有一些其他有意思的应用,比如:
- 1. 在文档管理中吗,列出了与主文档关键字相关的文档,并支持将关键词锚定作为文档之间的超链接,使用户能够快速访问相关材料。
- 2. 在医疗领域,通过关键词提取,自动从科学文献中,标注蛋白质的功能。
- 3. 社交网络中,自动的抽取关键词,发现热点话题。
Methods for Auto Keyword Extraction
早期的可自动提取关键词的算法,倾向于利用统计方法来做。例如用单词在单文本中出现的次数,和在整个语料库中的出现的分布进行对比,来进行抽取关键词。著名的 TF-IDF 算法就是基于这种思路来做的。
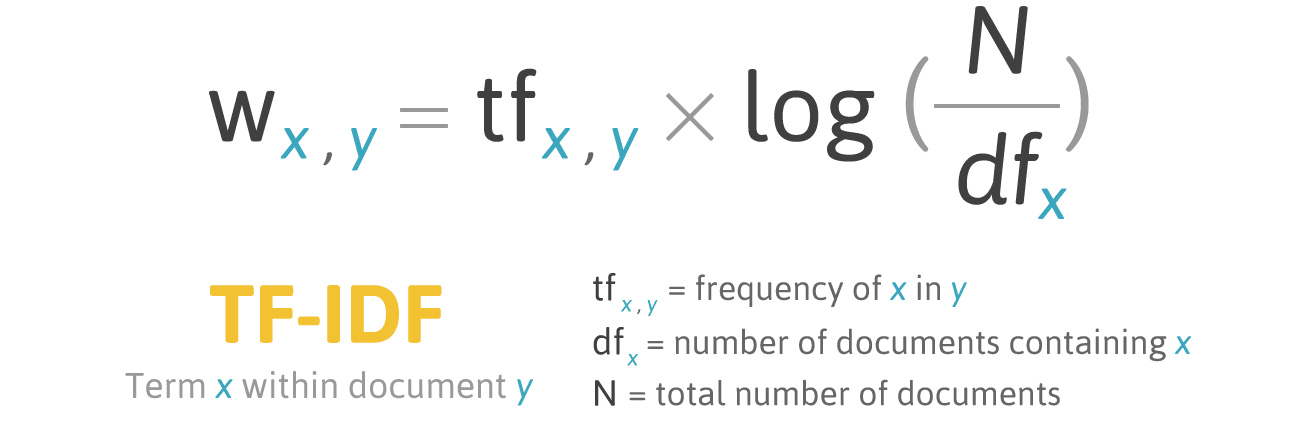
这种基于词频的统计方法,往往是对 “ 单个 ” 单词进行的统计。想要统计多个词组成的词组,如 New York,San Francisco 等,则需要提供专门的词库。如果一个词组没有出现在词库中的词,是无法提取出来作为关键词的。
为了避免这些缺点,出现了一些面向文本的关键词的提取方法。这种面向文档的方法将从文档中提取相同的关键字,而不考虑语料词库的当前状态。一些 NLP 的 features 也被加入了进来来帮助关键词的抽取工作,如 noun-phrase (NP) chunks, n-grams 和 POS tags 等。
例如大名鼎鼎的 TextRank 算法,就运用到了 POS tags 来帮忙选择关键词的 candidates。这些被选取的 candidates 会根据一个固定大小的滑动窗口大小来生成单词共现图(Co-occurrences Graph)。

TextRank 算法会根据图中词与其他词的关联程度来对词的重要性此进行排序,那些和其他词关联得最紧密的词,就是关键词。如上图中红色部分的词,就是分析得到的关键词,通过关键词我们大概可以猜测到它是讲述文档关键词抽取的。TextRank 在如果只选取形容词和名词作为 candidates 的时候,算法会得到最好的效果。
Rapid Automatic Keyword Extraction
正如名字所暗示的,Rapid Automatic Keyword Extraction (RAKE) 算法的一大特点就是快。不同于面向文本的 TextRank 需要迭代收敛,它的计算量很小。
RAKE 算法的基本思路是基于以下的发现:关键字通常包含多个单词,但很少包含标准标点符号或停用词,例如 on 和 of 等。

例如上图中的短文,在我们人手工选择出来的关键词中,只有 set of natural numbers 是包含有 stopword 的。
那么 RAKE 算法的过程也是非常的简单和清楚的。总体来说,分为了四步。
- Step 1. 候选关键词的抽取
首先,文档文本被 stopwords 和标点符号分割成单词序列。这些单词序列被一起被认为是候选关键字。

例如,这就是从上图的文章片段中,我们抽取的候选关键字。
- Step 2. 为候选关键词打分
对于每个文本中的词,统计它出现的频数 freq( w ) ,和与其他词的的共现次数(包括自己)deg( w ),我们可以通过一个矩阵的形式来看,需要求的是什么。
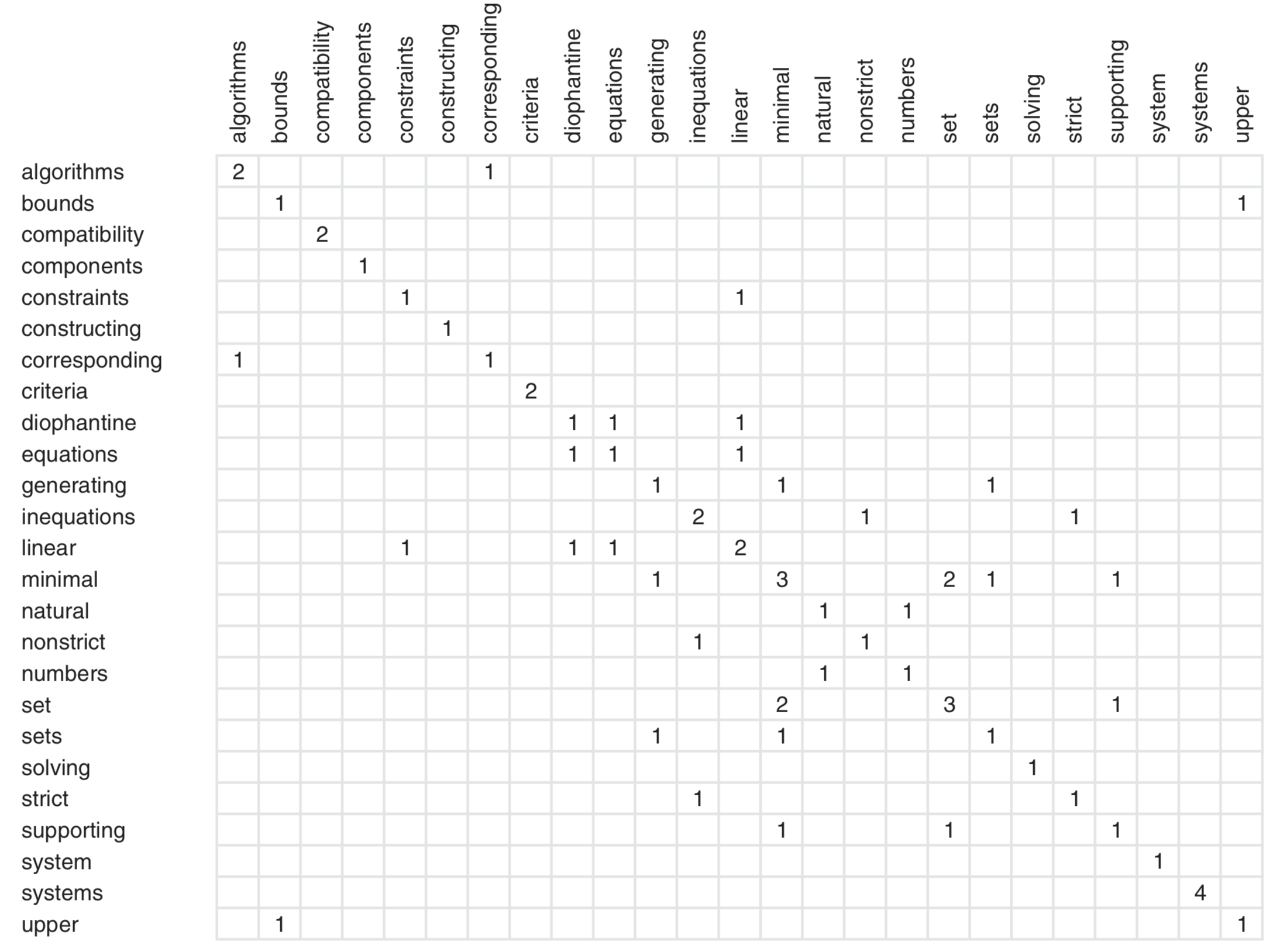
其中对角线上的值,表示的是单词出现的次数,每一条 column 或者 row 的值的和,就是它的 degree。计算结果如下:

简单来说,
- deg( w ) 越高,说明这个词 w 经常与其他词共现在长的候选词中。
- freq ( w ) 无论有多少个词出现在 co-occur graph 中,它只选择出现频率最高的。
- deg( w ) / freq ( w ) 会倾向于选择主要出现在更长的候选关键字中的词。
在 RAKE 中,每个 keyword candidate 的分数,是每一个 candidate 中的 word 的 deg( w ) / freq ( w ) 的和。

上图即是例子中,每个 candidate 和它所对应的分数。
- Step 3. 找到某些可能漏掉的候选关键词
由于 RAKE 通过停用词分割候选关键字,因此提取的关键字不包含内部停用词。虽然 RAKE 由于能够挑选出高度特定的术语而引起了强烈的兴趣,但也有人对识别包含内部停用词(如 axis of evil )的关键字表示兴趣。 要找到这种情况下的关键词,需要查找在相同文档中以 “ 相同顺序 ” 至少 “ 两次 ” 相邻的关键字对。然后创建一个新的候选关键字作为这些关键字及其内部停用词的组合。新关键字的分数是其成员关键字分数的总和。
应该注意的是,这些链接的关键字相对较少被提取,这增加了它们的重要性。 由于相邻关键字必须在文档中以相同的顺序出现两次,因此在短文摘以上的文本中它们的提取更为常见。
- Step 4. 从候选词中抽取关键词。
在计算完候选词的分数之后,对他们进行排序,选择其中前 “ 三分之一 ” 的词作为最终的关键词的结果。
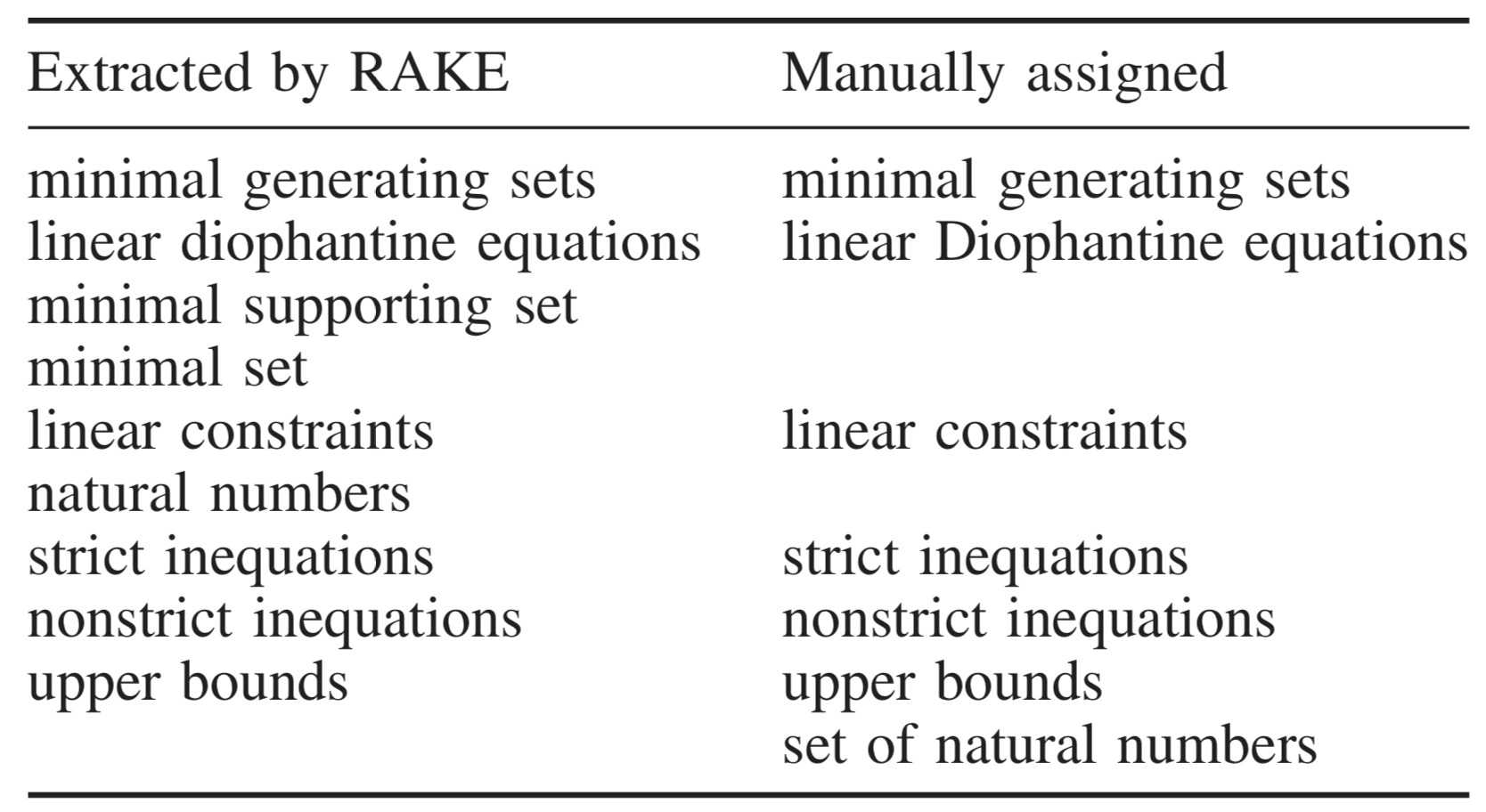
对比一下 RAKE 算法选择出来的关键词,和人手工选择出来的关键词,可以看到它的 FP 是 67%, Recall 是 86%, F-measure 是75%。
Practical RAKE For Chinese
在工作中,我有尝试着用 RAKE 算法进行中文的关键词的自动抽取。发现如果生搬硬套英文的这一种方法的话,效果不会很好。
原因是,RAKE 的选取关键词的方法是用停顿词和标点去切开句子,在英文中 stopwords 出现的概率非常大,如 the, a, of, on 等,它很少会出现一个 keyword candidate 很长的情况。而由于中文句法的原因,如果直接用这种方法去切的话,经常会有一些候选词会包括很多的词,从而导致最后的得分很高(因为 RAKE 的计算是对所有词的得分进行加法)。
为了解决这个问题,首先我尝试的是对计算的分数进行一个 normalize,即是除以候选词中单词出现的次数。但得到的效果反而更糟,其实想想也可以明白,RAKE 这种面向文本的关键词抓取方法,它的初衷就是认为词组作为 keyword 的可能性更大,进行归一化后,就抹去了算法的这一特色,效果变差也是自然。
那么这种太长的 candidate 该怎么处理呢? 我自己的做法,当然,这个不一定是最好的方法了。是对长 candidate 再进行一次切割,再切割的方法就不是根据 stopword 和标点了,而是看词的 POS tags。我人为的认为某些特定的词组才会成为 keyword candidate,如名词性短语(一个或多个形容词 + 名词),动宾结构(名词 + 动词)等。这样再选取一次的话,候选词的长度就短了许多,然后再走一遍 RAKE 算法的时候,效果也提升不少。
RAKE 算法非常的依赖 stopwords 的选定,一个能很好的将无意义的词剔除的 stopwords list 对算法最后结果的性能有很大的提升。我自己的实验是,在不加入明显有意义的词的情况下,stopwords 越多越好。
和 TextRank 类似,RAKE 对于单文本处理的效果会更好,当然,这也很正常,因为多文本会涉及到多主题,主题越多,关键词就越不明显,因为混在在一起做排序的话,最后往往就看不出来有什么关键词的意义了。
At The End
我个人是比较喜欢 RAKE 这个算法的,因为它定义个了一种很容易扩展的框架,大致说来就是三步走:
- 1. 找 candidates
- 2. 计算每个 candidate 的分数
- 3. 排序,选取最高得分的作为关键词
那么,实际上有很多东西是我们可操控的,比如 candidate 的选取,甚至可以采用 NER 选出一定的词,也放入关键词的候选中,也可以用户先 pre define 一些关键词,最后也加入到 keyword 的选取中来。计算分数的方法也很灵活,总之,算法的可提升空间和可调优空间都很大。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK