

一文带你了解数仓智能运维框架
source link: https://my.oschina.net/u/4526289/blog/5438166
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

摘要:本文将针对GaussDB(DWS)内调度器的底层运作原理进行简单说明,并针对调度模式扩容重分布进行介绍。
本文分享自华为云社区《GaussDB(DWS)智能运维框架-调度框架实现原理介绍》,作者: 疯狂朔朔。
随着GaussDB(DWS)的快速发展,GaussDB(DWS)目前集成了众多运维操作,其中大部分运维操作均需占用用户资源,如IO、Mem、CPU、网络、磁盘空间等,且无法依据用户业务负载,自动调整运维负载,因此,如何协调不同运维操作与用户业务之间的资源分配,成为了关键问题。
调度框架实现原理介绍
为解决这个问题,GaussDB(DWS)内设计并实现了运维任务调度器,下图描述了运维任务调度器的基本工作原理。
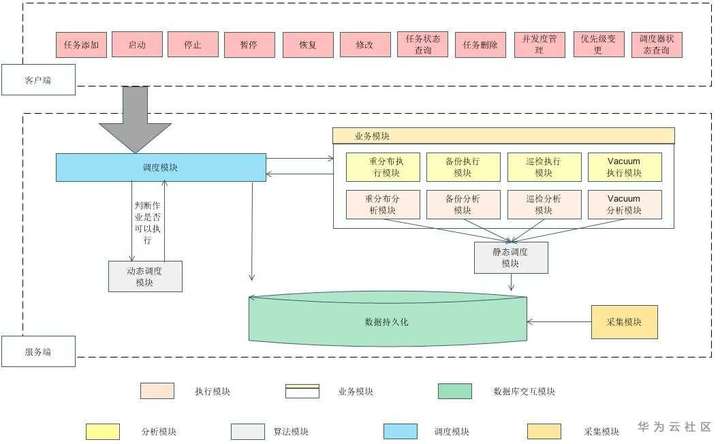
调度器分为客户端和服务端,通过grpc实现通信,调度器客户端的功能在此不做详细说明,可参考另一篇博文https://bbs.huaweicloud.com/blogs/257575。
调度器服务端是整个调度器的核心,主要包括几个核心模块,调度模块、业务模块、动态调度模块、静态调度模块、数据持久化模块和负载信息采集模块,其中业务模块包括业务分析模块和业务执行模块。
调度模块:调度模块主要负责客户端交互、维护调度器、拉起运维任务执行模块。
- 客户端交互:调度器服务端通过grpc与客户端进行通信,调度器启动时将占用默认端口49851,若该端口已被占用,则随机选取空闲端口,并将该端口写入配置文件。客户端启动时,将读取该配置文件,与服务端通信。
- 维护调度器:调度模块内包含一个常驻维护线程,该维护线程负责维护调度器正常执行,该维护线程通过轮询方式执行多个维护项,目前版本维护项包括:
1. 执行模块维护:轮询所有的执行模块,查看执行模块是否已经完成,若完成,则释放该执行模块。
2. 运维任务清理:清理调度器历史数据。
3. 查询调度任务:从数据库中查询当前时间节点是否有需要做的运维任务,并调用动态调度模块,依据集群资源负载情况,判断该运维任务是否可以执行。
动态调度模块:依据集群实时状态,提供调度决策,决定是否执行该运维任务。
- 通常情况下,用户在注册运维任务时,会配置该运维任务执行的时间窗。调度器会从时间窗开始的时间点,调用动态调度模块,判断该运维任务是否可以执行,若不可以执行,则进行下一次轮询判断,若可以执行,则拉起运维任务对应的执行模块。
执行模块:负责运维任务的执行。
- 调度器可同时执行多个运维任务,每个运维任务对应一个单独的执行模块,执行模块之间未实现资源隔离,执行模块之间会争抢集群资源。当执行模块被拉起以后,执行模块从数据库中读取对应的作业,并执行该作业。在执行模块执行完以后,执行模块退出,并等待调度模块执行清理操作。
分析模块:负责运维任务的分析。
- 在用户注册运维任务以后,分析模块将该运维任务拆分为多个作业,并分析每个作业的IO、CPU、MEM负载、执行时长预估等信息,作业信息为静态调度和动态调度提供了调度依据。
静态调度模块:依据集群历史信息,提供静态调度策略。
- 相比于动态调度策略,静态调度策略仅依据集群历史负载信息,对运维任务进行粗略的调度,该运维任务真正被调起的时间实际取决于动态调度。静态调度的意义是,粗略估计运维任务的执行时间,判断用户提供时间窗是否合理。
数据持久化模块:调度器通过调用libpq.so.5.5动态库与gauss内核进行通信。相比于gsql,libpq的通信方式更轻量。
采集模块:负责采集集群信息。
- 采集模块目前仅包括两个采集项,集群IO负载和集群网络负载,其中IO负载通过读取gs_wlm_instance_history实现,网络负载通过读取视图pgxc_comm_status实现。
调度重分布
随着GaussDB(DWS)用户数据的不断增长,用户原有的集群规模,无论从存储容量还是算力,均已经无法满足用户日益增长的业务需求,为提升用户体验,GaussDB(DWS)对外提供了集群扩容方案,该方案中包括以下几个步骤:
- 集群下发:用户购买新机器,此时下发后的新节点处于裸机状态,还无法使用;
- 构建新节点:对下发后的裸机进行初始化,加入到集群中,此时新节点已经加入到集群中,但是用户数据还未搬迁到新节点中,数据处于不均衡状态,新集群的算力还未达标;
- 数据重分布:进行数据搬迁,将数据从老集群重分布到新集群中,算力提升。
在上述三个步骤中,可能会对用户业务产生影响:
- 集群下发不会对用户业务产生影响
- 构建新节点包含两种模式,一种模式为read-only模式,该模式下用户业务必须离线,阻塞用户业务,另外一种模式为insert模式,该模式下用户业务受阻程度较小,阻塞时间为分钟级。通常情况下,构建新节点的时间与用户数据量、用户新增节点数量和CN数量相关,通常为小时级。
- 数据重分布也包含两种模式,read-only模式和insert模式,与构建新节点不同的是,数据重分布时间较长,通常为小时级至天级,具体需要依据用户表数据规模、磁盘类型进行估计。
综上,构建新节点和数据重分布可能会对用户业务造成一定影响,为减少对用户业务的影响,通常用户会选择业务低峰期进行扩容,然而,用户业务低峰期有可能是不连续的,例如说,用户业务低峰期为每天的00:00:00至05:00:00,而数据重分布时长总长为12小时,也就是说用户扩容可能会持续三天,每天只有5小时的扩容时间。为实现该目标,GaussDB(DWS)提供了分段扩容方案,虽然目前分段扩容方案已经逐步成熟,在多个局点取得了良好的效果,获得了用户的好评,但现阶段分段扩容方案依然面临着人力成本投入过高的问题。在分段扩容方案实施过程中,运维人员需要在用户业务低峰期,手动在后台通过命令行执行数据重分布,在用户低峰期时间窗结束时,再手动暂停重分布。
为了解决人力成本投入过高的问题,GaussDB(DWS)利用调度器(https://bbs.huaweicloud.com/blogs/262904)功能,实现了智能扩容方案。相比于已有的扩容方案,调度模式扩容具备以下特点:
- 【调度扩容-时间窗】
在调度模式重分布方案中,用户需预先将重分布时间窗信息写入配置文件,而调度器将自动在指定时间窗内执行重分布,调度器会在每个时间窗开始时,将重分布进程拉起,并在每个时间窗结束时,自动将重分布暂停。
若在所有时间窗耗尽后,重分布依然未完成,将进行告警处理,需要用户重新配置新的时间窗。 - 【调度模式扩容-容错】
在数据重分布过程中,可能会出现集群网络闪断,CN/DN进程重启,或者错表坏表的情况,会导致数据重分布失败。在调度模式扩容过程中,具备一定的容错能力,若发生部份表重分布失败,将跳过失败的表,继续重分布其他表,以避免浪费低峰期时间窗。对于重分布失败的表,需要用户手动修复重分布失败的表,或通知调度器进行重试。 - 【调度模式扩容-并发调节】
通常情况下,重分布会占用用户IO资源,现有扩容方案通过并发数量实现IO资源控制,高并发表示占用IO资源较高,低并发表示占用IO资源较少,现网实施过程中,通常通过手动调整并发数实现IO控制,需要运维人员实时跟踪扩容IO占用。
在调度模式重分布过程中,支持智能并发调节,调度器依据集群IO状态,自动执行并发调节。其中集群IO状态依据木桶原理,以集群中IO负载最高的节点作为集群整体IO。 - 【调度模式扩容-优先级表】
数据重分布支持“早投资早收益”的原则,即重分布完成的表将立即获得算力和容量的提升。因此,在调度模式重分布过程中,支持实时变更修改重分布优先级,用户可以手动指定表重分布顺序,对于用户业务频繁访问的表,可优先重分布,以立即获取算力和容量的提升。 - 【调度模式扩容-表重分布资源估计】
在调度模式重分布过程中,调度器将针对每张表的重分布执行时长进行估计,若当前时间窗不足以完成该表的重分布,则调度器不会针对该表进行重分布。 - 【调度模式扩容-多库并行】
调度模式重分布支持多库并发执行重分布。
调度模式重分布在已有扩容方案的基础上,依据现网扩容实时方案的反馈结果进行改进,主要针对人力成本、易用性进行改善,未来会成为GaussDB(DWS)主流扩容实施方案。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK