

李彦宏不寒碜:不赚钱,做大模型干吗?
source link: https://www.niaogebiji.com/article-672855-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
李彦宏不寒碜:不赚钱,做大模型干吗?-鸟哥笔记
作者|Cindy
编辑|刘珊珊
来源| 极点商业
一位行业领袖对技术路线的断言甚至是“拉踩”,其影响,或许将远超公众预判。
“开源模型会越来越落后。”Create 2024百度AI开发者大会上,一袭白衣的百度创始人、董事长兼首席执行官李彦宏,断言称,“大家以前用开源觉得开源便宜,其实在大模型场景下,开源是最贵的。”
这是数天内,Robin对开源大模型泼下的第二瓶冷水——此前4月11日,李彦宏在内部信中也称,大模型开源意义不大。
作为国内大模型较早入局者,百度在去年3月发布文心一言大模型,选择走闭源路线。一年间,文心大模型已迭代至目前的4.0。
李彦宏观点在行业内引发不小争议,认为以他国内AI布道者地位,不应如此武断。毕竟,开源创新力量几乎被每一位开发者公认,整个互联网都建立在开源基础上,才有了如今信息世界的畅通无阻。

因此也有多位现场媒体人猜测,李彦宏是否在暗指或diss行业其他闭源模型。
“百模大战”如火如荼,行业大佬下场对垒成为常态。如百川智能创始人兼首席执行官王小川,今年3月因李彦宏“文心一言4.0在中文处理上已经超越了ChatGPT 4.0”的表态,与百度高管多次互呛。
自称“开源信徒”的360创始人周鸿祎,截至目前已连续两次(4月13日、4月18日)在公开场合炮轰李彦宏言论,他表示没有开源,就没有Linux、没有互联网,“开源不如闭源好是胡说八道,是忽悠,连说这话支持闭源的公司都是靠开源才发展起来。”
值得一提的是,百川智能、360都是开源大模型。而大模型开闭源之争,也早是业界两大阵营争论话题,从去年7月Llama 2宣布开源可直接商用就已开始,并在最近马斯克起诉OpenAI,要求OpenAI恢复开源并给予赔偿后,掀起广泛争论。
一切技术路线争议终点,是需要商业化挣钱。大模型加速商业化下半场,对“all in”人工智能的百度来说,作为国内最早利用通用大模型会员付费模式,向C端用户收费企业,依靠大模型搞钱想法之迫切显而易见——此前内部信中,李彦宏说得很直接:闭源才有真正的商业模式。才能够真正赚到钱的,能够赚到钱才能聚集算力、聚集人才。
从这个角度看,不赚钱,还做大模型干吗?这并不寒碜。但问题是,仅选择开闭源任一道路,是否在通向极端?开源是否真的落后于闭源?闭源是否能真正代表大模型“商业化”破局之道?
01、开源一直领先闭源?
在李彦宏看来,无论是技术还是商业模式上,闭源模型都会持续地领先,而不是一时领先。
开源和闭源区别上,TechTarget在一篇文章中解释,开源意味着公开AI模型、训练数据和底层代码,闭源则隐藏或保护其中一项或多项。
可以简单理解为,开源模型注重开放、共享和协作,推动大模型创新;闭源意味着源代码仅供拥有它的公司修改和开发,但能更好保护商业利益和技术优势。
从阵营来看,开源阵营远比闭源庞大。目前国内外大模型行业,闭源主要以OpenAI GPT、百度文心一言为代表,开源则是Meta旗下Llama(羊驼)、马斯克旗下 xAI 公司的 Grok-1,以及国内阿里通义千问、百川智能、360、昆仑万维、智谱AI等。其中,有不少企业选择“两条腿走路”,既做开源又做闭源。

从普通用户应用/产品化影响力来看,闭源目前领先开源毫无疑问。李彦宏核心论断之一也是,无论中美,当前最强基础模型都是闭源。
当前“登上神坛”,让很多大模型有绝望感觉的OpenAI,2019年发布GPT-2时还是开源,此后从GPT-3开始转变为闭源,推出“核爆”聊天机器人ChatGPT后,才震惊世界。
最初,OpenAI还公布论文,但到GPT-3.5、GPT-4,连算法、路线、论文都“讳莫如深”。今年初推出Sora时,更是明确表示不分享技术实现细节,只提供模型设计理念及其“炫酷”效果展示。
毫无疑问,大模型赛道近两年繁荣,很大程度上得益于OpenAI带动——倘若没有ChatGPT,不会有如此多科技企业加入大模型赛道,更不会有百花齐放、百家争鸣的行业形态。
在国内,文心一言是闭源代表。根据李彦宏最新公布的数据,文心一言用户数、API日均调用量均突破2亿。百度在大模型赛道初步建立起自己AI生态。
今年格外火爆,引发大模型巨头“围剿”的初创公司月之暗面旗下产品Kimi,也是闭源大模型。
大模型爆炒背景下,以上简单易用、面向To c的闭源大模型可谓尽人皆知,在当下成功占据市场主导地位——但未来是否能保持当下优势,尚未定论。
大获好评的Llama 2后,开源逐渐成为大模型主流趋势,其进化速度越来越快,迅速成为大模型竞争重要一极。
3月底,也就是Grok-1公开后几天后,初创公司Databricks公布旗下开源大模型DBRX,基于混合专家(MoE)架构,在语言理解、编程、数学和逻辑等标准行业上,战胜了Llama2-7B、Mixtral 以及Grok-1。整体性能超越GPT-3.5,编程方面更是轻松击败GPT-3.5。
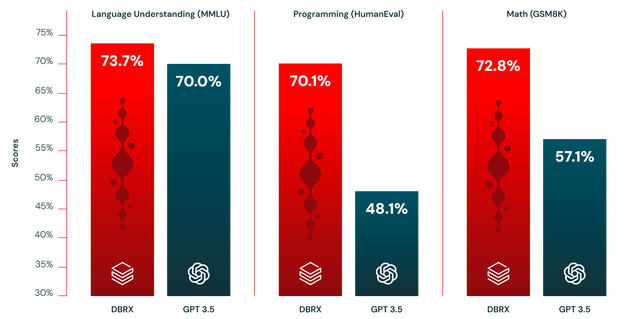
根据最新消息,Meta将在下个月发布Llama 3,支持多模态处理。届时,Llama 3或又将超越DBRX,直接对标GPT-4,复现后者大部分能力。
多位业内人士认为,如无意外,Meta将遵循Llama 2路线,将Llama 3训练数据、训练方法、数据标注等大量细节都公布,成为“任何人都可以拿到模型权重的最强大语言模型”。同样,DBRX为开放社区和企业提供了仅限于封闭模型的API功能。
过去,闭源大模型有“遥遥领先”的参数。如今开源模型参数正越来越大,DBRX参数规模达1320亿,Grok有3140亿,Llama 3预计其大规模版本参数量可能超过1400亿。国内昆仑万维也在4月17日宣布开源4000亿参数的大模型天工3.0,一跃成为全球参数最大开源大模型,号称超越GPT-4V。尽管相比闭源大模型万亿参数有距离,但追赶速度越来越快。所以谷歌工程师说,谷歌没有护城河,OpenAI也没有。
对诸多开源大模型——特别是中国大模型赛道创业者而言,拉平认知的Llama,事实上远比GPT更为重要。不少行业、垂直大模型多是通过对Llama等开源大模型进行微调或修改实现。“如果没有Llama,国内大模型整体水平会被国外甩下不少身位。”
“无需闭门造车,重复发明轮子。”周鸿祎和金沙江创投主管合伙人朱啸虎等均认为,开源社区聚集的工程师和科学家的数量是闭源的数百倍,借助全球技术力量,实现迭代、体验改进和生态扩张。“开源会很快超过闭源。”
但李彦宏并不认可这种说法,他表示大模型开源跟Linux、安卓不同,实际上最主要开发者就是Meta,“不是一个真正大家一起来协同开发的产品。”
02、开源成本真比闭源贵?
两大阵营最激烈交锋,目前发生在马斯克与OpenAI之间——2016年,马斯克还是OpenAI联合创始人、投资人、联席CEO,如今早已彻底走向决裂。
自ChatGPT发布后,马斯克多次暗讽OpenAI,断掉OpenAI对推特的数据访问权限,并在今年2月克起诉OpenAI跟山姆·奥特曼,理由是OpenAI违背了造福人类非营利的宗旨。
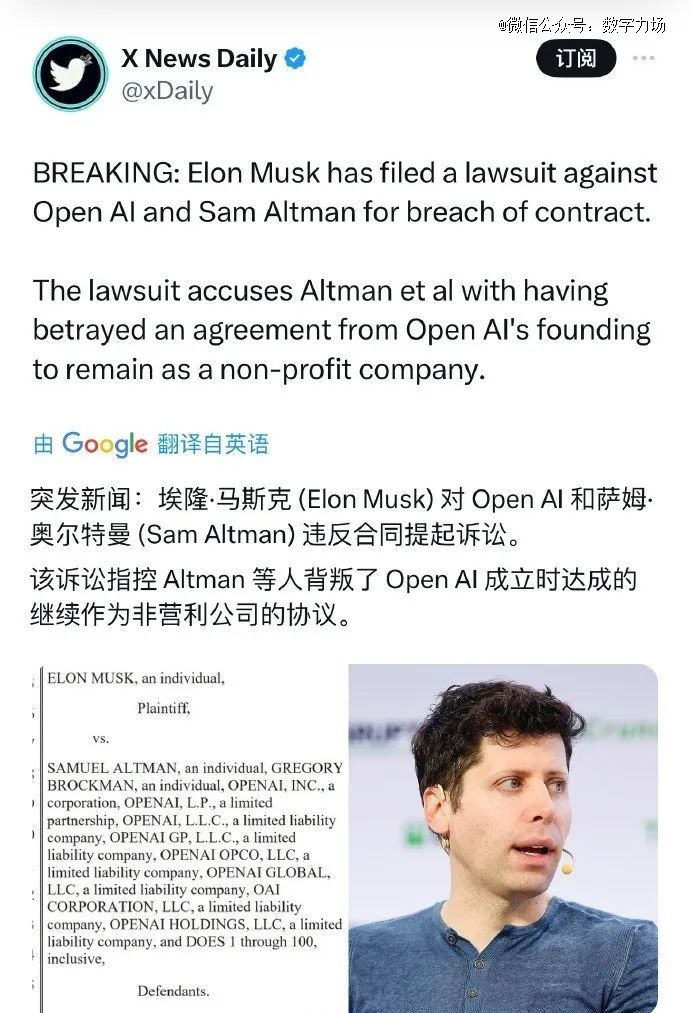
整体来看,伴随两大阵营的交锋态度日益强硬,谁也说服不了谁。开源阵营认为,开源更容易创新,更容易被大众理解和监督,闭源是奉行保守主义,容易权力集中,垄断市场和数据,AI技术发展也会滞后。
闭源阵营则认为,开源模型是套壳,存在滥用风险,无法基于此自行演进,影响某些企业商业化策略,特别是注重安全、隐私的企业。
但从李彦宏论断来看,开源模型会一直越来越落后,核心论点是因为成本更昂贵——这是行业最新争议点,毕竟印象中,开源使用成本更低甚至免费,而且开源成本的高低,从逻辑而言并不等于技术路线的高低。
李彦宏的依据是,基于文心大模型4.0,降维裁剪出来的“小模型”,要比直接拿开源模型调出来的模型,同等尺寸下效果明显更好;同等效果下,成本明显更低。
这话有一定道理,此前有业内人士就在X平台表示,Grok-1没有对特定任务进行微调,普通用户使用它的基础门槛并不低。如何开源、什么可以开源、开源到何种程度仍有待实践回应。
但也有中小开发者表示,尽管Llama2的开发和使用并没有完全面向全体公众开放,但对中小开发者也非常友好,只需一台PC就可以零代码微调大模型,花不了多少钱,且性能并不差。
事实上,业内公认的是,当前大模型技术路线都未成熟,包括ChatGPT也出现过将三星机密资料外泄严重事件。开源闭源各有利弊,“两条腿走路”才是目前大部分公司的选择,即构建一系列AI模型,既有闭源也要开源。
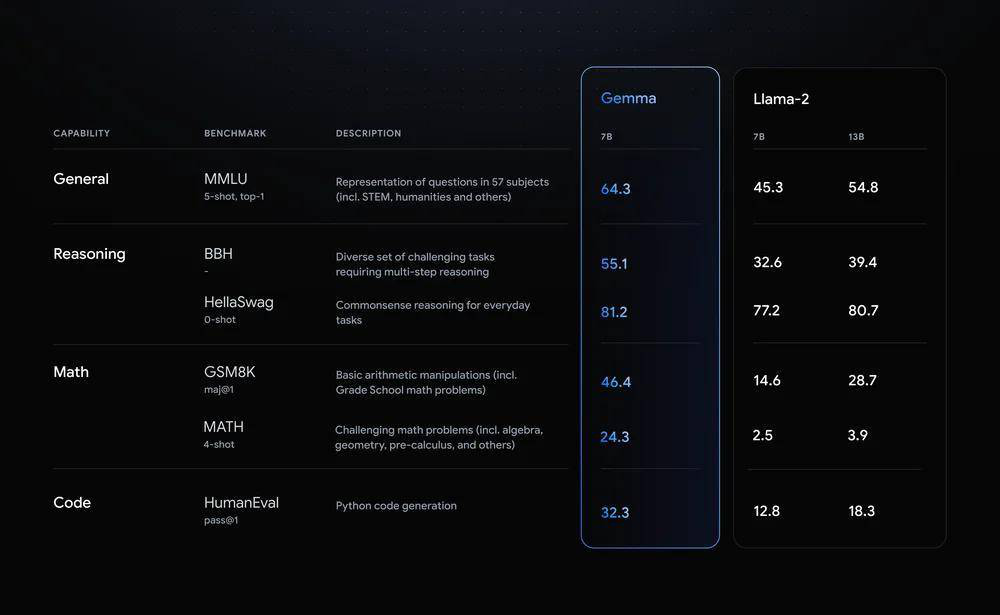
比如微软130亿元投资了OpenAI,但也扩大了开源ONNX Runtime投资力度,以及下场推出开源Phi大模型;谷歌也是从过去押注坚持闭源,在今年2月突然推出“开源”大模型 Gemma,双线作战去对抗OpenAI和Llama。
在国内,兼顾开源闭源的大模型更多。比如阿里通义千问,虽然以开源为主,但也有闭源模型,去年12月进阶至2.1版。包括百度也是如此,去年发布的文心千帆大模型平台2.0,就接入了30多个主流大模型,包括Llama2等诸多开源大模型。

可以说,没有开源大模型,就没有如今百度智能云生态的成熟,在千行百业的落地——根据最新数据,文心千帆大模型生态伙伴数量过去半年增长 5 倍,API 调用量指数级增长,超8.5万客户,300多款进入千帆应用市场。对这些用户和开发者而言,表面是在文心一言上,实际用到的也很可能是Llama2等开源模型。
既然如此,李彦宏为何还会多次断言,开源大模型会一直落后?
有业内人士就认为,这或许与百度当下大模型的战略定位,以及需要为产品工具宣传背书直接相关。
“以后人人都是开发者。”Create 大会上,李彦宏给出AI时代答案的同时,也发布了被广泛宣传的三大AI“开发神器”——AgentBuilder、AppBuilder、ModelBuilder,将个人、企业、开发者统统囊括在百度体系内,加速抢占应用入口,甚至是基础模型通吃AI,构建国内最强大大模型生态的“野心”。
“如果说开源大模型开放且正逐渐强大,那么有多少人还愿意给闭源大模型送钱,甚至是加入受控制的生态体系?”一位网友评论说,长期以来,全球开发者对苹果iOS封闭生态系统的“霸道”行为,深感不满却又无可奈何。
03、利用大模型赚钱,百度跑在前面
实际上,在大模型下半场,探索商业化路径成为所有玩家亟待选择的问题。
在这方面,李彦宏相当坦诚,表示百度之所以坚持闭源,是因为市场有足够多的开源,百度要开源还得自己去维护一套开源版本,从成本来说非常不划算。更重要的是,闭源有着真正的商业模式,能够赚到钱。

大模型当前如何商业化,或者说赚钱?尽管各大模型还在探索ToB还是ToC的不同路径,但重点布局方向都是“脱虚向实”,向“应用为王”倾斜。
这一点,从李彦宏、周鸿祎或者其他行业大佬、专家表态来看,已成共识。
大模型商业化如何变现答案上,“all in”姿态的百度堪称行业样本,在国内跑在最前面。
B端,构建“文心千帆”一系列商业化矩阵,为客户产品嫁接文心大模型能力,通过调用API调取实现营收。
这种收费方式可以简单理解为,模型租赁。360、阿里通义千问、腾讯混元、科大讯飞星火等通用大模型,以及更多行业大模型也有类似尝试,但当前大模型工具推动千行百业生产力进步还需要过程,且门槛更高(如针对各行各业的定制化服务),基于tokens(“字”或“词”)计价方式的ROI(投入产出比)各家并不算高,更多是通过API的绑定,向客户出售云、广告等其他服务。
李彦宏曾在2023年财报会中披露,去年Q4百度智能云总营收84亿元,其中大模型为云业务带来约6.6亿元增量收入,同时文心大模型重构后的广告系统,为百度带来数亿元增量收入。根据李彦宏的预计,上述两项增量收入,将在2024年增加到数十亿。或许,这会成为百度智能云加快追赶阿里云、华为云等的希望。
更值得一提的是C端。在国外,ChatGPT率先推出收费Plus服务;在国内,百度紧随其后,率先在C端推出了“文心一言”会员订阅模式。
目前,文心一言3.5基础版仍可免费使用,只是体验并不完美。能力更强的4.0则需要升级成会员,会员服务有两种,分别是单独的会员服务和联合会员服务。
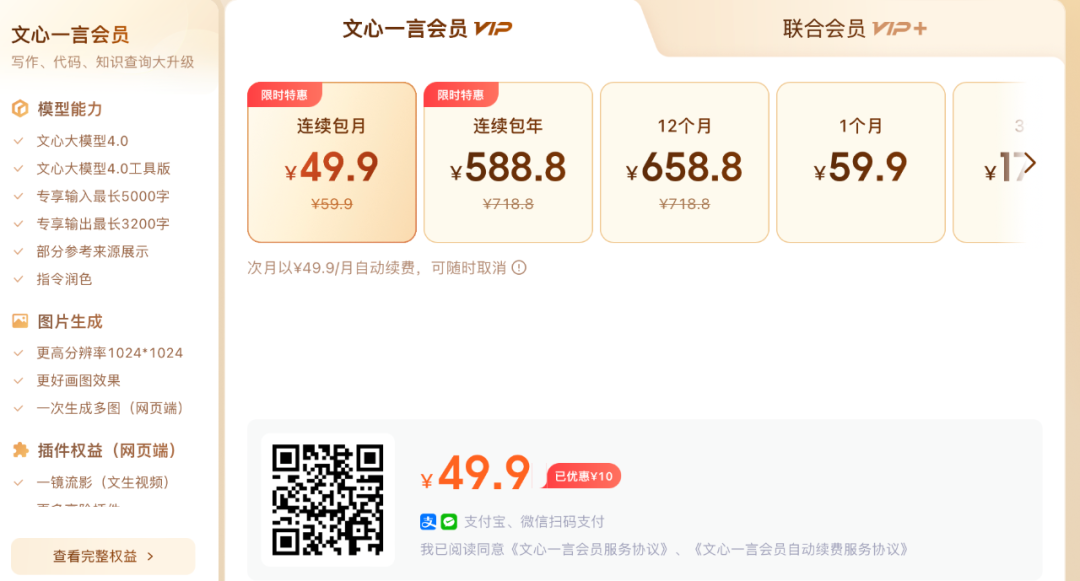
单独会员服务价格上,连续包月优惠价为49.9元,单月购买价格为59.9元,连续包年588.8元,12个月658.8元。选择这种会员服务,用户将能够体验文心大模型4.0的高级服务,比如更强的模型能力和图片生成能力。
此外,百度还推出了文心一言4.0与文心一格白银的联合会员服务,限时特惠价为99元/月。除文心大模型4.0服务外,用户还可以获得文心一格白银会员的权益,包括极速生成多尺寸高清图像、创作海报和艺术字,以及AI编辑改图修图等功能。
不过,这也引起了部分用户的争议。虽然会员付费是互联网行业常见盈利模式,但像大模型会员这么贵价格的比较少见,比如闹得沸沸扬扬的爱奇艺,多次涨价后会员包月价目前为每月25元。
如此贵的会员费,业内人士认为大部分是AI 知识工作者、开发者等买单,从普通用户角度看,如果一年用不上几次,购买并不合适。
但客观来看,如今生成式AI产品收费是大势所趋,且大模型会员价格贵,和服务器、芯片、训练、电费等高额成本有关,如果不收费,以百度的弹药储备,恐怕也难以支撑烧钱多久。
从财报来看,大模型C端会员收费并未在百度最新财报中有所体现,有多少用户付费难以得知。但无论是B端还是C端的AI故事,想真正体现更大提振效应,还需要很长的路要走。2023年百度总营收1345.98亿元,在线营销贡献751亿元的收入。
这不只是百度的问题。目前能从AI身上赚到钱的公司并不多,百度已经算是其中佼佼者,一是迅速推动旗下大部分产品和大模型的融合,二是文心一言、百度广告、智能云、自动驾驶等领域,都开始有了来自AI的落地收入,AI商业化布局呈多元化态势。
OpenAI成功,首先是商业模式的成功。2022年全年,OpenAI收入仅为2800万美元。今年2月有外媒称,OpenAI的年化收入已超过20亿美元,其估值达惊人的1000亿美元。一些OpenAI的领导认为,到2024年年底,该公司年化收入可以达到50亿美元。
在商言商,只要未被利益蒙蔽双眼,因商业利益而为自家产品、技术路线强硬站台,无可厚非。
对李彦宏和他的百度来说显然也是如此,其既不是发布会上鼓吹的“让人人都是开发者”的那样高尚,也不是周鸿祎反驳中的“胡说八道和忽悠”。区别,在于企业路线,在于未来策略。包括马斯克和OpenAI 的决裂,本质同样如此。

当然周鸿祎有一点没有说错,那就是OpenAI、文心一言也是自开源成长起来——如今所有主流大模型的核心机制(包括开源、闭源),都是基于Transformer架构,热潮起点则源自2017年的谷歌,其发表了《Attention is all you need》的经典论文,对Transformer模型做出了具有历史意义的重大改进,有了Transformer框架下的“不可能三角”(并行训练能力、性能和低成本推理),才有了后来的GPT。
从这个角度看,AI和大模型注定引领一场新工业革命的当下,断言某一种技术路线会一直落后,也是一种极端。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK