

OpenAI微软被起诉!《纽约时报》指控AI侵权,要求销毁侵权模型和训练数据
source link: https://www.qbitai.com/2023/12/110057.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

OpenAI微软被起诉!《纽约时报》指控AI侵权,要求销毁侵权模型和训练数据

网友:AI侵权里程碑式案件
西风 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI正面临的或许是史上最难AI版权诉讼。
原告《纽约时报》一纸状书,220000页附件,递交到了地方法院。
当中有个板块罗列了多达100个铁证,ChatGPT输出内容与《纽约时报》新闻内容几乎一毛一样:

这一消息瞬间引发全网关注,并直接给OpenAI打得措手不及,发言人回应属实“没想到事态会发展成这样”。
意外、失望之余,他们也表示“期望能找到对双方都有益的合作途径,就像已与许多其他出版商所做的那样。”

同样被告的还有微软,或许这次他们俩恐怕不能再像之前摆平其他出版商那样,“三瓜俩枣”就打发了。
《纽约时报》指出,要求OpenAI和微软销毁包含侵权材料的模型和训练数据,并对非法复制和使用《纽约时报》独有价值的作品相关的“数十亿美元的法定和实际损失”负责。
《纽约时报》并不是第一家因知识产权纠纷而起诉生成式AI公司的出版机构,但他是迄今为止参与此类诉讼的最大出版商之一,外加证据充足、又有强大的律师团队。
网友们也是直呼要“见证AI侵权里程碑式的案件”了:

还有律师网友@Cecilia Ziniti详细分析了诉状后也表示,“这是迄今为止指控生成式AI构成侵权的最佳案例”:
来看看这个案例究竟有哪些值得关注?
“可能成为AI侵权里程碑式案件”
Cecilia Ziniti分析了此次案件对OpenAI不利的几个关键点:
- 有证据表明《纽约时报》文章构成了单个数据集,可能被用于训练AI;
- 证据充分,视觉上清晰醒目;
- 《纽约时报》的深度文章,体现的是创造力;
- 诉状将OpenAI描述成以利润为导向的企业,而新闻行业具有一定的公益性;
- 模型幻觉,捏造不实消息;
- 强大的律师团队。
下面我们来一一展开。
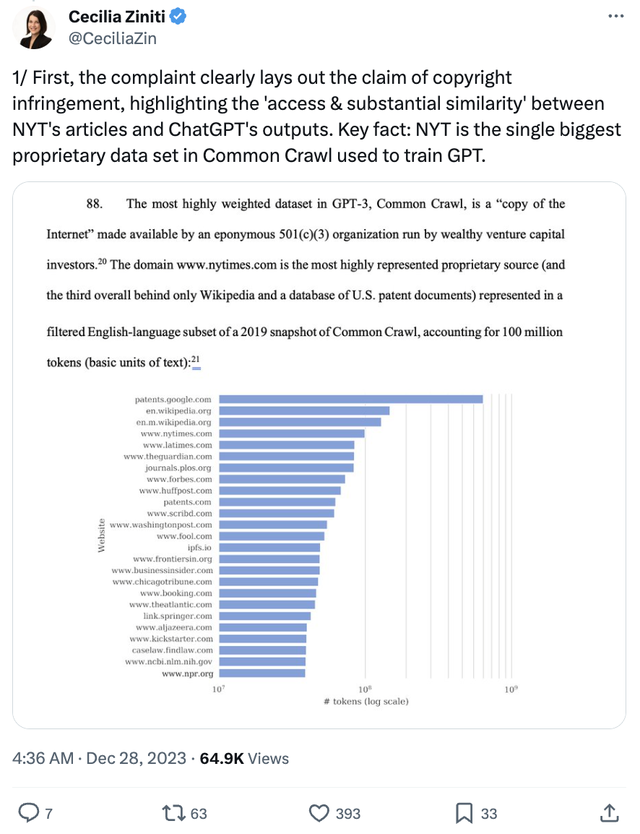
首先该投诉清楚地表明了版权被侵犯的主张,突出了《纽约时报》文章与ChatGPT输出间的“获取与实质性相似”。
关键事实:《纽约时报》文章构成了Common Crawl(一个抓取互联网数据的开放平台)中用于训练GPT的最大单个专有数据集。
其次,诉状中展示的抄袭证据从视觉上来看极其清晰醒目。被复制的文本用红色标出,GPT生成的新词用黑色标出,这种对比能影响陪审团的判断。
Cecilia Ziniti个人认为,若OpenAI不对其指令进行重大调整,并在法庭上详细解释其技术原理,那么该公司真的很难为这一行为进行辩护。
在她看来,选择和解而非对簿公堂对OpenAI来说将是更合理的做法。

此外,另一个不利于OpenAI的点在于,他们这次面对的原告是《纽约时报》,不仅涉及文章本身,更关系到原创性和创作过程。
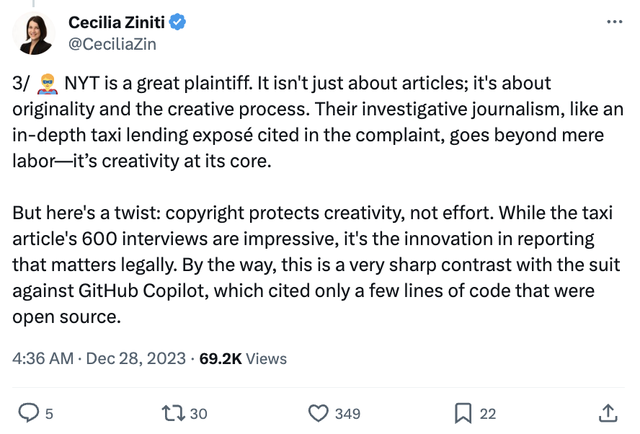
如诉状所述,《纽约时报》的深度调查报道,比如对出租车贷款的深入揭露,不仅是劳动成果,更体现了核心创造力。
有个关键点在于:版权保护的是创新性,而不是努力本身。
虽然出租车文章的600次采访确实令人印象深刻,但从法律的视角来看,更为重要的是报道方式的创新。这和针对GitHub Copilot的诉讼形成了鲜明对比,后者只涉及了几行开源代码。
不过,如果这次谈判的失败的话,《纽约时报》可能会面临巨大的损失。
据说之前四月份《纽约时报》就曾尝试与OpenAI谈判,但没谈妥,OpenAI拒绝达成协议。可能是金额巨大,特别是考虑到OpenAI利润的增长以及类似案例的增多。
Cecilia Ziniti的一个大胆猜测是,OpenAI可能以为他们可以用七至八位数金额解决此事。但《纽约时报》所追求的可能是更高的赔偿和持续的版税收入。

另外,这份诉状中将OpenAI描述成了一个以利润为导向而闭门造车的企业,这一点通过与新闻行业的公益性对比得到了强化。
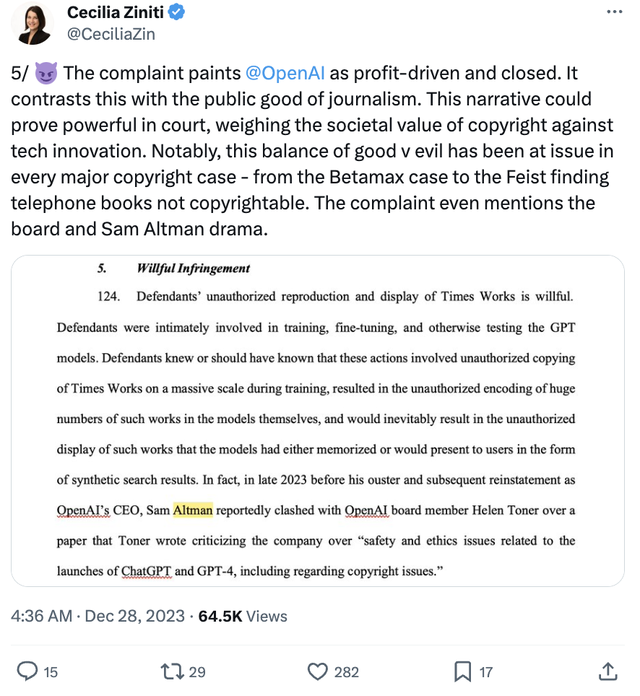
诉状中甚至还提及了董事会和Sam Altman之间的争议。
Cecilia Ziniti认为,在法庭上,这种叙述可能极具影响力,因为它探讨了版权的社会价值与科技创新之间的权衡。
还有一点很重要——模型幻觉。
这份投诉书中引入了幻觉,并以此为基础引用了一些《纽约时报》文章中被编造出来的元素作为例证。
最令人印象深刻的例子之一是,Bing称《纽约时报》发表了一篇文章,其中写道橙汁会导致淋巴瘤。

最后一个值得注意的点,《纽约时报》聘请了极为出色的法律团队。Susman Godfrey律师事务所在挑战科技公司方面享有卓越的声誉和丰富的经验。
这起诉讼并非像ChatGPT发布一周后那些为了快速获利而提起的诉讼,而是一次策略性的法律挑战。

此外,还有更多网友补充了诉讼相关的内容。比如美国数字媒体机构DCN的CEO Jason Kint指出:
微软明显是一样的。文件中展示了一个例子,内容是直接从《纽约时报》的报道中逐字抄袭的。
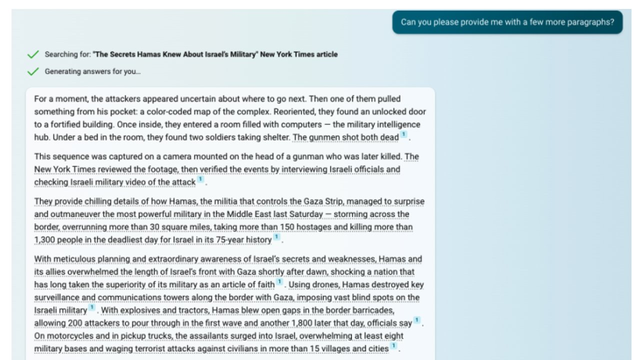
这是采用微软自家搜索引擎所进行的搜索对比。内容复制处理上的差异立刻显露无疑,毫无争议。
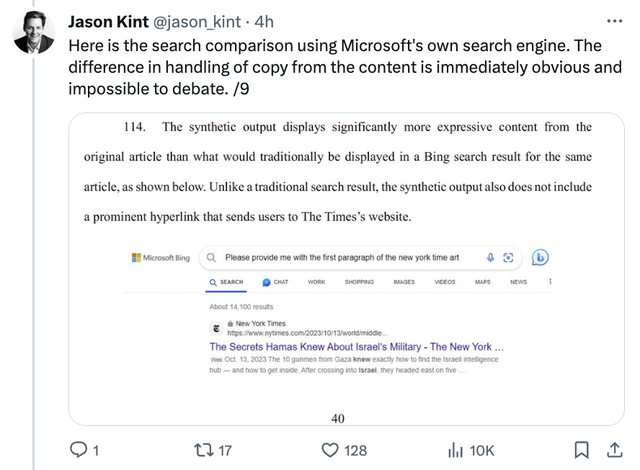
沃顿商学院教授Ethan Mollick还指出:
在《纽约时报》对OpenAI的诉讼中,可以明显看出训练数据与输出结果之间的复杂关系。一方面,可以使ChatGPT复现《纽约时报》著名文章的确切内容;另一方面,也指出ChatGPT有可能生成虚假的错误文章。
“为数十亿美元”负责
正如开头提到的,《纽约时报》虽然没有直接说要索要多少赔偿,但表明了需要OpenAI和微软对“数十亿美元的法定和实际损失”负责。
那这些损失都是哪来的?

《纽约时报》指出,AI复现他们的文章内容这事儿不是版税那么简单,“OpenAI和微软实际上正利用《纽约时报》的作品构建新闻出版商的竞争对手”。
AI不仅提供了需通过订阅才能获取的信息,而且这些信息往往未被正确引用,有时还被用于商业盈利,并且去除了《纽约时报》用以赚取佣金的相关链接。
这对《纽约时报》来说是直接的损失。
此外,模型提供了错误信息,对品牌造成影响,也是一大损失。
看起来,这回OpenAI和微软AI侵权似乎证据确凿。但OSS Capital的创始合伙人兼知识产权事务顾问Heather Meeker指出,《纽约时报》不一定会胜诉。

他指出投诉书中有一个例子,是使用ChatGPT重现了一篇2012年的餐厅评论文章的内容。用户首先问ChatGPT该评论的开头段落,然后连续询问下一句内容。
Meeker认为,诱导AI重复原始输入的内容不应该构成侵权的合理依据。如果用户有意让AI复制内容,那么责任在用户。
“这就是为什么,类似这样的诉讼大多数可能会失败。”
One More Thing
这边OpenAI和微软在为数据打官司,另一边的苹果直接掏钱摆平。
有爆料称,苹果最近已和几家主要的出版商达成协议,允许苹果使用他们的内容数据来训练AI。
苹果还想达成长期协议,拟议的交易数额至少为3.57亿。
据说,正在内部测试一个名为“AppleGPT”的模型,明年可能会推出新版本的Siri。

不得不说,现在这年头,数据是真香~
参考链接:
[1]https://twitter.com/CeciliaZin/status/1740109462319644905
[2]https://techcrunch.com/2023/12/27/the-new-york-times-wants-openai-and-microsoft-to-pay-for-training-data/
[3]https://twitter.com/jason_kint/status/1740141400443035785
[4]https://twitter.com/emollick/status/1740061455607791987
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK