

四年了,基础开源模型没有真正进步,指令调优大模型评估惊人发现
source link: https://www.51cto.com/article/757616.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

四年了,基础开源模型没有真正进步,指令调优大模型评估惊人发现
指令调优大语言模型的出现标志着 NLP 领域迎来一个重要转折点。从 ChatGPT 这类会话助手到解决复杂问题,这些指令调优大模型的变革能力在应用中瞩目。此类模型还包括 GPT-4,它的精通范围不局限于语言理解,还能解决数学、编码、医学和法律等不同领域的任务。
虽然它们具有非凡的能力和适应性,但其全部潜力仍有待全面了解。这种情况主要源于许多模型的黑箱性质以及目前缺乏深入和全面的评估研究。
为应对这些挑战,并对模型的能力进行更加深入的了解,新加坡科技设计大学和阿里达摩院(新加坡)的研究者提出了一个新的评估套件 INSTRUCTEVAL。该套件用于对指令调优大语言模型进行全面评估,并且超越了早期评估方法的限制。评估策略在其系统和整体方法上与之前的研究大不相同,不仅审查了模型的解决问题和写作能力,还严格评判了它们与人类价值观的一致性。

- 论文地址:2306.04757.pdf (arxiv.org)
- GITHUB 地址: https://github.com/declare-lab/instruct-eval
- LEADERBOARD 地址: https://declare-lab.github.io/instruct-eval/
评估方法的核心是考虑影响模型性能的各种因素,包括开发模型的预训练基础、用于改进模型的指令调优数据的性质和质量、以及采用的具体训练方法。通过对这些因素慎微的探究,研究者试图阐明决定模型性能的关键因素,进而理解如何更好地利用这些模型来满足我们的需求。
本文的研究发现强调了指令数据质量对模型性能缩放的关键影响。开源模型已经展现出令人惊叹的写作能力,这表明它们有潜力为各种领域做出非凡贡献。当然,本文的研究也有相当大的改进空间,特别是在模型的解决问题能力和与人类价值观的一致性方面。这一观察强调了整体评估和模式开发的重要性。
开源指令 LLM
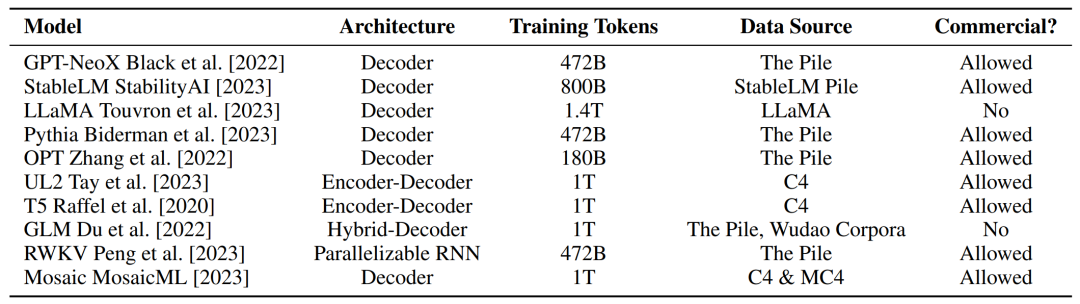
研究者在下表 1 中收集了开源基础 LLM 的细节,并考虑到了模型架构、大小和数据规模等预训练因素。
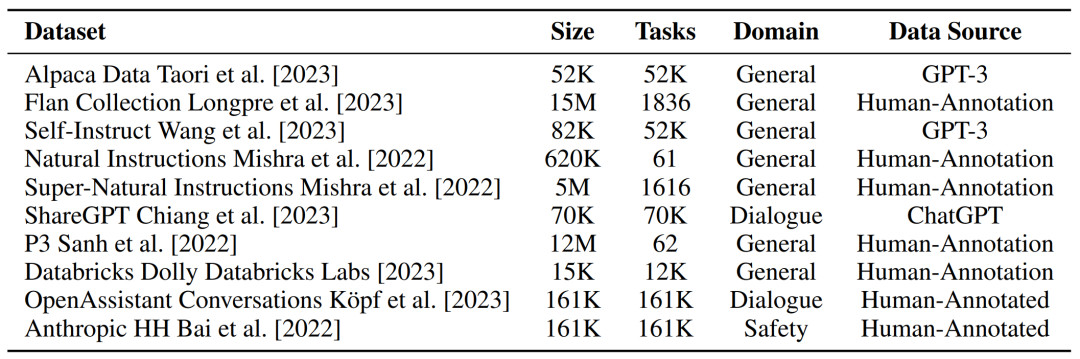
可以说,指令调优的核心是用于训练基础 LLM 的指令数据,比如质量、数量、多样性和格式等都是可以决定指令模型行为的因素。研究者在下表 2 中收集了一些开源指令数据集的细节。
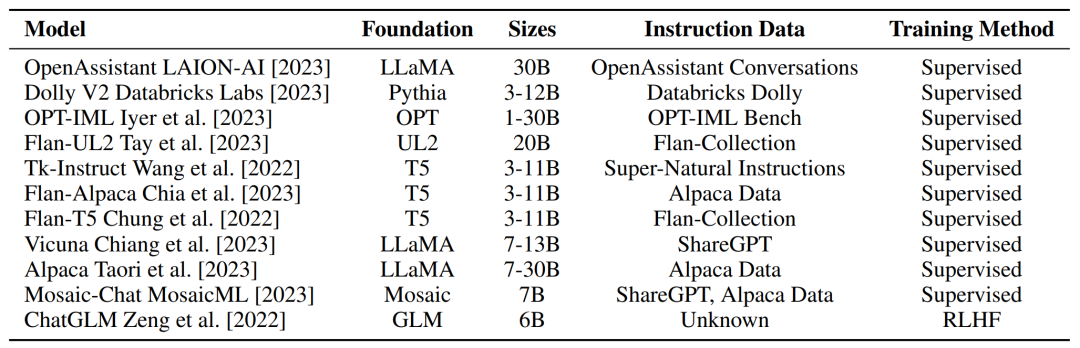
在考虑到为指令 LLM 提供支持的预训练基础模型和数据集之后,研究者在下表 3 中提供了开源指令模型的整体概述。
评估指令 LLM 面临哪些挑战?
首先是难以理解的黑箱模型。虽然 GPT-4 等指令 LLM 获得了广泛关注,但很多模型都选择闭源并仅限于通过 API 访问。此外,闭源模型的创建者往往不透露架构、指令数据集和训练方法等模型细节。
其次是压倒性的开源模型,在 GPT-4 等闭源模型令人印象深刻的演示刺激下,开源社区已经展开了狂热的模型开发,以期实现语言模型技术的民主化。虽然研究者对此备受鼓舞,但却深深担忧新模型的开发速度可能超过评估研究的进展。
接着是指令调优的多重考虑。为了全面了解指令 LLM,需要我们考虑可能影响它们行为的多样化因素,比如预训练、指令数据和训练方法。虽然以往的工作在某些领域进行过深入研究,比如指令数据集。但研究者认为应该综合考虑多种因素才能达到更完整的理解。
最后是广泛的能力范围。虽然指令 LLM 研究取得进展,我们自然能观察到它们通用能力的增强。最近的研究表明,LLM 可以通过指令调优来解决很多领域的问题,甚至可以使用外部工具来增强它们的能力。因此可以预见到,对指令 LLM 进行综合评估变得越来越重要,同时也越来越具有挑战性。
INSTRUCTEVAL 基准套件
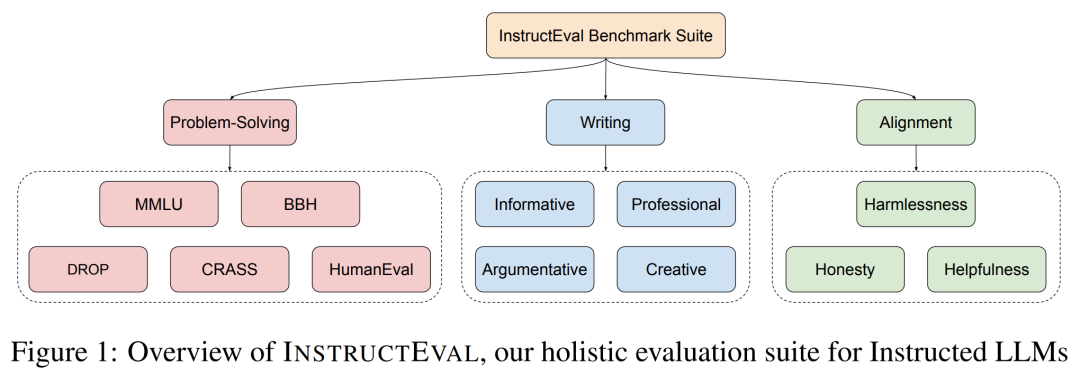
为了解决评估指令 LLM 的挑战,本文引入一个更全面的评估套件 INSTRUCTEVAL。为了涵盖广泛的通用能力,研究者在解决问题、写作和对齐人类价值观方面对模型进行了测试,具体如下图 1 所示。
评估解决问题的能力
为了评估指令 LLM 解决问题的能力,研究者采用了多个基准,涵盖了现实世界中不同主题的测试、复杂的指令、算术、编程和因果关系。为了在基准上表现良好,模型需要世界知识、多步推理的能力、创造力等。
评估写作能力
除了解决问题的能力,指令 LLM 在写作任务中展现的能力也十分具有前景,如写信或伦理辩论。研究评估了不同写作场景下的通用写作能力,包括信息性写作、专业写作、议论文写作和创意写作。议论文写作需要模型对伦理和社会问题的立场进行论述,而创意写作涉及多种写作格式,如故事、诗歌和歌曲。
为了构建写作基准 IMPACT,研究者为每个写作类别标注了 50 个 prompt。但是写作任务的答案很长,且通常没有唯一正确答案,这对严格的标准化评估来说是个大难题。其次,由于成本高、不同评价人之间可能存在不一致以及不可复现等原因,人工评价是不可扩展的。
评估与人类价值观的一致性
为研究指令调优对模型识别符合大众偏好需求的能力的影响,研究者在 INSTRUCTEVAL 中整合了有用、诚实和无害 (Helpful、Honest 和 Harmless) 基准,以评估人类价值观对指示模型的理解。这些值包括:
- 有用:始终致力于人类最大利益。
- 诚实:始终尽力传达准确的信息,避免欺骗人类。
- 无害:始终尽力避免任何伤害人类的行为。
下表 8 中列出了每个类别的例子:

解决问题
为了评估解决问题的能力,研究者在下表 5 中的基础上对 10 多种开源模型进行了评估。此外,为了全面分析模型性能,他们充分考虑了指令 LLM 的预训练基础、指令数据和训练方法。
首先,由于指令调优 LLM 是从它们各自的基础 LLM 中训练而来,因此在分析整体性能时考虑预训练基础至关重要。研究者观察到,坚实的预训练基础是在解决问题任务上表现出色的必要条件。其次,研究者发现虽然与预训练相比,指令调优对性能的影响更大,但它也并不是「灵丹妙药」。最后,训练方法也会影响模型性能和计算效率。研究者相信,参数高效的训练方法更有潜力实现扩展性更强和更高效的指令调优。
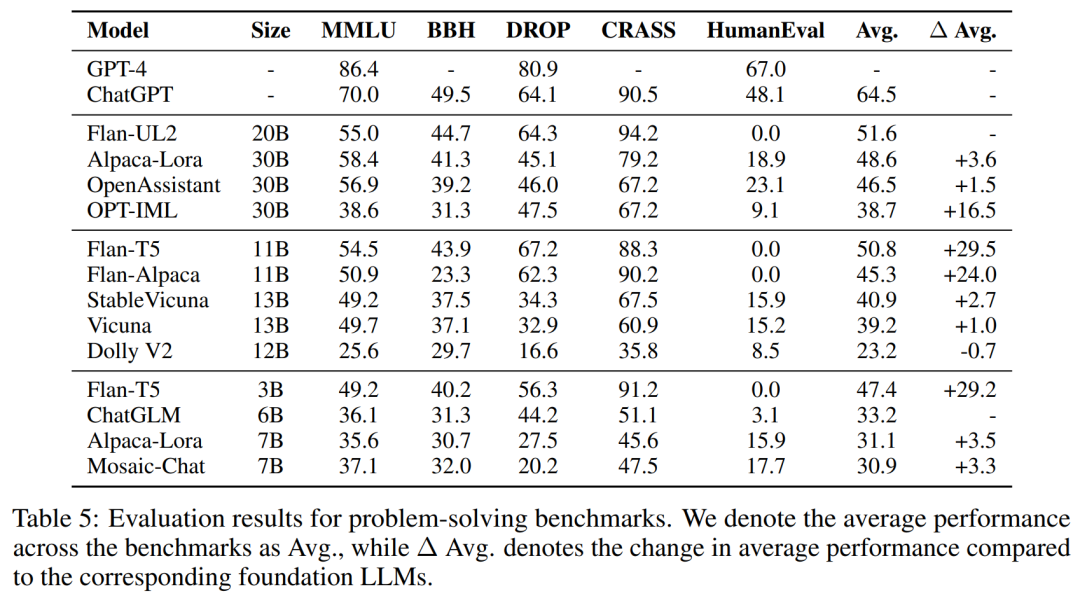
这些结果也引起了业内人士的关注,前谷歌大脑高级研究科学家、RekaAILabs 联合创始人兼首席科学家 Yi Tay 发现,「近来关于新基础开源模型的讨论很多,但自 2019 年的 T5 模型以来却没有出现真正的进步。」
他总结道,Flan-T5 击败了一切,包括 Alpaca(基于 LLama)、Flan-Alpaca 以及 Mosiac-Chat/MPT、Dolly。如果你从「计算匹配」(compute-match)的角度来看,则编码器 - 解码器应该处于不同(较低)的权重级别。基本上,Flan-T5 3 B 像是一个 1B+ 解码器,Flan-UL2 更像一个 8B+ 模型。从这个角度来看,差距如此之大。此外 Flan-UL2 在大多数指标上超越了 Alpaca-Lora 30B,尽管前者要小得多,计算量实际上也少数倍。
Yi Tay 表示,这并不完全是 Flan 系列模型,更多的是相关基础模型。关键是基础的 T5 模型,具有 1 万亿 token。此外还有多语言的 mT5 和 uMT5 模型,它们也都表现非常好。基础模型不是长上下文的,但 Flan 弱化了这一点。T5/UL2 的弱点是多样性较弱,仅接受 C4 训练。但令人惊讶的是自 2019 年以来 C4-only 基线模型的表现如此地强大。
最后可能在计算匹配时,T5 >> Llama。唯一的问题是 T5 没有 30B 和 65B 的版本。

推特:https://twitter.com/YiTayML/status/1668302949276356609?s=20
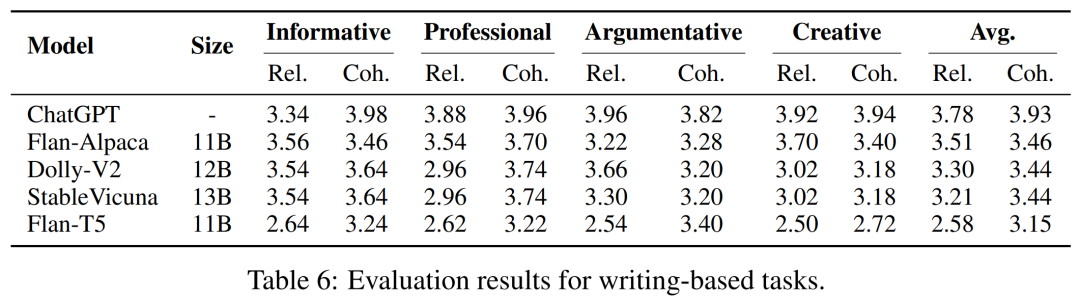
写作能力
研究者在下表 6 中提供了写作能力的评估结果。整体来说,研究者发现模型在信息性、专业性、议论文和创意性写作中表现一致,展现出了它们的通用写作能力。令人惊讶的是,具有更强问题解决能力的模型可能不具备更好的写作能力。值得注意的是,Flan-Alpaca 的问题解决能力较弱,但经过 GPT-3 的合成指令调优后,其在写作方面明显优于 Flan-T5。
研究者假设,尽管合成数据中存在着潜在噪声,但合成指令的更高多样性可以更好地泛化到现实世界的写作 prompt。与 Flan-T5,Flan-Alpaca 的相关性分数有了更显著提高,由此证明了这一点。开源指令 LLM 可以生成与 ChatGPT 具有可比相关性的答案,但在连贯性方面存在不足。这表明开源模型可以理解写作 prompt,但在生成输入的连贯性方面有所欠缺。
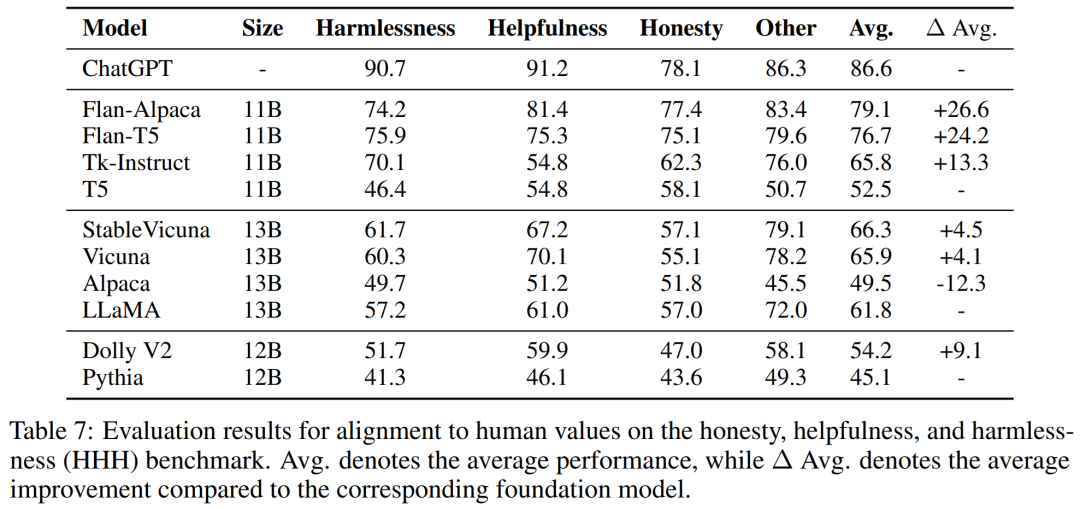
与人类价值观的一致性
为了评估指令 LLM 与人类价值观、偏好的一致性,研究者在下表 7 中对一些开源模型进行了评估。他们首先发现,与无害相比,基础模型通常更与有用和诚实对齐。
此外 Flan-T5 和 Flan-Alpaca 等基于 T5 的模型经过指令调优之后,更倾向于有用而非诚实。这些结果强调了提前确定指令 LLM 的对齐分布非常具有挑战性,即使在提供特定指令时也是如此。
通过分析下表 8 中的模型预测案例研究,研究者发现在保持指令 LLM 和人类价值观一致方面还有非常大的改进空间。

更多技术和实验细节请参阅原论文。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK