

浅谈算网融合路由调度技术
source link: https://www.51cto.com/article/753659.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

浅谈算网融合路由调度技术

1、网力调度与算力调度矛盾
传统业务,包括公有云、私有云、边缘云或数据中心均基于DNS域名解析或IP寻址方式提供算力服务,简言之,即只具备单纯的网力调度,与算力调度彼此独立。该服务方式的特点如下:
1️⃣ 算力服务状态和网络可达状态彼此分离,网络只确保IP可达,无法确保算力服务可用性,无法确保算力服务最优质量。主要如下两个原因:
A.网络转发路径最优不等价于所提供的算力服务最优;
B.所提供算力节点最优不等价于网络转发路径最优。
2️⃣ DNS域名解析或IP寻址方式,只能将算力请求调度至唯一确定的服务节点,单边缘计算节点通常算力有限,无法联动多边缘节点,难以提供精细粒度、弹性算力服务。
针对上述特点,下面做简单示例解释。
针对第一个问题:考虑如下图1,路由设备及边缘计算节点组成的网络拓扑,用户的计算请求数据通常遵循路由器设备的IP最短路径进行转发。但当计算请求数据到达路由器W,边缘计算节点(MEC 2)负载过高甚至宕机,那么计算请求就会被边缘计算节点丢弃,导致用户计算请求无法得到及时响应。直至服务提供商重新发布DNS更新或IP更新,重定向至其他计算节点(MEC 1),用户计算请求才能恢复正常。
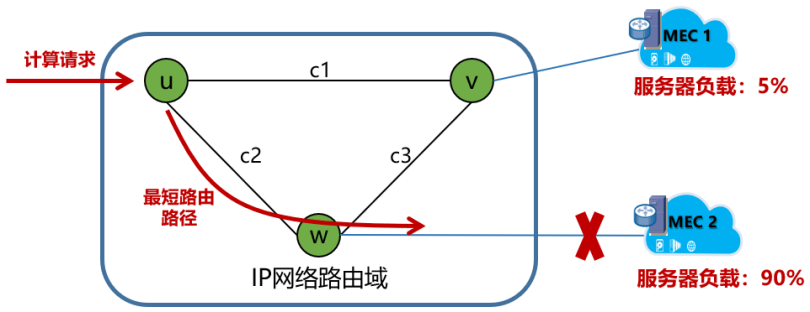
图1 传统网络和算力服务协同问题示例1
即使路由器W感知到了计算节点(MEC 2)状态异常(通常只能感知链路连接状态异常,难以感知负载情况),它可能采用快速重路由技术寻址到另一条备份路径,重定向至计算节点(MEC 1)。如图 2 所示,从路由器 U 到路由器 W,然后再到路由器 V,但是这个临时重定向的路径通常不能保证 QoS质量(例如,时延、带宽等要求),也难以为用户提供最优的算力服务。
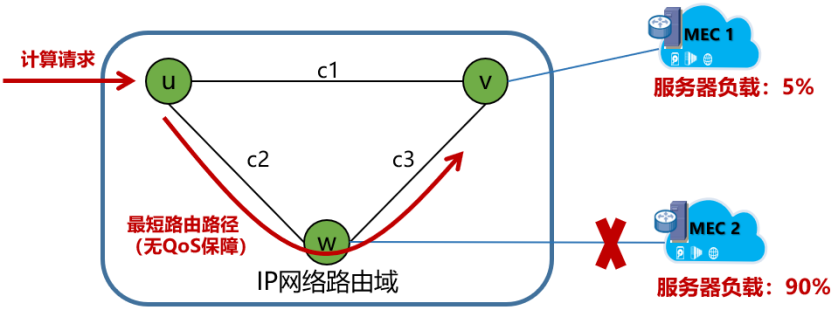
图2 传统网络和算力服务协同问题示例2
针对第二个问题,单个边缘节点的计算能力通常非常有限(例如,10台服务器处理能力)。边缘计算节点的处理能力、可靠性远远低于大型数据中心。通常需要跨多个边缘节点提供算力服务,以确保更好的服务性能和可靠性。一个关键问题是如何将计算请求数据定向到可用于提供最优服务的技术节点。目前通用的做法是,业务提供方提供相应的计算节点域名或IP,用户通过一定的哈希映射机制确定一个计算请求节点,向单一计算节点域名或IP发起计算请求。一旦计算节点确定,针对单用户而言,其计算请求通常会调度至唯一确定的计算节点。采用该方式在一定程度上可以通过DNS域名更新或IP更新方式重新切换计算节点,其切换粒度较大,实时性无法确保,用户体验大打折扣。
综上,现有网络服务提供服务方式,可总结为如下两个矛盾:
- 网力调度和算力调度彼此隔离、相互独立的矛盾;
- 网力调度的分布式和算力调度的集中式之间的矛盾。
2、算网融合调度技术
IP网络路由转发均基于分布式哈希路由表DHT(Distributed Hash Table)机制工作,对图1示例网络及算力拓扑进行抽象,形成如下拓扑:
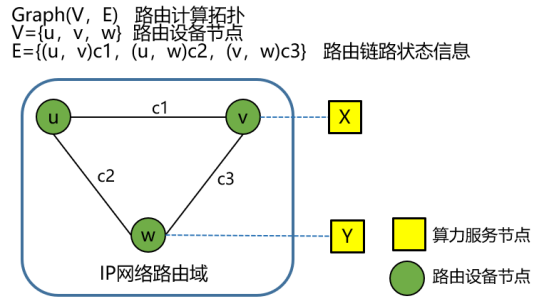
图3 传统网络和算力服务抽象拓扑
传统路由技术收集路由设备节点链路状态信息,形成u、v、w节点形成的网络拓扑Graph(V、E),分别由节点集合V、边集合E组成,并据此计算生成路由信息。算力服务节点X、Y并不在其中,不参与路由计算。
进一步抽象图3算力服务节点X、Y,将其加入路由度量,扩展至路由计算域,形成算力感知路由器,参与路由计算,形成如下网络拓扑:
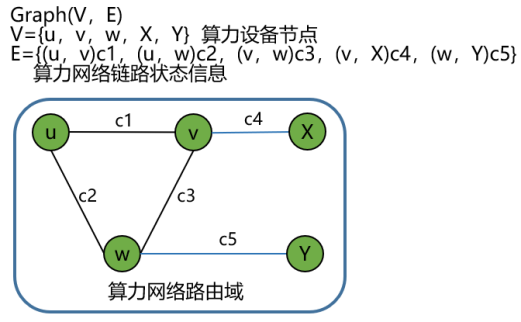
图4 算力网络拓扑模型
同时,可将算力路由器的计算能力(负载、处理能力、业务类型等)作为链路开销度量(示例中c4、c5)加入到路由计算中。传统上IP路由域以带宽、时延等为代价进行路由;通过算力感知路由,可以将吞吐量、计算延迟、服务器负载等计算能力作为一种虚拟链路状态来处理,并作为一种开销度量加入路由计算中。
示例如下,形成网络开销、算力开销为一体的算网网络路由域。
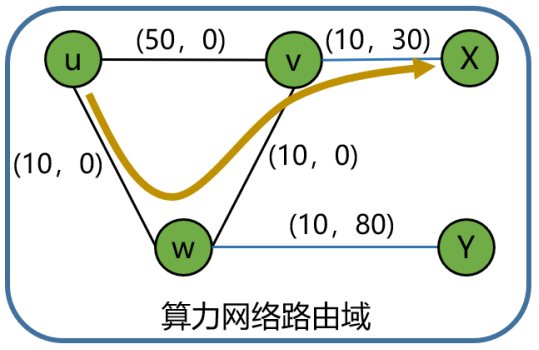
图5 算力感知网络拓扑示例
以u为根节点,根据网络链路拓扑信息,可形成如下路径及开销数据。网络开销和算力开销共同形成最终的算力服务开销。
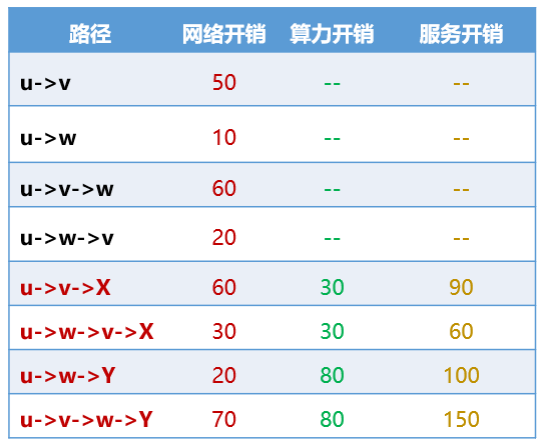
图6 算力感知计算路由表
由计算结果可知,u获取最优算力服务的开销为60,路径为:u->w->v->X。如果单纯基于网络开销计算,最优路径为u->w->Y。由于Y节点提供的算力有限(可能是负载过高、性能限制等因素,通过算力开销数值大小反应)。
进一步抽象,基于现有OSPF、IS-IS、BGP等传统路由技术,引入算力开销度量,将算力度量作为叶子信息参与算法计算,可形成通用算力感知路由框架,如图7:
1.算力节点以算力容器(可以以实体物理设备、服务器、虚拟机、容器等为载体)形式运行,底层运行路由进程应用。
2.算力节点通过Virtual Link或物理链路和边缘计算节点出口路由器相连接,通过路由协议进行本算力节点算力功能类型及算力质量开销度量信息发布,泛洪至整个路由域。
3.全网算力节点相关算力信息通过路由协议进行全网泛洪,各设备节点收集完成链路拓扑信息后,进行算力路由计算,在传统路由表基础上,计算生成算力路由表,指导算力路由。
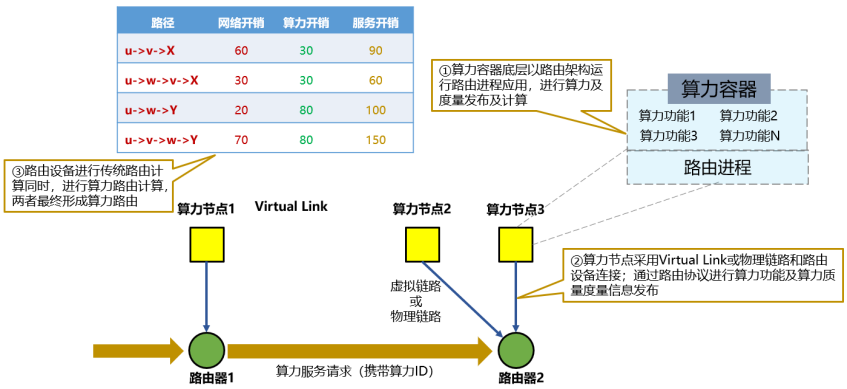
图7 算力感知路由框架
传统路由设备均基于IP路由,现网应用中基于兼容性考虑,算力服务采用IP地址或地址段方式来标识仍有必要性,典型可结合AnyCast任播技术,针对不同类型算力进行不同任播地址段划分,使算网无缝融合,天然具备防御DDos攻击能力,提升网络吞吐量、弱化网络拥塞,具备高可用性,全网可用性即算力可用性,避免单点故障。
算网融合涉及方方面面,包括算力编址、寻址、路由、生态等。不同于OverLay层面基于SRv6、APN6+等技术的算力路由技术,以上从另一维度,从传统UnderLay路由调度维度谈了对算网融合技术的粗浅认识。
算力网络成为运营商“主战场”趋势已成,家庭边缘云、家庭业务是新型算网基础设施落地切入关键点,进行算网深度融合,提供“一点接入、即取即用”的算力服务,将对家庭业务产生革命性影响。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK