

如何使用RFM模型和K-means聚类,实现更有效的客户分层?
source link: https://www.woshipm.com/user-research/5778472.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

仅仅只是从客户消费金额来分析客户是否流失,有时可能会成为曲解客户的行为。那如何实现对用户的精细化运营,达到最有效的客户召回方式呢?本文详细解析了使用RFM模型和K-means聚类实现更有效的客户分层,感兴趣的童鞋快来看看吧。

01 业务背景
不同的客户具有不同的客户价值,采取有效的方法对客户进行分类,发现客户的内在价值变化规律以及分布规律,针对不同的客户制定差别化服务政策,能够帮助企业投入最小的成本获取最大的价值。
在没有对用户进行分类的情况下,很难实现对用户的精细化运营。考虑到不同的套餐价格不同,而且在促销过程中也会有不同的折扣,如果单纯从客户消费金额来分析客户是否流失有时会曲解客户行为。
因此在对客户的分析过程中,需要根据客户最近一次的购买行为以及客户的购买频率的变化来推测客户的流失可能性,再通过客户的消费金额来判断客户的价值情况,最终指导运营决策,把重点放在贡献度高且流失机会也高的客户上,重点拜访或联系,以达到最有效的客户召回方式。
而RFM模型较为动态的显示了一个客户的全部轮廓,这对个性化的沟通和服务提供了依据。同时,如果与该客户打交道的时间足够长,也能够较为精确地判断该客户的长期价值(甚至是终身价值),通过对RFM三项指标的监控,可以为更多的营销决策提供支持,帮助改善经营状况。
02 RFM模型
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。根据美国数据库营销研究所Arthur Hughes的研究,最近一次消费时间间隔(Recency),消费频率(Frequency),消费金额(Monetary),这三个要素构成了数据分析最好的指标,通过这3个指标对用户进行分类,根据不同类别的用户进行精准营销。
最近一次消费时间间隔(Recency):近度,最近一次有效订购订单距离当前时间点的时间。
- 理论上最近一次购买的顾客越近越是优质客户,最近才购买商品或服务的顾客,是最有可能再次购买商品或服务的客户,对即时提供的商品或者是服务也最有可能有反应;
- 最近一次消费的过程是持续变动的,客户的最近一次消费时间间隔会随着时间的变化以及客户的购买行为变化而变化;
- 最近一次消费时间间隔可以帮助监控业务的健康程度。比如,月报告中显示上一次购买很近的客户(最近一次消费为1个月)人数环比增加,则表示该业务是个稳健成长的业务。相反,如上一次购买很近的客户(最近一次消费为1个月)人数环比降低,则表示该业务走向衰落的先兆;
消费频率(Frequency):频度,客户在限定时间内订购订单的次数。
- 消费频次高的客户,往往也是满意度最高的客户;
- 根据消费频次,可以把客户分成不同层级,观察用户在不同层级的分布情况,通过运营手段提高消费频次,增加高层级客户占比;
消费金额(Monetary):值度,客户在限定时间内订购订单的总支付金额。
- 消费金额是衡量客户价值的支柱指标,”帕雷托法则”——公司80%的收入来自20%的顾客,对有价值的客户进行营销能得到更可观的经验效果;
以客户订购订单的Recency、Frequency、Monetary来替代客户使用的Recency、Frequency、Monetary,主要有以下几点原因:
- 电信行业的客户每天都在使用电信业务的情况下,其最近时间间隔为零,不同的客户区分度很小,客户订购的时间间隔较大,以订购近度替代使用近度,避免了客户使用的近度难于区分的问题。
- 如果客户在一定时期内使用电信业务的次数数量非常大,则客户的频度也将是一个很大的数量,客户订购的次数相对较少,可以减少统计客户使用次数的工作量。
- 客户订购支付金额跟客户实际使用消费金额最终是相等的,因此,从订购交费角度构建的RFM模型是可取的。
因此需要从客户交费角度来考虑对客户进行RFM模型建模,以RFM模型为基础,通过客户的RFM行为特征衡量分析客户忠诚度与客户内在价值。
从公司所有的客户记录中选择近2年内还有消费订购记录的客户进行分析。把这3个指标(R、F、M)按价值从低到高排序,并把这3个指标作为XYZ坐标轴,大于(等于)总RFM平均值的为价值高坐标、小于总RFM平均值的为价值低坐标。可以划分为8个类别,RFM客户价值空间分类规则如下图:
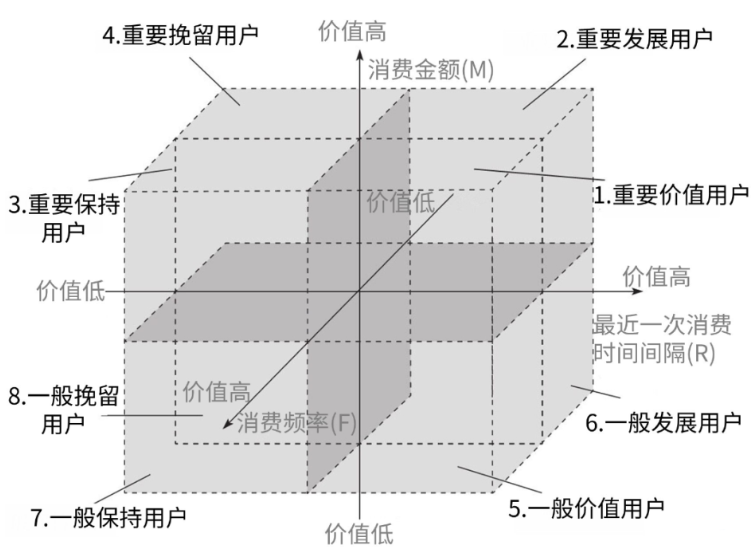
图1 RFM模型客户价值空间分类规则图
03 AHP计算RFM权重
虽然可以按照RFM模型把客户进行分类,但是这种分类只是确定了客户的聚类,却没有把各类客户之间进行一个量化的价值比较,无法对各种类别的客户群体进行权重的排名,因而对各类客户的RFM各个指标权重进行定义非常必要,需要结合各类指标的权重给各类客户进行综合价值的评分。
The analytic hierarchy process 简称AHP,也称为层次分析法,是在20世纪70年代中期由美国运筹学家托马斯·塞蒂(T.L.saaty)正式提出。它是一种定性和定量相结合的、系统化、层次化的分析方法,它的基本思路与人对一个复杂的决策问题的思维、判断过程大体上是一样的。
3.1、构造对比矩阵
设共有 n 个元素(RFM模型中n等于3)参与比较,则![]() 称为成对比较矩阵,其中在比较第 i 个元素与第 j 个元素相对上一层用户价值的重要性时,使用数量化的相对权重
称为成对比较矩阵,其中在比较第 i 个元素与第 j 个元素相对上一层用户价值的重要性时,使用数量化的相对权重 ![]() 来描述。
来描述。
- 成对比较矩阵中
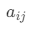 的取值可按下述标度进行赋值。 在 1-9 及其倒数中间取值。其中取值含义如下:
的取值可按下述标度进行赋值。 在 1-9 及其倒数中间取值。其中取值含义如下: - = 1,元素 i 与元素 j 对上一层次因素的重要性相同;
- = 3,元素 i 比元素 j 略重要;
- = 5,元素 i 比元素 j 重要;
- = 7, 元素 i 比元素 j 重要得多;
- = 9,元素 i 比元素 j 的极其重要;
- = 2n,n=1,2,3,4,元素 i 与 j 的重要性介于
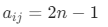 与
与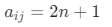 之间;
之间; - ,n=1,2,…,9, 当且仅当 = n ,其中
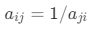 ,当 i = j 时, = 1。
,当 i = j 时, = 1。
针对RFM模型,建立![]() 的成对比较矩阵,其中矩阵中的
的成对比较矩阵,其中矩阵中的 ![]() 参数根据实际业务场景进行赋值。比如创建R、F、M的成对比较法,得到的比较矩阵如:
参数根据实际业务场景进行赋值。比如创建R、F、M的成对比较法,得到的比较矩阵如: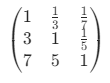 ,其中
,其中 ![]() 表示F(消费频率)比R(最近一次订购时间间隔)的重要性之比为3,即当前业务下决策认为F(消费频率)比R(最近一次订购时间间隔)略重要。
表示F(消费频率)比R(最近一次订购时间间隔)的重要性之比为3,即当前业务下决策认为F(消费频率)比R(最近一次订购时间间隔)略重要。
3.2、一致性检验
从理论上来说,完全一致的成对比矩阵的权向量是精确度是最高的。其中矩阵A如果是完全一致的成对比较矩阵,那么![]() ,其中1<=i,j,k<=n。但实际上根据业务情况构造成对比较矩阵时要求满足完全一致的成对比矩阵是不可能的,因此退而要求成对比较矩阵有一定的一致性,即可以允许成对比较矩阵存在一定程度的不一致性。
,其中1<=i,j,k<=n。但实际上根据业务情况构造成对比较矩阵时要求满足完全一致的成对比矩阵是不可能的,因此退而要求成对比较矩阵有一定的一致性,即可以允许成对比较矩阵存在一定程度的不一致性。
由分析可知,对完全一致的成对比较矩阵,其绝对值最大的特征值等于该矩阵的维数。对成对比较矩阵的一致性要求,应该满足矩阵A绝对值最大的特征值和该矩阵的维数相差不大,矩阵的随机一致性比率不得大于0.1。其中校验成对比较矩阵A一致性的步骤如下:
计算衡量一个成对比较矩阵 A (n>1 阶方阵)不一致程度的指标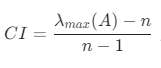 ,其中
,其中![]() 为矩阵A的绝对值最大特征值。
为矩阵A的绝对值最大特征值。
从有关资料查出检验成对比较矩阵 A 一致性的标准RI,其中RI称为平均随机一致性指标,它只与矩阵阶数 n 有关。
RI的计算方式为:对于固定的n,随机构造成对比较阵A,其中![]() 是从1,2,…,9,1/2,1/3,…,1/9中随机抽取的, 这样的A是不一致的, 取充分大的子样得到A的最大特征值的平均值。
是从1,2,…,9,1/2,1/3,…,1/9中随机抽取的, 这样的A是不一致的, 取充分大的子样得到A的最大特征值的平均值。

计算成对比矩阵A的随机一致性比率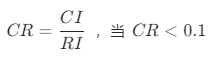 时,判定成对比较阵 A 具有满意的一致性,其不一致程度是可以接受的。否则就调整成对比较矩阵 A,直到达到满意的一致性为止。
时,判定成对比较阵 A 具有满意的一致性,其不一致程度是可以接受的。否则就调整成对比较矩阵 A,直到达到满意的一致性为止。
3.3、RFM矩阵权重
成对比矩阵A的一致性检验满足要求后( CR <1 ),可以通过矩阵A的最大特征值对应的特征向量来算出R(近度)、F(频度)、M(值度)各个指标变量对应的权重。
矩阵A对应最大特征值的特征向量数学计算公式: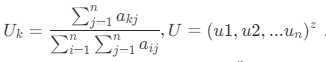 。
。
矩阵A对应最大特征值数学计算公式:
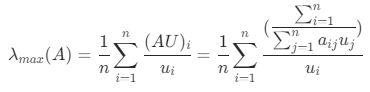
。
- 可以用Matlab语句求矩阵A的最大特征值对应的特征向量:
- A的特征值以及特征向量,可以通过[ X , Y ]=eig(A),其中Y为成对比较阵的特征值,X的列为相应的特征向量;
- 最大的特征值,可以通过eigenvalue=diag(Y) 以及 lamda=eigenvalue(1)进行计算,其中lamda表示最大的特征值;
- 可以通过y_lamda = x(:, 1) 进行计算最大特征值对应的特征向量。
实际在使用过程中,需要把矩阵最大特征值对应的特征向量转换成权向量,使得它的各分量都大于零,各分量之和等于 1,这样才能满足对RFM模型中各个指标变量的权重设置,各指标变量的相对重要性由权向量的各分量所确定,权向量的各分量对应的值就是出R(近度)、F(频度)、M(值度)的计算权重。
权向量等于自身向量各分量除以自身向量的和,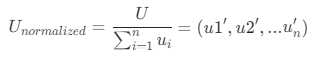 ,其中
,其中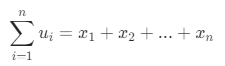 。 比如特征向量U= [ 2, 3, 5 ],
。 比如特征向量U= [ 2, 3, 5 ], ![]() 。
。
04 K-均值聚类法对客户分类
与RFM指标对客户分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,这种对客户的分类方式并不能满足“每个分类内部的元素之间相异度尽可能低,而不同分类的元素相异度尽可能高”的客户分类要求,反而会出现相同分类中的内部元素之间的相异度高,不同分类中的内部元素之间相异度反而低的情况发生。
聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。k均值(k-means)算法是一种迭代求解的聚类分析算法,所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高,其中每个子集叫做一个簇。
4.1、相异度计算
用通俗的话说,相异度就是两个东西差别有多大。
在数学上对相异度的定义指的是:设![]() ,其中X,Y是两个元素项,各自具有n个可度量特征属性,那么X和Y的相异度定义为:
,其中X,Y是两个元素项,各自具有n个可度量特征属性,那么X和Y的相异度定义为:![]() ,其中R为实数域,也就是说相异度是两个元素对实数域的一个映射,所映射的实数定量表示两个元素的相异度。
,其中R为实数域,也就是说相异度是两个元素对实数域的一个映射,所映射的实数定量表示两个元素的相异度。
在计算不同元素的相异度上我们采用欧几里得距离来作为相异度,其意义就是两个元素在欧氏空间中的集合距离,因为其直观易懂且可解释性强,被广泛用于标识两个标量元素的相异度。
欧几里得距离的定义如下:
![]()
在真实应用中,经常会出现元素项的取值问题,取值范围大的属性对距离的影响高于取值范围小的属性,比如在RFM模型的属性中,M的取值往往要远大于F的取值,这样不利于真实反映真实的相异度,为了解决这个问题,一般要对属性值进行规格化。
规格化的意思就是将各个属性值按比例映射到相同的取值区间(通常将各个属性均映射到[0,1]区间),这样是为了平衡各个属性对距离的影响。
映射公式为:
 表示所有元素项中i个属性的最大值和最小值,x是集合中的一个属性指标。
表示所有元素项中i个属性的最大值和最小值,x是集合中的一个属性指标。
4.2、k-means聚类算法
把近两年内还有订购记录的客户设定为一个元素集合D,其中每个元素有3个具有可观察的属性:R(近度)、F(频度)、M(值度)。
元素集合D按照K-means聚类算法把他分为8个聚类子集:
- 把集合D中每一个元素(客户)的RFM属性进行规格化,
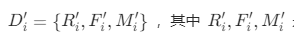 是基于
是基于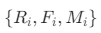 按照映射公式把各个属性均映射到[0,1]区间的结果;
按照映射公式把各个属性均映射到[0,1]区间的结果; - 对集合
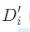 的各个属性进行加权处理,加权属性权重AHP法确定的权向量
的各个属性进行加权处理,加权属性权重AHP法确定的权向量 中对应的权重,加权后的集合
中对应的权重,加权后的集合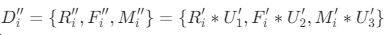 ;
; - 从集合
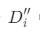 中随机选取K个元素(k = 125),作为作为k个簇的各自的中心;
中随机选取K个元素(k = 125),作为作为k个簇的各自的中心; - 分别计算剩下的元素到k个簇中心的相异度(按照欧几里得距离度量),将这些元素分别划归到相异度最低的簇;
- 根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数;
- 将集合中全部元素按照新的中心重新聚类;
- 重复第4步,直到聚类结果跟最近一次的聚类结果一致,不再变化;
- 输出最终的聚类结果;
4.3、划分客户类别
不同的层级聚合揭示不同层级的客户在行为上的特性以及变化倾向,划分客户类别方法如:
计算K均值聚类中每类客户的RFM平均值:
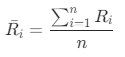 ,其中1<= i <=n,n指的是每类中的客户(设备)数,
,其中1<= i <=n,n指的是每类中的客户(设备)数,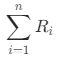 指的是对应类别中每台设备的R之和,R的计量单位为天;
指的是对应类别中每台设备的R之和,R的计量单位为天;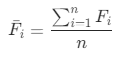 ,其中1<= i <=n,n指的是每类中的客户(设备)数,
,其中1<= i <=n,n指的是每类中的客户(设备)数,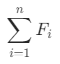 指的是对应类别中每台设备的F之和,F的计量单位为次;
指的是对应类别中每台设备的F之和,F的计量单位为次;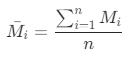 ,其中1<= i <=n,n指的是每类中的客户(设备)数,
,其中1<= i <=n,n指的是每类中的客户(设备)数,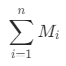 指的是对应类别中每台设备的M之和,M的计量单位为USD;
指的是对应类别中每台设备的M之和,M的计量单位为USD;
将每类客户的RFM平均值和总RFM平均值作比较:
- 将K均值聚类的125类客户的RFM平均值同总RFM均值进行比较。
- K均值聚类类别客户的均值大于(等于)总均值,则给该指标对应坐标为“价值高”坐标;
- K均值聚类类别客户的均值小于总均值,则给该指标对应坐标为“价值低”坐标;
划分RFM客户价值分类:
- 根据RFM空间坐标模型,匹配对应R、F、M三个指标的坐标,把K均值聚类的125个类别客户划分为8个类别:重要价值客户、重要发展客户、重要保持客户、重要挽留客户、一般价值客户、一般发展客户、一般保持客户、一般挽留客户。
05 客户价值排序
5.1、RFM指标分类客户价值
输出每一类客户的评分集合 ![]() ,其中1<= i <=125,R,F,M分别代表R(近度)、F(频度)、M(值度)的等级评分。对评分集合
,其中1<= i <=125,R,F,M分别代表R(近度)、F(频度)、M(值度)的等级评分。对评分集合![]() 的RFM属性进行规格化,规格化
的RFM属性进行规格化,规格化![]() ,其中
,其中![]() 按照映射公式把各个属性均映射到[0,1]区间的结果。
按照映射公式把各个属性均映射到[0,1]区间的结果。
RFM指标评分分类划分的5*5*5 = 125类客户进行价值排序:
- 假如计算出RFM矩阵权重的权向量
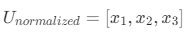 ,那每一类客户的综合总得分等于:规格化
,那每一类客户的综合总得分等于:规格化 的各指标值的
的各指标值的 加权平均值,每类客户的总得分为
加权平均值,每类客户的总得分为 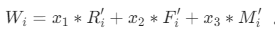 。
。 - 通过总得分的大小可以对5*5*5 = 125类客户进行优先级排序,指导运营支撑决策。
RFM指标分类划分成的8类客户(重要价值客户、重要发展客户、重要保持客户、重要挽留客户、一般价值客户、一般发展客户、一般保持客户、一般挽留客户)进行价值排序:
计算分类(RFM空间坐标划分的8类客户)客户中归属类客户(指标评分分类的5*5*5 = 125类客户)规格化指标属性的平均值;
8类客户规格化后各个指标的平均值![]() ,其中1<= i <=8,
,其中1<= i <=8,![]() 分别代表每类客户R(近度)、F(频度)、M(值度)的规格化指标平均值。
分别代表每类客户R(近度)、F(频度)、M(值度)的规格化指标平均值。
比如: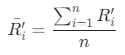 ,其中1<= i <=n,n指的是对应空间类别中归属类别(指标评分分类的5*5*5 = 125类客户)数,
,其中1<= i <=n,n指的是对应空间类别中归属类别(指标评分分类的5*5*5 = 125类客户)数,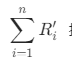 指的是对应空间类别中归属类别(指标评分分类的5*5*5 = 125类客户)的规格化属性R之和;
指的是对应空间类别中归属类别(指标评分分类的5*5*5 = 125类客户)的规格化属性R之和;
假如计算出RFM矩阵权重的权向量![]() ,那每一类客户的综合总得分等于:
,那每一类客户的综合总得分等于:![]() 的各指标值的
的各指标值的![]() 加权平均值,每类客户的总得分为
加权平均值,每类客户的总得分为 ![]() 。
。
通过总得分的大小可以对RFM坐标空间划分的8类客户进行优先级排序,指导运营支撑决策。
5.2、k-均值聚类客户价值
把集合D中每一个元素(客户)的RFM属性进行规格化,![]() 是基于
是基于![]() 按照映射公式把各个属性均映射到[0,1]区间的结果;
按照映射公式把各个属性均映射到[0,1]区间的结果;
K-均值聚类法划分的5*5*5 = 125类客户进行价值排序:
- 计算聚类中每类客户被规格化后各个指标的平均值
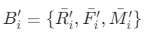 ,其中1<= i <=125,
,其中1<= i <=125,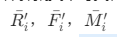 分别代表每一个客户R(近度)、F(频度)、M(值度)的规格化指标平均值。比如:
分别代表每一个客户R(近度)、F(频度)、M(值度)的规格化指标平均值。比如: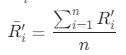 ,其中1<= i <=n,n指的是每类中的客户(设备)数,
,其中1<= i <=n,n指的是每类中的客户(设备)数,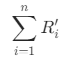 指的是每类中客户的属性R规格化之和;
指的是每类中客户的属性R规格化之和; - 假如计算出RFM矩阵权重的权向量,那每一类客户的综合总得分等于:
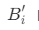 的各指标值的加权平均值,每类客户的总得分为
的各指标值的加权平均值,每类客户的总得分为 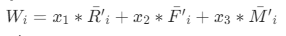 。
。 - 通过总得分的大小可以对k均值聚类的125类客户进行优先级排序,指导运营支撑决策。
K-均值聚类法对按照RFM坐标空间划分的8类客户(重要价值客户、重要发展客户、重要保持客户、重要挽留客户、一般价值客户、一般发展客户、一般保持客户、一般挽留客户)进行价值排序:
- 计算每类客户被规格化后各个指标的平均值,其中1<= i <=8,分别代表每一个客户R(近度)、F(频度)、M(值度)的规格化指标平均值。
- 假如计算出RFM矩阵权重的权向量,那每一类客户的综合总得分等于:的各指标值的加权平均值,每类客户的总得分为 。
- 通过总得分的大小可以对RFM坐标空间划分的8类客户进行优先级排序,指导运营支撑决策。
06 可视化分析
进行客户价值分类的过程中,需要能支持从不同维度来通过RFM模型对客户进行分类,针对同类别的客户采取不同的运营策略,数据驱动决策,帮助企业解决客户运营问题。其中最近消费以及消费频次是最有力的预测指标,可以预测客户下一次购买时间点以及行为。
取近两年还有订购记录的客户设定为一个集合统计客户样本数据,RFM模型对客户分层的可视化看板如图2所示:
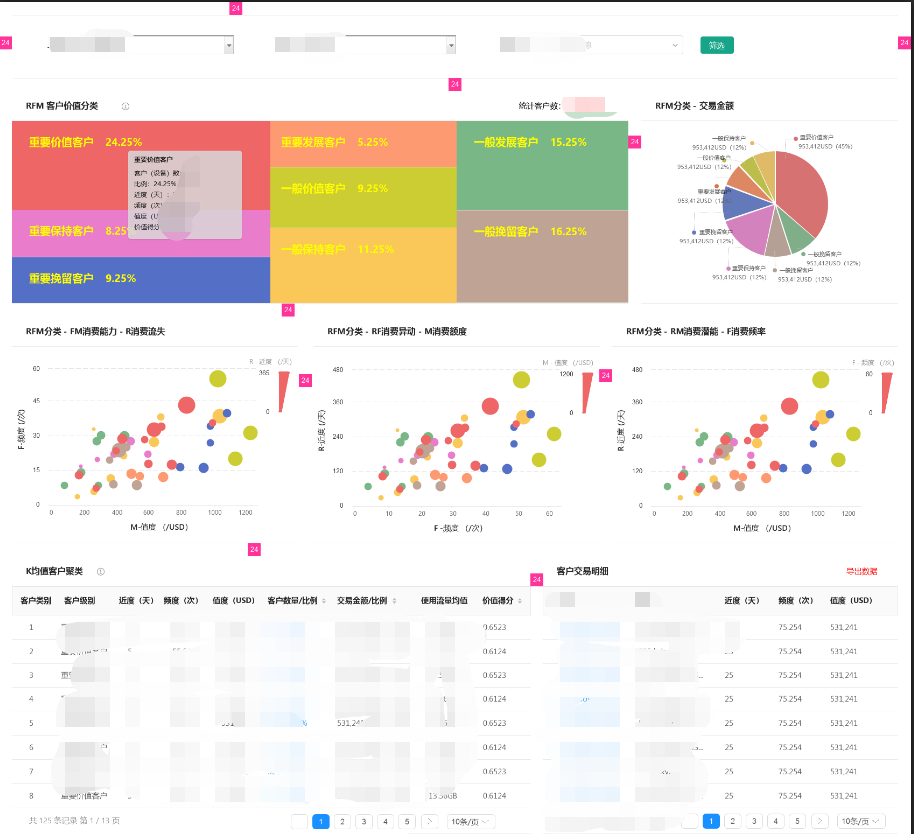
图2 RFM模型对客户分析看板
- 按维度筛选;
- RFM客户价值分类:是整个RFM模型的核心,直观显示了8个客户群的人数以及占比。
- k均值聚类+RFM模型+AHP分层,对统计的样本客户进行分类;
- 8个客户群:重要价值客户、重要发展客户、重要保持客户、重要挽留客户、一般价值客户、一般发展客户、一般保持客户、一般挽留客户;
- RFM分类-交易金额:在RFM指标中,往往我们更关心8个客户群中各个客户群的价值贡献,交易金额可以更直观的看出哪个客户群的价值较大。
- 显示不同客户群的总M-消费金额以及消费金额占比;
- FM消费能力 – R消费流失:通过MF分布来直观看到客户的消费能力分布,进而通过R的大小来判断客户的忠诚度,定位价值高忠诚度高的客户群体。
- 横坐标为M-值度(消费金额),纵坐标为F-频度(消费频率),点大小为R-近度(最近一次消费时间间隔);
- RF消费异动 – M消费额度:通过RF分布来直观看到客户的消费异动情况,进而通过M的大小来判断哪些客户更有必要挽回。
- 横坐标为F-频度(消费频率),纵坐标为R-近度(最近一次消费时间间隔),点大小为M-值度(消费金额);
- RM消费潜能 – F消费频率:通过MR分布来直观看到客户的消费潜能情况,进而通过F的大小来挖掘更有价值的客户。
- 横坐标为M-值度(消费金额),纵坐标为R-近度(最近一次消费时间间隔),点大小为F-频度(消费频率);
- K均值客户聚类:通过列表展示K-均值聚类法划分的125类客户的RFM聚类信息,更直观的通过价值得分对所有聚类的客户群进行价值大小排序;
- 列表展示信息:客户类别序列号、客户级别、近度(天)、频度(次)、值度(USD)、客户数量、客户数量占比、交易金额、交易金额占比、价值得分;
- 客户交易明细:显示各客户类型下的客户交易明细。
本文由 @慎独 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
-
6
编辑导语:DBSCAN算法是一种典型的基于密度的聚类方法,能够将具有足够高密度的区域划分为簇,并在具有噪声的数据中发现任意形状的簇;本文作者分享了关于如何用DBSCAN聚类模型做数据分析,我们一起来看一下。
-
10
利用Python实现K-Means聚类—以创造营2021集资数据为例上海市新能源汽车公共数据采集与监测研究中心 数据分析师快来给小九高卿尘投票把~~~本文主要讲述利用Python...
-
10
Python实现聚类算法的图像化处理April 07, 2016聚类算法参考这篇文章,本文是根据聚类算法得出的数据来绘制图像。 首先要对数据处理一下,在 DBSCAN 的算法中,我最后输出的 clu...
-
5
【层次聚类】理论与实现 2017年09月30日 Author: Guofei 文章归类: 3-2-聚类 ,文章编号: 303 版权声明:本文作者是郭飞。转载随意,但需要标明...
-
4
客户加上企业好友后不活跃,导致企业客户转化难,是很多企业长期以来困扰的问题,那么针对不活跃客户如何进行客户激活?怎么才能有效活跃客户呢? 怎么激活沉睡客户 想要激活沉睡客户,最直接的方法可以使用
-
5
斯图飞腾Stratifyd:如何建立有效的客户体验评估项目...
-
5
本文章将从数学及代码角度阐述K-Means聚类方法的原理及应用。 聚类分析允许我们找到相似样本或者feature的组,这些对象之间的相关性更强。 常见的用途有包括按照不同的基因表达情况对样本进行分组,或者根据不同样本的分类对基因进行分组等。 本文将会介...
-
4
聚类是一种非监督式的机器学习方法。对于监督式的分类问题,其 learning dataset 中的每一个样本点都有对应的标签,其目标为学习一个模型使得其对未知数据的预测表现最好。而对于非监督式的聚类问题,其数据集中并没有提供标签,而且它不像分类问题那样有明显的 训练...
-
2
之前分享过kmeans算法(传送门:
-
3
摘要:在本案例中,我们使用人工智能技术的聚类算法去分析超市购物中心客户的一些基本数据,把客户分成不同的群体,供营销团队参考并相应地制定营销策略。 本文分享自华为云社区《
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK