

K-Means聚类及slearn实现
source link: https://www.bobobk.com/902.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文章将从数学及代码角度阐述K-Means聚类方法的原理及应用。
聚类分析允许我们找到相似样本或者feature的组,这些对象之间的相关性更强。 常见的用途有包括按照不同的基因表达情况对样本进行分组,或者根据不同样本的分类对基因进行分组等。 本文将会介绍聚类算法中的k-means:
- k-means聚类的基本概念
- k-means 算法背后的数学原理
- k-means的优缺点
- 使用scikit-learn 包实现
- 可视化分类
- 选择最优的k
k-means聚类的基本概念
k-means是一种高效的无监督的聚类方法,最初用于信号处理,旨在将n个观测值划分为k个簇,其中每个观测值都属于具有最近均值的簇(簇中心或簇质心),作为群。很容易混淆的另一种聚类方法是监督学习算法k-nearest neighbors (KNN),需要注意。
k-means 算法背后的数学原理
给定一组观测值 (x1, x2, …, xn),其中每个观测值都是一个 d 维实向量,k-means 聚类旨在将 n 个观测值划分为 k (≤ n) 个集合 S = {S1, S2, …, Sk} 以最小化集合内平方和(WCSS)(即方差),最大化组间差异。 形式上:
其中Ui是Si的平均值。
该公式可等价于使得同一类中成对平方差最小
k-means的优缺点
- 原理简单,实现快
- 聚类效果好
- 算法可解释度高
- 只需要调整聚类个数k
- K值的选取不好把握
- 对于不是凸的数据集比较难收敛
- 采用迭代方法,得到的结果只是局部最优
- 对噪音和异常敏感
使用scikit-learn 包实现
首先随机生成数据分类数据,再通过KMeans函数进行聚类
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# from 春江暮客
x,y = make_blobs(n_samples=150, n_features=2,centers=3, cluster_std=0.5,shuffle=True, random_state=1024)
km = KMeans( n_clusters=3, init='random',n_init=10, max_iter=300, tol=1e-04, random_state=1024)
y_km = km.fit_predict(x)
可视化分类
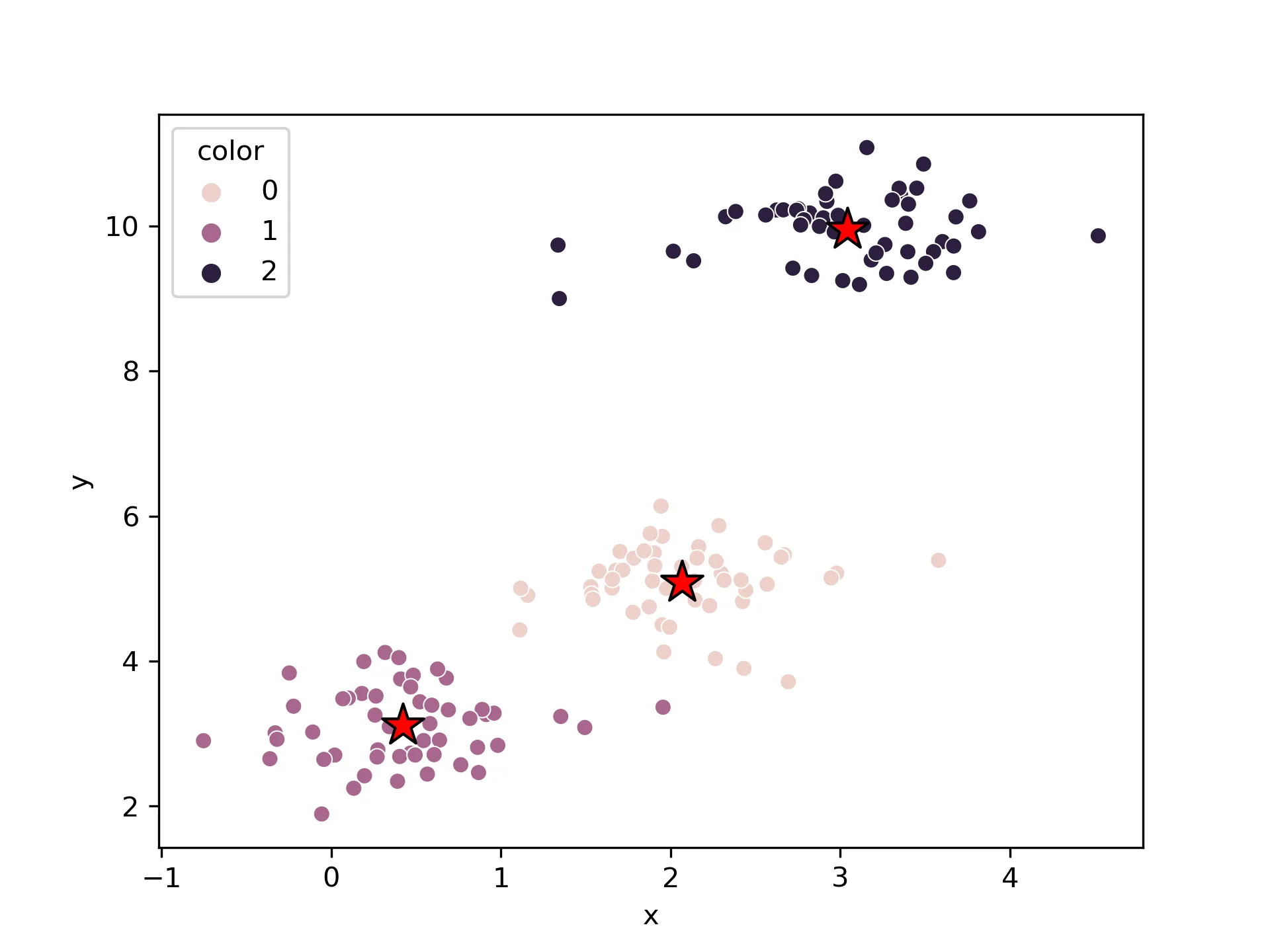
将KMeans聚类结果进行可视化,matplotlib和seaborn都可
首先使用seaborn
# seaborn
df = pd.DataFrame(x,columns=["x","y"])
df["color"] = y_km
sns.scatterplot(data=df,x="x",y="y",hue="color", markers="color")
# 绘制聚类中心
plt.scatter(
km.cluster_centers_[:, 0], km.cluster_centers_[:, 1],
s=250, marker='*',
c='red', edgecolor='black',
label='center'
)
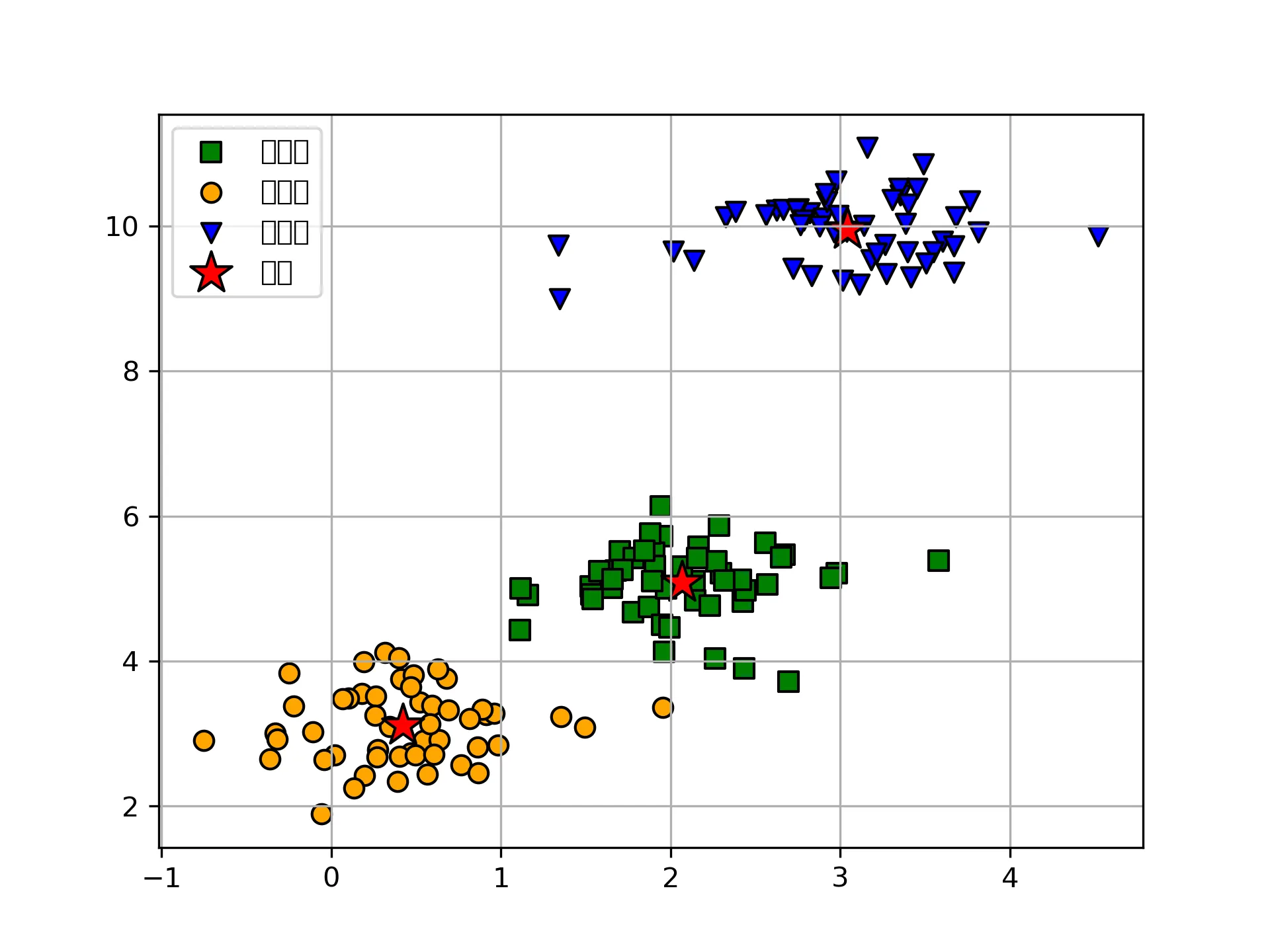
接下来是matplotlib直接绘制
# matplotlib
plt.scatter(
x[y_km == 0, 0], x[y_km == 0, 1],
s=50, c='green',
marker='s', edgecolor='black',
label='cluster1'
)
plt.scatter(
x[y_km == 1, 0], x[y_km == 1, 1],
s=50, c='orange',
marker='o', edgecolor='black',
label='cluster2'
)
plt.scatter(
x[y_km == 2, 0], x[y_km == 2, 1],
s=50, c='blue',
marker='v', edgecolor='black',
label='cluster3'
)
# 绘制聚类中心
plt.scatter(
km.cluster_centers_[:, 0], km.cluster_centers_[:, 1],
s=250, marker='*',
c='red', edgecolor='black',
label='center'
)
plt.legend(scatterpoints=1)
plt.grid()
plt.show()
选择最优的k
在我们自己生成的数据上,k-means聚类效果是非常好的。但是我们前面提到过, k-means受k的影响是很大的,在多维数据上类别数并不好判断,理论上k增大,则组内差异变小,而组别差异和会增大,因此如何评估最佳k-means聚类中非常重要,这里采用elbow method进行评估.
distortions = []
for i in range(1, 11):
km = KMeans(
n_clusters=i, init='random',
n_init=10, max_iter=300,
tol=1e-04, random_state=1024
)
km.fit(x)
distortions.append(km.inertia_)
# 绘图
plt.plot(range(1, 11), distortions, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()
结果:
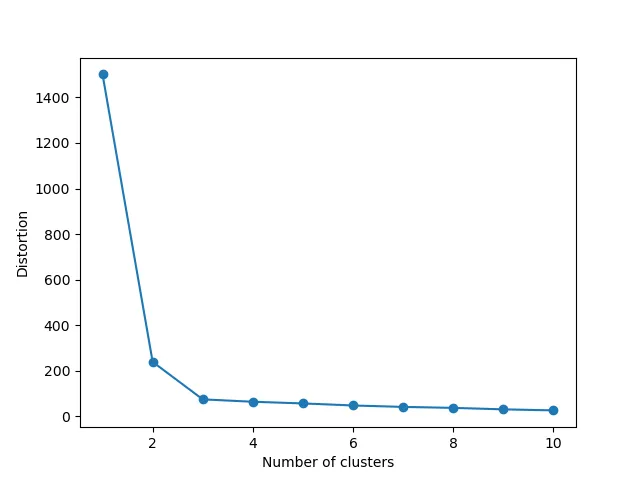
可以看到在K到达3后,随着K增大,而Y并没有剧烈变化,因此该数据中K为3是理想值.
本文从原理入手,一步步通过sklearn运算并得到样本分类情况,并通过matplotlib和seaborn战士分类效果,最后提供方法找寻最佳分类个数.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK