

Graviton3 outperforms x86 on Machine Learning - Infrastructure Solutions blog -...
source link: https://community.arm.com/arm-community-blogs/b/infrastructure-solutions-blog/posts/performance-improvement-of-xgboost-and-lightgbm-when-deploying-on-aws-graviton3-1110606499
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Introduction
XGBoost (eXtreme Gradient Boosting) is an open-source machine learning library under Gradient-Boosting Decision Tree (GBDT) framework. XGBoost is used to solve regression and classification problems in data science using machine learning. And the tasks can be distributed over a cluster of machines for faster training and inference. For instance, XGBoost4J-Spark is a project for integrating XGBoost with Apache Spark.
LightGBM (Light Gradient Boosting Machine) is another open-source GDBT-based tool developed by Microsoft, mostly known for more efficient training compared to XGBoost. Similar to XGBoost, LightGBM training can be distributed over a cluster of nodes and keeps the cost of the task distribution low by reducing the communication between the nodes.
This blog compares the performance of XGBoost and LightGBM running on several AWS instances. These instances include types C5 (Skylake-SP or Cascade Lake), C6i (Intel Ice Lake), C6g (AWS Graviton2), and C7g (AWS Graviton3) and with the size of 12xlarge. The instances are all equipped with 48 vCPUs and 96GB memory.
AWS Graviton3: the 3rd generation of Graviton processor family
AWS Graviton2 processors are the second generation of the processors designed by AWS using Arm Neoverse cores, providing extensive price-performance improvements for different workloads over x86 instances in Amazon EC2. AWS Graviton3 are the 3rd generation of the Graviton processor family, delivering up to 25% higher compute performance over the 2nd generation. The performance for specific computations can be 2 to 3 times better, for instance for floating point and cryptography operations, and CPU-based machine learning applications with bfloat16 support. Graviton3 support for DDR5 has increased memory bandwidth by up to 50% compared to the instances with DDR4 support.
Benchmark environment
Benchmark Tool
XGBoost is integrated in scikit-learn, a popular machine library for Python. We use scikit-learn_bench for benchmarking XGBoost, and for benchmarking LightGBM with minor modifications. The benchmark tool and the parameters are passed in a configuration file. Sample configuration files are located inside the `config` directory on the repository. The benchmarks use Python 3.10.4 and the following versions of Python libraries:
- XGBoost: 1.6.2
- LightGBM: 3.3.2
- scikit-learn: 1.1.2
For the XGBoost, we run the benchmarks for the following datasets:
For the LightGBM, we represent the results for the Airline and Higgs datasets.
The parameters used for the benchmarks are as follows:
|
tree-method (for XGBoost) |
|
|
learning-rate |
|
|
max-depth |
|
|
max-leaves |
|
|
n-estimators (number of estimators) |
The `hist` tree method for XGBoost is like how LightGBM works and increases the training speed. The number of estimators is set to 100, which is the default value for XGBoost and LightGBM libraries. The number of threads is set to the number of vCPUs available on the instances, which is 48 for 12xlarge instances.
Performance comparison
XGBoost training performance
The following chart shows the training time for the three datasets and on different instance types. The results show Graviton3 instances have up to 52% training time improvement over C5, 36% improvement over C6i, and 37% improvement over Graviton2.
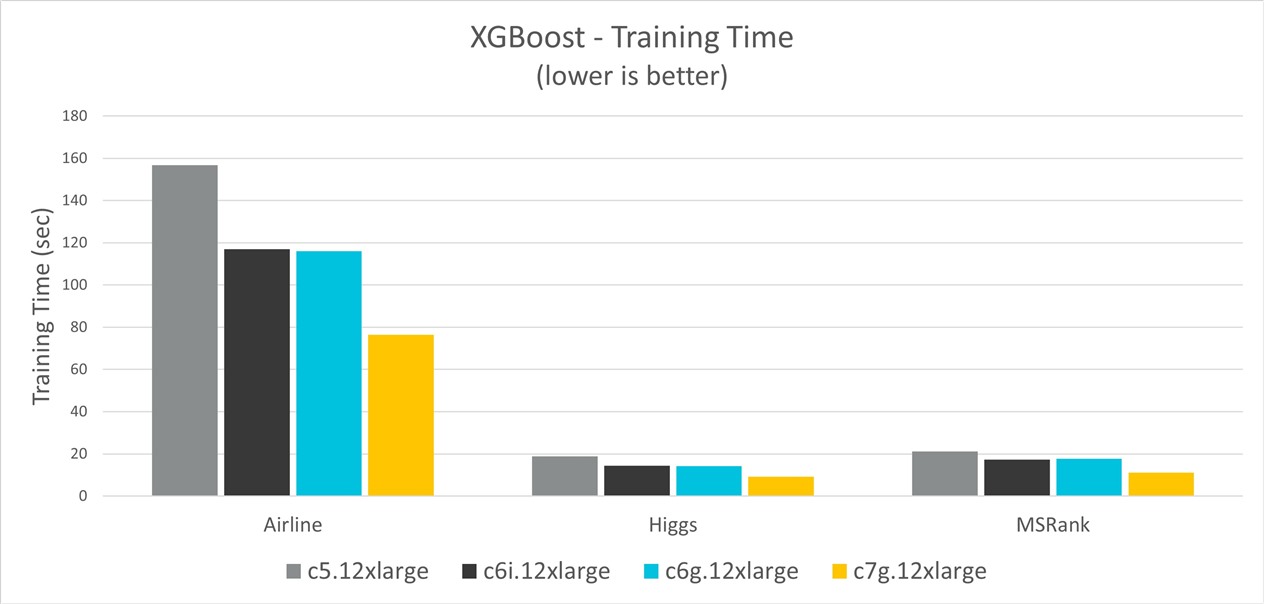
Figure 1. XGBoost training time comparison
The following table shows the XGBoost training times for Airline, Higgs, and MSRank datasets.
|
Training time |
c5.12xlarge |
c6i.12xlarge |
c6g.12xlarge |
c7g.12xlarge |
|
Airline |
156.7542863 |
117.0082541 |
116.0416869 |
76.4209646 |
|
Higgs |
18.89056222 |
14.33615984 |
14.11944058 |
9.149896008 |
|
MSRank |
21.16431952 |
17.23972275 |
17.74064451 |
11.17478875 |
XGBoost inference performance
Figure 2 shows the inference time for the three datasets and on different instance types. The results show Graviton3 instances have up to 45% inference time improvement over C5, 26% improvement over C6i, and 32% improvement over Graviton2.
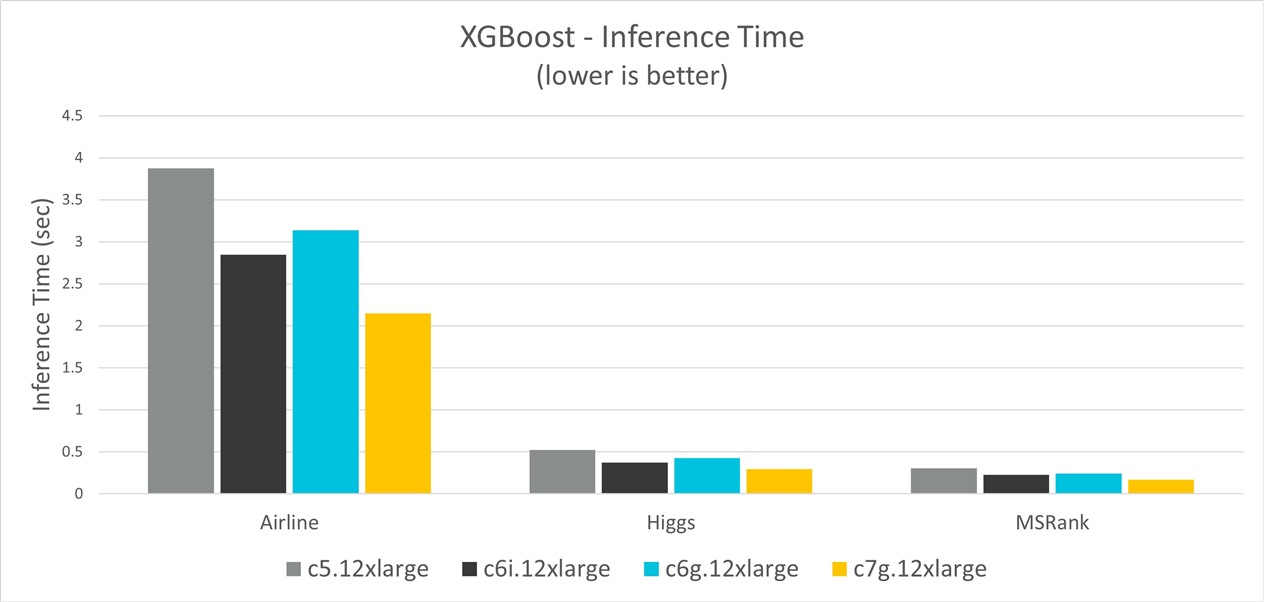
Figure 2. XGBoost inference time comparison
The following table shows the XGBoost inference times for the three datasets.
|
Prediction time |
c5.12xlarge |
c6i.12xlarge |
c6g.12xlarge |
c7g.12xlarge |
|
Airline |
3.872979737 |
2.844810675 |
3.137031317 |
2.147960264 |
|
Higgs |
0.522402984 |
0.372625213 |
0.425959238 |
0.29535643 |
|
MSRank |
0.303822537 |
0.225266151 |
0.243390166 |
0.166838843 |
LightGBM training performance
Figure 3 shows the training time for Airline and Higgs datasets, and on different instance types. The results show Graviton3 instances have up to 53% training time improvement over C5, 42% improvement over C6i, and 41% improvement over Graviton2.
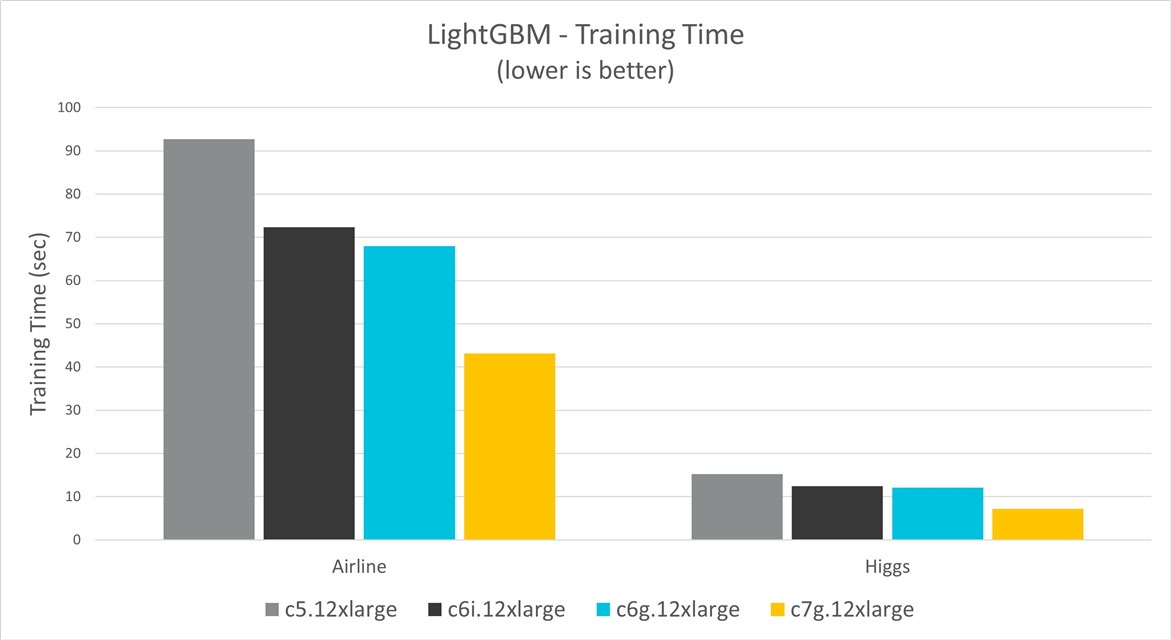
Figure 3. LightGBM training time comparison
The following table shows the LighttGBM training times for the Airline and Higgs datasets.
|
Training time |
c5.12xlarge |
c6i.12xlarge |
c6g.12xlarge |
c7g.12xlarge |
|
Airline |
92.7331301 |
72.38613732 |
67.94223656 |
43.12893921 |
|
Higgs |
15.230757 |
12.40288175 |
12.0835368 |
7.17597144 |
LightGBM inference performance
Figure 4 shows the training time for the two datasets and on different instance types. The results show Graviton3 instances have up to 39% improvement over C5, 31% improvement over C6i, and 31% improvement over Graviton2.
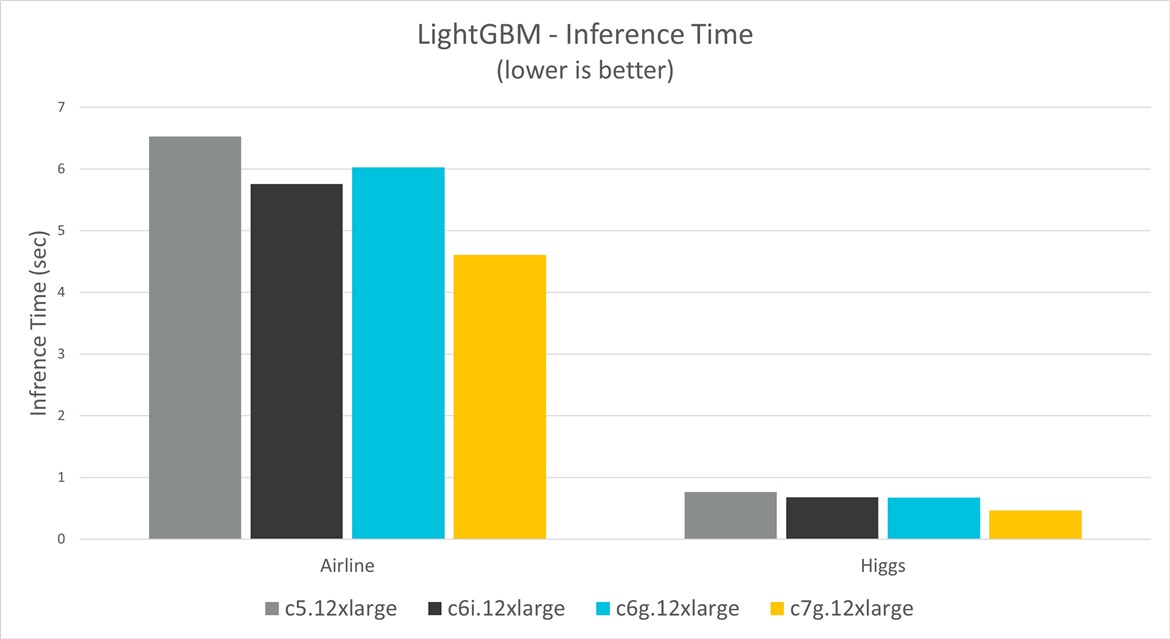
Figure 4. LightGBM inference time comparison
The data for the chart in Figure 4 comes from the following table, showing inference times for LightGBM and for the Airline and Higgs datasets:
|
Prediction time |
c5.12xlarge |
c6i.12xlarge |
c6g.12xlarge |
c7g.12xlarge |
|
Airline |
6.5264758 |
5.757308737 |
6.026721292 |
4.610307491 |
|
Higgs |
0.76227941 |
0.677829095 |
0.674827518 |
0.464917262 |
Benchmark considerations
scikit_learn_bench by default patched Scikit-learn using Intel(R) Extension for Scikit-learn to optimize ML performance on Intel processors with SSE2, AVX, AVX2, and AVX512 support. However, Gradient Boosting algorithms are not supported by the patch at the time of the publication of this blog.
Intel offers oneAPI Data Analytics Library (oneDAL) to accelerate ML algorithms on Intel machines. However, it requires code changes and conversion from standard XGBoost and LightGBM models to OneDAL. We have not converted and tested any of these models using OneDAL as part of this exercise.
Conclusion
XGBoost benchmarks show that Graviton3 instances outperform Graviton2 and x86 counterparts for the three datasets selected for performance analysis (Airline, Higgs, and MSRank). In some cases, Graviton3 outperforms x86 by up to 50%. Similar performance enhancement was demonstrated for LightGBM and for the two datasets of Airline and Higgs, for both the training and inference operations.
Visit the AWS Graviton page for customer stories on adoption of Arm-based processors. For any queries related to your software workloads running on Arm Neoverse platforms, feel free to reach out to us at [email protected].
References:
https://neptune.ai/blog/when-to-choose-catboost-over-xgboost-or-lightgbm
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK