

网络字节序和主机字节序 - MElephant
source link: https://www.cnblogs.com/hyacinthLJP/p/16703290.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

如今的通讯方式已经趋向与多样化,异构通信也已经很普遍了,如手机和电脑中的 QQ 进行互联互通。
同时,在计算机设计之初,对内存中数据的处理也有不同的方式(如「低位数据存储在低位地址处」或者「高位数据存储在低位地址处」);然而,在通信的过程中,数据被一步步封装,当传到目的地址时,再被一步步解封,然后获取数据。
从上面我们可以看出,数据在传输的过程中,一定有一个标准化的过程,也就是说从「主机 a」到「主机b」进行通信:
a 的固有数据存储格式-------标准化--------转化成 b 的固有格式
如上而言:a 或者 b 的固有数据存储格式就是自己的主机字节序,上面的标准化就是网络字节序:
a的主机字节序----------网络字节序 ---------b的主机字节序
二、字节序
2.1 主机字节序
自己的主机内部,内存中数据的处理方式,可以分为两种:
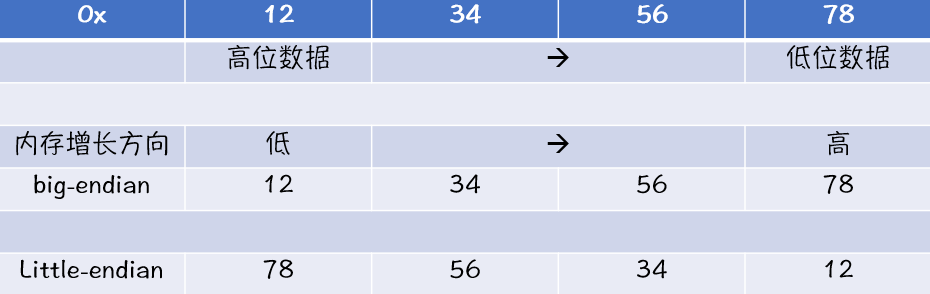
- 大端字节序( big-endian):按照内存的增长方向,高位数据存储于低位内存中(最直观的字节序 )
- 小端字节序(little-endian):按照内存的增长方向,低位数据存储于低位内存中
如果我们要将0x12345678这个十六进制数放入内存中:
2.2 网络字节序
网络数据流也有大小端之分。
网络数据流的地址规定:先发出的数据是低地址,后发出的数据是高地址。
发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出,为了不使数据流乱序,接收主机也会把从网络上接收的数据按内存地址从低到高的顺序保存在接收缓冲区中。
TCP/IP协议规定:网络数据流应采用大端字节序,即低地址高字节。
三、测试主机字节序
我们可以通过程序来验证我们所使用的主机用的是哪一种字节序,编写程序前先来谈一谈测试思路:
- 用无符号整形保存数据「0x12345678」,即
unsigned int a = 0x12345678;- 十六进制下的一位 = 4b,那么 0x12345678=8×4=32b0x12345678=8×4=32b,故可以考虑用无符号整形保存
- 用
unsigned char *p保存 a 的地址,并通过输出p[0]、p[1]、p[2]、p[3]来观察主机字节序
3.1 demo 1.0
#include <stdio.h>
void Print(unsigned char *p)/* 输出主机的字节序 */
{
if (0x12 == p[0]) //判断高位数据 0x12 是否存储在低位内存中
{
printf(" big-endian[%0x %0x %0x %0x]\n", p[0], p[1], p[2], p[3]);
}
else
{
printf("little-endian[%0x %0x %0x %0x]\n", p[0], p[1], p[2], p[3]);
}
}
int main()
{
unsigned int a = 0x12345678;
unsigned char *p = (unsigned char *)(&a);
Print(p);
return 0;
}输出结果如下:
3.2 demo 2.0
其实,我们也可以利用union内存共享的特点改写一下上边的 demo:
#include <stdio.h>
#include <stdlib.h>
union
{
unsigned int u32a;
char p[4]; //用于观察 u32a 的内存分布情况
} un;
void Print(unsigned char *p)/* 输出主机的字节序 */
{
if (0x12 == p[0]) //判断高位数据 0x12 是否存储在低位内存中
{
printf(" big-endian[%0x %0x %0x %0x]\n", p[0], p[1], p[2], p[3]);
}
else
{
printf("little-endian[%0x %0x %0x %0x]\n", p[0], p[1], p[2], p[3]);
}
}
int main()
{
if (4 != sizeof(un.u32a)) // 判断 unsigned int 是否为 32 位,如果不是,则退出
{
exit(0);
}
un.u32a = 0x12345678;
Print(un.p);
return 0;
}输出结果同上。
四、大小端转换
常用的转换函数:
htons(): 将 16 位的主机字节序转换为网络字节序;ntohs(): 将 16 位的网络字节序转换为主机字节序;htonl(): 将 32 位的主机字节序转换为网络字节序;ntohl(): 将 32 位的网络字节序转换为主机字节序。
h 是主机 host,n 是网络 net,l 是长整形 long,s是短整形short,所以上面这些函数还是很好理解的。
下面,我们通过代码深入理解一下:
#include <stdio.h>
#include <stdlib.h>
union
{
unsigned int u32a;
char p[4]; //用于观察 u32a 的内存分布情况
} un;
void Print(unsigned char *p)/* 输出主机的字节序 */
{
if (0x12 == p[0]) //判断高位数据 0x12 是否存储在低位内存中
{
printf(" big-endian[%0x %0x %0x %0x]\n", p[0], p[1], p[2], p[3]);
}
else
{
printf("little-endian[%0x %0x %0x %0x]\n", p[0], p[1], p[2], p[3]);
}
}
int main()
{
if (4 != sizeof(un.u32a)) // 判断 unsigned int 是否为 32 位,如果不是,则退出
{
exit(0);
}
un.u32a = 0x12345678;
Print(un.p);
printf("\n");
un.u32a = htonl(0x12345678);
Print(un.p);
return 0;
}输出结果如下:
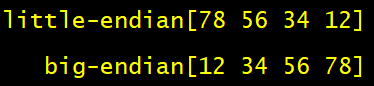
比较奇怪的是,经过我的测试发现,htonl的实际作用其实是「将 32 位的大端字节序与小端字节序进行互转」:
#include <stdio.h>
#include <stdlib.h>
union
{
unsigned int u32a;
char p[4]; //用于观察 u32a 的内存分布情况
} un;
void Print(unsigned char *p)/* 输出主机的字节序 */
{
if (0x12 == p[0]) //判断高位数据 0x12 是否存储在低位内存中
{
printf(" big-endian[%0x %0x %0x %0x]\n", p[0], p[1], p[2], p[3]);
}
else
{
printf("little-endian[%0x %0x %0x %0x]\n", p[0], p[1], p[2], p[3]);
}
}
int main()
{
if (4 != sizeof(un.u32a)) // 判断 unsigned int 是否为 32 位,如果不是,则退出
{
printf("======> [%s][%s-%lu] u32a[%d]\n", __FILE__, __FUNCTION__, __LINE__, sizeof(un.u32a));
exit(0);
}
un.u32a = 0x12345678;
Print(un.p);
un.u32a = htonl(un.u32a);/* 一次转换,将主机默认的小端字节序转化为大端字节序 */
Print(un.p);
un.u32a = htonl(un.u32a);/* 再次转换,将转换后的大端字节序转换为小端字节序 */
Print(un.p);
return 0;
}输出结果如下:
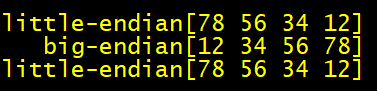
验证成功!其余的转换函数同理,可自行测试验证。
参考资料:
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK