

谣言检测——(GCAN)《GCAN: Graph-aware Co-Attention Networks for Explainable Fake N...
source link: https://www.cnblogs.com/BlairGrowing/p/16698050.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论文标题:GCAN: Graph-aware Co-Attention Networks for Explainable Fake News Detection on Social Media
论文作者:Yi-Ju Lu, Cheng-Te Li
论文来源:2020, ACL
论文地址:download
论文代码:download
1 Abstract
目的:预测源推文是否是假的,并通过突出显示可疑的转发者上的证据和他们所关心的词语来产生解释。
2 Introduction
我们预测一个源推文故事是否是假,根据它的短文内容和用户转发序列,以及用户个人资料。
我们在三种设置下检测假新闻: (a) short-text source tweet (b) no text of user comments (c) no network structures of social network and diffusion network.
本文贡献:
(1) 研究了一种新颖、更现实的社交媒体上的假新闻检测场景;
(2) 为了准确的检测,我们开发了一个新的模型,GCAN,以更好地学习用户交互的表示、转发传播及其与源短文的相关性;
(3) 本文的双重共同注意机制可以产生合理的解释;
(4) 在真实数据集上进行的大量实验证明,与最先进的模型相比,GCAN具有良好的性能前景;
3 Related Work
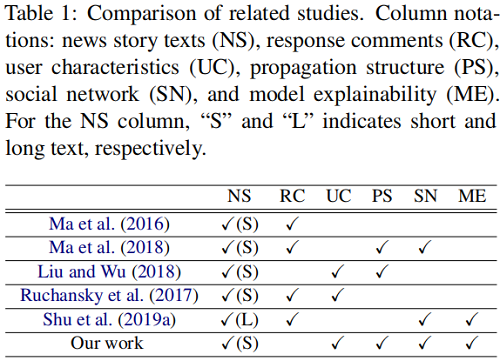
4 Problem Statement

5 GCAN Model
总体框架如下:
GCAN 包括五个部分:
- user characteristics extraction: creating features to quantify how a user participates in online social networking.
- new story encoding: generating the representation of words in the source tweet.
- user propagation representation : modeling and representing how the source tweet propagates by users using their extracted characteristics.
- dual co-attention mechanisms: capturing the correlation between the source tweet and users’ interactions/propagation.
- making prediction: generating the detection outcome by concatenating all learned representations.
5.1 User Characteristics Extraction
用户 ujuj 的特征为 xj∈Rvxj∈Rv:
(1) number of words in a user's self-description;
(2) number of words in u′jsuj′s screen name;
(3) number of users who follows ujuj;
(4) number of users that ujuj is following;
(5) number of created stories for ujuj ;
(6) time elapsed after u′jsuj′s first story;
(7) whether the ujuj account is verified or not;
(8) whether ujuj allows the geo-spatial positioning;
(9) time difference between the source tweet's post time and u′jsuj′s retweet time;
(10) the length of retweet path between ujuj and the source tweet (1 if ujuj retweets the source tweet);
5.2 Source Tweet Encoding
输入是 story sisi 中每个单词的一个热向量。由于每个 source story 的长度都是不同的,所以在这里通过设置最大长度 mm 来执行零填充。设 E=[e1,e2,…,em]∈RmE=[e1,e2,…,em]∈Rm 为 source story 的输入向量,其中 emem 为第 mm 个单词的独热编码。我们创建了一个完全连接的层来生成单词嵌入,V=[v1,v2,…,vm]∈Rd×mV=[v1,v2,…,vm]∈Rd×m,其中 dd 是单词嵌入的维数。VV 的推导方法为:
V=tanh(WwE+bw)(1)V=tanh(WwE+bw)(1)
其中,WwWw 为可学习权值的矩阵,bcbc 为偏差项。然后,利用门控循环单元(GRU)从 vv 学习单词序列表示。源推文表示学习可以用:st=GRU(vt),t∈{1,…,m}∣st=GRU(vt),t∈{1,…,m}∣,其中 mm 是 GRU 维数。将源推文表示为 S=[s1,s2,…,sm]∈Rd×mS=[s1,s2,…,sm]∈Rd×m。
5.3 User Propagation Representation
随着时间的推移,源推文 sisi 的传播是由一系列的用户触发的。我们的目的是利用提取的用户特征向量 xjxj,以及用户序列扩展sisi,来学习用户传播表示。
本文利用门控递归单元(GRU)和卷积神经网络(CNN)来学习传播表示。
这里输入的是用户转发 sisi 的特征向量序列,用 PF(si)=⟨x1,x2,…,xt,…,xn⟩PF(si)=⟨x1,x2,…,xt,…,xn⟩ 表示,其中 nn 是观察到的转发的固定长度。如果共享 sisi 的用户数量大于 nn,我们取前 nn 个用户。如果这个数字小于 nn,我们在 PF(si)PF(si) 中重新采样用户,直到它的长度等于 nn。
GRU-based Representation
给定特征向量 PF(si)=⟨…,xt,…⟩PF(si)=⟨…,xt,…⟩ 的序列,我们利用 GRU 来学习传播表示。每个 GRU 状态都有两个输入,当前的特征向量 xtxt 和前一个状态的输出向量 ht−1ht−1,和一个输出向量 ht−1ht−1。基于GRU的表示学习可以用: ht=GRU(xt),t∈{1,…,n}ht=GRU(xt),t∈{1,…,n} 来表示,其中 nn 是GRU的维数。我们通过平均池化生成最终的基于 GRUs 的用户传播嵌入 h∈Rdh∈Rd,由 h=1n∑nt=1hth=1n∑t=1nht 给出。
CNN-based Representation.
本文利用一维卷积神经网络来学习 PF(si)PF(si) 中用户特征的序列相关性。本文一次性考虑 λλ 个连续用户来建模他们的序列相关性,即 ⟨xt,…,xt+λ−1⟩⟨xt,…,xt+λ−1⟩。因此,过滤器被设置为Wf∈Rλ×v。然后输出表示向量 C∈Rd×(t+λ−1)C∈Rd×(t+λ−1) 由
C=ReLU(Wf⋅Xt:t+λ−1+bf)C=ReLU(Wf⋅Xt:t+λ−1+bf)
其中 WfWf 为可学习参数的矩阵,ReLU 为激活函数,Xt:t+λ−1Xt:t+λ−1 描述了第一行索引从 t=1t=1 到t=n−λ+1t=n−λ+1 的子矩阵,bfbf 为偏差项。
5.4 Graph-aware Propagation Representation
我们的目的是创建一个图来建模转发用户之间潜在的交互,想法是拥有特殊特征的用户之间的相关性对揭示源推文是否是假新闻能够起到作用。每个源推文 sisi 的转发用户集合 UiUi 都被用来构建一个图 Gi=(Ui,Ei)Gi=(Ui,Ei) 。由于用户间的真实交互是不清楚的,因而这个图是全连接的,也 就是任意节点相连, |Ei|=n×(n−1)2|Ei|=n×(n−1)2 。结合用户特征,每条边 eαβ∈Eieαβ∈Ei 都被关联到 一个权重 wαβwαβ,这个权重也就是节点用户特征向量 xαxα 和 xβxβ 的余弦相似度,即 wαβ=xα⋅xβ∥xα∥∥xβ∥wαβ=xα⋅xβ‖xα‖‖xβ‖ ,图的邻接矩阵 A=[wαβ]∈Rn×nA=[wαβ]∈Rn×n。
然后使用 GCN 来学习用户交互表示。给定邻接矩阵 AA 和用户特征矩阵 XX ,新的 gg 维节 点特征矩阵 H(l−1)∈Rn×gH(l−1)∈Rn×g 计算过程为:
H(l+1)=ρ(A~H(l)Wl)H(l+1)=ρ(A~H(l)Wl)
ll 是层数,A~=D−12AD−12A~=D−12AD−12,Dii=∑jAijDii=∑jAij 是度矩阵,Wl∈Rd×gWl∈Rd×g 是第 ll 层的学习参数, ρρ 是激活函数。这里 H0=XH0=X ,实验时选择堆叠两层 GCNGCN 层,最终学习到的表示为 G∈Rg×nG∈Rg×n。
5.5 Dual Co-attention Mechanism
我们认为假新闻的证据可以通过调查源推文的哪些部分是由哪些类型的转发用户关注的来揭开,并且线索可以由转发用户之间如何互动来反映。因此,本文提出了 dual co-attention 机制,来建模:
① 源推文 (S=[s1,s2,⋯,sm])(S=[s1,s2,⋯,sm]) 与用户传播 Embedding (C=[c1,c2,⋯,cn−λ+1](C=[c1,c2,⋯,cn−λ+1] ) 之间
② 源推文 (S=[s1,s2,⋯,sm])(S=[s1,s2,⋯,sm]) 与 graph-aware 的 Embedding 交互 (G=[g1,g2,⋯,gn]G=[g1,g2,⋯,gn]) 之间
通过 dual co-attention 的注意力权重,模型可以具有可解释性。
Source-Interaction Co-attention
首先计算一个相似性矩阵 F∈Rm×n:F∈Rm×n:
F=tanh(STWsgG)F=tanh(STWsgG)
这里 WsgWsg 是一个 d×gd×g 的参数矩阵,接着按照以下方式得到 HsHs 和 HgHg 。
Hs=tanh(WsS+(WgG)F⊤)Hg=tanh(WgG+(WsS)F)(4)Hs=tanh(WsS+(WgG)F⊤)Hg=tanh(WgG+(WsS)F)(4)
这里 Ws∈Rk×dWs∈Rk×d, Wg∈Rk×gWg∈Rk×g ,这里的 FF 和 FTFT 可以看做在做 user-interaction attention 空间和 source story word attention 空间的转换。接下来得到 attention 的权重:
as=softmax(w⊤hsHs)ag=softmax(w⊤hgHg)(5)as=softmax(whs⊤Hs)ag=softmax(whg⊤Hg)(5)
这里 as∈R1×mas∈R1×m,ag∈R1×nag∈R1×n , whs,whg∈R1×kwhs,whg∈R1×k 是学习的参数。最后可以得到源倠文 和用户交互的 attention 向量:
s^1=∑i=1masisi,g^=∑j=1nagjgj(6)s^1=∑i=1maissi,g^=∑j=1najggj(6)
s^1s^1 和 g^g^ 描述源推文中的单词是如何被用户参与互动的。
Source-Propagation Co-attention.
按照上述类似过程生成 SS 和 CC 的 attention 向量 s^2s^2 和 c^c^。
注意基于 GRU 的传播表示没有用来学习与 SS 的交互。这是因为对于假新闻的预测来说,转发序列的用户特征能够起到重要的作用。因此本文采用基于 GRU 和 CNN 的两种方式来学习传播表 示,其中基于 CNN 的传播表示被用来学习与 S 的交互,基于 GRU的传播表示在进行最终预测时 用作最终分类器的直接输入。
5.6 Make Prediction
最终使用 f=[s^1,g^,s^2,c^,h]f=[s^1,g^,s^2,c^,h] 来进行假新闻检测:
y^=softmax(ReLU(fWf+bf))y^=softmax(ReLU(fWf+bf))
损失函数采用交叉熵损失:
L(Θ)=−ylog(y^1)−(1−y)log(1−y^0)L(Θ)=−ylog(y^1)−(1−y)log(1−y^0)
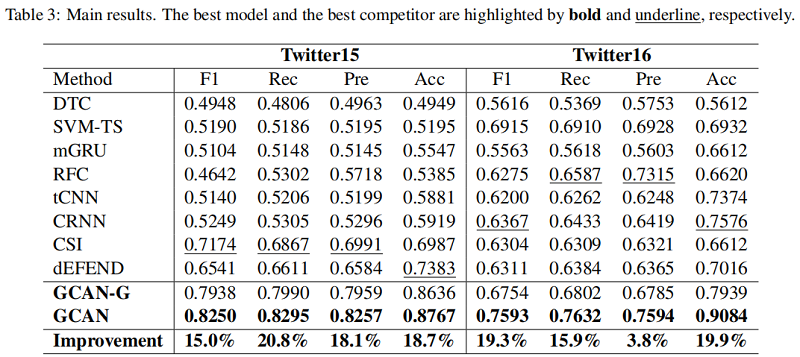
6 Experiments
Baseline:
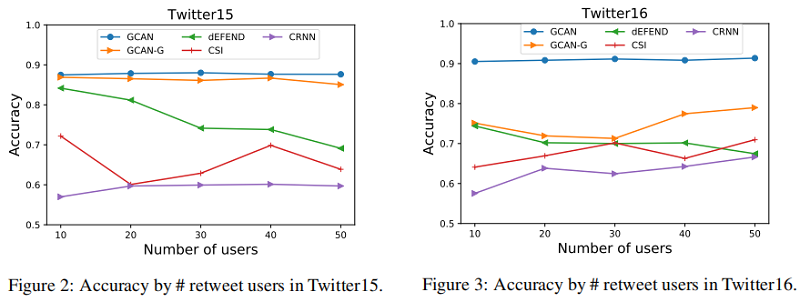
假新闻早期检测
GCAN也可以用于假新闻早期的检测,也就是在转发用户不多的时候进行检测,实验改动了使用的转发用户数量来进行验证:
消融实验
另外移除了一部分组件进行了消融实验,图中 -A,-R,-G,-C 分别代表 移除dual co-attention,基于GRU的表示,graph-aware的表示和基于CNN的表示:

-S-A 代表既没有源推文 Embedding 也没有 dual co-attention,由于源推文提供了基本线索,因此 -S-A 有一个明显的性能下降。
可解释性
source-propagation co-attention 学习到的 attention 权重可以用来为预测假新闻提供证据,采用的方式就是标识出源推文中的重要的词和可疑的用户。注意,我们不考虑 source-interaction Co-attention 的可解释性,因为从构造的图中学到的用户交互特征不能直观地解释。
下图是根据对源推文中的 attention 权重绘制的两个例子的词云(权重越大,词云中的词就越大):

图中结果满足常识,也就是假新闻倾向于使用戏剧性和模糊的词汇,而真实新闻则是被证实和核实事实的相关词汇。
另外我们希望利用传播中的转发顺序来揭示假新闻与真新闻的行为差异。下图采集并展示了三个假新闻和三个真新闻的传播序列 attention 的权重:
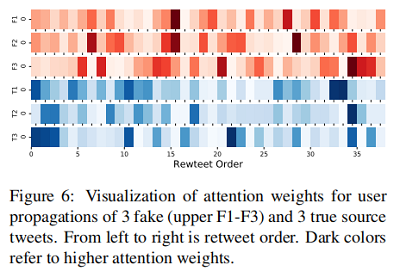
结果表明,要确定一个新闻是否虚假,首先应该检查早期转发源推文的用户的特征。假新闻的用户 attention 权重可能在传播过程中均匀分布。
source-propagation co-attention可以进一步解释可疑用户的特征及其关注的词语,举例如下图:

可以发现,可疑用户在转发传播中的特征有:
①账号未被验证;
②账号创建时间较短;
③用户描述长度较短;
④距发布源推文用户的图路径长度较短。
他们高度关注的词是“breaking”和“pipeline”这样的词。我们认为这样的解释有助于解读假新闻的检测,从而了解他们潜在的立场。
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK