

携程分布式图数据库Nebula Graph运维治理实践
source link: https://www.51cto.com/article/716729.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
携程分布式图数据库Nebula Graph运维治理实践
作者简介
Patrick Yu,携程云原生研发专家,关注非关系型分布式数据存储及相关技术。
随着互联网世界产生的数据越来越多,数据之间的联系越来越复杂层次越来越深,人们希望从这些纷乱复杂的数据中探索各种关联的需求也在与日递增。为了更有效地应对这类场景,图技术受到了越来越多的关注及运用。
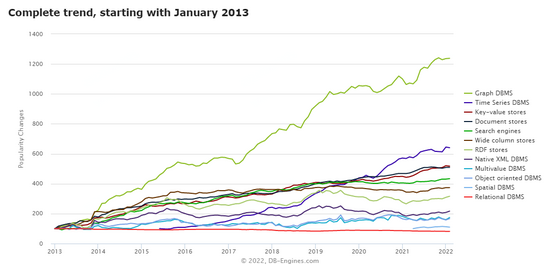
DB-ENGINES 趋势报告显示图数据库趋势增长遥遥领先
在携程,很早就有一些业务尝试了图技术,并将其运用到生产中,以Neo4j和JanusGraph为主。2021年开始,我们对图数据库进行集中的运维治理,期望规范业务的使用,并适配携程已有的各种系统,更好地服务业务方。经过调研,我们选择分布式图数据库Nebula Graph作为管理的对象,主要基于以下几个因素考虑:
1)Nebula Graph开源版本即拥有横向扩展能力,为大规模部署提供了基本条件;
2)使用自研的原生存储层,相比JanusGraph这类构建在第三方存储系统上的图数据库,性能和资源使用效率上具有优势;
3)支持两种语言,尤其是兼容主流的图技术语言Cypher,有助于用户从其他使用Cypher语言的图数据库(例如Neo4j)中迁移;
4)拥有后发优势(2019起开源),社区活跃,且主流的互联网公司都有参与(腾讯,快手,美团,网易等);
5)使用技术主流,代码清晰,技术债较少,适合二次开发;
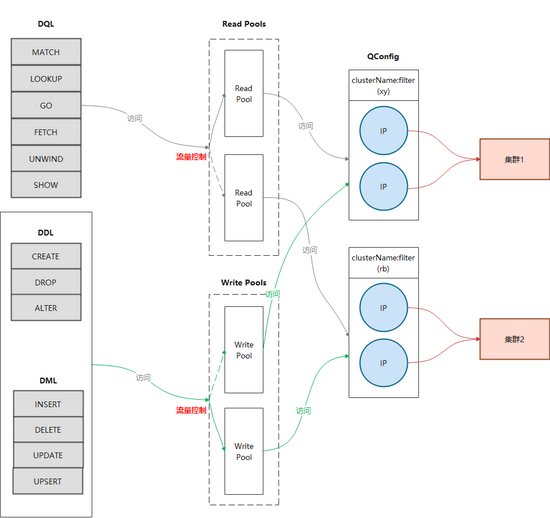
二、Nebula Graph架构及集群部署
Nebula Graph是一个分布式的计算存储分离架构,如下图:
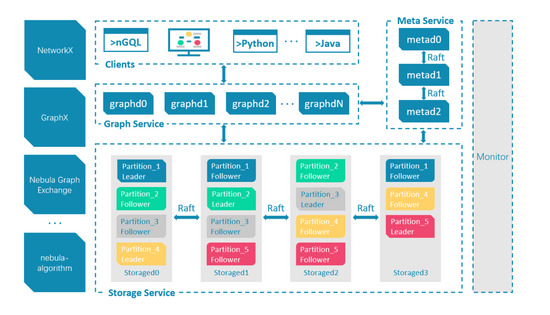
其主要由Graphd,Metad和Storaged三部分服务组成,分别负责计算,元数据存取,图数据(点,边,标签等数据)的存取。在携程的网络环境中,我们提供了三种部署方式来支撑业务:
2.1 三机房部署
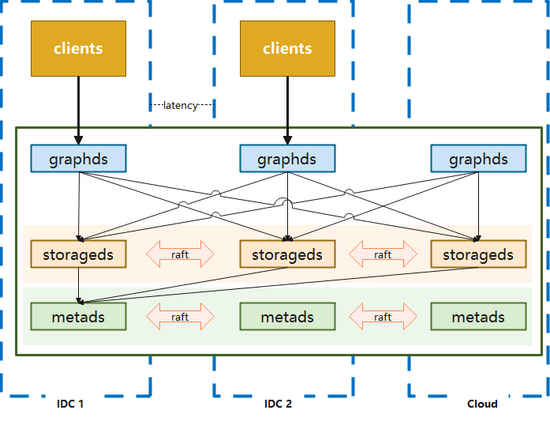
用于满足一致性和容灾的要求,优点是任意一个机房发生机房级别故障,集群仍然可以使用,适用于核心应用。但缺点也是比较明显的,数据通过raft协议进行同步的时候,会遇到跨机房问题,性能会受到影响。
2.2 单机房部署
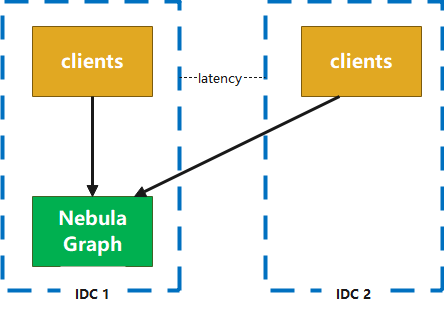
集群所有节点都在一个机房中,节点之间通讯可以避免跨机房问题(应用端与服务端之间仍然会存在跨机房调用),由于机房整体出现问题时该部署模式的系统将无法使用,所以适用于非核心应用进行访问。
2.3 蓝绿双活部署
在实际使用中,以上两种常规部署方式并不能满足一些业务方的需求,比如性能要求较高的核心应用,三机房的部署方式所带来的网络损耗可能会超出预期。根据携程酒店某个业务场景真实测试数据来看,本地三机房的部署方式延迟要比单机房高50%+,但单机房部署无法抵抗单个IDC故障,此外还有用户希望能存在类似数据回滚的能力,以应对应用发布,集群版本升级可能导致的错误。
考虑到使用图数据库的业务大多数据来自离线系统,通过离线作业将数据导入到图数据库中,数据一致的要求并不高,在这种条件下使用蓝绿部署能够在灾备和性能上得到很好的满足。
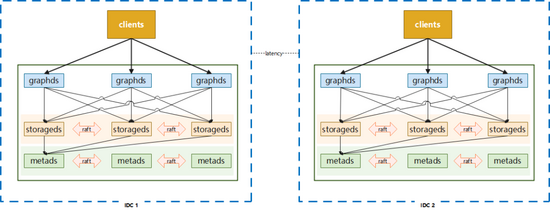
与此同时我们还增加了一些配套的辅助功能,比如:
分流:可以按比例分配机房的访问,也可以主动切断对某个机房的流量访问
灾备:在发生机房级故障时,可自动切换读访问的流量,写访问的流量切换则通过人工进行操作
蓝绿双活方式是在性能、可用性、一致性上的一个折中的选择,使用此方案时应用端架构也需要有更多的调整以配合数据的存取。
生产上的一个例子:

三机房情况

三、中间件及运维管理
我们基于k8s crd和operator来进行Nebula Graph的部署,同时通过服务集成到现有的部署配置页面和运维管理页面,来获得对pod的执行和迁移的控制能力。基于sidecar模式监控收集Nebula Graph的核心指标并通过telegraf发送到携程自研的Hickwall集中展示,并设置告警等一系列相关工作。
此外我们集成了跨机房的域名分配功能,为节点自动分配域名用于内部访问(域名只用于集群内部,集群与外部连通是通过ip直连的),这样做是为了避免节点漂移造成ip变更,影响集群的可用性。
在客户端上,相比原生客户端,我们主要做了以下几个改进和优化:
3.1 Session管理功能
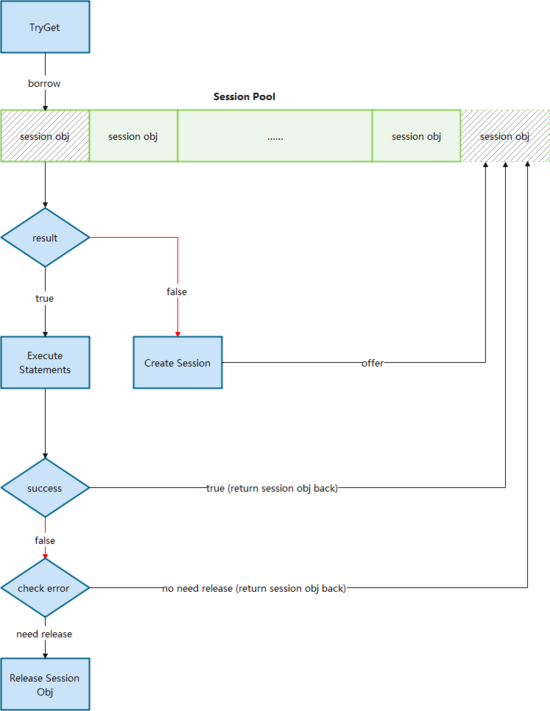
原生客户端Session管理比较弱,尤其是2.x早期几个版本,多线程访问Session并不是线程安全的,Session过期或者失效都需要调用方来处理,不适合大规模使用。同时虽然官方客户端创建的Session是可以复用的,并不需要release,官方也鼓励用户复用,但是却没有提供统一的Session管理功能来帮助用户复用,因此我们增加了Session Pool的概念来实现复用。
其本质上是管理一个或多个Session Object Queue,通过borrow-and-return的方式(下图),确保了一个Session在同一时间只会由一个执行器在使用,避免了共用Session产生的问题。同时通过对队列的管理,我们可以进行Session数量和版本的管理,比如预生成一定量的Session,或者在管理中心发出消息之后变更Session的数量或者访问的路由。
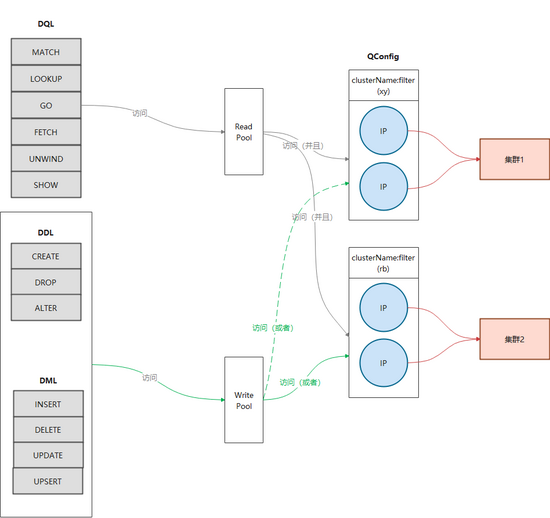
3.2 蓝绿部署(包括读写分离)
上面章节中介绍了蓝绿部署,相应的客户端也需要改造以支持访问2个集群。由于生产中,读和写的逻辑往往不同,比如读操作希望可以由2个集群共同提供数据,而写的时候只希望影响单边,所以我们在进行蓝绿处理的时候也增加了读写分离(下图)。
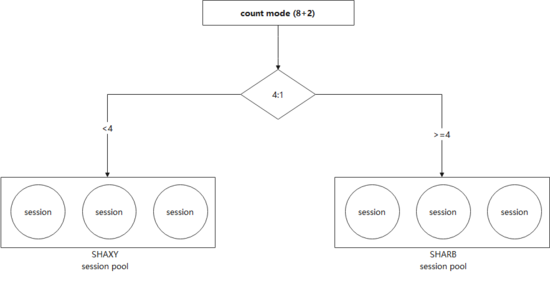
3.3 流量分配
如果要考虑到单边切换以及读写不同的路由策略,就需要增加流量分配功能。我们没有采用携程内广泛使用的Virtual IP作为访问路由,希望有更为强大的定制管理能力及更好的性能。
a)通过直连而不是Virtual IP中转可以减少一次转发的损耗
b)在维持长连接的同时也能实现每次请求使用不同的链路,平摊graphd的访问压力
c)完全自主控制路由,可以实现更为灵活的路由方案
d)当存在节点无法访问的时候,客户端可以自动临时排除有问题的IP,在短时间内避免再次使用。而如果使用Virtual IP的话,由于一个Virtual IP会对应多个物理IP,就没有办法直接这样操作。
通过构造面向不同idc的Session Pool,并根据配置进行权重轮询,就可以达到按比例分配访问流量的目的(下图)。
将流量分配集成进蓝绿模式,就基本实现了基本的客户端改造(下图)。
3.4 结构化语句查询
图DSL目前主流的有两种,Gremlin和Cypher,前者是过程式语言而后者是声明式语言。Nebula Graph支持了openCypher(Cypher的开源项目)语法和自己设计的nGQL原生语法,这两种都是声明式语言,在风格上比较类似SQL。尽管如此,对于一些较为简单的语句,类似Gremlin风格的过程式语法对用户会更为友好,并且有利用监控埋点。基于这个原因,我们封装了一个过程式的语句生成器。
Cypher风格 | MATCH (v:user{name:"XXX"})-[e:follow|:serve]->(v2) RETURN v2 AS Friends; |
新增的过程式风格 | Builder.match() .vertex("v") .hasTag("user") .property("name", "XXX", DataType.String()) .edge("e", Direction.OUTGOING) .type("follow") .type("serve") .vertex("v2") .ret("v2", "Friends") |
四、系统调优实践
由于建模,使用场景,业务需求的差异,使用Nebula Graph的过程中所遇到的问题很可能会完全不同,以下以携程酒店信息图谱线上具体的例子进行说明,在整个落地过程我们遇到的问题及处理过程(文中以下内容是基于Nebula Graph 2.6.1进行的)。
关于酒店该业务的更多细节,可以阅读《 信息图谱在携程酒店的应用 》这篇文章。
4.1 酒店集群不稳定
起因是酒店应用上线后发生了一次故障,大量的访问超时,并伴随着“The leader has changed”这样的错误信息。稍加排查,我们发现metad集群有问题,metad0的local ip和metad_server_address的配置不一致,所以metad0实际上一直没有工作。
但这本身并不会导致系统问题,因为3节点部署,只需要2个节点工作即可,后来metad1容器又意外被漂移了,导致ip变更,这个时候实际上metad集群已经无法工作(下图),导致整个集群都受到了影响。

在处理完以上故障并重启之后,整个系统却并没有恢复正常,cpu的使用率很高。此时外部应用并没有将流量接入进来,但整个metad集群内部网络流量却很大,如下图所示:
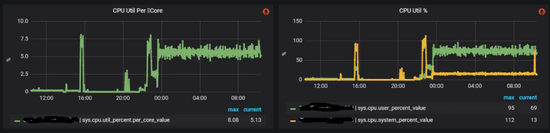
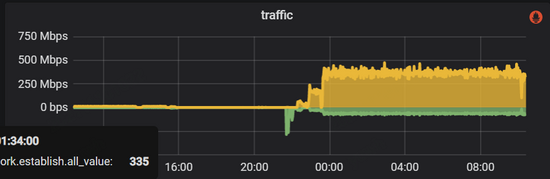
监控显示metad磁盘空间使用量很大,检查下来WAL在不断增加,说明这些流量主要是数据的写入操作。我们打开WAL数据的某几个文件,其大部分都是Session的元数据,因为Session信息是会在Nebula集群内持久化的,所以考虑问题可能出在这里。阅读源码我们注意到,graphd会从metad中同步所有的session信息,并在修改之后将数据再全部回写到metad中,所以如果流量都是session信息的话,那么问题就可能:
a)Session没有过期
b)创建了太多的Session
检查发现该集群没有配置超时时间, 所以我们修改以下配置来处理 这个问题:
Graphd | session_idle_timeout_secs | 默认(0) | 86400 | 此配置控制session的过期,由于初始我们没有设置这个参数,这意味着session永远不会过期,这会导致过去访问过该graphd的session会永远存在于metad存储层,造成session元数据累积。 |
session_reclaim_interval_secs | 默认(10) | 原设置说明每10s graphd会将session信息发送给metad持久化。这也会导致写入数据量过多。考虑到即使down机也只是损失部分的Session元数据更新,这些损失带来的危害比较小,所以我们改成了30s以减少于metad之间同步元数据的次数。 | ||
Metad | wal_ttl | 默认(14400) | wal用于记录修改操作的,一般来说是不需要保留太久的,况且nebula graph为了安全,都至少会为每个分片保留最后2个wal文件,所以减少ttl加快wal淘汰,将空间节约出来 |
修改之后,metad的磁盘空间占用下降,同时通信流量和磁盘读写也明显下降(下图):
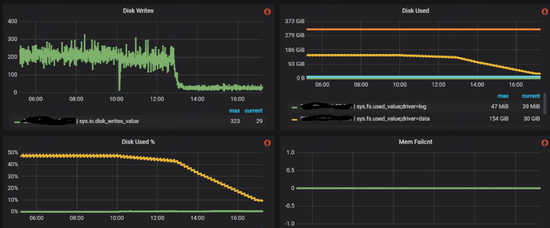
系统逐步恢复正常,但是还有一个问题没有解决,就是为什么有如此之多的session数据?查看应用端日志,我们注意到session创建次数超乎寻常,如下图所示:

通过日志发现是我们自己开发的客户端中的bug造成的。我们会在报错时让客户端释放对应的session,并重新创建,但由于系统抖动,这个行为造成了比较多的超时,导致更多的session被释放并重建,引起了恶性循环。针对这个问题,对客户端进行了如下优化:
将创建session行为由并发改为串行,每次只允许一个线程进行创建工作,不参与创建的线程监听session pool | |
进一步增强session的复用,当session执行失败的时候,根据失败原因来决定是否需要release。 原有的逻辑是一旦执行失败就release当前session,但有些时候并非是session本身的问题,比如超时时间过短,nGQL有错误这些应用层的情况也会导致执行失败,这个时候如果直接release,会导致session数量大幅度下降从而造成大量session创建。根据问题合理的划分错误情况来进行处理,可以最大程度保持session状况的稳定 | |
增加预热功能,根据配置提前创建好指定数量的session,以避免启动时集中创建session导致超时 |
4.2 酒店集群存储服务CPU使用率过高
酒店业务方在增加访问量的时候,每次到80%的时候集群中就有少数storaged不稳定,cpu使用率突然暴涨,导致整个集群响应增加,从而应用端产生大量超时报错,如下图所示:
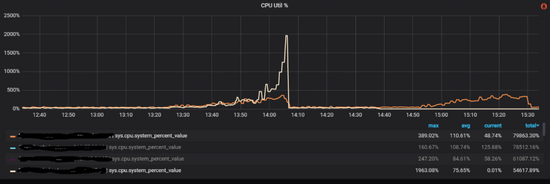
和酒店方排查下来初步怀疑是存在稠密点问题(在图论中,稠密点是指一个点有着极多的相邻边,相邻边可以是出边或者是入边),部分storaged被集中访问引起系统不稳定。由于业务方强调稠密点是其业务场景难以避免的情况,我们决定采取一些调优手段来缓解这个问题。
1)尝试通过Balance来分摊访问压力
回忆之前的官方架构图,数据在storaged中是分片的,且raft协议中只有leader才会处理请求,所以重新进行数据平衡操作,是有可能将多个稠密点分摊到不同的服务上意减轻单一服务的压力。同时我们对整个集群进行compaction操作(由于Storaged内部使用了RocksDB作为存储引擎,数据是通过追加来进行修改的,Compaction可以清楚过时的数据,提高访问效率)。
操作之后集群的整体cpu是有一定的下降,同时服务的响应速度也有小幅的提升,如下图。
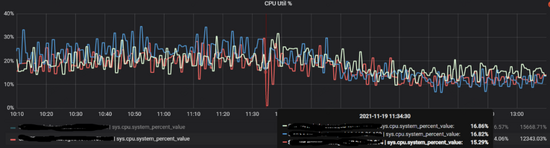
但在运行一段时间之后仍然遇到了cpu突然增加的情况,稠密点显然没有被平衡掉,也说明在分片这个层面是没法缓解稠密点带来的访问压力的 。
2)尝试通过配置缓解锁竞争
进一步调研出现问题的storaged的cpu的使用率,可以看到当流量增加的时候,内核占用的cpu非常高,如下图所示:
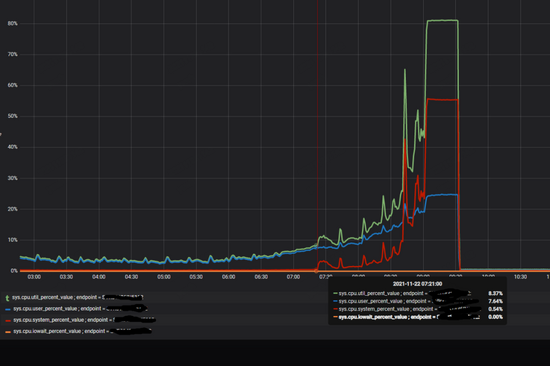
抓取perf看到,锁竞争比较激烈,即使在“正常”情况下,锁的占比也很大,而在竞争激烈的时候,出问题的storaged服务上这个比例超过了50%。如下图所示:
所以我们从减少冲突入手,对nebula graph集群主要做了如下改动:
Storaged | rocksdb_block_cache | 默认(4) | block cache用缓存解压缩之后的数据,cache越大,数据淘汰情况越低,这样就越可能更快的命中数据,减少反复从page cache加载及depress的操作 | |
enable_rocksdb_prefix_filtering | false | 在内存足够的情况下,我们打开prefix过滤,是希望通过其通过前缀更快的定位到数据,减少查询非必要的数据,减少数据竞争 | ||
RocksDB | disable_auto_compactions | false | 打开自动compaction,缓解因为数据碎片造成的查询cpu升高 | |
write_buffer_size | 134217728 | 将memtable设置为128MB,减少其flush的次数 | ||
max_background_compactions | 控制后台compactions的线程数 |
重新上线之后,整个集群服务变得比较平滑,cpu的负载也比较低,正常情况下锁竞争也下降不少(下图),酒店也成功的将流量推送到了100%。
但运行了一段时间之后,我们仍然遇到了服务响应突然变慢的情况,热点访问带来的压力 的确超过了优化带来的提升。
3)尝试减小锁的颗粒度
考虑到在分片级别的balance不起作用,而cpu的上升主要是因为锁竞争造成的,那我们想到如果减小锁的颗粒度,是不是就可以尽可能减小竞争?RocksDB的LRUCache允许调整shared数量,我们对此进行了修改:
LRUCache默认分片数 | ||
2.5.0 | 修改代码,将分片改成2 10 | |
2.6.1及以上 | 通过配置cache_bucket_exp = 10,将分片数改为2 10 |
观察下来效果不明显,无法解决热点竞争导致的雪崩问题。其本质同balance操作一样,只是粒度的大小的区别,在热点非常集中的情况下,在数据层面进行处理是走不通的。
4)尝试使用ClockCache
竞争的锁来源是block cache造成的。nebula storaged使用rocksdb作为存储,其使用的是LRUCache作为block cache等一系列cache的存储模块,LRUCache在任何类型的访问的时候需要需要加锁操作,以进行一些LRU信息的更新,排序的调整及数据的淘汰,存在吞吐量的限制。
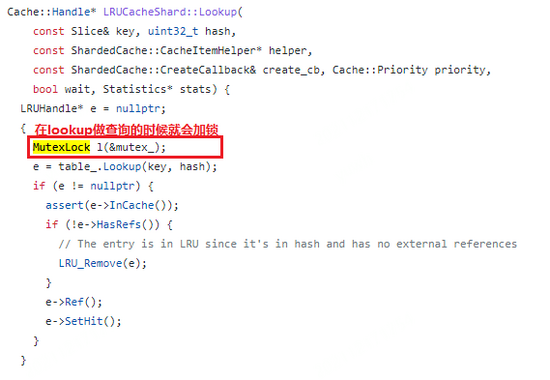
由于我们主要面临的就是锁竞争,在业务数据没法变更的情况下,我们希望其他cache模块来提升访问的吞吐。按照rocksdb官方介绍,其还支持一种cache类型ClockCache,特点是在查询时不需要加锁,只有在插入时才需要加锁,会有更大的访问吞吐,考虑到我们主要是读操作,看起来ClockCache会比较合适。
LRU cache和Clock cache的区别: https://rocksdb.org.cn/doc/Block-Cache.html
经过修改源码和重新编译,我们将缓存模块改成了ClockCache,如下图所示:
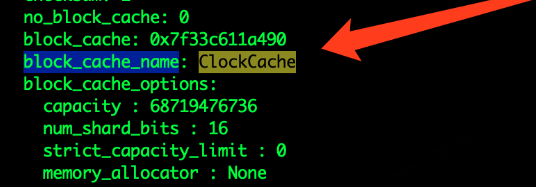
但集群使用时没几分钟就core, 查找资料我们发现目前ClockCache支持还存在问题( https://github.com/facebook/rocksdb/pull/8261) , 此方案目前无法使用。
5)限制线程使用
可以看到整个系统在当前配置下,是存在非常多的线程的,如下图所示。
如果是单线程,就必然不会存在锁竞争。但作为一个图服务,每次访问几乎会解析成多个执行器来并发访问,强行改为单线程必然会造成访问堆积。
所以我们考虑将原有的线程池中的进程调小,以避免太多的线程进行同步等待带来的线程切换,以减小系统对cpu的占用。
Storaged | num_io_threads | 默认(16) | ||
num_worker_threads | 默认(32) | |||
reader_handlers | 默认(32) | 8或者12 | 官方未公开配置 |
调整之后整个系统cpu非常平稳,绝大部分物理机cpu在20%以内,且没有之前遇到的突然上下大幅波动的情况(瞬时激烈锁竞争会大幅度提升cpu的使用率),说明这个调整对当前业务来说是有一定效果的。
随之又遇到了下列问题,前端服务突然发现nebula的访问大幅度超时,而从系统监控的角度却毫无波动(下图24,19:53系统其实已经响应出现问题了,但cpu没有任何波动)。
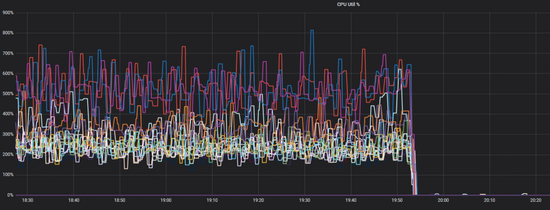
原因是在于,限制了thread 确实有效果,减少了竞争,但随着压力的正大,线程吞吐到达极限,但如果增加线程,资源的竞争又会加剧,无法找到平衡点。
6)关闭数据压缩,关闭block cache
在没有特别好的方式避免锁竞争的情况,我们重新回顾了锁竞争的整个发生过程,锁产生本身就是由cache自身的结构带来的,尤其是在读操作的时候,我们并不希望存在什么锁的行为。
使用block cache,是为了在合理的缓存空间中尽可能的提高缓存命中率,以提高缓存的效率。但如果缓存空间非常充足,且命中长期的数据长期处于特定的范围内,实际上并没有观察到大量的缓存淘汰的情况,且当前服务的缓存实际上也并没有用满,所以想到,是不是可以通过关闭block cache,而直接访问page cache来避免读操作时的加锁行为。
除了block cache,存储端还有一大类内存使用是Indexes and filter blocks,与此有关的设置在RocksDB中是cache_index_and_filter_blocks。当这个设置为true的时候,数据会缓存到block cache中,所以如果关闭了block cache,我们就需要同样关闭cache_index_and_filter_blocks(在Nebula Graph中,通过配置项enable_partitioned_index_filter替代直接修改RocksDB的cache_index_and_filter_blocks)。
但仅仅修改这些并没有解决问题,实际上观察perf我们仍然看到锁的竞争造成的阻塞(下图):
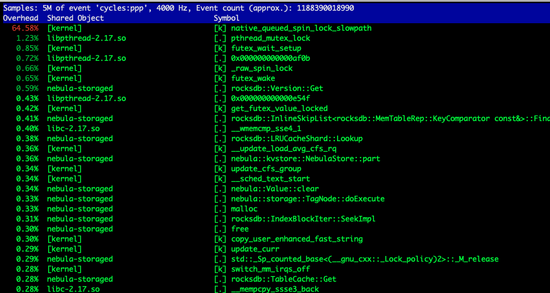
这是因为当cache_index_and_filter_blocks为false的时候,并不代表index和filter数据不会被加载到内存中,这些数据其实会被放进table cache里,仍然需要通过LRU来维护哪些文件的信息需要淘汰,所以LRU带来的问题并没有完全解决。处理的方式是将max_open_files设置为-1,以提供给系统无限制的table cache的使用,在这种情况下,由于没有文件信息需要置换出去,算法逻辑被关闭。
总结下来核心修改如下表:
Storaged | rocksdb_block_cache | 关闭block cache | ||
rocksdb_compression_per_level | no:no:no:no:lz4:lz4:lz4 | 在L0~L3层关闭压缩 | ||
enable_partitioned_index_filter | false | 避免将index和filter缓存进block cache | ||
RocksDB | max_open_files | 避免文件被table cache淘汰,避免文件描述符被关闭,加快文件的读取 |
关闭了block cache后,整个系统进入了一个非常稳定的状态,线上集群在访问量增加一倍以上的情况下,系统的cpu峰值反而稳定在30%以下,且绝大部分时间都在10%以内(下图)。
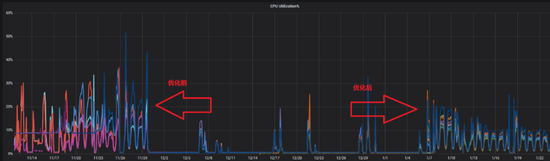
需要说明的是,酒店场景中关闭block cache是一个非常有效的手段,能够对其特定情况下的热点访问起到比较好的效果,但这并非是一个常规方式,我们在其他业务方的nebula graph集群中并没有关闭block cache。
4.3 数据写入时服务down机
起因酒店业务在全量写入的时候,即使量不算很大(4~5w/s),在不特定的时间就会导致整个graphd集群完全down机,由于graphd集群都是无状态的,且互相之间没有关系,如此统一的在某个时刻集体down机,我们猜测是由于访问请求造成。通过查看堆栈发现了明显的异常(下图):

可以看到上图中的三行语句被反复执行,很显然这里存在递归调用,并且无法在合理的区间内退出,猜测为堆栈已满。在增加了堆栈大小之后,整个执行没有任何好转,说明递归不仅层次很深,且可能存在指数级的增加的情况。同时观察down机时的业务请求日志,失败瞬间大量执行失败,但有一些执行失败显示为null引用错误,如下图所示:
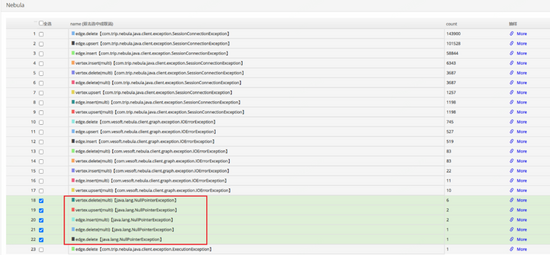
这是因为返回了报错,但没有error message,导致发生了空引用(空引用现象是客户端未合理处理这种情况,也是我们客户端的bug),但这种情况很奇怪,为什么会没有error message,检查其trace日志,发现这些请求执行nebula时间都很长,且存在非常大段的语句,如下图所示:
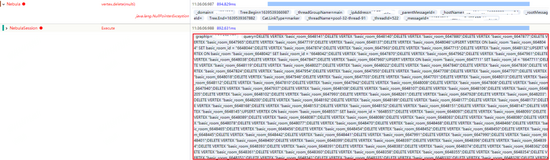
预感是这些语句导致了graphd的down机,由于执行被切断导致客户端生成了一个null值。将这些语句进行重试,可以必现down机的场景。检查这样的请求发现其是由500条语句组成(业务方语句拼接上限500),并没有超过配置设置的最大执行语句数量(512)。
看起来这是一个nebula官方的bug,我们已经将此问题提交给官方。同时业务方语句拼接限制从500降为200后顺利避免该问题导致的down机。
五、Nebula Graph二次开发
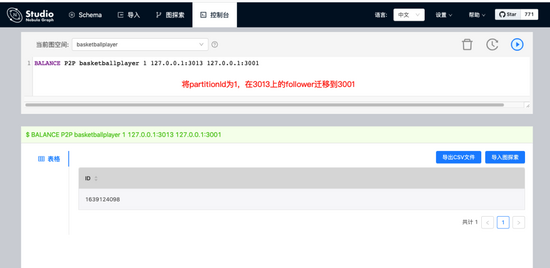
当前我们对Nebula Graph的修改主要集中的几个运维相关的环节上,比如新增了命令来指定迁移Storaged中的分片,以及将leader迁移到指定的实例上(下图)。
六、未来规划
- 与携程大数据平台整合,充分利用Spark或者Flink来实现数据的传输和ETL,提高异构集群间数据的迁移能力。
- 提供Slowlog检查功能,抓取造成slowlog的具体语句。
- 参数化查询功能,避免依赖注入。
- 增强可视化能力,增加定制化功能。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK