

Elasticsearch深度应用(下) - 女友在高考
source link: https://www.cnblogs.com/javammc/p/16460380.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Query文档搜索机制剖析
1. query then fetch(默认搜索方式)
搜索步骤如下:
- 发送查询到每个shard
- 找到所有匹配的文档,并使用本地的Term/Document Frequery信息进行打分
- 对结果构建一个优先队列
- 返回关于结果的元数据到请求节点。注意,实际文档还没有发送,只是分数
- 来自所有shard的分数合并起来,并在请求节点上进行排序,文档被按照查询要去进行选择
- 最终,实际文档从它们各自所在的独立的shard上检索出来
- 结果被返回给用户
优点:返回的数据量是准确的
缺点:性能一般,并且数据排名不准确
2. dfs query then fetch
比前面的方式多了一个DFS步骤。也就是查询之前,先对所有分片发送请求,把所有分片中的词频和文档频率等打分依据全部汇总到一块,再执行后面的操作。
详细步骤如下:
- 预查询每个shard,询问Term和Document frequency
- 发送查询到每个shard
- 找到所有匹配的文档,并使用全局的Term/Document Frequency信息进行打分
- 对结果构建一个优先队列
- 返回关于结果的元数据到请求节点。注意,实际文档还没有发送,只是分数。
- 来自所有shard的分数合并起来,并在请求节点进行排序,文档被按照查询要求进行选择
- 最终,实际文档从它们各自所在的独立的shard上检索出来
- 结果被返回给用户
优点:返回的数据和数据排名都是准确的
缺点:性能较差
文档增删改和搜索的请求过程
增删改流程
- 客户端首先会选择一个节点发送请求过去,这个节点可能是协调节点
- 协调节点会对document数据进行路由,将请求转发给对应的node
- 实际上node的primary shard会处理请求,然后将数据同步到对应的含有replica shard的node上
- 协调节点如果发现含有primary shard的节点和含有replica shard的节点的符合要求的数量后,就会将响应结果返回给客户端
搜索流程
- 客户端首先会选择一个节点发送请求获取,这个节点可能是协调节点
- 协调节点将搜索请求转发到所有shard对应的primary shard或replica shard都可以
- query phase:每个shard将自己搜索结果的元数据发到请求节点(doc id和打分信息),由请求节点进行数据的合并、排序、分页等操作,产出最后结果
- fetch phase:请求节点根据doc id去各个节点上拉取实际的document数据,最终返回给客户端。
说到排序,我们必须要说Doc Values这个东西。那么Doc Values是什么呢?又有什么作用?
我们都知道ES之所以那么快速,归功于他的倒排索引的设计,然而他也不是万能的,倒排索引的检索性能是非常快的,但是在字段值排序时却不是理想的结构。

如上表可以看出,他只有词对应的doc,但是并不知道每一个doc中的内容,那么如果想要排序的话每一个doc都去获取一次文档内容岂不非常耗时?Doc Values的出现就是解决这个问题。
Doc Values是可以根据doc_values属性进行配置的,默认为true。当配置为false时,无法基于该字段排序、聚合、在脚本中访问字段值。
Doc Values是转置倒排索引和正排索引的关系来解决这个问题。倒排索引将词项映射到包含它们的文档,Doc Values将文档映射到它们包含的词项:

当数据被转置后,想要收集到每个文档行,获取所有的词项就比较简单了。所以搜索使用倒排索引查找文档,聚合操作和排序就要使用Doc Values里面的数据。
深入理解Doc Values
Doc Values是在索引时与倒排索引同时生成。也就是说Doc Values和倒排索引一样,基于Segement生成并且是不可变的。同时Doc Values和倒排索引一样序列化到磁盘,这样对性能和扩展性有很大帮助。
Doc Values通过序列化把数据结构持久化到磁盘,我们可以充分利用操作系统的内存,而不是JVM的Heap。当workingset远小于系统的可用内存,系统会自动将Doc Values保存在内存中,使得其读写十分高速;不过,当其远大于可用内存时,操作系统会自动把Doc Values写入磁盘。很显然,这样性能会比在内存中差很多,但是它的大小就不再局限于服务器的内存了。如果是使用JVM的Heap来实现是因为容易OutOfMemory导致程序崩溃了。
禁用Doc Values
Doc Values默认对所有字段启用,除了analyzed strings。也就是说所有的数字、地理坐标、日志、IP和不分析字符类型都会默认开启。
analyzed strings暂时不能使用Doc Values,因为分析后会生成大量的Token,这样非常影响性能。虽然Doc Values非常好用,但是如果你存储的数据确实不需要这个特性,就不如禁用他,这样不仅节省磁盘空间,也许会提升索引的速度。
要禁用Doc Values,在mapping设置即可。示例:
PUT my_index
{
"mappings": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}
Filter过滤机制剖析
- 在倒排索引中查找搜索串,获取docment list
如下面这个例子,需要过滤date为2020-02-02的数据,去倒排索引中查找,发现2020-02-02对应的document list是doc2、doc3.
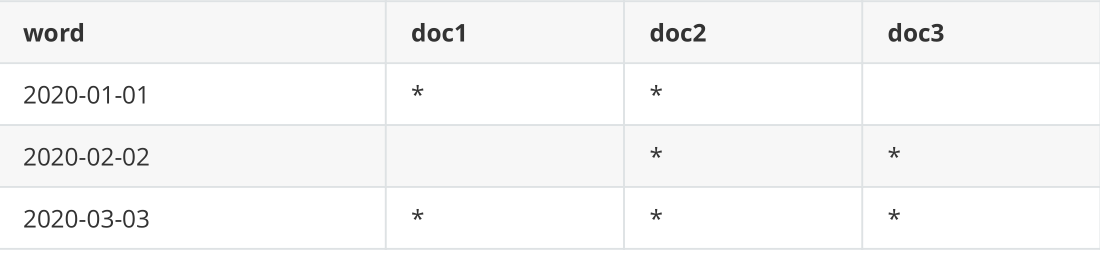
- Filter为每个倒排索引中搜索到的结果,构建一个bitset
如上面的例子,根据document list,构建的bitset是[0,1,1],1代表匹配,0代表不匹配
- 多个过滤条件时,遍历每个过滤条件对应的bitset,优先从最稀疏的开始搜索,查找满足所有条件的document。
另外多个过滤条件时,先过滤比较稀疏的条件,能先过滤掉尽可能多的数据。
-
caching bitset,跟踪query,在最近256个query中超过一定次数的过滤条件,缓存其bitset。对于小的segment(记录数小于1000或小于总大小3%),不缓存。
-
如果document有新增或修改,那么cached bitset会被自动更新
-
filter大部分情况下,在query之前执行,先尽量过滤尽可能多的数据
控制搜索精准度
基于boost的权重控制
考虑如下场景:
我们搜索帖子,搜索标题包含java或spark或Hadoop或elasticsearch。但是需要优先输出包含java的,再输出spark的的,再输出Hadoop的,最后输出elasticsearch。
我们先看如果不考虑优先级时怎么搜索:
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "java"
}
}
},
{
"term": {
"title": {
"value": "elasticsearch"
}
}
},
.....省略
]
}
}
}
搜索出来的结果跟我们想要的顺序不一致,那么我们下一步加权重。增加boost
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "java",
"boost": 5
}
}
},
{
"term": {
"title": {
"value": "spark",
"boost": 4
}
}
}
]
}
}
}
基于dis_max的策略控制
dix_max想要解决的是:
如果我们想要某一个filed中匹配到尽可能多的关键词的被排在前面,而不是在多个filed中重复出现相同的词语的排在前面。
举例说明:
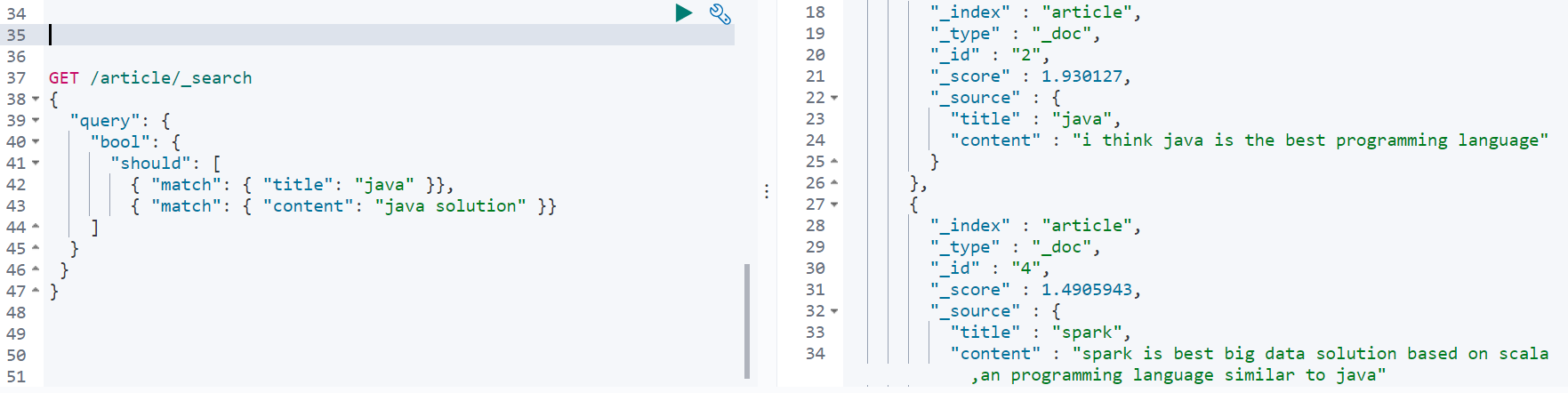
对于一个文档会将title匹配到的分数和content匹配到的分数相加。所以doc id为2的文档的分数比doc id为4的大。
dis_max查询:
GET /article/_search
{
"query": {
"dis_max": {
"queries": [
{"match": {"title": "java"}},
{"match":{"content":"java solution"}}
]
}
}
}
查询到的结果如下:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.4905943,
"hits" : [
{
"_index" : "article",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.4905943,
"_source" : {
"title" : "spark",
"content" : "spark is best big data solution based on scala,an programming language similar to java"
}
},
{
"_index" : "article",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.2039728,
"_source" : {
"title" : "java",
"content" : "i think java is the best programming language"
}
}
]
}
}
基于function_score自定义相关度分数
在用ES进行搜索时,搜索结果默认会以文档的相关度进行排序,而这个"文档的相关度",是可以通过function_score自定义的。
function_score提供了几种类型的得分函数:
- script_score
- weight
- random_score
- field_value_factor
- decay functions:gauss、linear、exp
random_score
随机打分,也就是每次查询出来的排序都不一样。
举一个例子:
GET /article/_search
{
"query": {
"function_score": {
"query": {"match_all": {}},
"random_score": {}
}
}
}
field_value_factor
该函数可以根据文档中的字段来计算分数。
GET /item/_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "price",
"factor": 1.2,
"modifier": "none"
}
}
}
}
| 属性 | 说明 |
|---|---|
| field | 要从文档中提取的字段 |
| factor | 字段值乘以的值,默认为1 |
| modifier | 应用于字段值的修复符 |
modifier的取值有如下多种:
| Modifier | 说明 |
|---|---|
| none | 不要对字段值应用任何乘数 |
| log | 取字段值的常用对数。因为此函数将返回负值并在0到1之间的值上使用时导致错误,所以建议改用log1p |
| log1p | 将字段值上加1并取对数 |
| log2p | 将字段值上加2并取对数 |
| ln | 取字段值的自然对数。因为此函数将返回负值并在0到1之间的值上使用时引起错误,所以建议改用 ln1p |
| ln1p | 将1加到字段值上并取自然对数 |
| ln2p | 将2加到字段值上并取自然对数 |
| square | 对字段值求平方 |
| sqrt | 取字段值的平方根 |
| reciprocal | 交换字段值,与1 / x相同,其中x是字段的值 |
field_value_score函数产生的分数必须为非负数,否则将引发错误。如果在0到1之间的值上使用log和ln修饰符将产生负值。请确保使用范围过滤器限制该字段的值以避免这种情况,或者使用log1p和ln1p
分页性能问题
在ES中我们一般采用的分页方式是from+size的形式,当数据量比较大时,Es会对分页作出限制,因为此时性能消耗很大。
举个例子:一个索引分10个shards,然后一个搜索请求,from=990,size=10。
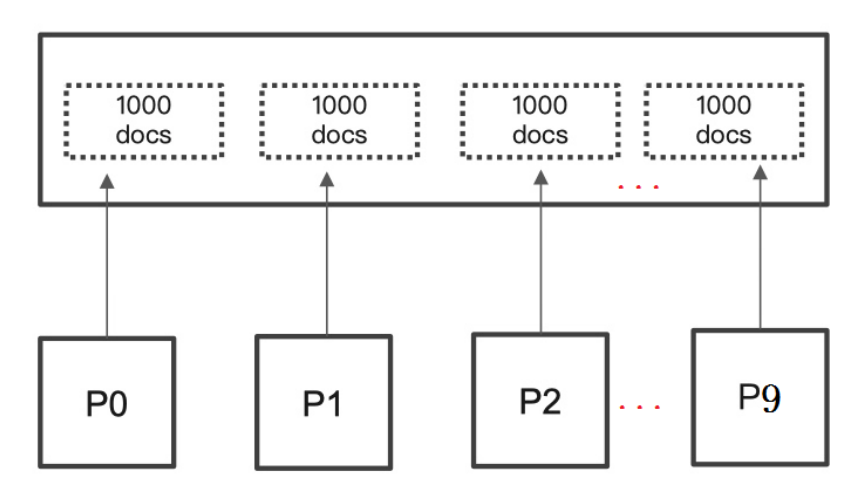
此时es会从每个shards上去查询1000条数据,尽管每条数据只有_doc_id和_score,但是经不住它量大啊。如果from是10000呢?就更加耗费资源了。
解决方案
1. 利用scroll遍历
scroll分为初始化和遍历两步。
POST /item/_search?scroll=1m&size=2
{
"query": { "match_all": {}}
}
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "步骤1中查询出的值"
}
2. search after方式
在ES 5.x后提供的一种,根据上一页的最后一条数据来确定下一页的位置的方式。如果分页请求的过程中,有数据的增删改,也会实时的反映到游标上。这种方式依赖上一页的数据,所以不能跳页。
GET /item/_search
{
"query": {
"match_all": {}
},
"size": 2
,"sort": [
{
"_id": {
"order": "desc"
}
}
]
}
查询结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "item",
"_type" : "_doc",
"_id" : "uL6choEB9TD2fYkcrziw",
"_score" : null,
"_source" : {
"title" : "小米8手机",
"images" : "http://image.lagou.com/12479122.jpg",
"price" : 2688,
"createTime" : "2022-02-02 12:02:02"
},
"sort" : [
"uL6choEB9TD2fYkcrziw"
]
},
{
"_index" : "item",
"_type" : "_doc",
"_id" : "tr6YgYEB9TD2fYkcFzjY",
"_score" : null,
"_source" : {
"title" : "小米手机",
"images" : "http://image.lagou.com/12479122.jpg",
"price" : 2688,
"createTime" : "2022-02-01 12:02:02"
},
"sort" : [
"tr6YgYEB9TD2fYkcFzjY"
]
}
]
}
}
GET /item/_search
{
"query": {
"match_all": {}
},
"size": 2,
"search_after":["tr6YgYEB9TD2fYkcFzjY"]
,"sort": [
{
"_id": {
"order": "desc"
}
}
]
}
总结对比:
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反映数据的实时性(快照版本)维护成本高,需要维护一个scroll_id | 海量数据的导出需要查询海量结果集的数据 |
| search_after | 高 | 性能最好 | 不存在深度分页问题能够反映数据的实时变更实现连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 海量数据的分页 |
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK