

知乎日报数据下载存储
source link: http://nathanlvzs.github.io/ZhihuDaily-Data-Download.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

以前经常使用【知乎日报】,上面有挺多的好文章,但是它的APP的账号系统跟【知乎】的不一致,导致收藏的文章只能在【知乎日报】APP上查看,而且查看往期的文章比较麻烦,查找也十分不便。于是想将知乎日报的全部内容下载到本地,方便查看阅读,而且又可以将文本数据可以用来处理、学习。
注:本人下载的所有数据仅供本人学习之用,如有侵权请告知。
-
下载新闻数据,保存到MongoDB或保存成文件
-
根据已下载数据生成网页供本地查看
-
对文本数据进行清洗处理供分析使用
-
我是占位符,待更新(文本数据分类,提取主题)
代码见【我是占位符,待更新】
将通过以下文章进行阐述:
环境:Windows8.1 ×64,Python 2.7.8,PyMongo 3.0.2。
对于知乎日报数据的下载保存,可以分为如下几个部分处理:
下载保存新闻id列表
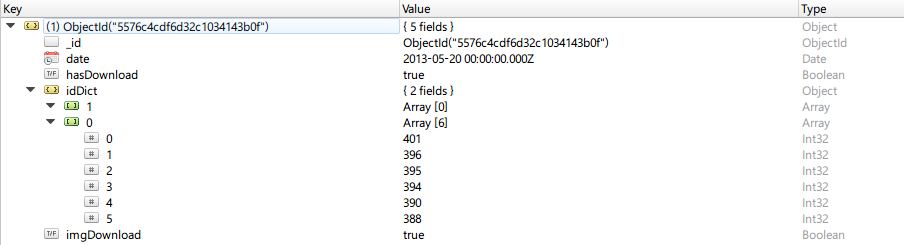
新闻列表请求的url为 http://news.at.zhihu.com/api/4/news/before/20131119,最后面的参数为日期,日期应该大于等于20130520。返回的是json数据,里面是我们日期参数的前一天的新闻列表,其中新闻有两类(分为0和1),不过类型为1的新闻很少很少。从json数据中提取出各条新闻的id,生成一个dict,如下例所示:
{
"1" : [],
"0" : [401, 396, 395, 394, 390, 388]
}定义如下的类,生成该类的对象并将其存储到MongoDB中。
class DateNewsIdDict(object):
def __init__(self, date, ids):
"""
用以保存日期以及其这一天的新闻id
date: 为请求参数的字符串对应的日期,并不是文章的日期,文章的日期为请求日期减一天
ids: 文章编号的dict对象
"""
self.date = datetime(date.year, date.month, date.day)
self.idDict = ids
self.hasDownload = False # 文章文本内容是否已下载的标志
self.imgDownload = False # 图片是否已下载的标志
return存入MongoDB中,如下图所示:
下载保存文章html内容
从数据库中读取某一天的新闻id字典,然后进行遍历,根据id下载文章的html内容,请求url为 http://news-at.zhihu.com/api/4/news/id,将id的值代入即可。返回的是json数据,响应实例如下所示:
{
"body": "<div class=\"main-wrap content-wrap\">...</div>",
"image_source": "Yestone.com 版权图片库",
"title": "光吃蛋白粉就想增肌,性质跟拜菩萨差不多(多图)",
"image": "http://pic1.zhimg.com/b6a3a5201b93c9eb6af0215e9b4373a4.jpg",
"share_url": "http://daily.zhihu.com/story/4776328",
"js": [],
"recommenders": [
{
"avatar": "http://pic2.zhimg.com/cbc5d3c6f333215a1c480cb3b4735b45_m.jpg"
}
],
"ga_prefix": "060615",
"type": 0,
"id": 4776328,
"css": [
"http://news.at.zhihu.com/css/news_qa.auto.css?v=1edab"
]
}这里只需要body(文章的主体内容)、title(文章标题)、id(文章编号)、share_url(分享链接)以及这篇文章的日期。提取出这些数据之后生成一个Article对象,然后将其存储到MongoDB中,如下例所示:

下载保存图片数据
每篇文章的内容是html标记的,一篇文章中可能包含图像标签,需要将其对应的图片一并下载保存。
原本打算使用正则表达式来匹配得到图像标签,但是确定正则表达式比较繁琐,考虑不周可能会事倍功半。于是去查找有没有别的解决方法。经过一番搜索之后发现了PyQuery这个库,它是JQuery的Python实现,移植了JQuery大部分的功能。之前使用过JQuery,感觉挺方便的,于是决定使用PyQuery来处理。
首先用PyQuery解析内容字符串,然后提取出img标签的src属性即可。使用PyQuery来完成这一任务十分地简单,部分代码如下:
import HTMLParser
from pyquery import PyQuery as pquery
html_parser = HTMLParser.HTMLParser()
artiContent = html_parser.unescape(artiRecord['body'])
domTree = pquery(artiContent)
imgElems = domTree.find('img')
imgUrls = []
for imgE in imgElems:
imgUrls.append(pquery(imgE).attr('src'))在得到图像请求url的list之后,遍历list,根据url请求将图片内容保存到本地。图片在本地的保存路径的格式为 基路径/year/month/day/imgname,其中基路径可以是任意一个本地路径,year、month、day是该图片所在日报文章的日期,imgname由guid加后缀名组成(后缀名可以从响应头信息中获取)。
由于要实现在本地查看日报内容,所以需要记录原本图像url到本地保存路径的映射关系,以便在本地生成网页时替换掉img标签中的src属性值。定义一个类来表示该映射信息,如下所示:
class ImageUrlMap(object):
def __init__(self, oriurl, date, newsid, filename):
"""
构造方法
oriurl: 请求图像的url
date: 所在文章对应的日期(这里的date为请求参数的字符串对应的日期,
并不是文章的日期,文章的日期为请求日期减一天)
newsid: 所在文章的编号
filename: 本地保存的文件名
"""
self.oriUrl = oriurl
self.date = datetime(date.year, date.month, date.day)
self.newsId = newsid
self.localName = filename
return遍历图像url的list时,生成ImageUrlMap对象,存储到MongoDB中,

注:截至2015-06-27的日报内容中,对应有85000+张图像(貌似相当一部分是头像),其中有47张图片无法下载。
首先确定MongoDB中名为dateids的collection中所有document中 date 字段的最大值,该最大值的下一天即为待处理的开始日期,如果该collection中没有document,则开始日期为20130520;待处理的结束日期为今天的日期。
DController.storeNewsId(dateIdCollOper, idStartDate, datetime.today().date())日报文章内容(html和图片,分开处理)都是以日期为下载调度单位的。DateNewsIdDict类中的hasDownload和imgDownload是用来帮助定位待处理的日期。html内容的下载控制和图片的下载控制类似,下面是图片下载控制的部分代码:
[imgcnt2Download, imgStartItem] = DController.getStartDate4Download(
dateIdCollOper, 'imgDownload')
print "{0} days' images need to be downloaded...".format(imgcnt2Download)
if imgcnt2Download > 0:
startDate4Download = imgStartItem['date'].date()
print "start downloading images... startdate: {0}\n".format(str(startDate4Download))
DController.storeImages(imgCollOper, dateIdCollOper,
artiCollOper, startDate4Download,
imgcnt2Download, baseImgPath)改进的方向
- 数据库写入时没有注意检查重复性
虽然在实现过程中稍微手动检查处理了一下,保证了并没有重复。感觉没什么问题,细枝末节就暂不处理了。。。
- 图片下载之后检查是否成功
有时候由于网络原因,可能导致请求图片之后返回数据有问题,导致保存的图片数据不正确。可以在下载保存完成之后判断该本地文件是否为图像格式,若不是则需重复请求。
- 多机(多IP)并行处理
这个对下载处理速度有较大的提升,然而只有一台机子和一个VPS。。。不过知乎日报的数据比较小,大概估算了一下,截至2015-06-27的数据不到一天就下完了(中大校园网在宿舍大概也就3M带宽的水平)。数据量太小,好像也没必要。
- 单机并行处理
将要处理的日期范围分成几部分,使用multiprocessing来处理。由于下载处理的瓶颈主要在于网速,目测没什么用。。。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK