

Kaldi中的ivector-原理和实现
source link: http://placebokkk.github.io/kaldi/2020/05/08/asr-kaldi-ivector.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
- 学习GMM-UBM/FA/Ivector的基本原理。
- 学习Kaldi的实现和Ivector论文中公式的对应关系。
GMM-UBM模型( GMM Universal Background Model)
用GMM来建模语音特征,即假设每一帧语音独立同分布于一个GMM分布。
i是第i个utterance(一个utterance对应一个不同speaker),t表示是第t时刻的帧,c是GMM的成分索引。则 p(oit)=∑Cc=1λcN(oit|μc,Σc),t=1,…,Tip(oit)=∑c=1CλcN(oit|μc,Σc),t=1,…,Ti
- UBM(Universal Backgound GMM) - 所有训练数据用最大似然估计(EM)训练出的GMM, 得到UBM参数 λ(b)cλc(b),μ(b)cμc(b) Σ(b)cΣc(b)
- Target GMM - 特定目标(比如某个说话人)的语音的训练出的GMM。每个uttrance估计出自己的GMM参数,第i个uttrance的GMM参数是 λicλic,μicμic ΣicΣic 若直接Target数据做EM估计GMM,一方面数据少,训练不充分,另一方面其混合成分和UBM的混合成分的对应关系未知。 所以一般使用target训练数据在UBM上做adaptation训练,从而高斯混合成分和UBM是对应的。
基于GMM-UBM说话人验证任务过程
- 训练全局GMM
- 说话人说几句话注册(Enroll), 从而得到该说话人的语音。
- 用该说话人的语音学习Target-GMM
- 说话人验证(Verification), 对于一段语音,如果该语音在Target-GMM上的似然 减去 其在UBM-GMM上的似然 大于阈值,则认为是该Target的声音。
Supervector的概念
除了计算似然,还可以从另一个角度去使用GMM-UBM框架做说话人识别。
将GMM的每个高斯成分的均值拼接成一个长向量(supervector)。这个向量表征了说话人的信息。对于一个语音,在UBM-GMM上用MAP去更新参数(每个高斯成分均值,高斯成分的权重),将得到的新的高斯成分均值拼起来,作为这个语音的说话人信息向量。 用该向量和Target-GMM的均值组成的超向量去计算相似度(比如cosine距离),如果相似度大于阈值,则认为是该Target发出的声音。
FA(因子分析)模型
x=m+z∗V+ϵx=m+z∗V+ϵ 什么是因子分析模型?
考虑一个问题:全世界人任何两个人长得都不一样。但是我们描述一个人的长相时并不是从像素点去描述,而是会说他是亚洲脸,这个人的嘴巴很小。 这里亚洲脸,嘴巴大小这些就叫因子。
脸 = 平均人脸 + 本质特征 * 特征展现矩阵(本质的特征 -> 脸上的展现) + 随机扰动
- x:每个人的脸的像素点。
- m:平均的脸的像素点。
- z:本质特征,但是你本质特征不是脸上的像素点,是一个更抽象的描述,可能是一个维度更低的量,比如 [肤色,性别,年龄,名族]甚至 [嘴型,脸型,鼻型,眼型,眉形,胡须型,肤质,耳形…]。
- V:本质特征(特征空间)反映到脸上(观察空间)的一个变换。
- epsilon: 一些随机变化。比如双胞胎,因为他们[肤色,年龄,民族]肯定一样,而他们的[嘴型,脸型,鼻型,眼型,眉形,胡须型,肤质,耳形。。。]因为遗传也非常相似, 但是epson还是会引入一些随机变化,所以两者的脸在像素级别看肯定还是有不同的,但是这种微小的差别可能妈妈都分不出来。
我们看看脸怎么来的,概率图模型或者生成模型。
- 有一个很不错平均脸。
- 上帝、父母和你自己一起选择了一些特征。
- 这些特征会根据共同的规则V作用在平均脸上。比如”肤色=白”这个描述,会让你脸上所有的像素点的颜色变浅。
- 再加点随机扰动
两个,根据这个模型,如果我们知道了V,则对于一个x可以得到其更本质的表示,这个表示。 当然,这个V可以是人类的先验知识,也可以是通过
- 参数估计(训练):给定很多x,学习V
- 推断:给定一个x,已知V,得到x对应的z。
训练 x=m+z∗V+ϵx=m+z∗V+ϵ 其中
- z服从高斯分布 N(z∥0,I)N(z‖0,I)
- ϵϵ 服从高斯分布 N(ϵ∥0,Σ)N(ϵ‖0,Σ)
FA 参数估计
通过EM算法去求最大化似然logp(X)logp(X),即不停迭代最大化
Ep(Z|X)[p(X,Z)]Ep(Z|X)[p(X,Z)]
这里直接给出结果,关于FA的推导,可以参考PRML第10章和FA-Ivector的FA部分。理解这个推导需要用到的基础知识
- EM算法 - 通过迭代最大化联合分布在隐变量条件分布下的期望,a求含有隐变量的模型的最大似然解。
- 理解高斯分布的配方 - 高斯分布的乘法和积分运算仍是高斯,计算后的均值和方差可以通过配方法找出。
- 矩阵向量的基本运算 - 某些形式的求导公式。
E-步,计算隐变量的统计量
⟨zi|xi⟩=L−1V⊤Σ−1(xi−m)⟨zi|xi⟩=L−1V⊤Σ−1(xi−m)
⟨ziz⊤i|xi⟩=L−1+⟨zi|xi⟩⟨zi|xi⟩⊤⟨zizi⊤|xi⟩=L−1+⟨zi|xi⟩⟨zi|xi⟩⊤
L=I+V⊤Σ−1VL=I+V⊤Σ−1V
M-步,更新参数。
V′=[∑i(xi−m′)⟨zi|xi⟩⊤][∑i⟨ziz⊤i|xi⟩]−1V′=[∑i(xi−m′)⟨zi|xi⟩⊤][∑i⟨zizi⊤|xi⟩]−1
m′=1N∑ixim′=1N∑ixi
Σ′=1N{N∑i=1[(xi−m′)(xi−m′)⊤−V′⟨zi|xi⟩(xi−m′)⊤]}Σ′=1N{∑i=1N[(xi−m′)(xi−m′)⊤−V′⟨zi|xi⟩(xi−m′)⊤]}
已知模型参数,给定一个x,求其对应的z的期望值,Ep(z|x)[z]Ep(z|x)[z].也就是参数估计里E步中的
⟨zi|xi⟩=L−1V⊤Σ−1(xi−m)⟨zi|xi⟩=L−1V⊤Σ−1(xi−m)
Ivector模型
在GMM-UBM模型部分介绍了supervector,第i个uttrance的supervector μiμi是对第i句话的一种表示,这种表示可以把不同长度的uttrance用等长度的向量表示出来,从而大家在同一个向量空间中,可以进行相似度计算。更进一步,μiμi 本身也可以用FA模型来建模,从而得到更本质的表示。
μi=m+Twiμi=m+Twi
supervector是各个GMM的成分均值拼起来的,如果按各成分拆开则有:(注意这里是wiwi 而不是wicwic,这里是对拼接的supervector做因子分析,并不是各个成分的μicμic有自己的因子模型)
μic=mc+Tcwi,c=1,…,Cμic=mc+Tcwi,c=1,…,C
其中T=[Tt1,...,TtC]tT=[T1t,...,TCt]t;m=[mt1,...,mtC]tm=[m1t,...,mCt]t;μi=[μti1,...,μtiC]tμi=[μi1t,...,μiCt]t
每个uttrance都有自己的GMM,比如第i个uttrance的各个时刻t的特征服从如下GMM模型:
p(oit)=C∑c=1λicN(oit|μic,Σic),t=1,…,Tip(oit)=∑c=1CλicN(oit|μic,Σic),t=1,…,Ti
用UBM中计算得到的的λ(b)cλc(b),μ(b)cμc(b) Σ(b)cΣc(b)代替λicλic,mcmc,ΣicΣic,得到
p(oit)=C∑c=1λ(b)cN(oit|μic,Σ(b)c),t=1,…,Tip(oit)=∑c=1Cλc(b)N(oit|μic,Σc(b)),t=1,…,Ti
μic=μ(b)c+Tcwi,c=1,…,Cμic=μc(b)+Tcwi,c=1,…,C
- λ(b)cλc(b),μ(b)cμc(b) Σ(b)cΣc(b) 是已知的参数。
- TcTc是未知的参数。
- μicμic,wiwi是隐随机变量
- oitoit 是已知的随机变量
如上的模型就是Ivector模型,其本质是:
对GMM成分均值拼接成的超向量随机变量用FA建模,并直接使用UBM的参数作为高斯混合权重,成分方差和FA的均值参数值。
我把它简称为UBM-constrainted-FA-GMM模型。
GMM-UBM/FA/Ivector各自的概率图模型表示如下:
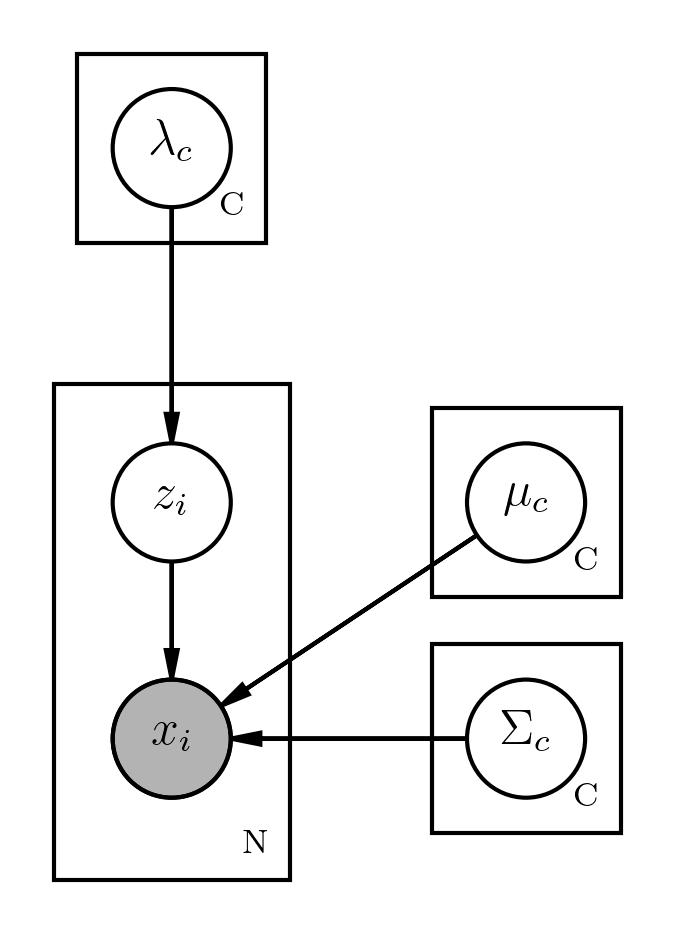 GMM
GMM
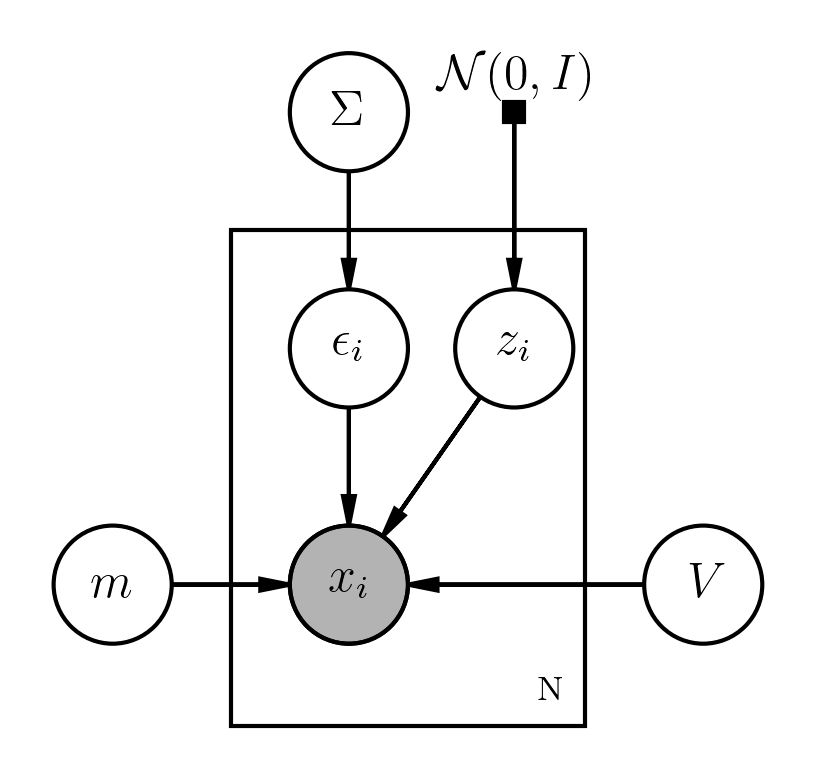 FA
FA
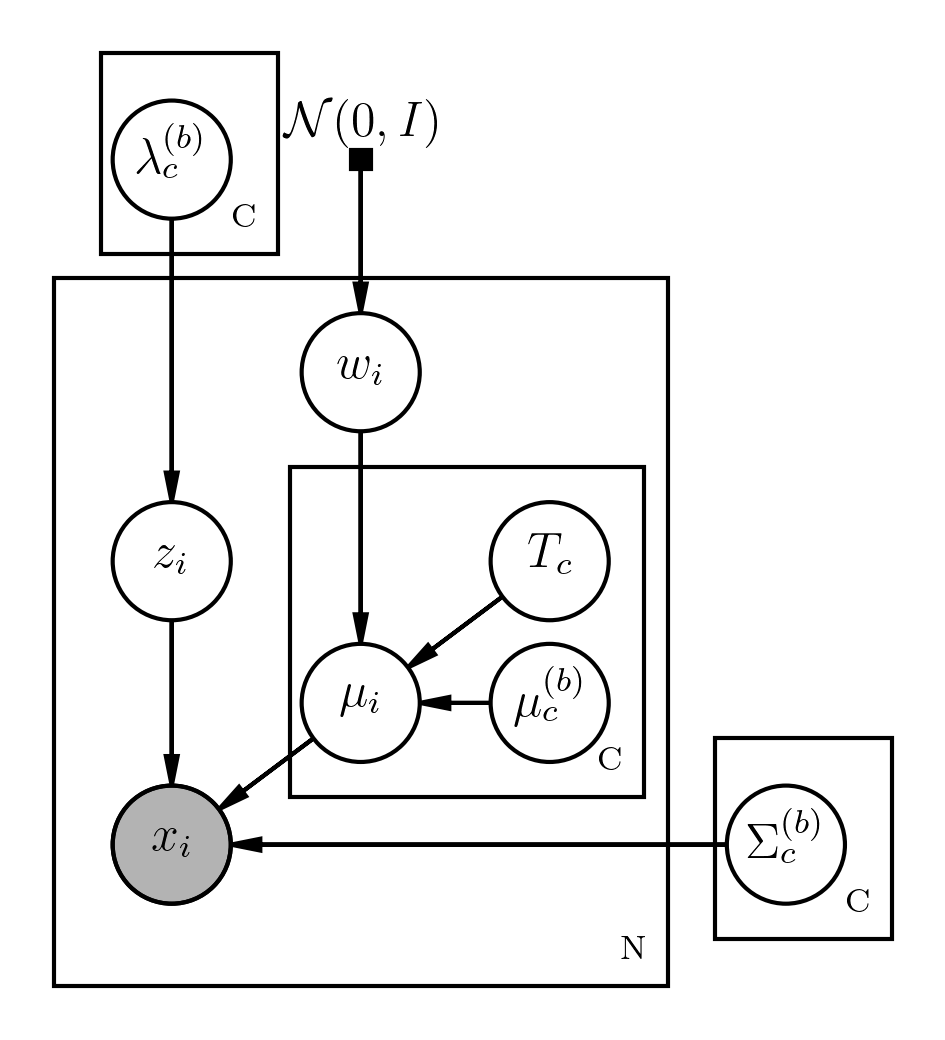 Ivector
Ivector
两篇文献和Kaldi实现的符号对比说明
- FA-ivector的下标i表示第i个uttrance样本
- Simple-Ivector省略下标i
- kaldi里的下标i对应公式中的c
说明 FA-ivector Simple-Ivector Kaldi GMM成分索引 c c i 高斯成分的权重 λλ ωω - ubm得到第c个成分的均值 γc(oit)γc(oit) γt,cγt,c weight(i) 对齐到第c个成分的统计量 NicNic ηcηc gamma(i) ubm得到的均值 μ(b)cμc(b) μcμc Means_(i) ivector隐变量的条件期望 <wi|Oi><wi|Oi> ww ivec_mean ivector隐变量平方的条件期望 <wiwi|Oi><wiwi|Oi> ww ivec_mean f <wi|Oi><wi|Oi> ww R 第c个成分的变换矩阵 TcTc T(c)T(c) M(i) 计算T的第一项 C Y 计算T的第二项 A R T(c)′Σ−1T(c)T(c)′Σ−1T(c) U(i)
- 公式(4)需要除上分母p(x)
- 公式(10)不带求逆
from SJTU 王帅 phd: Ivector如何去除文本相关信息,只保留ivector 本质上是对帧级别的统计量求了平均,ivector 本质上是对帧级别的统计量求了平均。
Kaldi的实现
high-level脚本
# computing a PCA transform from the fbank data."
steps/online/nnet2/get_pca_transform.sh
# training the diagonal UBM."
steps/online/nnet2/train_diag_ubm.sh
# training the iVector extractor"
steps/online/nnet2/train_ivector_extractor.sh
其中计算PCA和计算UBM放在全文最后,这里直接介绍第三步,计算Ivecotr。
Kaldi的计算Ivector脚本
计算GMM-UBM后验用的feat和更新ivector统计量用的feat不一样。
gmm_feats="ark,s,cs:apply-cmvn-online --config=$dir/online_cmvn.conf --spk2utt=ark:$sdata/JOB/spk2utt $dir/global_cmvn.stats scp:$sdata/JOB/feats.scp ark:- | splice-feats $splice_opts ark:- ark:- | transform-feats $dir/final.mat ark:- ark:- | subsample-feats --n=$subsample ark:- ark:- |"
feats="ark,s,cs:splice-feats $splice_opts scp:$sdata/JOB/feats.scp ark:- | transform-feats $dir/final.mat ark:- ark:- | subsample-feats --n=$subsample ark:- ark:- |"
模型训练流程
ivector-extractor-init --ivector-dim=$ivector_dim --use-weights=false \
"gmm-global-to-fgmm $dir/final.dubm -|" $dir/0.ie
gmm-global-get-post --n=$num_gselect --min-post=$min_post $dir/final.dubm "$gmm_feats" ark:- \| \
scale-post ark:- $modified_posterior_scale "ark:|gzip -c >$dir/post.JOB.gz" || exit 1;
Args=() # bash array of training commands for 1:nj, that put accs to stdout.
for j in $(seq $nj_full); do
Args[$j]=`echo "ivector-extractor-acc-stats --num-threads=$num_threads $dir/$x.ie '$feats' 'ark,s,cs:gunzip -c $dir/post.JOB.gz|' -|" | sed s/JOB/$j/g`
done
for g in $(seq $nj); do
start=$[$num_processes*($g-1)+1]
ivector-extractor-sum-accs --parallel=true "${Args[@]:$start:$num_processes}" $dir/acc.$x.$g
done
for j in $(seq $nj); do
accs+="$dir/acc.$x.$j "
done
ivector-extractor-sum-accs $accs $dir/acc.$x
ivector-extractor-est --num-threads=$nt $dir/$x.ie $dir/acc.$x $dir/$[$x+1].ie
Kaldi中Ivector的C++实现
Kaldi在实现Ivector时,基于SGMM框架,和Ivecotr标准公式有些不制止,idiap在kaldi的基础上做了一些调整,实现了一个和公式完全一致的版本。
代码: https://github.com/idiap/kaldi-ivector
ivector-extractor-acc-stats
{
utt_stats.AccStats(feats, post); //利用r计算0阶/1阶。
CommitStatsForUtterance(extractor, utt_stats);//计算C/A,mean,Var
}
更新???
void IvectorExtractorConv::GetStats(
const MatrixBase<BaseFloat> &feats,
const MatrixBase<BaseFloat> &post,
IvectorExtractorConvUtteranceStats *stats) const {
typedef std::vector<std::pair<int32, BaseFloat> > VecType;
int32 num_frames = feats.NumRows(), num_gauss = NumGauss(),
feat_dim = FeatDim();
KALDI_ASSERT(feats.NumCols() == feat_dim);
KALDI_ASSERT(stats->gamma.Dim() == num_gauss &&
stats->X.NumCols() == feat_dim);
bool update_variance = (!stats->S.empty());
for (int32 t = 0; t < num_frames; t++) {
SubVector<BaseFloat> frame(feats, t);
SpMatrix<double> outer_prod;
if (update_variance) {
outer_prod.Resize(feat_dim);
outer_prod.AddVec2(1.0, frame);
}
for (int32 i = 0; i < num_gauss; i++) {
double weight = post(t,i);
stats->gamma(i) += weight;
stats->X.Row(i).AddVec(weight, frame);
if (update_variance)
stats->S[i].AddSp(weight, outer_prod);
}
}
for (int32 i = 0; i < num_gauss; i++) {
stats->X.Row(i).AddVec(-stats->gamma(i), Means_.Row(i));
}
}
CommitStatsForUtterance
{
extractor.GetIvectorDistribution(utt_stats,
&ivec_mean,
&ivec_var);//mean,var
CommitStatsForM(extractor, utt_stats, ivec_mean, ivec_var);//计算C/A,
}
GetIvectorDistribution
{
GetIvectorDistMean(utt_stats, &linear, &quadratic);
GetIvectorDistPrior(utt_stats, &linear, &quadratic);
if (var != NULL) {
var->CopyFromSp(quadratic);
var->Invert(); // now it's a variance.
// mean of distribution = quadratic^{-1} * linear...
mean->AddSpVec(1.0, *var, linear, 0.0);
} else {
quadratic.Invert();
mean->AddSpVec(1.0, quadratic, linear, 0.0);
}
}
void IvectorExtractor::GetIvectorDistMean(
const IvectorExtractorUtteranceStats &utt_stats,
VectorBase<double> *linear,
SpMatrix<double> *quadratic) const {
int32 I = NumGauss();
for (int32 i = 0; i < I; i++) {
double gamma = utt_stats.gamma_(i);
if (gamma != 0.0) {
SubVector<double> x(utt_stats.X_, i); // == \gamma(i) \m_i
// next line: a += \gamma_i \M_i^T \Sigma_i^{-1} \m_i
linear->AddMatVec(1.0, Sigma_inv_M_[i], kTrans, x, 1.0);
}
}
SubVector<double> q_vec(quadratic->Data(), IvectorDim()*(IvectorDim()+1)/2);
q_vec.AddMatVec(1.0, U_, kTrans, utt_stats.gamma_, 1.0);
}
ivector-extractor-sum-accs ivector-extractor-est 根据0阶/1阶统计量,和ubm参数,T等,进行EM。
double IvectorExtractorStats::Update(
const IvectorExtractorEstimationOptions &opts,
IvectorExtractor *extractor) const {
CheckDims(*extractor);
if (tot_auxf_ != 0.0) {
KALDI_LOG << "Overall auxf/frame on training data was "
<< (tot_auxf_/gamma_.Sum()) << " per frame over "
<< gamma_.Sum() << " frames.";
}
double ans = 0.0;
ans += UpdateProjections(opts, extractor);
if (extractor->IvectorDependentWeights())
ans += UpdateWeights(opts, extractor);
if (!S_.empty())
ans += UpdateVariances(opts, extractor);
ans += UpdatePrior(opts, extractor); // This will also transform the ivector
// space. Note: this must be done as the
// last stage, because it will make the
// stats invalid for that model.
KALDI_LOG << "Overall objective-function improvement per frame was " << ans;
extractor->ComputeDerivedVars();
return ans;
}
// Note, throughout this file we use SGMM-type notation because
// that's what I'm comfortable with.
// Dimensions:
// D is the feature dim (e.g. D = 60)
// I is the number of Gaussians (e.g. I = 2048)
// S is the ivector dim (e.g. S = 400)
/// R_i, quadratic term for ivector subspace (M matrix)estimation. This is a
/// kind of scatter of ivectors of training speakers, weighted by count for
/// each Gaussian. Conceptually vector<SpMatrix<double> >, but we store each
/// SpMatrix as a row of R_. Conceptually, the dim is [I][S][S]; the actual
/// dim is [I][S*(S+1)/2].
Matrix<double> R_;
/// Weight projection vectors, if used. Dimension is [I][S]
Matrix<double> w_;
/// If we are not using weight-projection vectors, stores the Gaussian mixture
/// weights from the UBM. This does not affect the iVector; it is only useful
/// as a way of making sure the log-probs are comparable between systems with
/// and without weight projection matrices.
Vector<double> w_vec_;
/// Ivector-subspace projection matrices, dimension is [I][D][S].
/// The I'th matrix projects from ivector-space to Gaussian mean.
/// There is no mean offset to add-- we deal with it by having
/// a prior with a nonzero mean.
std::vector<Matrix<double> > M_;
void IvectorExtractorConv::GetIvectorDistribution(
const IvectorExtractorConvUtteranceStats &utt_stats,
VectorBase<double> *mean,
SpMatrix<double> *var) const {
Vector<double> linear(IvectorDim());
SpMatrix<double> quadratic(IvectorDim());
GetIvectorDistMean(utt_stats, &linear, &quadratic);
if (var != NULL) {
var->CopyFromSp(quadratic);
var->Invert(); // now it's a variance.
// mean of distribution = quadratic^{-1} * linear...
mean->AddSpVec(1.0, *var, linear, 0.0);
} else {
quadratic.Invert();
mean->AddSpVec(1.0, quadratic, linear, 0.0);
}
}
更新Y和R,即更新C和A
void IvectorConvStats::CommitStatsForM(
const IvectorExtractorConv &extractor,
const IvectorExtractorConvUtteranceStats &utt_stats,
const VectorBase<double> &ivec_mean,
const SpMatrix<double> &ivec_var) {
subspace_stats_lock_.lock();
// We do the occupation stats here also.
gamma_.AddVec(1.0, utt_stats.gamma);
// Stats for the linear term in M:
for (int32 i = 0; i < extractor.NumGauss(); i++) {
Y_[i].AddVecVec(1.0, utt_stats.X.Row(i),
Vector<double>(ivec_mean));
}
int32 ivector_dim = extractor.IvectorDim();
// Stats for the quadratic term in M:
SpMatrix<double> ivec_scatter(ivec_var);
ivec_scatter.AddVec2(1.0, ivec_mean);
SubVector<double> ivec_scatter_vec(ivec_scatter.Data(),
ivector_dim * (ivector_dim + 1) / 2);
R_.AddVecVec(1.0, utt_stats.gamma, ivec_scatter_vec);
subspace_stats_lock_.unlock();
}
ivec_mean -> w
M->T
Y->C
R->A
U->T^T Sigma T
/// U_i = M_i^T \Sigma_i^{-1} M_i
X_ -> f
i -> c
其中的i对应GMM成分c索引.
double impr = SolveQuadraticMatrixProblem(R, Y_[i], SigmaInv, solver_opts, &M),
计算T=CcA−1cT=CcAc−1, 代码表示是M=YiR−1iM=YiRi−1,
double IvectorConvStats::UpdateProjection(
const IvectorExtractorConvEstimationOptions &opts,
int32 i,
IvectorExtractorConv *extractor) const {
int32 I = extractor->NumGauss(), S = extractor->IvectorDim();
KALDI_ASSERT(i >= 0 && i < I);
/*
For Gaussian index i, maximize the auxiliary function
Q_i(x) = tr(M_i^T Sigma_i^{-1} Y_i) - 0.5 tr(Sigma_i^{-1} M_i R_i M_i^T)
*/
if (gamma_(i) < opts.gaussian_min_count) {
KALDI_WARN << "Skipping Gaussian index " << i << " because count "
<< gamma_(i) << " is below min-count.";
return 0.0;
}
SpMatrix<double> R(S, kUndefined), SigmaInv(extractor->Sigma_inv_[i]);
SubVector<double> R_vec(R_, i); // i'th row of R; vectorized form of SpMatrix.
SubVector<double> R_sp(R.Data(), S * (S+1) / 2);
R_sp.CopyFromVec(R_vec); // copy to SpMatrix's memory.
Matrix<double> M(extractor->M_[i]);
SolverOptions solver_opts;
solver_opts.name = "M";
solver_opts.diagonal_precondition = true;
// TODO: check if inversion is sufficient?
double impr = SolveQuadraticMatrixProblem(R, Y_[i], SigmaInv, solver_opts, &M),
gamma = gamma_(i);
if (i < 4) {
KALDI_VLOG(1) << "Objf impr for M for Gaussian index " << i << " is "
<< (impr / gamma) << " per frame over " << gamma << " frames.";
}
extractor->M_[i].CopyFromMat(M);
return impr;
}
https://danielpovey.com/files/csl10_sgmm_preprint.pdf A.2
- 计算后验γγ, kaldi代码中的weight
- 更新ηη, kaldi代码中的gamma
- 计算ff,代码中的X
for (int32 t = 0; t < num_frames; t++) { for (int32 i = 0; i < num_gauss; i++) { double weight = post(t,i); // (4) stats->gamma(i) += weight; // stats->X.Row(i).AddVec(weight, frame); if (update_variance) stats->S[i].AddSp(weight, outer_prod); } } for (int32 i = 0; i < num_gauss; i++) { stats->X.Row(i).AddVec(-stats->gamma(i), Means_.Row(i)); }
相关文件 $dir/post.JOB.gz $dir/acc.$x $dir/$[$x+1].ie
ωω 和ww区别
Kaldi中计算GMM成分后验
p(Mixture=c|x) 后验计算公式。 λ(b)cN(x|μ(b)c,Σ(b)c)∑Cj=1λ(b)jN(x|μ(b)j,Σ(b)j)λc(b)N(x|μc(b),Σc(b))∑j=1Cλj(b)N(x|μj(b),Σj(b))
Kaldi里的求后验实现(src/gmmbin/gmm-global-get-post.cc)
- 求每个成分的log-likehood实现里,代码 DiagGmm::LogLikelihoods()(src/gmm/diag-gmm.cc)
- 求softmax. GMM的成分可能很多(比如2048个),Kaldi里只选择似然最高的N个成分(num_post默认值50)做softmax。 代码 VectorToPosteriorEntry() (src/hmm/posterior.h)
计算每个成分的log-likehood时:
ln(λcN(x|μc,Σc))=12xTΣ−1x+μΣ−1x+constln(λcN(x|μc,Σc))=12xTΣ−1x+μΣ−1x+const
其中的const部分和x无关,可以提前计算好。kaldi中的变量叫gconsts_。
Kaldi训练PCA的脚本
local/chain/train_ivector.sh: computing a PCA transform from the fbank data.
feat-to-dim scp:exp/chain/diag_ubm_fbank/train_subset/feats.scp -
steps/online/nnet2/get_pca_transform.sh --cmd queue.pl --splice-opts --left-context=3 --right-context=3 --max-utts 10000 --subsample 2 --dim 23 exp/chain/diag_ubm_fbank/train_subset exp/chain/pca_transform_fbank
Done estimating PCA transform in exp/chain/pca_transform_fbank
// bin/est-pca.cc
est-pca --dim=$dim --normalize-variance=$normalize_variance \
--normalize-mean=$normalize_mean "$feats" $dir/final.mat || exit 1;
final.mat是得到的pca
查看pca matrix的dim的方法
kaldi/src/bin/matrix-dim exp/chain/pca_transform_fbank/final.mat
- 7帧特征拼接加上normalize_mean维一共 7 *23 +1 = 162 维。
- pca矩阵 162 -> 23
if (normalize_mean) { offset.AddMatVec(-1.0, transform, kNoTrans, sum, 0.0); transform.Resize(full_dim, full_dim + 1, kCopyData); // Add column to transform. transform.CopyColFromVec(offset, full_dim); }
查看matrix内容
/export/maryland/chaoyang/kaldi/src/bin/copy-matrix --binary=false exp/chain/pca_transform_fbank/final.mat -
Kaldi训练GMM-UBM的脚本
steps/online/nnet2/train_diag_ubm.sh --cmd queue.pl --nj 15 --num-frames 700000 --num-threads 8 exp/chain/diag_ubm_fbank/train_subset 512 exp/chain/pca_transform_fbank exp/chain/diag_ubm_fbank
- –num-frames 700000, 最多使用700000帧数据训练
- 512个成分的GMM
其训练过程就是正常的GMM模型的EM估计
gmm-global-init-from-feats --num-threads=$num_threads --num-frames=$num_frames --min-gaussian-weight=$min_gaussian_weight \
--num-gauss=$num_gauss --num-gauss-init=$num_gauss_init --num-iters=$num_iters_init \
"$all_feats" $dir/0.dubm
gmm-gselect --n=$num_gselect $dir/0.dubm "$feats" "ark:|gzip -c >$dir/gselect.JOB.gz";
for x in `seq 0 $[$num_iters-1]`; do
gmm-global-acc-stats "--gselect=ark,s,cs:gunzip -c $dir/gselect.JOB.gz|" $dir/$x.dubm "$feats" $dir/$x.JOB.acc
gmm-global-est $opt --min-gaussian-weight=$min_gaussian_weight $dir/$x.dubm "gmm-global-sum-accs - $dir/$x.*.acc|" $dir/$[$x+1].dubm
done
mv $dir/$num_iters.dubm $dir/final.dubm;
kaldi/gmmbin中,gmm-global-*的相关代码是ubm相关的, dubm是对角ubm的意思
比如查看gmm-ubm模型信息 /export/maryland/chaoyang/kaldi/src/gmmbin/gmm-global-info exp/chain/diag_ubm_fbank/final.dubm number of gaussians 512 feature dimension 23
比如复制gmm-ubm模型(可以用转换为文本) /export/maryland/chaoyang/kaldi/src/gmmbin/gmm-global-copy –binary=false exp/chain/diag_ubm_fbank/final.dubm -
转换为文本格式后可以查看模型的具体内容,512个成分,每个是23维的对角高斯。
<DiagGMM>
<GCONSTS>[512]
<WEIGHTS>[512]
<MEANS_INVVARS> [512 * 23]
<INV_VARS>[512 * 23]
</DiagGMM>
C++实现
/// Equals log(weight) - 0.5 * (log det(var) + mean*mean*inv(var))
Vector<BaseFloat> gconsts_;
bool valid_gconsts_; ///< Recompute gconsts_ if false
Vector<BaseFloat> weights_; ///< weights (not log).
Matrix<BaseFloat> inv_vars_; ///< Inverted (diagonal) variances
Matrix<BaseFloat> means_invvars_; ///< Means times inverted variance
计算单个高斯成分(component)的似然
BaseFloat DiagGmm::ComponentLogLikelihood(const VectorBase<BaseFloat> &data,
int32 comp_id) const {
BaseFloat loglike;
Vector<BaseFloat> data_sq(data);
data_sq.ApplyPow(2.0);
// loglike = means * inv(vars) * data.
loglike = VecVec(means_invvars_.Row(comp_id), data);
// loglike += -0.5 * inv(vars) * data_sq.
loglike -= 0.5 * VecVec(inv_vars_.Row(comp_id), data_sq);
return loglike + gconsts_(comp_id);
}
- SIMPLIFICATION AND OPTIMIZATION OF I-VECTOR EXTRACTION
- Lecture Notes on Factor Analysis and I-Vectors
- The subspace Gaussian mixture model – a structured model for speech recognition
- Implementation of the Standard I-vector System for the Kaldi Speech Recognition Toolkit
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK