

Cornernet and centernet on detection
source link: http://kakack.github.io/2022/01/Cornernet-and-Centernet-on-Detection/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Why Anchor Free?
随着anchor在检测算法中的应用,不管是one or two stage的检测模型,都会在图片上放置密密麻麻尺寸不一的anchors,用来检测全图各个角落大小不一的目标物体。但是anchor based model有两个不足之处:
-
Anchor amount过大,导致计算复杂度过高,对于绝大部分情况,只有其中很小一部分anchor能成功匹配到ground truth,而大量anchor作为负样本被丢弃。
-
整体引入大量hyper-parameters,以及针对anchor得到的bounding box所做的NMS操作,都会影响模型性能。
CornerNet
CornerNet的文章取名为Detecting Objects as Paired Keypoints,言下之意就是用一对关键点来确定目标位置。我们主要从以下几点来描述:
- 如何用anchor-free的方法表示目标;
- 什么是corner pooling;
- CornerNet的网络结构和损失函数。
Locate the Object
在CornerNet中,我们预测的是目标bounding box的左上top-left和右下bottom-right两个角点作为识别关键点。网络在进行预测的时候,会为每个点分配一个embedding vector,属于同一物体的点的vector的距离较小。
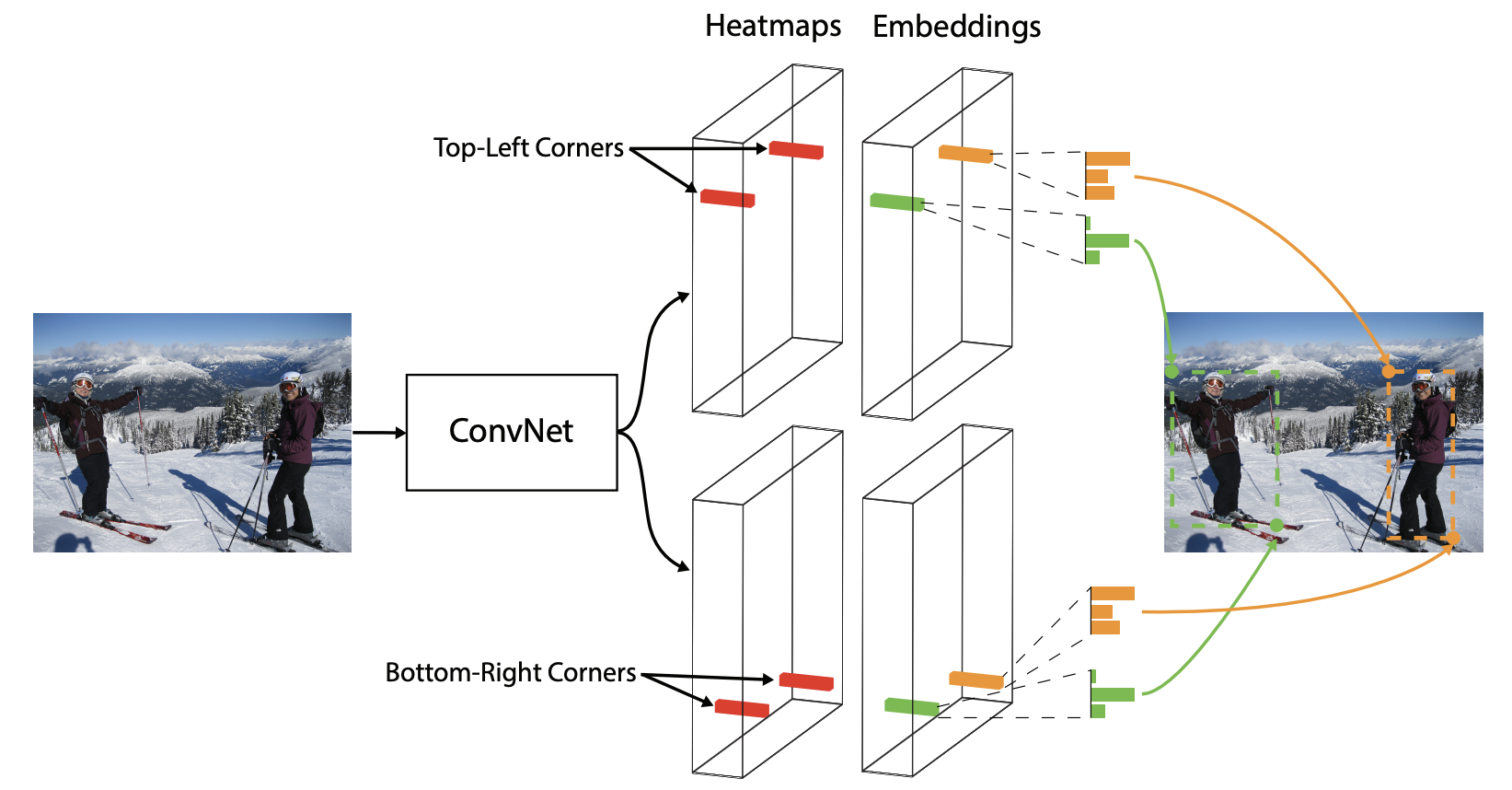
作者选择corner而不是center的原因在于,一个中心点需要四个边决定,而一个角点只需要两个边,同时通过corner表示box相当于一种降维。
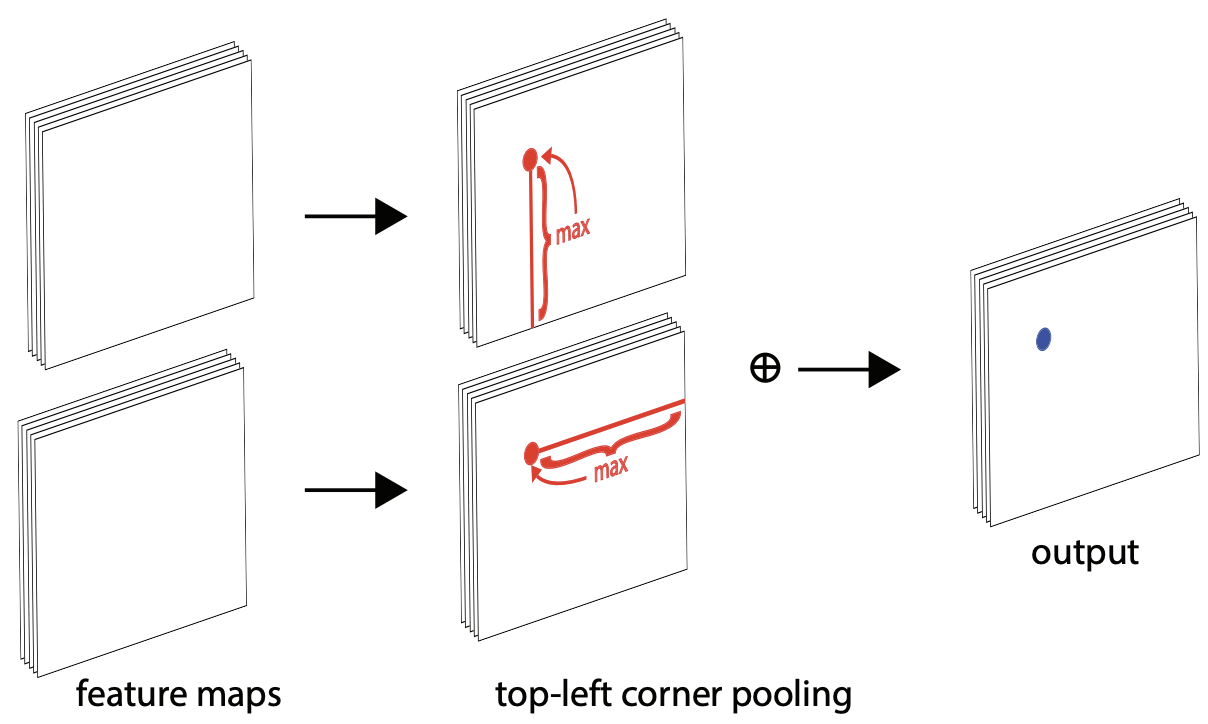
Corner Pooling
如何预测角点的heatmap,就引入了corner pooling的思想。我们先生成整张图的heatmap,对于top-left而言,它首先包含两张相同的特征图,在每个像素点位置,它将第一个特征图右边的所有特征向量和第二个特征图正下方的所有特征向量都做max pooling,然后将pooling得到的两个结果相加。(可以用逆向最大值作为单方向corner pooling的值直接使用)
CornerNet Detail
Network Architecture
CornerNet的网络结构主要分为以下几个部分
- Backbone: Hourglass Network;
- Head: 二分支输出 Top-left corners 和 Bottom-right corners,每个分支包含了各自的corner pooling以及三分支输出。
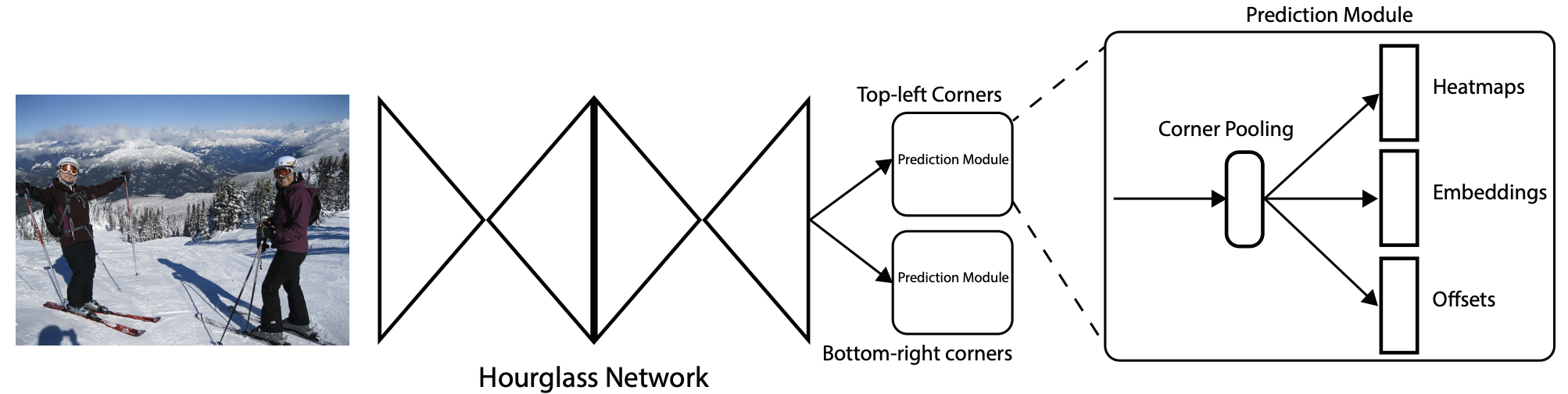
CornerNet借用了hourglass network作为他的backbone特征提取网络,这个hourglass network通常被用在姿态估计任务中,是一种呈沙漏状的downsampling 和 upsampling组合,为两个沙漏模块(hourglass module)头尾相连的效果。
在原有hourglass的基础上,作者做了以下的改进:
- 在输入hourglass module之前,需要将图片分辨率降低为原来的1/4倍。本文采用了一个stride=2的7x7卷积和一个stride=2的残差单元进行图片分辨率降低。
- 使用stride=2的卷积层代替max pooling进行downsample
- 共进行5次downsample ,这5次downsample后的特征图通道为[256,384,384,384,512]
- 采用最近邻插值的上采样(upsample),后面接两个残差单元
Loss Function
Focus Loss
首先是detection中角点与目标ground truth之间的loss。输出的角点的heatmap有C个channel,˜M∈RW/R×H/R×C,在这里C即数据集的种类(不设置background的类别)。每个channel都是0-1之间的数(可以看作一个概率),比如我们有pcij=1就表示(i,j)位置的角点是类别c的角点的概率为1。ycij表示该位置的ground truth,s是一个binary value,如果这个点正好是一个object的corner那他=1,否则=0,但是这里ycij是0-1之间的数,是用基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i‘,j‘)点的yci‘j‘值接近1。这样做是因为靠近ground truth的误检角点组成的预测框仍会和ground truth有较大的重叠面积,也能很好的框住原物体。
Ldet=−1NC∑c=1H∑i=1W∑j=1{(1−pcij)αlog(pcij)ifycij=1(1−ycij)β(pcij)αlog(1−pcij)Otherwise
计算对每个channel在heatmap上的每个位置的损失的和。如果这是一个正样本点(ycij=1),那么使用focal loss计算损失,更多的关注难样本。如果不是,那么在focal loss的基础上加上(1−ycij)β这一项,控制我们分配的标签对整体损失的影响。可以看到如果ycij很接近1,这一项损失是接近0的,也就是说我们鼓励将这里的pcij预测为1,这种soft的操作看起来就很舒服,注意使用object的数目N进行归一化。
Embedding Loss
论文中利用该损失函数来减小同一物体bounding box左上角和右下角embedding的距离,根据embedding的距离大小进行聚类,增大不同物体bounding box左上角和右下角embedding的距离,即˜E∈RW/R×H/R×1。
Lpull=1NN∑k=1[(etk−ek)2+(ebk−ek)2]
Lpush=1N(N−1)N∑k=1N∑i=1,j≠1max(0,△−|ebk−ej|)
这两个损失函数得目的是pull损失使得类内距离尽可能小,push损失使得类间距离尽可能大。etk,ebk,ek分别是对象k预测的的右上角,左下角和平均的embedding,显然这里也只是存在object的地方才会计算embedding损失。
Offsets Loss
对于heatmap被downsample至原来的1n后,还想继续upsample回去的话会造成精度的损失,这会严重影响到小物体框的位置精度,所以作者采用了offsets来缓解这种问题。对于输出值offset,˜O∈RW/R×H/R×2,我们使用卷积网络之后会将(x,y)位置的pixel映射到([x/n],[y/n]),而此时因为我们在特征图的每个pixel产生corner的预测,把他映射回去肯定会因为取整造成一定的误差(越小的box造成的误差越大),这个offset就是为了缓和这个取整误差:
ok=(xkn−⌊xkn⌋,ykn−⌊ykn⌋)
每个pixel都会预测一对偏移值,但是只有存在object的pixel才会计算偏移误差。
Loff=1NN∑k=1SmoothL1Loss(ok,^ok)
CenterNet
但是CornerNet仍存在group环节带来了较大计算量,因此在此基础上出现了CenterNet。
CenterNet直接预测bbx的中心点,其他特征如大小、3D位置、方向,甚至姿态可以使用中心点位置的图像特征进行回归。将目标检测当成了关键点估计得任务来做,使用FCN将图像变成heatmap,峰值处就是我们想要的关键点。CenterNet的输出分辨率的下采样因子是4,比起其他的目标检测框架算是比较小的,因为centernet没有采用FPN结构,因此所有中心点要在一个Feature map上出,因此分辨率不能太低。
总之,CenterNet结构十分简单,直接检测目标的中心点和大小,是真正意义上的anchor-free。
Network Architecture
论文中CenterNet提到了三种用于目标检测的网络,这三种网络都是编码解码(encoder-decoder)的结构:
- Resnet-18 with up-convolutional layers : 28.1% coco and 142 FPS
- DLA-34 : 37.4% COCOAP and 52 FPS
- Hourglass-104 : 45.1% COCOAP and 1.4 FPS
每个网络内部的结构不同,但是在模型的最后输出部分都是加了三个网络构造来输出预测值,默认是80个类、2个预测的中心点坐标、2个中心点的偏置。
在整个训练的流程中,CenterNet学习了CornerNet的方法。对于每个标签图(ground truth)中的某一类,我们要将真实关键点(true keypoint) 计算出来用于训练,中心点的计算方式:p=(x1+x22,y1+y22),对于下采样后的坐标设为:˜p=⌊pR⌋,,其中 R 是文中提到的下采样因子4。所以我们最终计算出来的中心点是对应低分辨率的中心点。
然后我们对图像进行标记,在下采样的[128,128]图像中将ground truth point以下采样的形式,用一个高斯滤波:
Yxyc=exp(−(x−˜px)2+(y−˜py)22σ2p)
来将关键点分布到特征图上。
Loss Function
Center Points Loss Function
Lk=−1N∑xyc{(1−ˆYxyc)αlog(ˆYxyc)ifYxyc=1(1−ˆYxyc)β(ˆYxyc)αlog(1−ˆYxyc)Otherwise
其中α和β是Focal Loss的超参数,在这篇论文中分别是2和4,N是图像的关键点数量,用于将所有的positive focal loss标准化为1。这个损失函数是Focal Loss的修改版,适用于CenterNet。
而在CenterNet中,每个中心点对应一个目标的位置,不需要进行overlap的判断。那么怎么去减少negative center pointer的比例呢?CenterNet是采用Focal Loss的思想,在实际训练中,中心点的周围其他点(negative center pointer)的损失则是经过衰减后的损失(上文提到的),而目标的长和宽是经过对应当前中心点的w和h回归得到的。
Offset Loss
因为上文中对图像进行了R=4的下采样,这样的特征图重新映射到原始图像上的时候会带来精度误差,因此对于每一个中心点,额外采用了一个local offset 去补偿它。所有类c的中心点共享同一个offset prediction,这个偏置值(offset)用L1 loss来训练:
Loff=1N∑p|ˆO˜p−(pR−˜p)|
这个偏置损失是可选的,我们不使用它也可以,只不过精度会下降一些。这部分跟CornerNet一致。
Size Loss
假设目标k坐标为(x(k)1,y(k)1,x(k)2,y(k)2),所属类别为c,那它的中心点坐标为pk=(x(k)1+x(k)22,y(k)1+y(k)22)。我们使用关键点预测ˆY去预测所有中心点,然后对每个目标k的size做回归,最终得到sk=(x(k)2−x(k)1,y(k)2−y(k)1),这个值是在训练前提前计算出来的,是进行了下采样之后的长宽值。
为了减少回归的难度,这里使用ˆS∈RW‘R×HR×2作为预测值,使用L1损失函数,与之前的Loff损失一样:
Lsize=1NN∑k=1|ˆSpk−sk|
Process
在预测阶段,首先针对一张图像进行下采样,随后对下采样后的图像进行预测,对于每个类在下采样的特征图中预测中心点,然后将输出图中的每个类的热点单独地提取出来。具体怎么提取呢?就是检测当前热点的值是否比周围的八个近邻点(八方位)都大(或者等于),然后取100个这样的点,采用的方式是一个3x3的MaxPool,类似于anchor-based检测中nms的效果。
这里假设ˆpc为检测到的点,
ˆp={(ˆxi,ˆyi)}ni=1
代表c类中检测到的一个点。每个关键点的位置用整型坐标表示(xi,yi),然后使用ˆYxiyic表示当前点的confidence,随后使用坐标来产生标定框:
(ˆxi+δˆxi−ˆwi2,ˆyi+δˆyi−ˆwi2,ˆxi+δˆxi−ˆwi2,ˆyi+δˆyi−ˆwi2)
其中(δˆxi,δˆyi)=ˆOˆxi,ˆyi,是当前点对应原始图像的偏置点,(ˆwi,ˆhi)=ˆSˆxi,ˆyi代表预测出来当前点对应目标的长宽。
下图展示网络模型预测出来的中心点、中心点偏置以及该点对应目标的长宽:

那最终是怎么选择的,最终是根据模型预测出来的ˆY∈[0,1]WR×HR×C值,也就是当前中心点存在物体的概率值,代码中设置的阈值为0.3,也就是从上面选出的100个结果中调出大于该阈值的中心点作为最终的结果。
Conclusion
Advantage
- 设计模型的结构比较简单,不仅对于two-stage,对于one-stage的目标检测算法来说该网络的模型设计也是优雅简单的;
- 该模型的思想不仅可以用于目标检测,还可以用于3D检测和人体姿态识别;
- 虽然目前尚未尝试轻量级的模型,但是可以猜到这个模型对于嵌入式端这种算力比较小的平台还是很有优势的。
Disadvantage
- 在实际训练中,如果在图像中,同一个类别中的某些物体的GT中心点,在下采样时会挤到一块,也就是两个物体在GT中的中心点重叠了,CenterNet对于这种情况也是无能为力的,也就是将这两个物体的当成一个物体来训练(因为只有一个中心点)。同理,在预测过程中,如果两个同类的物体在下采样后的中心点也重叠了,那么CenterNet也是只能检测出一个中心点,不过CenterNet对于这种情况的处理要比faster-rcnn强一些的,具体指标可以查看论文相关部分。
- 有一个需要注意的点,CenterNet在训练过程中,如果同一个类的不同物体的高斯分布点互相有重叠,那么则在重叠的范围内选取较大的高斯点。
Reference
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK