

链路层 网络层 UDP IO模型
source link: http://novoland.github.io/%E7%BD%91%E7%BB%9C/2014/07/26/%E9%93%BE%E8%B7%AF%E5%B1%82%20%E7%BD%91%E7%BB%9C%E5%B1%82%20UDP%20IO%E6%A8%A1%E5%9E%8B.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
链路层 网络层 UDP IO模型
1. 链路层
传输单位是frame,负责同一局域网内主机/直接连接主机之间的数据传输。
常见的链路层协议:
以太网(有线和无线局域网)
只讨论星形拓扑结构
共享型以太网
是一种广播网络,通过 集线器hub组建。Hub工作在物理层,单纯地复制并向所有主机转发物理信号,因此主机能够看到局域网内传送的所有信息。主机通过比对帧内的目的MAC地址和自己的MAC地址,判断是否接收。
WIFI也是共享型。
交换型以太网
通过交换机组建,交换机工作在链路层,会解析帧的目的MAC地址并选择性地转发。
以太网中的单播/广播/组播: 根据帧目的MAC地址区分
广播:(目的MAC地址全1)
组播
网络层中,组播地址允许源设备向一组设备发送数据包,组播IP地址只能是D类。
组播帧中的目的 MAC 地址是一个特殊的十六进制数值,以 01-00-5E 开头。然后将 IP 组播组地址的低 23 位换算成以太网地址中剩余的 6 个十六进制字符,作为组播 MAC 地址的结尾。MAC 地址剩余的位始终为 “0”。
帧的最大长度,不同类型的链路层有自己的MTU;当IP数据报长度超过链路层MTU时,需要分片。
2. 网络层
2.1 IP
IP协议传输的特点:
- best-effort,不保证到达
- 无序,不保证到达的顺序
主要负责两件事:
IP地址分为3个部分:网络号/子网号/主机号
网络号的长度:地址分类决定
头–网络号–(子网号&主机号)
A类
B类
C类
D类
子网号的长度:子网掩码决定
子网掩码的0决定了主机号的长度。
主机号全0代表这个子网,全1则是广播地址;这两个不能分配给主机。
保留IP地址,用于局域网
10.x.x.x、172.16.x.x-172.31.x.x、192.168.x.x
以太网根据帧的目的MAC地址决定该帧需要单播/广播/多播,相应的,IP地址也有这样的分类:
广播:主机号全1(指向网络的,子网号也全1/指向子网的)。
多播:D类地址
传输层协议中,只有UDP支持广播和多播。
IP数据报的传递是逐跳的。
路由器将各局域网连接起来,工作在网络层,负责IP数据报的转发。Switches create a network. Routers connect networks.
路由过程中,主机按照路由表匹配数据报的IP地址,决定下一跳要发往相邻节点。路由表项:
- 目标IP:一个完整的IP地址(主机号不为0),或一个网络地址(只有网络号和子网号,主机号全0,需要子网掩码判断主机号/子网号的长度)
- 下一跳路由器IP(gateway):符合该项的数据报发送到哪个路由器
- 网卡:经过哪个网卡发送
2.2 ARP
数据报从网络层进入链路层被发送,在发送一个以太网帧前,必须将目的IP地址(不是IP数据报中的目的IP,而是选路决定的下一跳IP)转换成以太网地址(MAC地址)。
ARP为IP到MAC地址提供动态映射,这个过程是自动的;每个主机有一个ARP缓存,ARP协议自动维护该结构。
ARP工作在网络层,有自己的数据报格式。它利用以太网的广播功能,发送一个广播帧给局域网内的所有主机,当某一主机收到对自己的ARP请求后(依据目标IP判断),就把自己的MAC地址填入并单播发送回去。
2.3 IP的配套协议:ICMP
工作在传输层,和TCP/UDP一样,由IP数据包包裹发送,但 逻辑上划分在网络层,作为IP协议的辅助协议,用于:
- 发送IP数据报传输过程中出现的错误;
- 查询/控制/诊断信息。
格式:
类型 | 代码 | 检验和 | 内容
类型和代码决定ICMP报文具体类型;
ICMP的典型应用:
1. 主机不可达错误
当主机/路由器接受一个IP数据报,但又无法转发时,向源主机发送“主机不可达”ICMP报文。
2. 端口不可达错误
UDP发送到主机一个没有使用的端口,目的主机将返回一个ICMP“端口不可达”错误报文。
3. Ping
目的:诊断网络通畅;
工作方式:循环向目标主机发送ICMP echo请求,目标主机返回ICMP echo响应。
4. TraceRoute
目的: 查看到目的主机的网络路径
原理: ICMP超时报文 + IP数据报中TTL字段。
TTL由发送端设置,指定数据报的存活跳数,每转发一次减1,当TTL降到0时数据报被丢弃,主机向源发送ICMP“超时”报文。
TraceRoute通过UDP发送数据给目的主机,但选择一个不可能的端口,目的主机将返回“端口不可达”ICMP报文。程序每次发送数据时,其TTL递增,初始值为1,依据“超时”ICMP报文构建路径,收到“端口不可到达”报文时结束。
2.4 IP数据报的分片
当IP数据报超过链路层的MTU时需要分片,每一片成为一个独立的数据报被传输,最终目的地负责组装。如果其中一片丢失,整个原始数据报被当做发送失败,这增加了IP数据报发送失败的机会。对于TCP这样的具有超时重传机制的高层协议,IP分片大大提高了需要重传数据的数量,因此TCP通过在连接阶段交换两端MSS/路径MTU发现等方式尽力避免IP分片。
IP数据报也可以被设置成不允许分片,当路由器发现其大小超过MTU但又无法分片时,将向源主机发送ICMP“不能分片”错误报文。TCP的路径MTU发现也是依赖该机制的。
3. 传输层
3.1 UDP
UDP是IP协议在传输层暴露的一个简单接口,增加了对“端口”概念的支持。
3.2 Socket缓冲区
1. 发送缓冲区
TCP 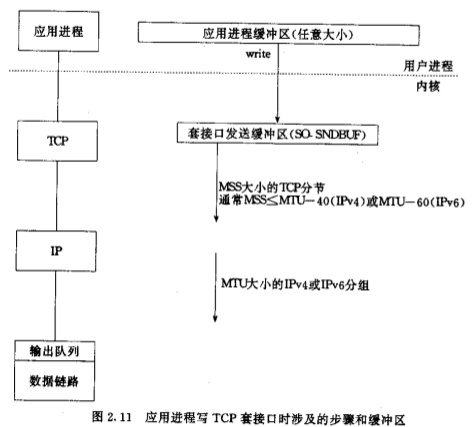
TCP服务器通常是并发的。每个TCP socket都有发送缓冲区,write只是将数据从应用进程缓冲区拷贝到了socket缓冲区,当发送缓冲区容量不够时,write调用被阻塞(假设是阻塞IO方式)。
TCP模块取发送缓冲区的数据并发送,报文段的长度为MSS或更小;直到收到ACK,数据才可从缓冲区中删除。
UDP 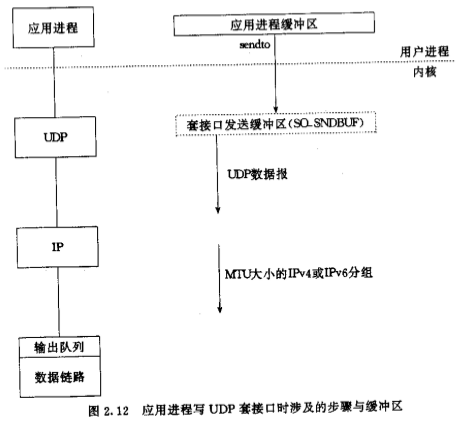
UDP是不可靠的,它不需要一个缓冲区保留数据用于失败重传。Socket上每次write,内核都直接将数据封装成一个UDP报文段/IP数据报,并将其或者其分片加入链路层的输出队列。UDP的发送缓冲区大小(SO_SNDBUF)其实是设置每次写到socket数据的最大值,当写数据大于该值时,返回EMSGSIZE错误。
理论上,UDP数据报的最大长度由IP数据报的最大长度决定,IP首部16bit总长度字段限制IP数据报最大长度为65535字节,但实际实现往往要小于这个值。
UDP没有MSS机制,因此更容易发生IP分片,数据更容易丢失。
2. 接收缓冲区
TCP
接收缓冲区的剩余空间就是滑动窗口协议中的接收窗口大小。
TCP提供流式的数据读取,当报文段到达时,应用层数据被提取并送入接收缓冲区,应用进程读取时不了解报文段之间的边界。
UDP
UDP没有连接的概念,因此UDP服务器通常只用一个线程循环处理所有收到的数据报,服务器端为所有客户端重用一个接收缓冲区,发来的数据报都会先在这里排队,并依次交付给应用进程。UDP是非流式的,应用进程以数据报为单位读取(将数据报从内核缓冲区复制到应用缓冲区),如果应用进程缓冲区小于该次读取的数据报长度,数据报将被截断,剩下的部分被丢弃,API提示一个错误。
参考:
SO_RCVBUF/SO_SNDBUF Socket Options
- Option Type: Int
- Every socket has a socket send buffer and a socket receive buffer
- Allows you to change the default sizes
- TCP buffer sizes for connected sockets are always inherited from the listening socket
Socket Receive Buffer
- For TCP, the available size in the receive buffer is the advertised window which is advertised to the TCP peer. This is TCP’s flow control.
- With both TCP and UDP, if a segment arrives which will not fit in the socket receive buffer, it will be discarded
- For TCP clients, this option must be set prior to calling connect( )
- For TCP servers, this option must be set for the listening socket, prior to calling listen( )
Socket Send Buffer
- UDP does not physically have a socket send buffer–it’s not a reliable protocol and need not keep a copy of the data for re-transmission. For UDP, SO_SNDBUF is simply an upper bound on the maximum sized UDP datagram which can be written to the socket (not the size of a physical buffer)
3.3 什么时候用UDP代替TCP?
- 如果只是简短的单次交互(如查询–应答),这时TCP的3次握手和4次挥手的开销就显得太大,UDP效率更高,但需要应用层自己负责超时和重传,保证可靠性;DNS就是这样的例子。
- 注重传输效率/时效性,不需要可靠性和有序性的场景,典型的如流媒体/语音通话
- 并发连接太多,TCP需要为每个连接维护相应的数据结构(如缓冲区),但每个连接上发送的数据频率较低且量小,此时UDP能显著降低开销,但可能需要在应用层提供TCP的一些特性,如超时重传/顺序性/流量&拥塞控制等等,如IM。
4. Unix下的IO模型
- 非阻塞IO
- IO复用(select/poll/epoll)
- 信号驱动IO
- 异步IO(Posix中的aio…系列函数)
以读为例,IO的两个阶段:
- 等待内核数据就绪,在TCP中就是等待TCP接收缓冲区中有数据;
- 从内核拷贝数据到用户空间
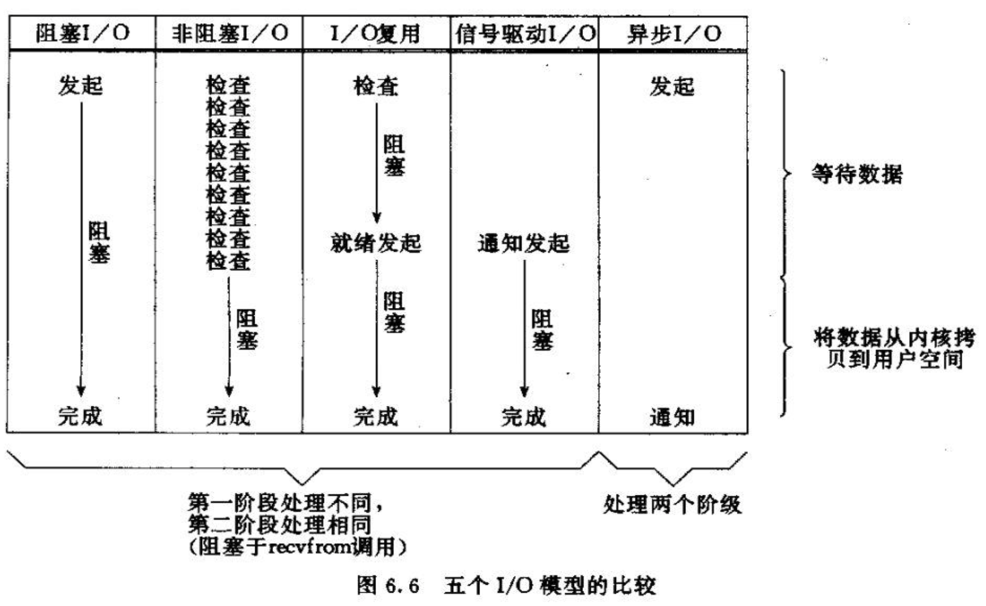
- 阻塞IO两个阶段都阻塞,直到整个请求完成;
- 非阻塞IO是best-effort式的,只做请求的一部分并立即返回;
- IO复用是针对第一个阶段而言的,阻塞在第一阶段,但可以用一个selector监控多个fd;第二阶段可以搭配阻塞IO或非阻塞IO;
- 信号驱动IO?
- 异步IO两个阶段都由内核完成,用户进程只需要提供一个callback,在IO完成后接收OS的通知。
异步和同步
假设某线程(姑且称为client线程)要完成某任务:
同步:client线程亲自处理,并在处理完毕后才去做别的事情;
异步:client线程提交任务给他人(内核/框架/etc)并立刻运行其他逻辑,后者在完成后通过某种方式(如callback)通知client线程。client线程也可以通过某些方式(如Future)在任一时刻查询任务完成的情况。
同步和异步的区别在于谁是任务的执行者:client线程 or 其他。
阻塞和非阻塞
阻塞:如果任务不能一次性完成,则client线程进入等待状态,任务之后的逻辑无法执行直到条件满足;
非阻塞:如果任务不能一次性完成,则完成部分并立刻返回,不会等待。
阻塞和非阻塞的区别在于client线程是否会进入等待状态
异步和非阻塞这两个概念尤其容易混淆,因为异步 “包含了” 非阻塞的语义(因为不是client线程完成的,不用傻等任务完成),但非阻塞并不一定意味着异步。这一点很好理解,比如非阻塞io依然需要client线程不停地来回在内核缓冲区和用户空间进行内存拷贝 — client线程参与执行了任务,它是同步的。
因此上述IO模型中,只有异步IO是异步的,因为该模型中IO的两个阶段都由内核完成,用户线程不参与IO执行。其余4种IO用户线程都必须参与第二阶段(内存拷贝),均为同步IO。
任务/client线程/任务执行者”的含义通常随语境变化。如Netty的write由client线程提交给框架执行,因此Netty的API接口对client线程而言是“异步的”。但如果细粒度地从底层IO考察,它是基于IO多路复用+non-blocking io的,属于同步IO。
4.1 多路复用
通常 IO multiplexing 和 非阻塞 二者是联合起来使用的。传统阻塞IO在服务器端的并发模型是一连接一线程,即使某个连接上没有数据流动,也要占用一个线程的资源;多路复用+非阻塞,连接上没有数据流动则不占线程资源,因此可以用少量线程处理大量连接,但只适合 “总连接很多,但同一时刻活跃连接较少” 的情况,如果连接的读写都很频繁,该模型没有优势。
select
// IO multiplexing: select
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);fd_set内部实际上是个bitmap,每个文件描述符对应一个bit。读写事件分别对应一个bitmap,需要监测某个socket则将其对应的bit置1。当select返回时,bitmap中有事件的为1,没有事件的被清零,循环bitmap可知哪些文件描述符上有事件发生。
每个进程的文件描述符(包括socket)从2开始依次递增
select的缺点:
- bitmap的长度决定了单个进程能够监控的socket的最大数量,但它是个固定值,由系统决定,一般是1024或2048,大部分情况下不够,如果要支持更高的连接数则只能用多进程;
- select需要将fd bitmap在用户空间/内核空间来回拷贝,这个开销是O(N)的;
- select是基于 轮询的,每次select内核需要对所有监控的fd扫描一遍,O(N),连接数一多性能就下降;
- select返回后,用户必须自己遍历bitmap才能知道哪些fd上有IO事件发生。
Poll
// IO multiplexing:poll
poll(struct pollfd *fds, int nfds, int timeout)
struct pollfd {
int fd;
short events;
short revents;
}poll和select本质是一样的,只不过它不是基于bitmap而是基于结构体数组的,没有最大连接数的限制。
epoll
// IO multiplexing:epoll
int epoll_create(int size); // 创建epoll fd
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);// 注册监听
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout); // 返回后events数组中就是IO事件- 监视的描述符数量不受限制,它所支持的FD上限是最大可以打开文件的数目。
- epoll 是基于 callback的,它为每个fd定义一个callback,只有活跃的 fd(设备) 会主动调用自己对应的 callback,这相当于将原来的线性扫描的工作分散给各个fd自己了,因此时间复杂度为O(IO就绪的fd数量),而不是O(N),当连接数很多但活跃连接少时,性能大大提升;
- 支持
Level Trigger和Edge Trigger(只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为Edge Trigger;select和poll只支持LevelTrigger,会反复通知)两种方式; - 内核需要将就绪fd通知给用户进程,select和poll简单地进行拷贝,epoll则使用mmap避免多余的内存拷贝;
- 只将IO就绪的fd通知给用户,不再需要自己遍历所有fd检查IO事件。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK