
7

有了这个Python程序后,干完饭不用再花时间算账了
source link: https://blog.csdn.net/dchzxl/article/details/123444347
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

大家好,我是翔宇!
今天带大家实现一个算账自动化,由于疫情,公司员工吃饭等着食堂送到工位,然后由我来帮大家订餐,每个周五由我来算账,再收大家的饭钱。
于是我用python写了这么一个自动算账的小程序。
首先,我们是用钉钉进行接龙点餐,于是,当我把数据导出来之后,它是这样的。

于是,之前我都是采用“人工智能”(我自己)来做这项工作的。然后将它整理成下面这样。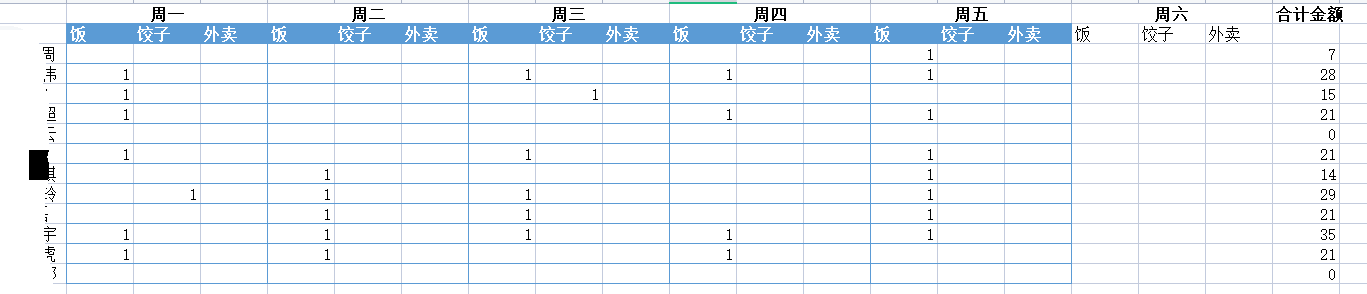
而“人工智能”罢工后,我不得不用Python写了今天这样一个“小程序”来进行自动化计算。
再进行自动化计算后,得到的效果是这样的。(1代表7元的快餐,2代表8元的饺子)
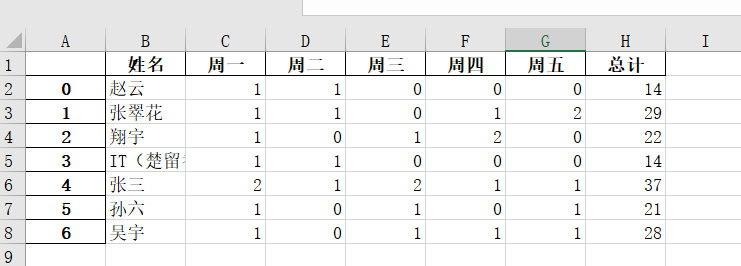
1.导入数据
原始数据是这样的,因此,我将一个周的都导出来以后,也就得到了上面第一张图那个数据。
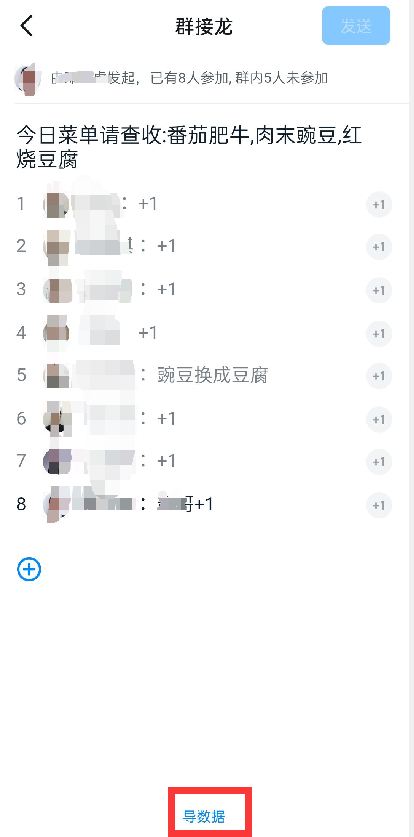
原始表格我已经上传到后台,需要数据去练练手的小伙伴,请在本公众号后台回复“算账”后自取。
2.采用pandas处理数据
得到数据后,接下最核心的步骤就是想办法将它处理成下面这个样子。
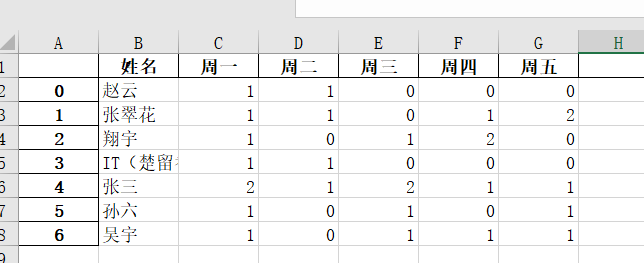
这也是我平时采用“人工智能”去解决去问题,只要到这里了,那剩下的不管你是用excel进行计算还是用手机打开计算器来算了填上去,这都不在是事情了吧!
2.1类似excel中的分列处理
# pandas处理数据
import pandas as pd
import numpy as np
df1 = pd.read_excel('data/订餐算账自动化.xlsx',sheet_name='明细')
df1.head(10)
# 去掉第一行记录
df1.drop(index=0,inplace=True)
# 类似excel中的分列处理
merged_DataFrame = pd.DataFrame()
for i in '一二三四五':
temp_str =f'第{i}天'
# temp_str_end = "'{}'".format(temp_str) # 加引号
# print(temp_str_end)
temp_DataFrame = df1[temp_str].str.extract(r'.+?,(.+?),(.+)') # 全空列不能.str
temp_DataFrame.rename(columns={0:f'周{i}姓名',1:f'周{i}'},inplace=True)
for column in temp_DataFrame.columns:
merged_DataFrame[column] = temp_DataFrame[column]
merged_DataFrame
经过几下操作后
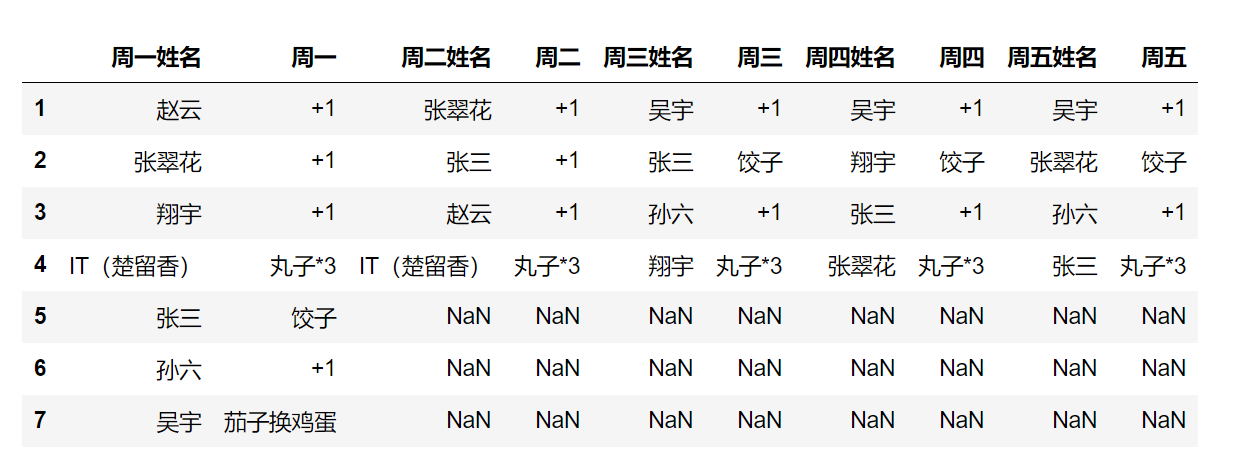
2.2采用正则表达式处理
# 采用正则表达式处理
# 将含有饺子的记录变为2,其它的都为1
for i in '一二三四五':
merged_DataFrame[f'周{i}'].replace(regex={r'.?[饺].':2,r'.+':1},inplace=True)
merged_DataFrame
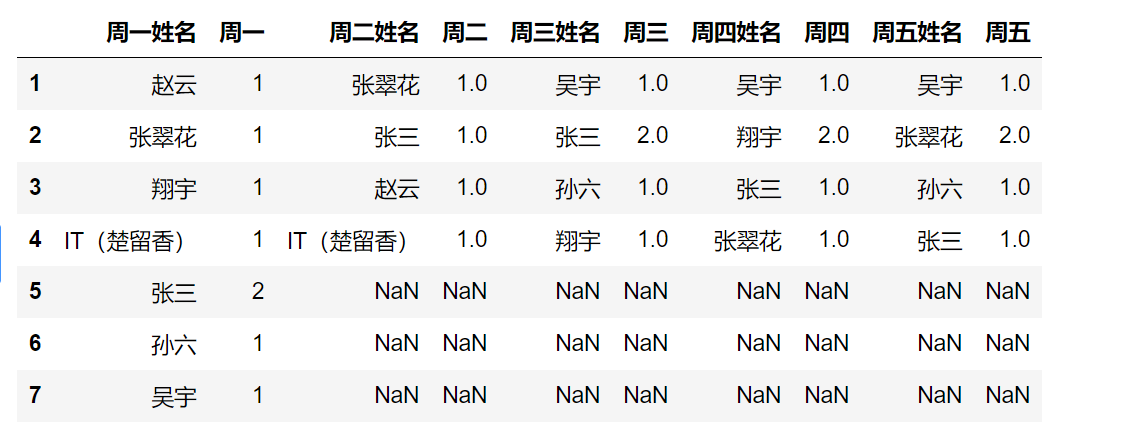
2.3每次取两列与“主表”进行左外连接
# 创建一个新表,只有所有人的名字
result_DataFrame = pd.DataFrame({'姓名':merged_DataFrame.周一姓名.values},index=merged_DataFrame.index)
result_DataFrame

# 每次取两列与新建的表进行左外连接
for i in range(0,10,2):
temp = merged_DataFrame.iloc[:,i:i+2]
temp.rename(columns={temp.columns[0]:'姓名'},inplace=True)
# temp
# # result_DataFrame = result_DataFrame.join(temp.columns[0], on='姓名') #不对的
result_DataFrame = pd.merge(result_DataFrame,temp,how='left',left_on='姓名',right_on='姓名')
# result_DataFrame = pd.concat([result_DataFrame,temp],axis=1,join='inner') #不对的
result_DataFrame
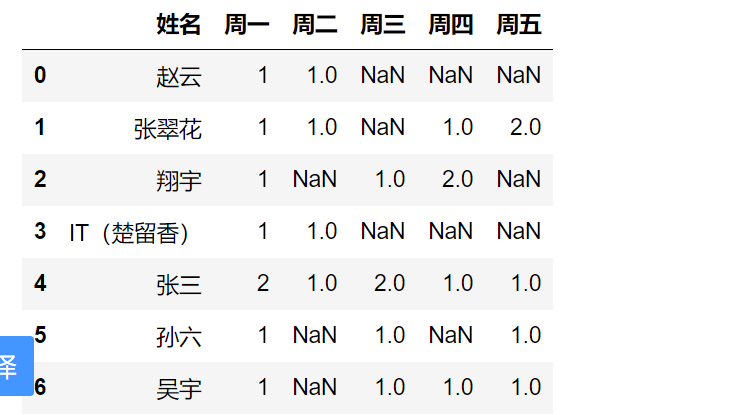
大致雏形已经出来了,下面,只需要处理空值了
3.1将NAN值全部处理成0
# 读取数据
df = result_DataFrame
df.head()
df.info()
# 将NAN值全部处理成0
df.fillna(0,inplace=True)
3.2建立映射,计算“总计”列
将1对应7元,2对应8元,建立字典
# 建字典
def get_value(key):
calc_dict = {0:0,1:7,2:8}
return calc_dict[key]
# 计算“总计”列
total = np.zeros(len(df))
for i in "一二三四五":
total += df[f'周{i}'].apply(get_value)
df['总计'] = total
df
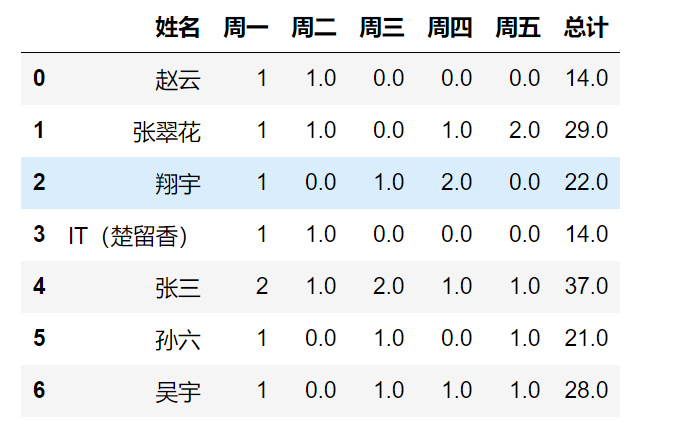
4.保存结果
df.to_excel('data/干饭算账自动化结果.xlsx')
接下,在data路径下打开excel文件,我们就得到总账了
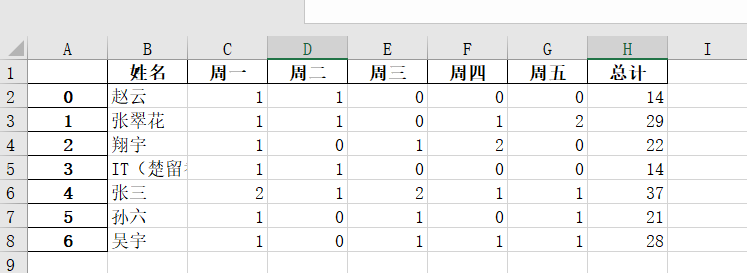
好了,今天的内容就是这么多,完整代码翔宇已经整理好放后台了,需要的小伙伴请到同名公众号在后台回复“干饭算账自动化”,获取吧!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK