

在线“杀死” App 的卡顿难题!
source link: https://www.51cto.com/article/701837.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ANR(Application Not Response)是安卓开发团队经常遇到的无响应问题,但却很难定位和根除。尤其是线上问题,由于难以复现,导致开发者难以有效地快速解决。为此,本⽂将为大家分享作者是如何在⼀个⽉内降低 50% 的 ANR 线上问题发⽣率的探索与实践,希望能对开发者有所帮助或启发。
Google 的一项内部研究表明,过高的崩溃与 ANR 发生率会直接影响应用的评分情况,并且很难在商店中累积起用户量,严重影响应用在商店的排名情况。这一系列的连锁反应将会给应用带来很大的损失,且有可能失去在应用商店获得谷歌推荐的资格。因此,ANR 问题对于⼤多数安卓团队来说十分棘手,尤其是线上问题令人头疼。因为本地问题可以复现,线上 ANR 却很难。因而探究线上 ANR 问题的治理⽅案更具意义。
触因与流程分析
1. 关于 ANR
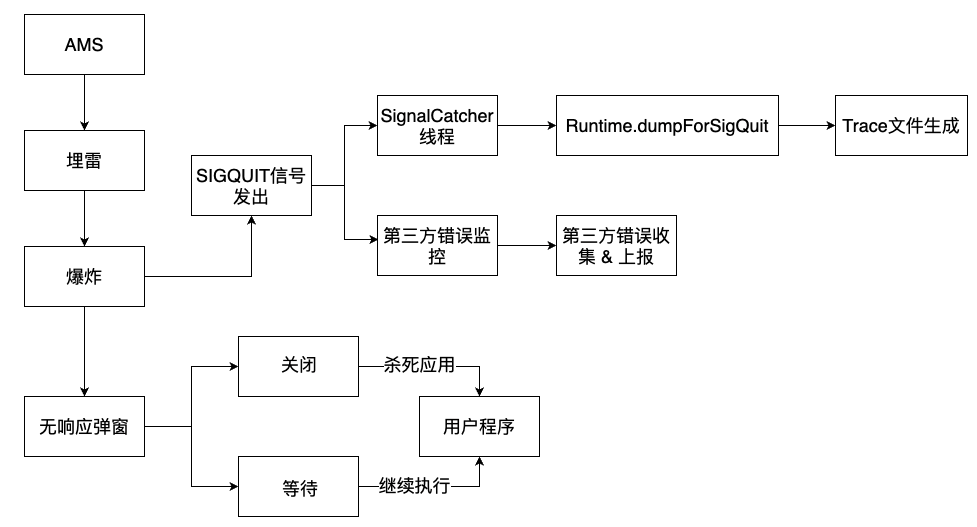
从用户侧看, ANR 问题是指⽤户在使⽤应⽤过程中出现了严重卡顿或卡死时,系统给出的⽆响应提示弹窗。而从系统侧看,ANR 问题就是 AMS 在执⾏特定⽅法时出现的超时错误,触发点有四个:
- InputDispatching Timeout
- BroadcastQueue Timeout
- Service Timeout
- ContentProvider Timeout
系统的 ANR 触发流程⼤致可分为两个部分:
⽤户可以直观感受到的 ANR 弹窗,这部分由 AMS 处理。
同时 AMS 还会发出⼀个 SIGQUIT 信号: SignalCatcher 线程会接收到这个信号,并且处理后续的 dump 逻辑;市⾯上的 ANR 错误收集 SDK⼤部分都依赖于这个原理。
2. 现状与挑战
根据美图秀秀 Android 端的线上监控数据表现, ANR 问题⼏乎是崩溃问题的两倍。在这种情况下,⾸先要考虑的就是如何将问题数量降低,然后再考虑后续⽅案。
⾯对大批问题,⾸先就是对数据进⾏分析、归类和梳理以便找出头部问题。美图秀秀的线上头部问题分布如下:
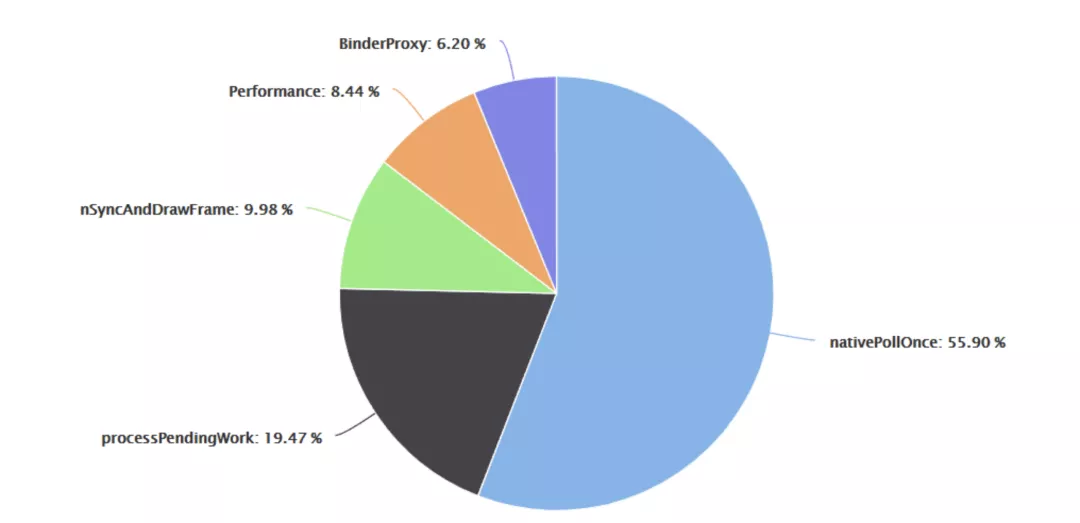
这些问题经过简单分析后,得出了如下结论:
nativePollOnce 问题,暂时不能依赖现有的⽇志信息得出结论。不过其占⽐较⼤,要放在⾼优先级处理。processPendingWork 问题已经有可靠的处理⽅案。占⽐不低,应该放在较⾼的优先级处理。
剩余问题数量相近,所以处理顺序并不固定。
分析与实践
在分析具体问题之前,⾸先跟⼤家分享⼀下笔者在处理问题过程中总结的⼀些经验。
我们遇到的绝⼤部分问题,都可以分为两类:
有源问题:是指可以直接溯源、定位到的问题;有源问题通常可以直接解决,其处理结果直接影响到线上的某个指标(如:相应问题的发⽣次数,发⽣率等等)
⽆源问题:问题成因不定且没有确定的线索;⾯对⽆源问题更多时候需要“⼤胆假设,⼩⼼求证” 。通常⽆源问题需要更多的现场信息以及侧⾯证据来溯源。成功溯源之后的⽆源问题可转换成⼀个或 多个有源问题。
当⼀系列问题有了明确的优先级以及分类之后,我们就可以开始分析单体 Case 了。
1. MessageQueue.nativePollOnce 问题
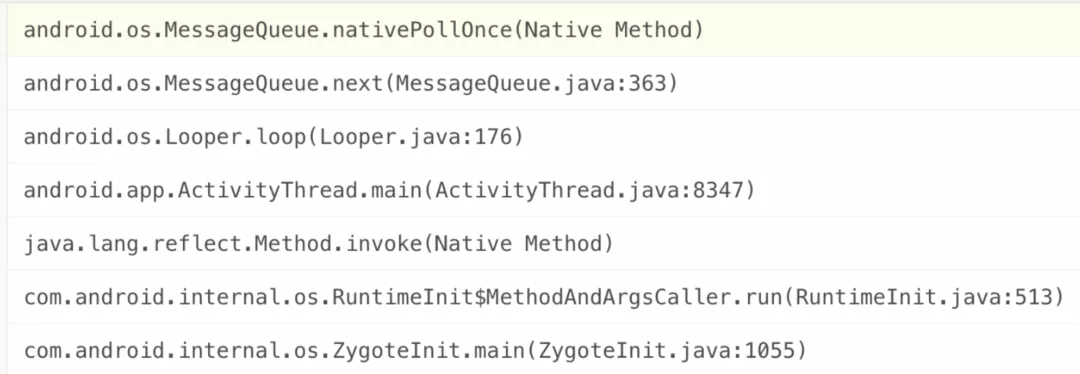
线上上报的堆栈如上图所示。棘手之处在于:如果只看上报的堆栈和错误⽇志,很难排查出问题的根本原因。上⾯提到过,处理这类问题要“⼤胆假设”,其可能的原因有:
- 主线程状态异常导致“停顿”
- 卡顿堆栈漂移
- 其他未知原因
- 有了假设之后,就需要“⼩⼼求证”了:
- 假设主线程异常,那么因何产⽣?
- 假设卡顿堆栈漂移,那么真实的卡顿堆栈在哪⾥?
1.1 主线程卡死情况
Android 应⽤启动过程中有这样的⼀段逻辑:zygote 初始化 →RuntimeInit 初始化。在 RuntimeInit 初始化过程中会注册⼀个默认的错误处理器来响应异常,如下所示:

默认的异常处理机制会在线程发⽣ Crash 时同步给 ActivityThread、ActivityManagerService 之后再“kill”掉⾃身。
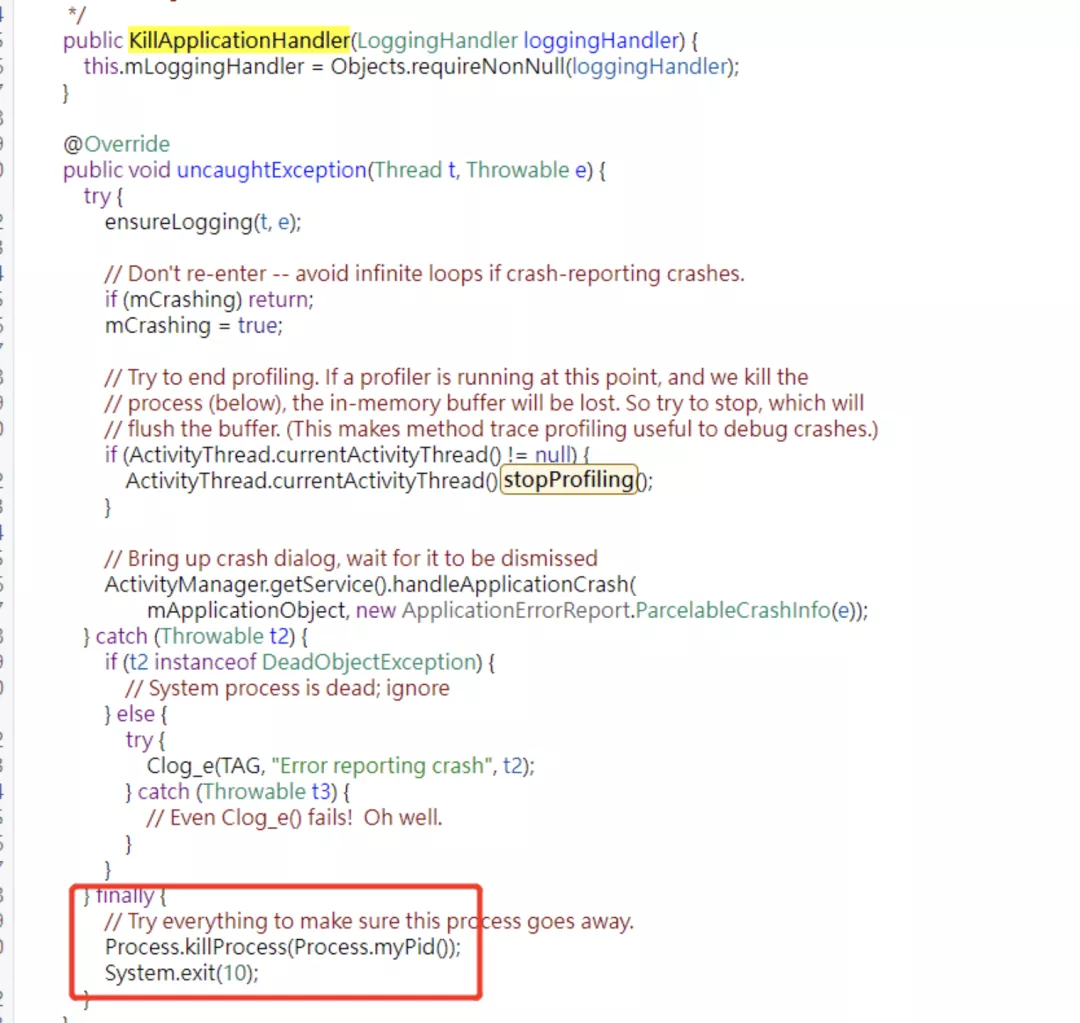
那么如果当主线程发⽣异常的情况下,不使⽤系统的处理链路或异常处理过程中耗时过久就会发⽣ ANR。当主线程发⽣了崩溃后其实已处于终⽌状态。此时主线程 Looper 的 MessageQueue 组件⽆法继续添加新的消息,⽽ Android 应⽤的运⾏恰恰依赖的就是主线程的消息轮询 -- 线上这个错误堆栈也是指向了 MessageQueue 组件在等待新消息的到来。因此,当主线程发⽣异常并⽆法及时 kill 掉进程时,系统就 会触发 ANR 超时机制。按照以上的逻辑推断,我们通过埋点找出了线上异常处理链的各个⽅法耗时数据:
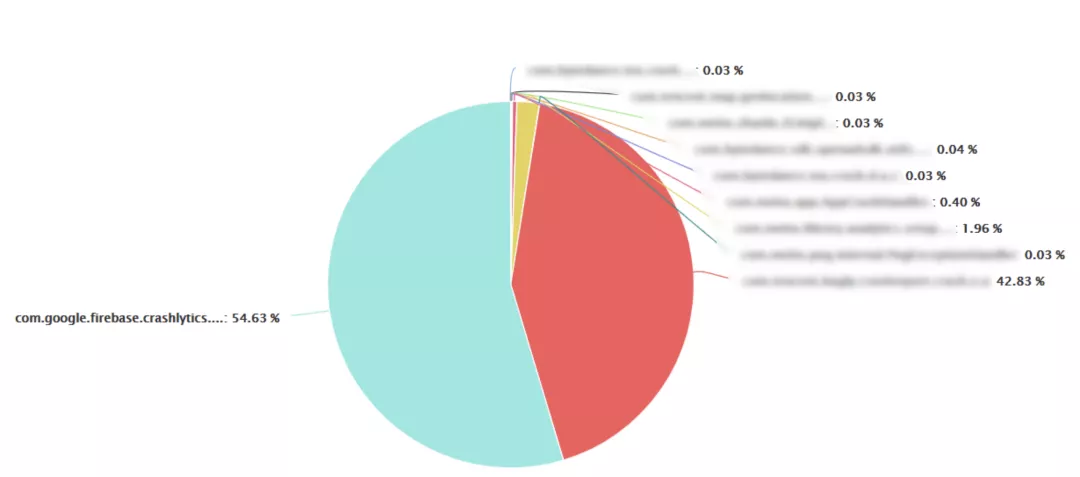
通过对⽐各个异常处理⽅法的耗时可以发现,Firebase 异常分析 SDK 在异常处理链路中耗时最⻓。预计移除此组件可降低该问题的发⽣数量。
最终在去除 Firebase 异常分析 SDK 的版本上线之后,线上数据显示整体的 ANR 率都有所下降。
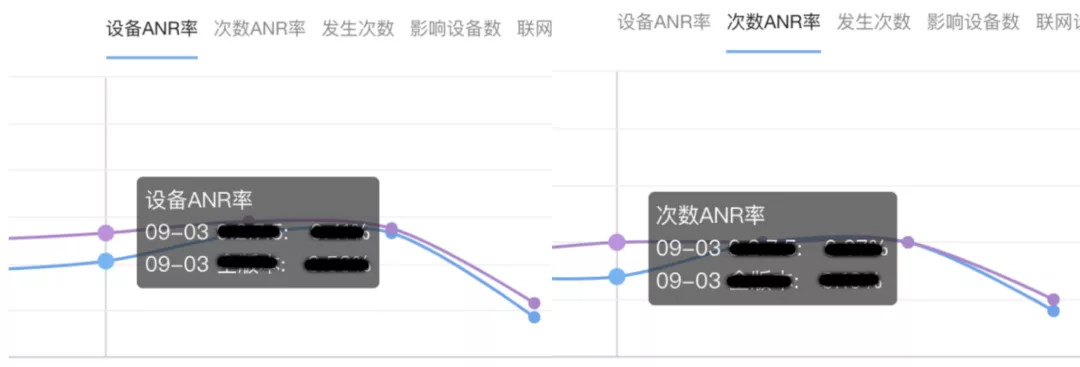
接下来分析另⼀种情况:
1.2 卡顿堆栈漂移
在这种情况下,错误上报中的卡顿堆栈已经失真,⽆法反映出当时现场的真实的情况。因此,增加线上的慢函数监控可以更准确地分析此问题。
线上慢函数监控的原理:
查看 Looper 的源码得知:主线程所有执⾏的任务都在 Looper.loop() ⽅法中的 msg.target.dispatchMessage 中派发执⾏。在这⾥有个 Printer 组件分别在消息的执⾏前、后会 有⼀个打印的⽅法调⽤。可通过 Looper.setMessageLogging ⽅法设置⼀个 Printer ,来监控每 个 Message 的执⾏时间:

监控逻辑的关键代码:

在后期,我们通过这种⽅式获得了以下慢函数数据:
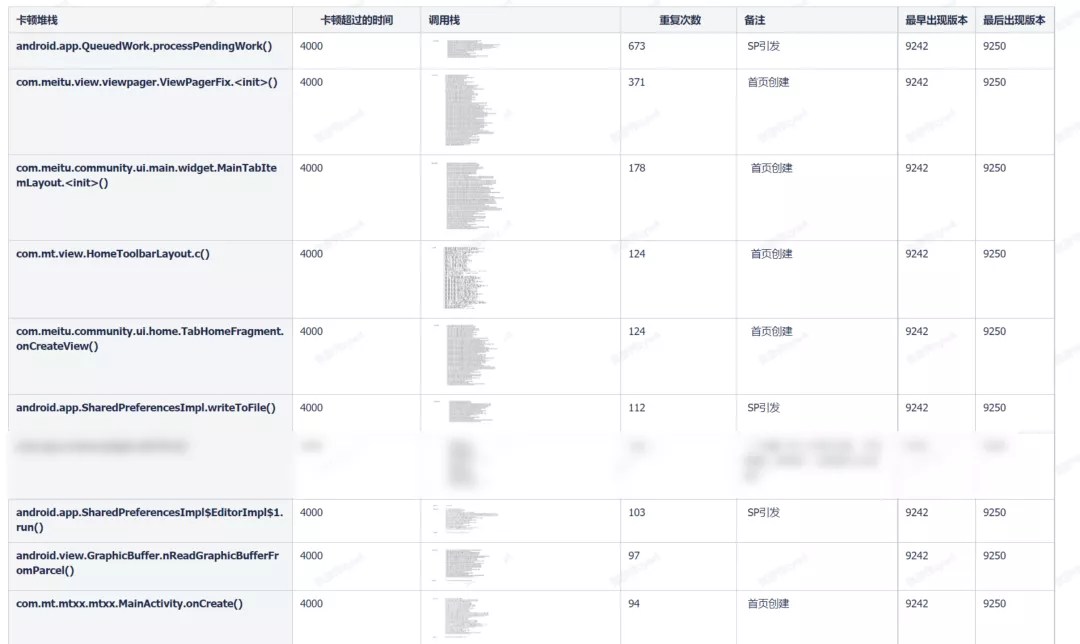
整理后得到的分布数据:
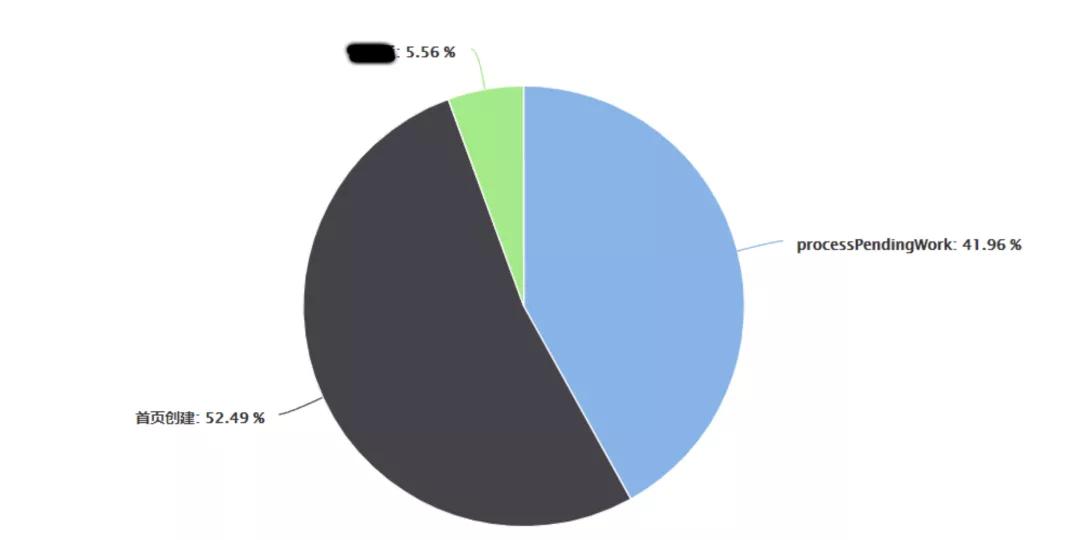
不难得出:
【QueuedWork.processPendingWork】、【⾸⻚创建】类型的问题占⽐最⼤,必须优先处理。下⾯将详细分析这两个问题。
回到上⾯错误处理的思路中:
此问题的处理中,使⽤了通⽤的⽆源问题处理⽅案。通过 【假设 -> 验证 -> 上线 ->数据变化 】这⼀流程,最终减少了此问题的发⽣或转换成了有源问题。当然,这个问题的诱因不只以上两个猜想,还有更多的可能需要进⼀步探索。
2. QueuedWork.processPendingWork 问题处理
问题调⽤栈:
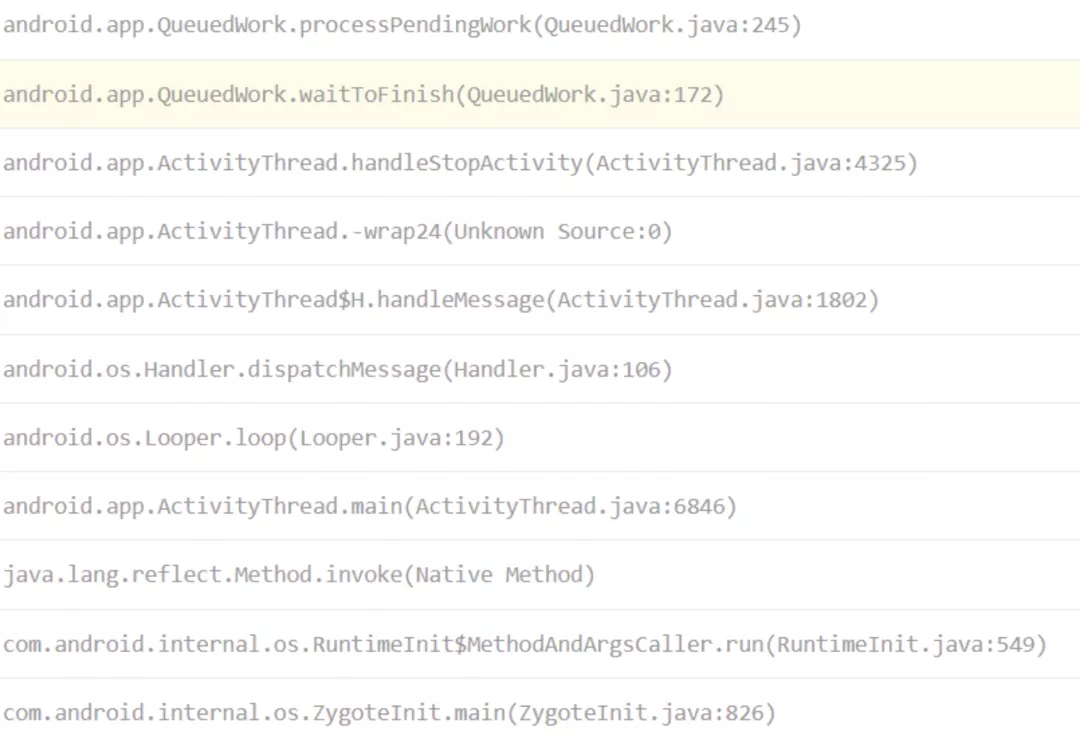
对 AndroidFrameWork 源码接触较少的同学们,可能并不了解这个类的作⽤。这时候可以借助 Android 源码搜索引擎来⼀看究竟:
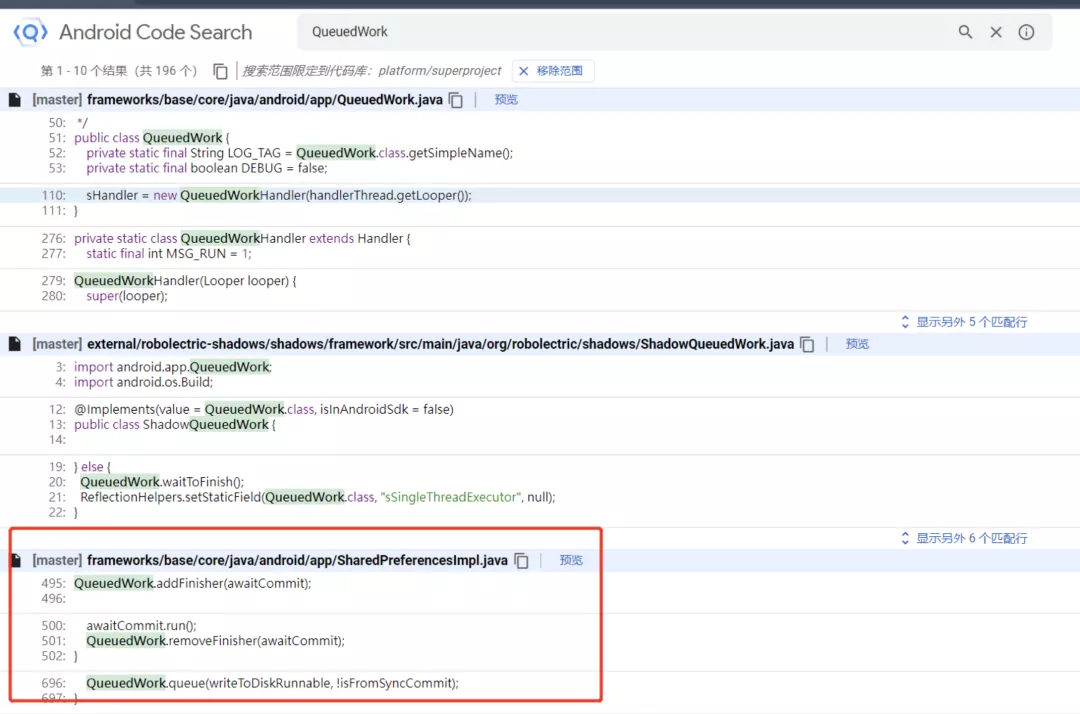
通过对源码的分析,可以得出⼀个⼤致流程:
SharedPreferencesImpl.apply() ⽅法中调⽤ QueuedWork.add() 将 SharedPreferences 的写 ⼊任务添加进 QueuedWork 的任务队列中,之后 ActivityThread 在⼀些组件⽣命周期⽅法中执⾏了 QueuedWork.waitToFinish → QueuedWork.processPendingWork 这⼀流程。这⼏个⽣命周期方法有:
- handleStopService
- handlePauseActivity
- handleStopActivity
- handleSleeping
以上的⽣命周期⽅法都会先等待 QueuedWork 中的异步队列执⾏完成,再执⾏后续的流程。
很容易得出这样的结论:SharedPreferences 的 apply ⽅法本身设计为异步写⼊,⽽Android 系统为了保证数据有效性会在特定的⽣命周期⽅法中等待异步写⼊任务的完成。如果这个任务处理耗时过⻓,就会产⽣ ANR 问题
美图秀秀内部开发了⼀款代码的织⼊⼯具 MtAjx 。其类似于⼤家熟知的 AspectJ ,相⽐ AspectJ ⽅案, 有着更好的兼容性(司内⼤批项⽬编译遇到 AspectJ 的问题)以及更⼈性化的 API 设计。
在处理这个问题时,我们使⽤了 MtAjx 来拦截 SharedPreferences 的创建,并返回带⽇志输出功能的 SharedPreferencesWrapper 。
简化的流程如下:
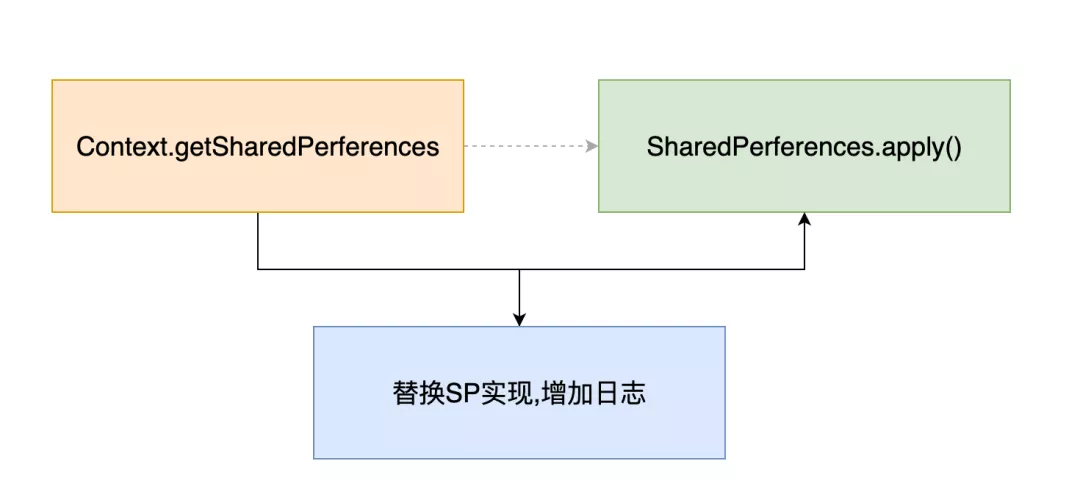
要完成上⾯的功能,使⽤ MtAjx 只需要编写⼀些简单的规则即可实现:
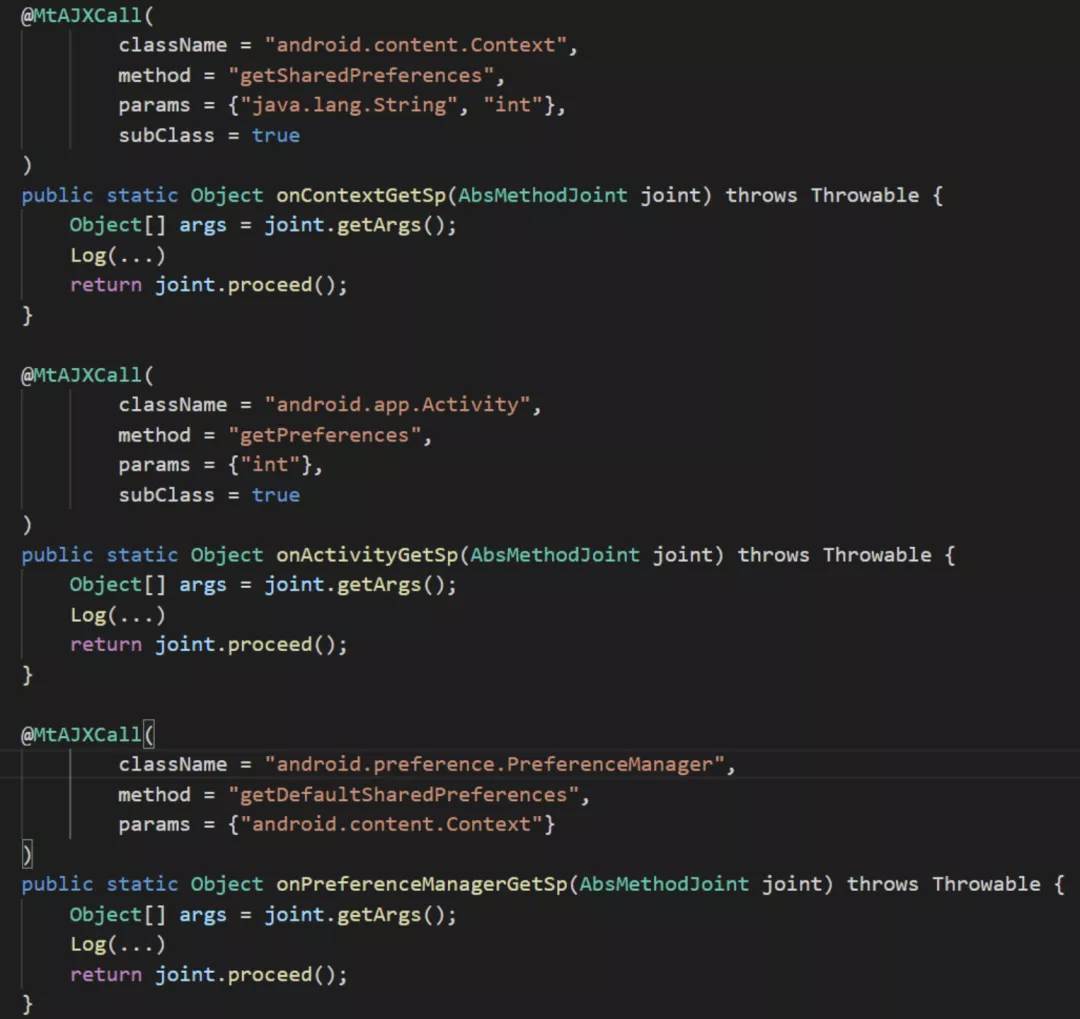
接下来可采⽤⾃动化测试来模拟线上⽤户的真实操作,并通过 SharedPreferencesWrapper 的⽇志对SharedPreferences 写⼊频率进⾏分析。
最终输出的数据如下:
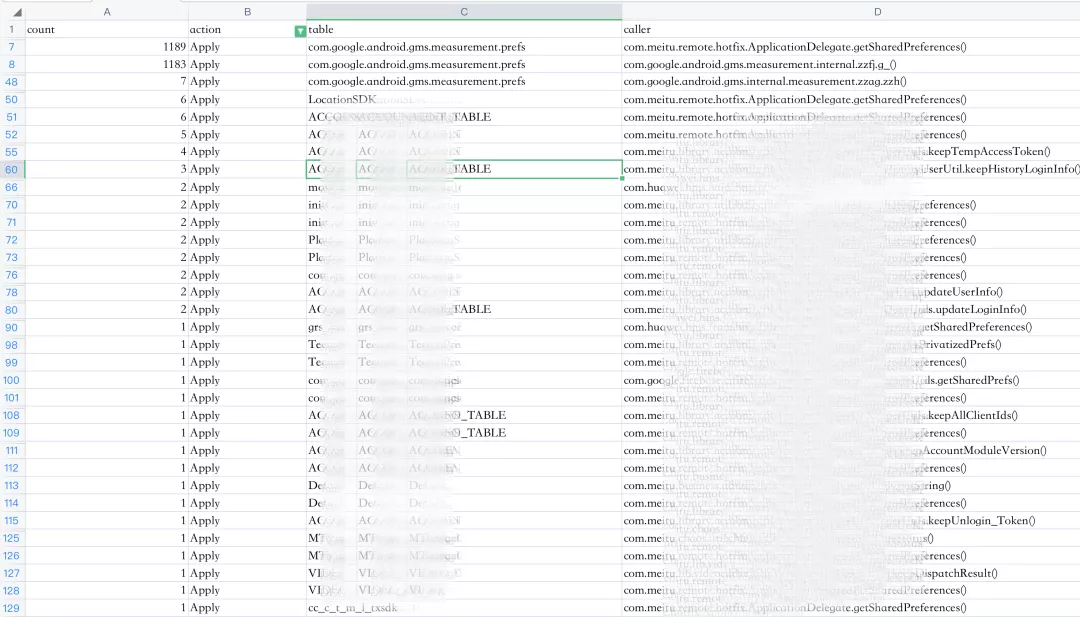
⽬前收集的线索可以推断出: GMS 组件的某个操作,⼤量地调⽤了 SharedPreferences 的 apply ⽅法。这个操作可能会使 SharedPreferences 的异步写⼊任务创建过多从⽽导致 ANR。后期处理此问题时,我们对这个组件进⾏了改造:使⽤ MtAjx 在 GMS 中拦截 SharedPreferences 的创建、获取操作, 并返回⼀个安全的 SharedPreferences 实现。⽽然上线之后,得到的数据跟预估的有些差距:
⾃身问题减少的⽐例很⼩
线上整体 ANR 波动不⼤
猜测这个问题发⽣时系统的 IO 负载已⼗分严重,处理部分场景可能收益并不⼤。于是之后上线了全量的 SharedPreferences 替换来避免此问题发⽣。
请注意,这⾥的“全量”并⾮真正的全量替换,⽽是排除了⼀些可能会受到影响的调⽤。⼤部分都只涉及 业务,这⾥不作为核⼼展开讨论;使⽤“安全的” SharedPreferences 实现只是规避问题,其根本还 是需要降低系统负载。
处理全量 SharedPreferences 替换的处理的⽅法与⽇志输出的流程类似。也采⽤了 MtAjx ⽅案来拦 截 SharedPreferences 的创建,并返回⼀个安全的实现。
此处为了容灾,线上做了在线开关作为全量替换的整体控制策略来规避未知⻛险。
最终,这个策略上线之后,上述问题整体降低了 60%-70%,详见下图:
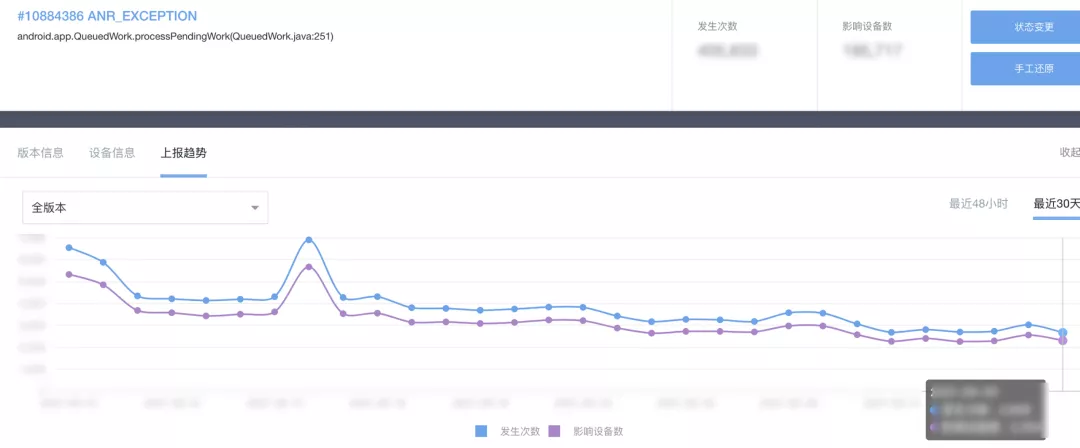
3. 首页创建问题处理
这个问题是通过前⾯提到的慢函数数据分析发现的。经过堆栈类聚分析之后,关联到了线上的两个指 标:
- 慢函数——关联了四个问题。
- ANR——关联了 N 个问题,⽽且问题很分散。
其中,慢函数问题多发⽣在某些 View 的初始化过程中。下⾯是⼀些线上触发此问题的点:
- ViewPagerFix.()
- MainTabItemLayout.()
- MainActivity.onCreate()
- HomeTopHeaderLayout.
筛选出上述问题的最终调⽤栈如下:

所有的卡顿点都落在 Runtime.loadLibrary0() 这个调⽤上。
线上 ANR 或者慢函数的数据表现也近乎⼀致:都是⾼通机型、低端机较多。
经过分析得知,⾼通机型存在⼀个 BoostFramework 组件⽤于加快应⽤的响应速度:类似的机制 可以在 特定情况下提升调度优先级、CPU 频率,从⽽加快应⽤的响应速度。
但在某些情况下,这种机制会导致应⽤发⽣卡顿:BoostFramework 初始化依赖⼀个 so 的加载。⽽Runtime.loadlibrary0 是⼀个 synchronize 修饰的函数,多线程调⽤必然会存在锁竞争情况。
美图秀秀在启动过程中,存在着⼤量“异步”加载 so 的操作。如果⼦线程先于主线程进⼊ Runtime.loadLibrary0 ⽅法,拿不到锁的主线程就会等待⼦线程释放锁之后再继续执⾏。也就是说,如果某个⼦线程中存在着耗时较久的 so 加载⾏为,就会阻塞主线程的 so 加载。
⽬前 so 的加载时间还是盲区,⽆法针对性地去处理这个问题。与之前 SharedPreferences 问题处理的思路⼀样:使⽤ MtAjx 拦截 System.loadLibrary() ⽅法并输出其耗时,最后得到如下数据(部分):
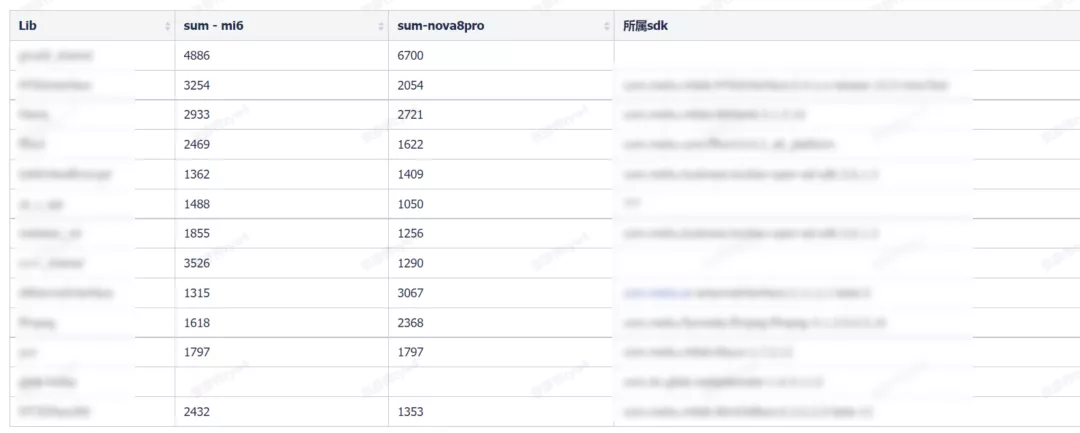
从数据上看,某些 so 加载确实消耗了不少时间。要解决此问题,⽬前初步的⽅案有:
尽量降低异步 so 加载对主线程 so 加载产⽣的影响
尝试 Hack ⾼通平台的 BoostFramework,让其延迟加载或提前加载
列举出可以执⾏的⽅案如下:
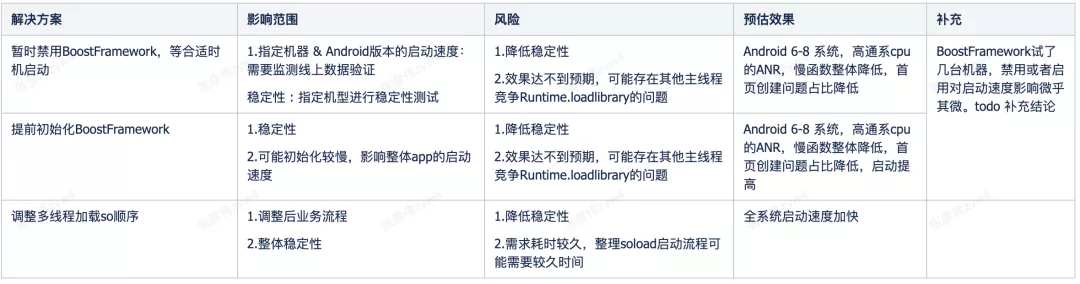
最终上线的⽅案:
- 延迟执⾏异步任务中的 so 加载
- ⾼通平台的 BoostFramewok 加速在合理的时间启动
对这种系统 Hack,必要的容灾还是要做。这⾥与之前的⽅案⼀样,通过在线开关去决定 BoostFramework 加载时机。
采⽤最终⽅案上线之后,得出了⼀些线上的数据:
- 关联 ANR 问题发⽣数降低 50%
- 低端机启动速度提升 13%
- 低端机 ANR 率降低,最⼤幅度在 50%
复盘 2、3 两个问题,都经历了类似的处理过程:
- 分析:这⾥包括对问题的根本原因、原理、发⽣场景全链路进⾏完整分析
- 建模:指将问题直观地“数据化”。如SharedPreferences 的读写频次分析、 so 加载中的加载时常数据分析、以及线上的慢函数、ANR 数据变化。
- 预估:列举现有⽅案的优劣对⽐,以及可能产⽣的影响,容灾措施等
- 验证:最终结果和预估时的进⾏对⽐,是否影响到线上关联问题的核⼼指标。
4. BinderProxy 问题处理
线上 Binder 问题的堆栈表现多种多样,不过其最终调⽤点都是android.os.BinderProxy.transactNative() 方法。
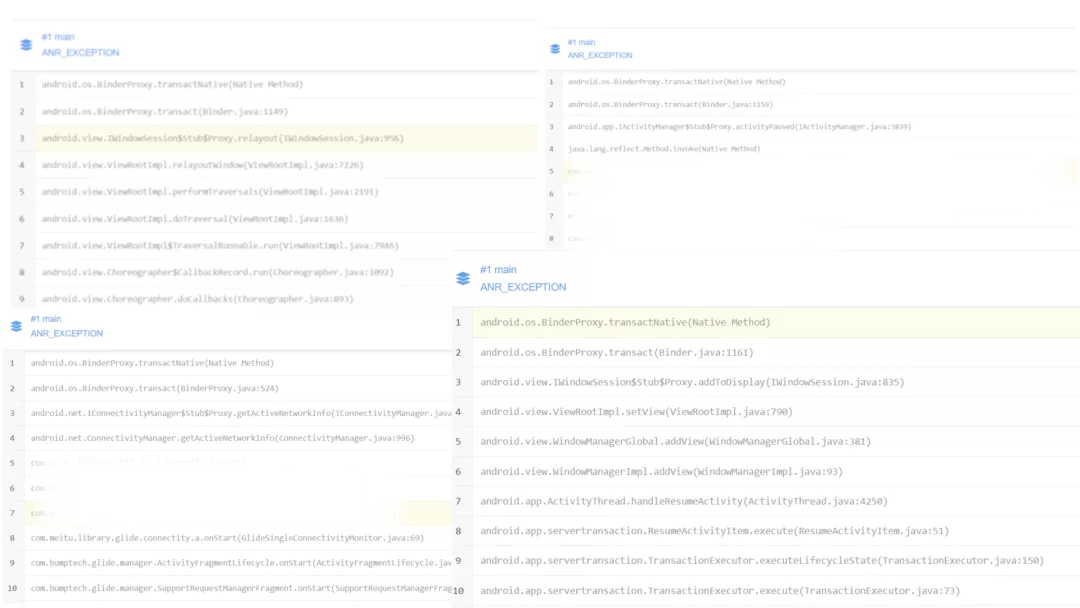
经过分析、查阅资料后,初步得出结论。当出现此类问题时,系统或应⽤基本都处于以下这些状态:
- Binder 本地资源耗尽
- 远程服务被频繁调⽤,致使远程服务负载过⾼
- 其他资源耗尽情况
这个问题的处理思路跟前⾯的⽐较类似:⾸先是收集不同场景下的 Binder 调⽤数据,然后针对数据进 ⾏分析、评估是否存在不合理场景。
不同于之前的例⼦:Binder 问题最终完全发⽣在系统层,⽆法通过 MtAjx 进⾏拦截。因此,换⼀种⽅ 式:通过 NativeHook 可以拦截所有的 Binder 调⽤,从⽽获取到 Binder 调⽤运⾏期的数据。此处选 择了 BinderProxy.transact() 作为拦截点:
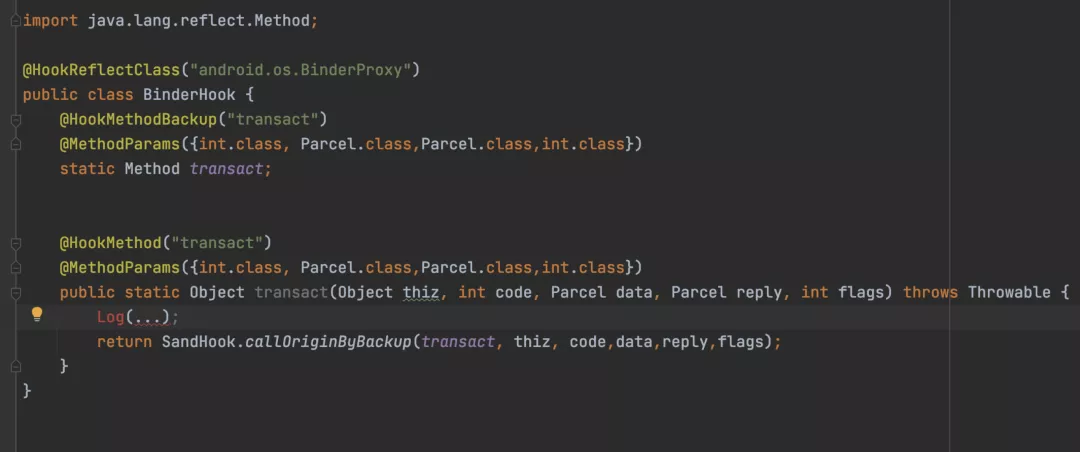
仍然采⽤⾃动化测试来模拟线上⽤户的使⽤情况并输出⼀份⽇志,分析后得到如下数据(部分):
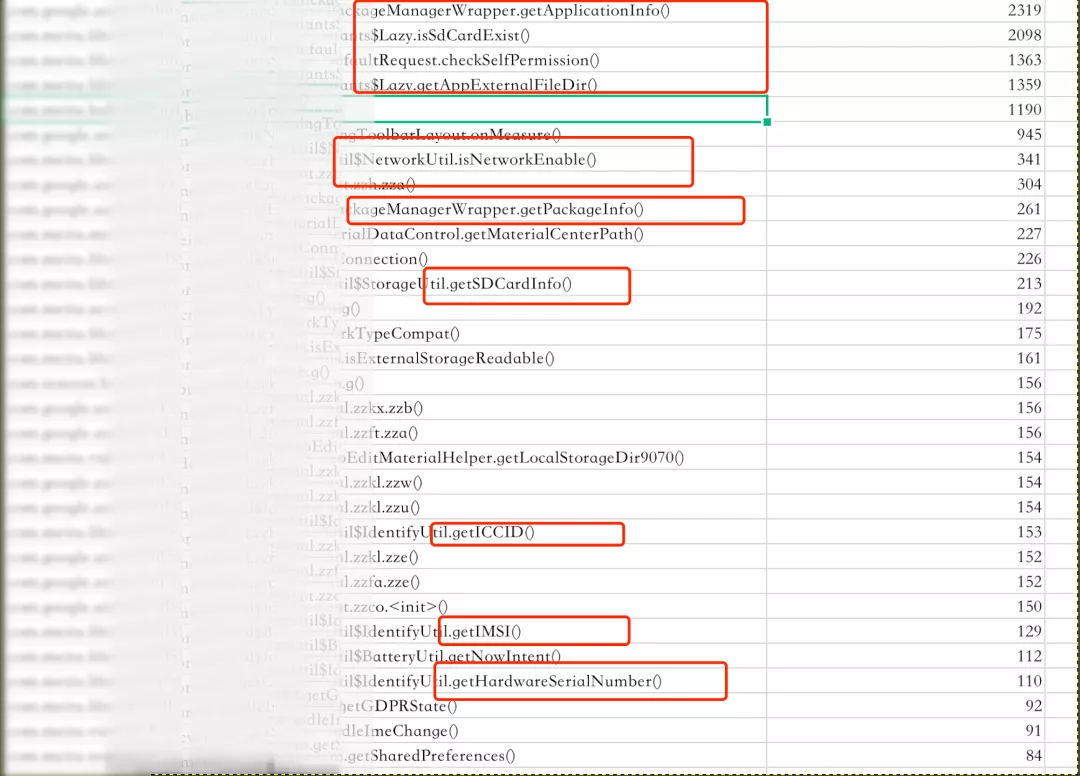
数据反映出了⼀系列问题:
- 频繁获取本身 package 信息:如 versionName,versionCode
- 频繁获取设备信息:如 IMEI,IMSI,⽹卡地址
- 频繁⽹络类型检测,⽹络状态检测
- 频繁访问本地⽬录
- 频繁权限检测
这些⽅法的调⽤频率都出现了异常(有些甚⾄超过了 View 绘制)。通过汇总整理,输出⼀份最终修改结论和建议,供内部或者第三⽅去修改问题:
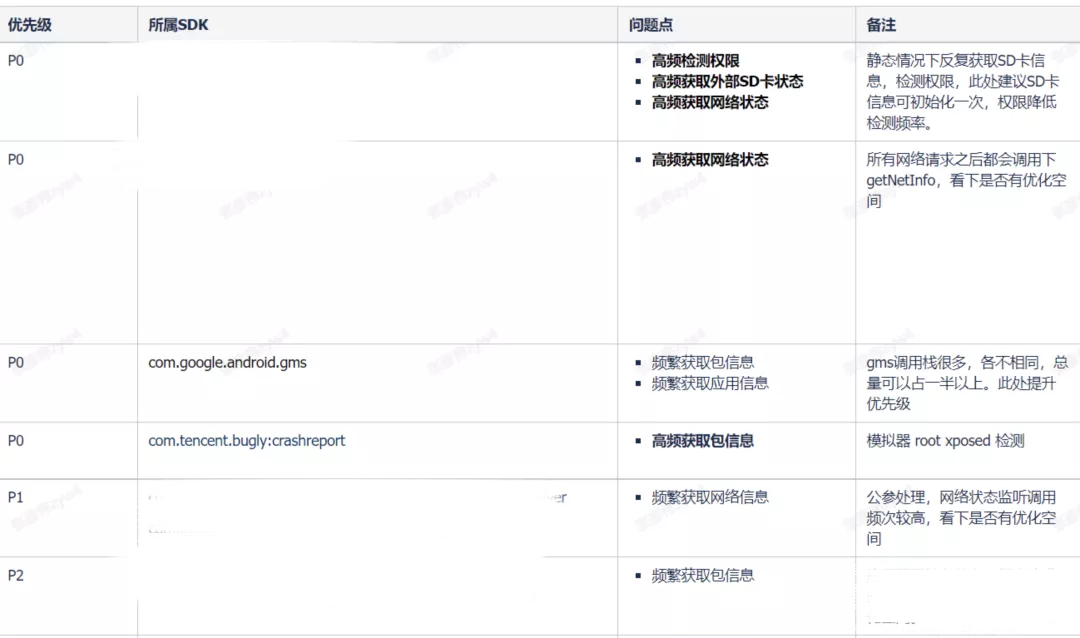
以上这些问题经过处理,整体 ANR 问题的发⽣都有⼀定程度地降低。所以,⼤部分 ANR 问题并⾮单体问题,通常降低整个应⽤的负载亦可降低整体 ANR 问题的发⽣率。
经过⼀整⽉的问题处理之后,通过复盘得出以下⼀系列思考。
1. 风险控制
在⻛险存在的时候,通常有以下⼏种做法:
本地容灾策略
异常发⽣的时候,⾃适应去熔断某些功能并上报。这个途径⽆论从效率还是从⽤户体验上来讲,都是最 好的。不过本地化意味着通常需要各种规则,各种条件去约束。所以⼤部分情况下这并不是最好的选择。
在线开关控制
在观测到异常数量上升(⼈为、报警)之后,通过在线开关关闭相应的功能。⽬前最常⽤的⽅法,在⼤ 部分场景下都能适⽤。
热修复补丁
在观测到线上异常之后,通过下发热修复补丁来避免问题的扩⼤。不过部分设备、渠道可能会失效。
发布紧急版本
迫不得已情况下使⽤的下策:紧急版本⽆论从修复效率还是从⽤户体验来讲,都是⽐较糟糕的选择。
2. 保持数据的准确 & 完整
完善的基础数据建设更有助于发现问题
笔者之前接⼿公司另⼀个业务的性能优化需求时,发现该业务线的应⽤并没有采集线上 ANR 指标,这部分在当时来看完全属于盲区,并且根本⽆法评估有多少⽤户流失与此关联。
单⼀维度的数据,只能反映部分事实,能互相佐证的多维度的数据才更可信
⽐如性能问题中:ANR 数据、慢函数数据、甚⾄于启动时⻓都能相互印证。
3. 别忽视了“蚁穴”
小问题积累到爆发再填坑,往往会耗费更多的精⼒。
之前公司内部的 AOP 处理⼀直使⽤ AspectJ ,前期遇到的问题始终在通过加各种规则去规避。在后期问题爆发的时刻,⽐开发⼀套 AOP ⽅案耗费的⼈⼒会更多。
没有外⼒约束下,⼀个稳定的系统会逐渐地熵增,从⽽陷⼊混乱状态,代码也是⼀样。
质量差的代码不仅会拖慢研发效率,⽽且会增加各种各样的稳定性隐患。平时不注意的细节会在上百万、上千万的⽤户⾯前成倍放⼤。⽐如主线程的⼀次 IO 操作:很多⼈都觉得“⼏ Kb 的数据⽽已,没什么⼤不了的”,可事实真的是这样吗?
⽆论过去、现在还是未来, ANR 问题的处理始终是⼀项具有挑战的任务。依靠过去的经验可以避免⼀些常见的问题,但是面向未来,还需要探索更多的⽅式去定位和解决问题。
1. 自研性能监控平台
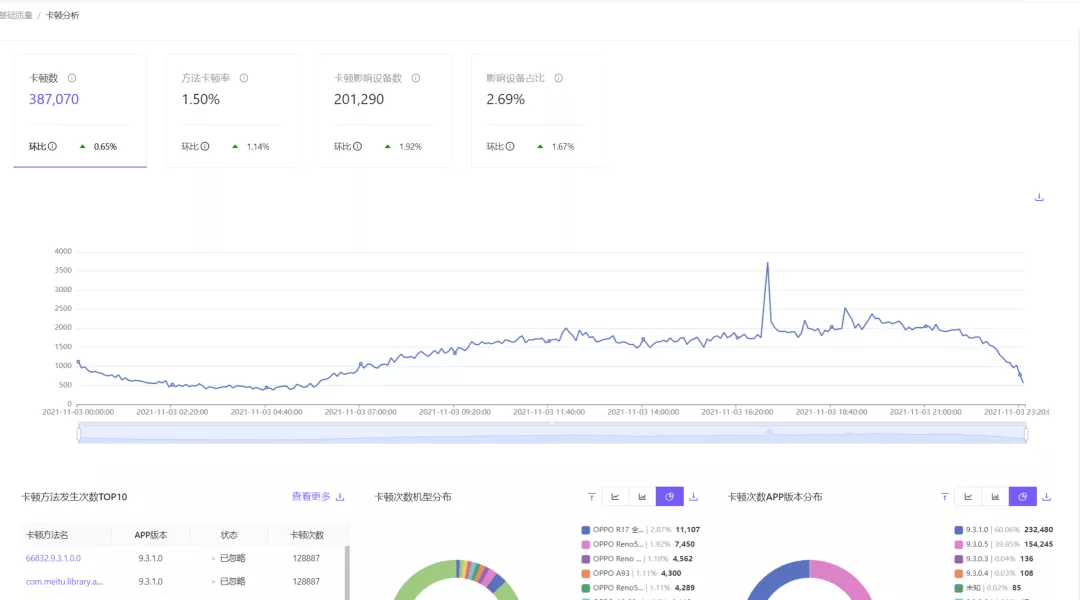
发现、预警,到 Bug 跟进,可以将整个开发和交付流程串联起来。这将是未来性能优化⼯作的⼀⼤利器。
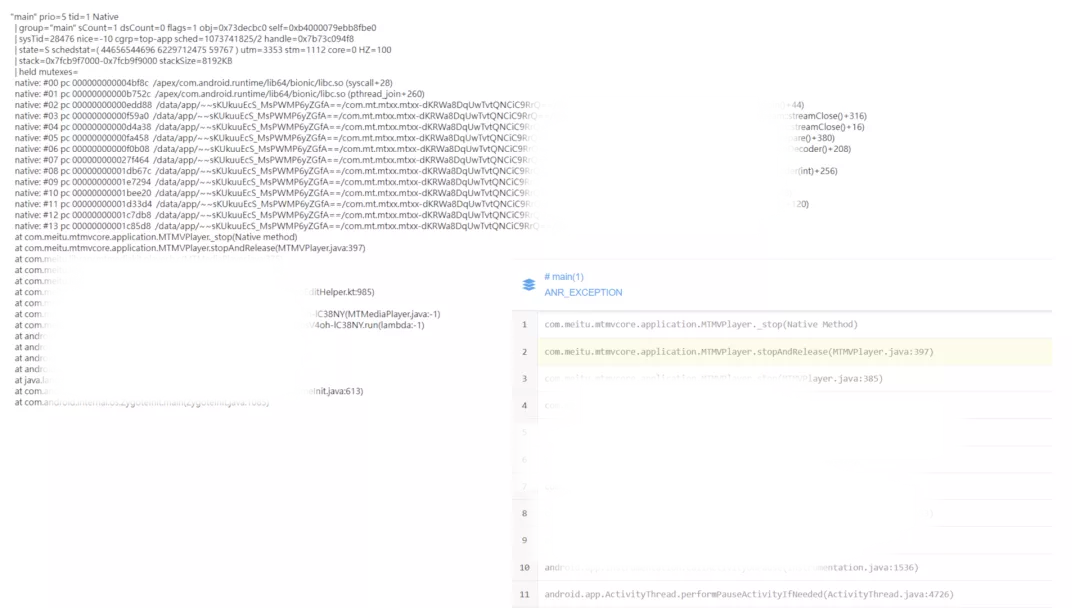
2. 抽样上报的详细 ANR⽇志
通过对⽐ Bugly 和 XCrash 上报的 ANR ⽇志,可以看出 XCrash 上报的信息更适合开发同学进⾏问题定位。在后期,我们将 XCrash 接⼊作为⼀个抽样的上报⽅案以补充 ANR 数据,为定位问题提供更有价值的信息。
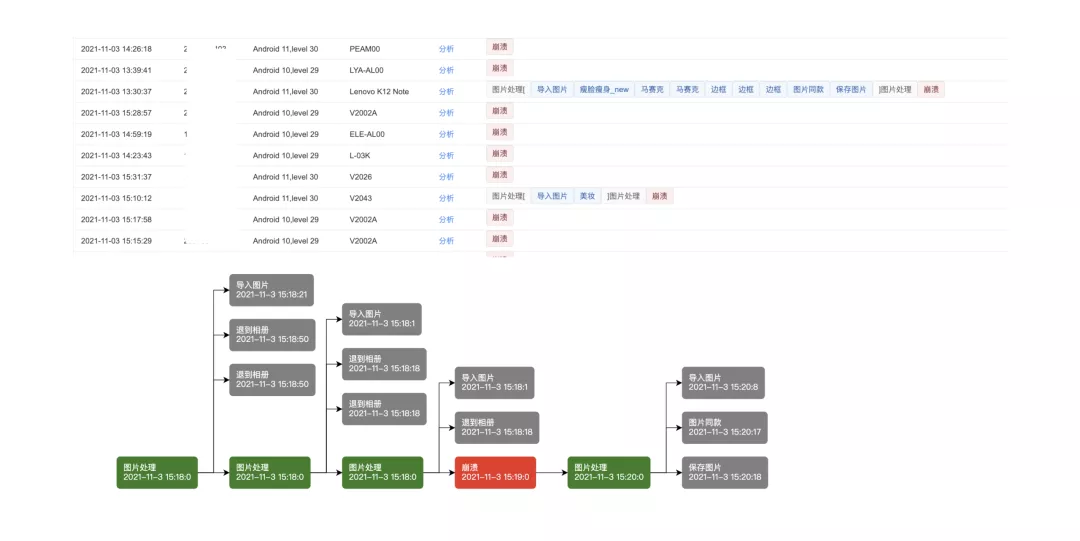
3. 业务异常关联数据分析
通过对核⼼业务的操作路径和线上的异常数据关联,可以发现⼀些平时容易被忽略的问题定位⽅法。我们关联了图⽚处理的业务与 ANR 或 Crash 的发⽣时间节点,来定位 ANR 或 Crash 是否与某个业务组件相关联。
ANR 问题并⾮单体问题。⼤部分 ANR 问题只是结果,其中的诱因千奇百怪,⽂中所述仅只是冰⼭⼀⻆。后续团队还需要不断地去解决新的问题,并持续地将已处理问题归纳、总结、规范,进而才能推⼴使⽤,更好地治理 ANR 问题。
注:
⽂中描述的 MtAjx 暂未公开,如有需要可使⽤ AspectJ 代替
⽂中⼤量的经验来源于前⼈贡献;⽔平有限难免存在纰漏 -- 如有问题欢迎随时与我交流:i@zhan gyanwei.com
作者张彦伟,美图秀秀 Android 专家。2019 年加入美图,现负责美图秀秀 Android 端优化工作。美图秀秀是 2008 年 10 月 8 日由厦门美图科技有限公司研发、推出的一款免费影像处理软件,全球累计超 10 亿用户,在影像类应用排行上长期保持领先优势。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK