

AI自助帮你换背景,超强实时人像扣图算法开源啦!
source link: https://my.oschina.net/u/4067628/blog/5288972
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

AI自助帮你换背景,超强实时人像扣图算法开源啦! - 飞桨PaddlePaddle的个人空间 - OSCHINA - 中文开源技术交流社区
谈到人像抠图想必大家都不陌生。在影视剪辑、直播娱乐、线上教学、视频会议等场景中都有人像分割的身影,它可以帮助用户实时、精准地将人物和背景精准识别出来,实现更精细化的人物美颜、背景虚化替换、弹幕穿人等,进一步提升视觉应用体验。



高精度的实时人像抠图模型一直是学术和产业界研究的重点,为此PaddleSeg团队开源了多场景覆盖的PP-HumanSeg人像系列模型:
PP-HumanSeg提供了3个高精度的人像分割模型:
有应用于服务端GPU部署的PP-HumanSegl模型,有适用于移动端的轻量PP-HumanSegm模型,还有能够在浏览器部署的超轻量模型PP-HumanSegs模型。
提供了完善的服务端、移动端、Web端部署文档,尤其是Web端提供了产业级的实时人像分割解决方案。
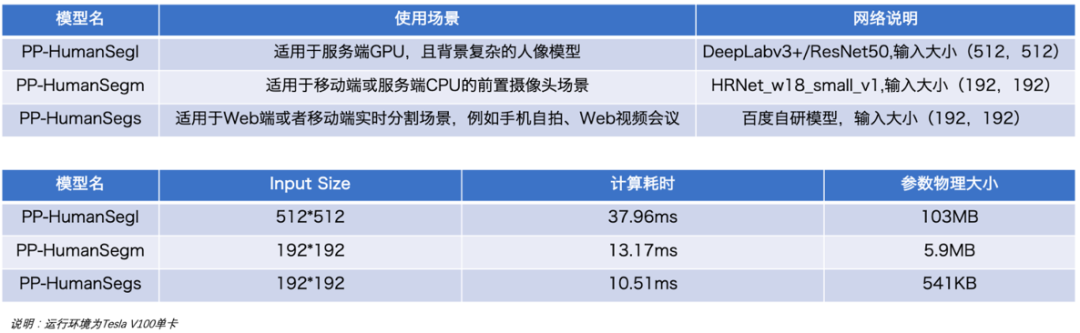
近期“百度视频会议”也上线虚拟背景功能,支持用户在视频会议时进行人像背景切换。这个功能正是基于PP-HumanSeg提供的超轻量的PP-HumanSegs来实现。通过 Padddle.js实现了在Web端部署,直接利用浏览器的算力进行实时人像抠图,效果受到一致好评!
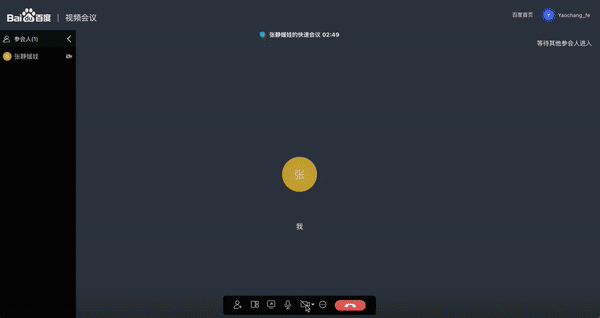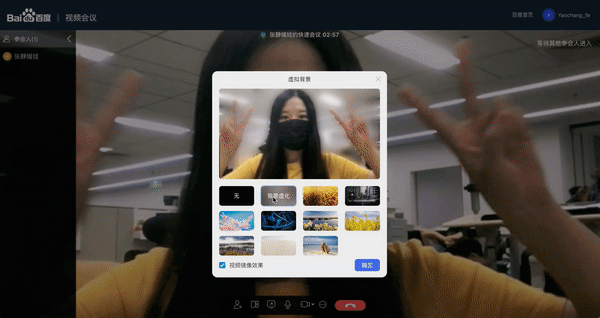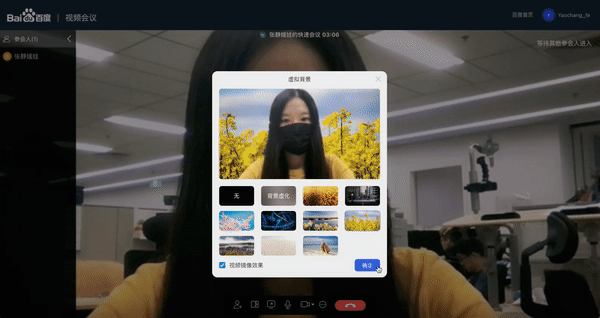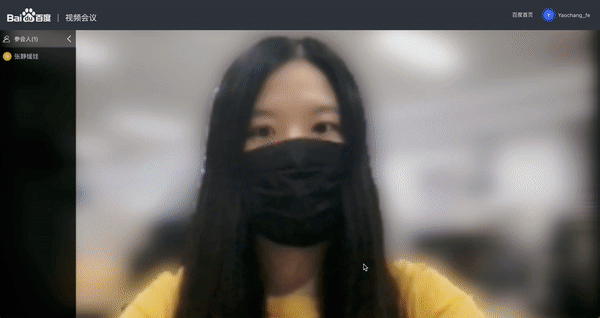
模型性能如此之好,是不是迫不及待地想知道如何实现的?
大规模数据合成和数据增强
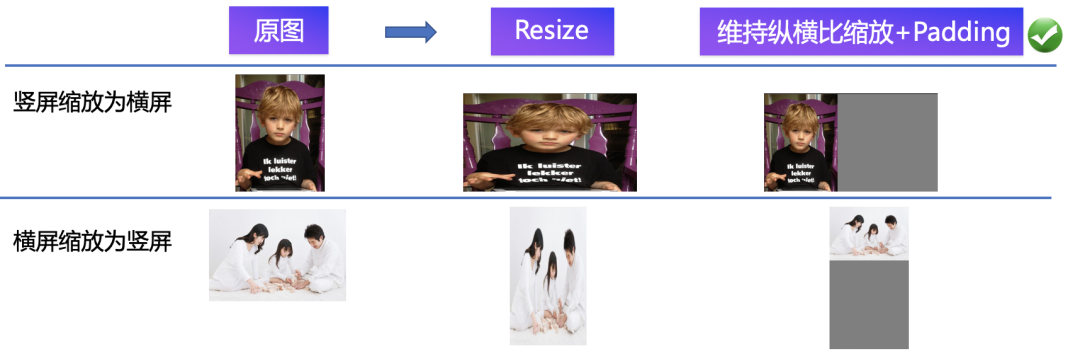
在训练集里有各种比例的图片,有横屏的,有竖屏的。如果直接使用缩放变形等数据增强方式,会直接导致形变失真,反而不会提升精度。针对此类问题,采用维持图像纵横比缩放、Padding补齐等方式缩放图像达到原图比例。通过这些方式处理后图像不会失真,训练精度也得到了提升。
针对人像标注样本少的问题,使用标注信息和背景图合成的方式进行数据生成,数据量的扩充提升了模型的精度。

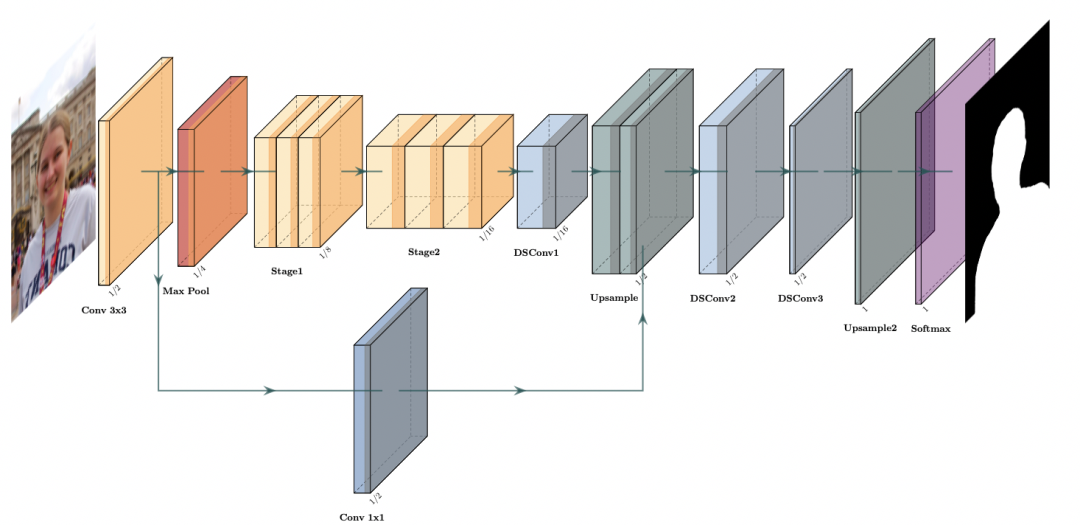
轻量级网络设计方式
对于移动端和网页端的人像分割,一个高效的轻量级网络必不可少,在这里为大家总结了一些轻量化关键设计方法。
关键一:深度可分离卷积
深度可分离卷积是一种卷积分解方式,将普通卷积分解为Depthwise Convolution和Pointwise Convolution,主要目的是减少计算量和参数量,此方式已被广泛应用在轻量级卷积网络中。
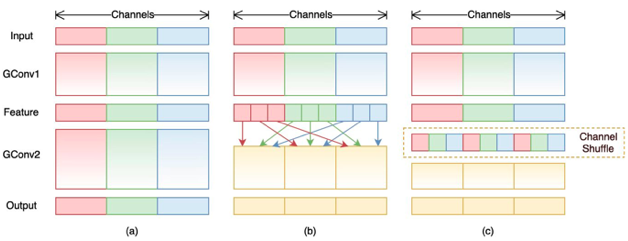
关键二:Channel Shuffle(通道洗牌)
在深度可分离卷积中用到的Depthwise Convolution会将所有的channel分组,每个channel分为一组,这就导致组与组之间无信息交换。Channel Shuffle通过对group convolution之后的特征图进行“重组”,可以保证接下了采用的group convolution输入来自不同的组,因此信息可以在不同组之间流转。
关键三:Skip-connection(跳跃连接)
对于分割任务,空间域信息非常重要。主流的分割网络均采用encoder-decoder结构。网络的encoder部分通过下采样层把特征图分辨率降得非常小,这一点不利于精确的分割mask生成,通过skip-connection跨层连接编码器和解码器,更利于生成精细的mask。Skip-connection直接复用encoder的特征,几乎不增加计算量,性价比非常之高!
关键四:上采样方法
Decoder的主要目的是将低分辨率信息的特征恢复到高分辨率。为了实现这个目的就需要上采样。常用的上采样方式有四类:转置卷积、反池化、插值、亚像素卷积。
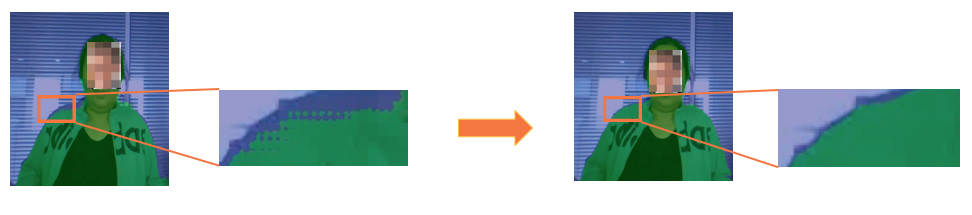
当使用转置卷积进行上采样的时候,容易出现棋盘效应(左图肩膀处)。开发团队为平衡计算量、显存占用和效果,最终采用深度可分离卷积+双线性插值,在保持高效计算的同时解决了棋盘效应问题。
综合考虑上述四个关键,开发团队设计了Web端超轻量级模型PP-HumanSegs。
优化损失函数
解决类别不均衡
人像在整张图片中所占的比例往往较小,存在前景背景类别占比不均衡的问题。常用的Cross Entropy Loss会公平处理正负样本,当出现正样本占比较小时,就会被更多的负样本淹没。通过改变损失函数,使用Lovasz loss来降低正负样本不均衡的问题。
光流后处理优化
视频分割存在一个问题:视频帧间不连贯,边缘部分闪烁严重,为此研发团队利用时序信息结合光流法,对分割结果进行优化。采用光流解决方法,将光流预测结果与分割结果进行融合,这样就可以参考上一帧的运动信息,使得前后帧变换相对更加稳定,减少边缘的闪烁。

心动不如行动,大家可以直接前往Github地址获得完整开源项目代码,记得Star收藏支持一下哦:
https://github.com/PaddlePaddle/PaddleSeg
也可以扫码加入微信交流群,与官方开发团队直接交流:

http://discuss.paddlepaddle.org.cn/
欢迎加入官方QQ群获取最新活动资讯:793866180。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·飞桨开源框架项目地址·
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle

????长按上方二维码立即star!????
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。

本文封面照片来自Ales Nesetril on Unsplash
本文同步分享在 博客“飞桨PaddlePaddle”(CSDN)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK