

两万字博文教你python爬虫requests库,看完还不会我把我女朋友都给你【❤️熬夜整理&...
source link: https://blog.csdn.net/qq_44907926/article/details/118667559
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

两万字博文教你python爬虫requests库,看完还不会我把我女朋友都给你【❤️熬夜整理&建议收藏❤️】
👻上一篇博文一篇万字博文带你入坑爬虫这条不归路(你还在犹豫什么&抓紧上车) 【❤️熬夜整理&建议收藏❤️】被众多爬虫爱好者/想要学习爬虫的小伙伴们阅读之后,很多小伙伴私信我说——大佬搞爬虫都是用的socket套接字嘛?👻
😬(苦笑)“那肯定不是啊!python为我们封装了那么多伟大而又简单实用的爬虫库,”不过我想说的是,“ 学啥技术都是从底层抓起,万丈高楼平地起,它也是基于地基稳! 所以在入坑文中简单地介绍使用了下底层爬虫库——socket!”😬
😜而本文,本博主就带领小伙伴们认真地学习一下Python中一大广为使用的爬虫库——Requests——专为人类而构建;有史以来下载次数最多的Python软件包之一!😜

重点来啦!重点来啦!! 💗💗💗
相信有不少小伙伴已经通过我的上篇博文入坑爬虫,而本篇文讲解的Requests库也是学习爬虫之路的一大最为重要的知识点,在我们日后的爬虫开发中使用的最多的也是它哦!

之前的urllib(后面会更新文章讲解哦——敬请期待!)做为Python的标准库,因为历史原因,使用的方式可以说是非常的麻烦而复杂的,而且官方文档也十分的简陋,常常需要去查看源码。与之相反的是,Requests的使用方式非常的简单、直观、人性化,让程序员的精力完全从库的使用中解放出来。
Requests的官方文档同样也非常的完善详尽,而且少见的有中文官方文档&&英文官方文档。

2.发起请求
Requests的请求不再像urllib一样需要去构造各种Request、opener和handler,直接使用Requests构造的方法,并在其中传入需要的参数即可。
源码:
def request(method, url,params=None, data=None, headers=None, cookies=None,
timeout=None, allow_redirects=True, proxies=None,verify=None, json=None):
参数详解:
(1)请求方法method:
每一个请求方法都有一个对应的API,比如GET请求就可以使用get()方法:
而POST请求就可以使用post()方法,并且将需要提交的数据传递给data参数即可:
而其他的请求类型,都有各自对应的方法:
知识点补给站——POST请求方法的小知识点:
应用场景:登录注册
需要传输大文本内容的时候使用(post请求对长度没有要求)。

(2)统一资源定位符url
URL(Universal Resource Locator),即统一资源定位符。
(3)传递url参数params
传递URL参数也不用再像urllib中那样需要去拼接URL,而是简单的,构造一个字典,并在请求时将其传递给params参数:
import requests
params = {'key': 'value1', 'key2': 'value2'}
resp = requests.get("http://httpbin.org/get", params=params)
print(resp.url)

小知识点:
有时候我们会遇到相同的url参数名,但有不同的值,而python的字典又不支持键的重名,那么我们可以把键的值用列表表示:
import requests
params = {'key': 'value1', 'key2': ['value2', 'value3']}
resp = requests.get("http://httpbin.org/get", params=params)
print(resp.url)

知识点补给站:
本文大多使用的URL站点是httpbin.org,它可以提供HTPP请求测试哦!
(4)传递form表单数据——data
将放进data的数据转换为form表单数据,同时不能传json数据,json数据为null。(注意:json和data二者只能同时存在其一)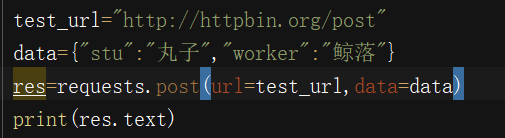

(5)传递json数据——json
将json对应的数据放进json参数里。


(6)自定义headers
是不是很熟悉,这就是反爬第一阶段常用套路!
如果想自定义请求的Headers,同样的将字典数据传递给headers参数。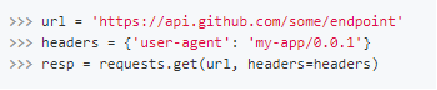
(7)自定义cookies

①获取cookies:
第一种方法:
import requests
from fake_useragent import UserAgent
r = requests.get('https://www.baidu.com',headers = {'User-Agent': UserAgent().random})
print(r.cookies)
print('*'*25)
print(r.cookies.items())
print('*'*25)
for key,value in r.cookies.items():
print(key + "=" + value)

此处我们首先调用cookies属性即可成功得到cookies,可以发现他是个RequestsCookieJar类型。然后用items()方法将其转化为元组组成的列表,遍历输出每一个Cookie的名称和值,实现Cookie的遍历解析。
第二种方法:
使用requests.utils.dict_from_cookiejar:把cookiejar对象转化为字典。
import requests
from fake_useragent import UserAgent
url = 'http://www.baidu.com'
response = requests.get(url=url, headers ={'user-agent': UserAgent().random})
cookie = requests.utils.dict_from_cookiejar(response.cookies)
print(cookie)
"""
输出:
{'BAIDUID_BFESS': '52EB4182E0877DFD9DBA8E0793772027:FG=1', 'H_PS_PSSID': '33802_34222_31254_33848_34112_34107_26350_34093', 'BDSVRTM': '0', 'BD_HOME': '1'}
"""

②使用Cookie维持登录状态的两种方法:
第一种方法: 请求头中加入网页复制的cookie来维持登录状态!
实战之以QQ空间为例来说明:
(如何在网页中获取Cookie:首先登录QQ空间,将Headers中的Cookie内容复制即可!)
import requests
headers = {
'cookie': '此处换为你自己的Cookie即可!',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
r = requests.get('https://user.qzone.qq.com/这里写上要登录的QQ号/infocenter', headers=headers)
print(r.text)
我们发现,结果中包含了登录后的结果,说明我们登录成功!
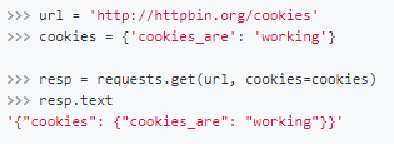
第二种方法: 通过cookies参数来设置,直接将cookies构造字典传入即可!
(8)设置代理proxies

-
什么是代理?
代理IP是一个ip ,指的是一个代理服务器。 -
要晓得正向代理和反向代理是啥?
知不知道服务器的地址做为判断标准:知道就是正向代理,不知道就是反向代理。

3. 代理ip的分类(常见有两大分类依据:匿名度&&协议)
①匿名度:
透明代理 :目标服务器可以通过代理找到你的ip;
匿名代理 :两者之间;
高匿代理 :在爬虫中经常使用,目标服务器无法获取你的ip。
②协议:(根据网站使用的协议不同,需要使用响应的协议代理服务)
http代理:目标的url为http协议;
https代理:目标url为https协议;
socks代理 :只是简单的传递数据包,不关心是何种协议,比http和HTTPS代理消耗小, 可以转发http和https的请求。
-
为何使用代理?
(1)让服务器以为不是同一个客户端在请求;
(2)防止我们的真实地址被泄露,防止被追究。 -
用法:
当我们需要使用代理时,同样构造代理字典,传递给proxies参数。

(9)重定向allow_redirects
在网络请求中,我们常常会遇到状态码是3开头的重定向问题,在Requests中是默认开启允许重定向的,即遇到重定向时,会自动继续访问。
(10)禁止证书验证vertify

有时候我们使用了抓包工具,这个时候由于抓包工具提供的证书并不是由受信任的数字证书颁发机构颁发的(比如,之前12306的整数就没有被官方CA机构信任,就会出现证书验证错误的结果!),所以证书的验证会失败,这时我们就需要关闭证书验证。
 解决方法:在请求的时候把verify参数设置为False就可以关闭证书验证了。
解决方法:在请求的时候把verify参数设置为False就可以关闭证书验证了。 小拓展:
小拓展: 但是关闭验证后,会有一个比较烦人的warning,它建议我们给它指定证书。我们可以通过设置忽略警告的方式来屏蔽它:
但是关闭验证后,会有一个比较烦人的warning,它建议我们给它指定证书。我们可以通过设置忽略警告的方式来屏蔽它:

(11)设置超时timeout
为了防止服务器不能及时响应,而设置一个超时时间,即超过了这个时间还没有得到响应,那就报错!
设置访问超时——设置timeout参数即可。(这个时间的计算是发出请求到服务器返回响应的时间)
实际上:请求分为两个阶段,即连接(connect)和读取(read)。下面设置的timeout将用作连接和读取这二者的timeout总合。如果分别指定,就可以传入一个元组:timeout=(5,11,30)。
- 使用retrying模块提供的retry方法
- 通过装饰器的方式,让被装饰的函数反复执行
- retry中可以传入参数 stop_max_attempt_number,让函数报错后继续重新执行,达到最大执行次数的上限,如果每次都报错,整个函数报错,如果中间有一个成功,程序继续往后执行
①代码讲解:
import requests
from retrying import retry
headers = {"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/532.2 (KHTML, like Gecko) Chrome/4.0.222.3 "}
@retry(stop_max_attempt_number=3) # stop_max_attempt_number=3最大执行3次,还不成功就报错
def _parse_url(url): # 前面加_代表此函数,其他地方不可调用
print("*"*100)
response = requests.get(url, headers=headers, timeout=3) # timeout=3超时参数,3s内
assert response.status_code == 200 # assert断言,此处断言状态码是200,不是则报错
return response.content.decode()
def parse_url(url):
try:
html_str = _parse_url(url)
except Exception as e:
print(e)
html_str = None
return html_str
if __name__ == '__main__':
# url = "www.baidu.com" # 这样是会报错的!
url = "http://www.baidu.com"
print(parse_url(url))
②实现效果一:无法爬取到的情况:url = “www.baidu.com”!
②实现效果二:正确爬取到的情况:url = “http://www.baidu.com”!

(12)文件上传
假如有的网站需要上传文件,我们也可以使用requests实现!
当前脚本的同一目录下有个名为1.jpg的文件:
import requests
files = {'file': open('1.jpg','rb')}
r = requests.post("http://httpbin.org/post", files=files)
print(r.text)


这个网站会返回响应,里面包含files这个字段,而form字段是空的,这证明文件上传部分会单独有个files字段来标识。
(13)Prepared Request
我们知道在urllib中可以将请求表示为数据结构,其中各个参数都可以通过一个Request对象来表示。这在requests中同样可以做到,这个数据结构叫做Prepared Request。如下:
from requests import Request,Session
url = 'http://httpbin.org/post'
data = {
'name':'peter'
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.29 Safari/525.13'
}
s = Session()
req = Request('POST', url, data=data, headers=headers)
prepped = s.prepare_request(req)
r = s.send(prepped)
print(r.text)
先用url,data,headers参数构造了一个Request对象,这时需要再调用Session的prepare_request()方法将其转换为一个Prepared Request对象,然后调用send()方法发送即可!

使用较少,但是这样使用的好处是:有了Request这个对象,就可以将请求当作独立的对象来看待,这样在进行队列调度时会非常方便!
import requests
# res=requests.get("http://httpbin.org/get") #功能:发起完整的网络请求
'''
源码:
def request(method, url,params=None, data=None, headers=None, cookies=None,
timeout=None, allow_redirects=True, proxies=None,verify=None, json=None):
'''
#1.method
# res=requests.post("http://httpbin.org")
# res=requests.delete("http://httpbin.org")
# url 字符串 统一资源定位符
# params 将放进params里的字典数据变为url的请求参数(如果是中文会自动编码)
# test_url="http://httpbin.org/get"
# params={"name":"allen","name2":"哈哈"}
# res=requests.get(url=test_url,params=params)
# print(res.text)
# data 将放进data的数据转换为form表单数据,同时不能传json数据,json数据为null
# test_url="http://httpbin.org/post" #post提交数据
# data={"stu":"丸子","worker":"鲸落"}
# res=requests.post(url=test_url,data=data)
# print(res.text)
# json 将json对应的数据放进json数据里
# test_url="http://httpbin.org/post" #post提交数据
# json={"name":"selffly"} #'{"name":"selffly"}' json串形式也可以传,字典也可以传
# res=requests.post(url=test_url,json=json)
# print(res.text)
# 添加头部信息headers 添加cookies 添加timeout 设置代理proxies=None verify=False安全验证(为False是忽略证书)
# test_url="http://httpbin.org/get"
# headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"}
# cookies={"sessionid":"dfsdaaagdgagdf"}
# proxies={'http':"127.0.0.1:8888"} #这个代理胡写的,不可用
# res=requests.get(url=test_url,headers=headers,cookies=cookies,timeout=10,proxies=proxies)
# print(res.text)
# 测试重定向allow_redirects 如果为True就可以进行重定向;反之不可以
# res_bd=requests.get("http://www.baidu.com",allow_redirects=False)
# print(res_bd.text)

3.接收响应
通过Requests发起请求获取到的,是一个requests.models.Response对象。通过这个对象我们可以很方便的获取响应的内容。
(1)响应内容
requests通过text属性,可以获得字符串格式的响应内容。

(2)字符编码
Requests会自动的根据响应的报头来猜测网页的编码是什么,然后根据猜测的编码来解码网页内容,基本上大部分的网页都能够正确的被解码。而如果发现text解码不正确的时候,就需要我们自己手动的去指定解码的编码格式。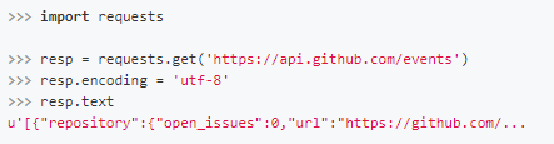
(3)二进制数据
而如果你需要获得原始的二进制数据,那么使用content属性即可。

(4)json数据
如果我们访问之后获得的数据是JSON格式的,那么我们可以使用json()方法,直接获取转换成字典格式的数据。
(5)状态码
通过status_code属性获取响应的状态码

应用:
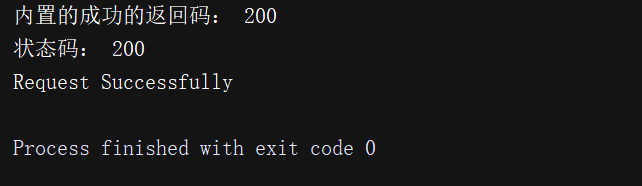
状态码常用来判断请求是否成功,而requests还提供了一个内置的状态码查询对象requests.codes,如下。这里通过比较返回码和内置的成功的返回码,来保证请求得到了正常响应,输出成功请求的消息,否则程序终止,这里我们用requests.codes.ok得到的是成功的状态码200。其实我们直接和200判断就好了!不过像下面这样写B格高!
import requests
r = requests.get('https://www.baidu.com')
print('内置的成功的返回码:',requests.codes.ok)
print('状态码:',r.status_code)
exit() if not r.status_code == requests.codes.ok else print('Request Successfully')
(6)响应报头
通过headers属性获取响应的报头
(7)服务器返回的cookies
通过cookies属性获取服务器返回的cookies
(8)查看响应的url
还可以使用url属性查看访问的url。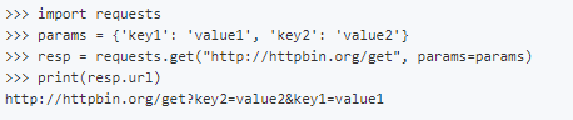
import requests
res=requests.get("http://www.baidu.com") #发起完整的网络请求
print(res.content) #字节码格式 图片,视频数据等
res.encoding="utf-8" #乱码需要解码,修改编码方式
print(res.text) #字符串格式 非字节码
print(res.status_code) #状态码
print(res.url) #获取响应的url
print(res.cookies) #获取cookies
res=requests.get("http://httpbin.org/get")
print(res.json()["headers"]["User-Agent"]) #使用json()方法将数据变为字典格式
print(res.headers) #获取响应报头
# 拓展:还可以使用方法获取请求的一些数据:
print("请求头:",res.request.headers)
print("请求的url",res.request.url)
print("请求的cookie",res.request._cookie) # 返回cookiejar类型

4.使用requests库进行实战:
(1)基操 之 实战项目一:进行百度贴吧指定搜索内容获取到的html源码头5页的爬取!
①上代码:
import os
import requests
'''
为了构造正确的url!!!
进入百度贴吧进行测试,任意搜索一个信息,通过不同页更换,观察url找寻规律:
https://tieba.baidu.com/f?kw=美食&ie=utf-8&pn=0
https://tieba.baidu.com/f?kw=美食&ie=utf-8&pn=50
https://tieba.baidu.com/f?kw=美食&ie=utf-8&pn=100
https://tieba.baidu.com/f?kw=美食&ie=utf-8&pn=150
'''
class TiebaSpider:
def __init__(self,tieba_name):
self.tieba_name = tieba_name
self.url_temp = "https://tieba.baidu.com/f?kw="+tieba_name+"&ie=utf-8&pn={}"
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"}
# 构造url列表
def get_url_list(self):
return [self.url_temp.format(i*50) for i in range(5)]
# 发送请求,获取响应
def parse_url(self,url):
response = requests.get(url,headers=self.headers)
return response.content.decode()
# 保存
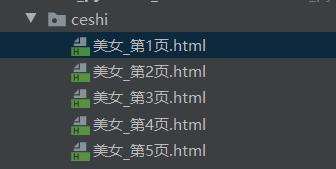
def save_html_str(self, html_str, page_num):
file_path = "{}_第{}页.html".format(self.tieba_name, page_num)
dir = 'ceshi'
if not os.path.exists(dir):
os.mkdir(dir)
file_path = dir + '/' + file_path
with open(file_path, "w", encoding='utf-8') as f:
f.write(html_str)
print("保存成功!")
# 实现主要逻辑
def run(self):
# 构造url列表
url_list = self.get_url_list()
# 发送请求,获取响应
for url in url_list:
html_str = self.parse_url(url)
# 保存
page_num = url_list.index(url)+1
self.save_html_str(html_str, page_num)
if __name__ == '__main__':
name_date = input("请输入你想知道的内容:")
tieba_spider = TiebaSpider(name_date)
tieba_spider.run()
②实现效果:


(2)升级版操作 之 实战项目二:使用session实现人人网登录状态维持
1.session:
实例化对象
session.get(url) #cookie保存在session中
session.get(url) #带上保存在session中cookie
2.cookie方法在headers中
3.cookie传递给cookies参数:
cookie = {"cookie 的name的值":"cookie 的value对应的值"}
①上代码:
import requests
# 1.实例化session
session = requests.Session()
# 2. 使用session发送post请求,对方服务器会把cookie设置在session中
headers = {"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/532.2 (KHTML, like Gecko) Chrome/4.0.222.3 "}
post_url = "http://www.renren.com/PLogin.do"
post_data = {"email":"自己的账号","password":"自己的密码"}
session.post(post_url,data=post_data,headers=headers)
# 3.请求个人主页,会带上之前的cookie,能够请求成功
profile_url = "http://www.renren.com/自己进自己主页会有的/profile"
response = session.get(profile_url,headers=headers)
with open("renren.html", "w", encoding="utf-8") as f:
f.write(response.content.decode())
②实现效果:
5.In The End!

本博主会持续更新爬虫基础分栏及爬虫实战分栏,认真仔细看完本文的小伙伴们,可以点赞收藏并评论出你们的读后感。并可关注本博主,在今后的日子里阅读更多爬虫文!
如有错误或者言语不恰当的地方可在评论区指出,谢谢!
如转载此文请联系我说明用以意并标注出处及本博主名,谢谢!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK