

统计词画番外篇(一):谁共我,醉明月?
source link: https://cosx.org/2015/03/song-poem-1/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

将军百战身名裂。向河梁、回头万里,故人长绝。易水萧萧西风冷,满座衣冠似雪。正壮士、悲歌未彻。啼鸟还知如许恨,料不啼清泪长啼血。谁共我,醉明月?
这是笔者最喜欢的词人辛弃疾的《贺新郎 · 别茂嘉十二弟》之下阙,最后一句 “谁共我,醉明月” 写尽了挚友远去的孤独和寂寞。毫无疑问,词人在生活中有自己的基友闺蜜,那么问题来了,词人之间有没有风格相近的知音来共醉明月?笔者识字不多,读词少,所幸学习统计专业,因此只能简单地用统计方法来浅显地探讨一下这个问题了。
本文的题目是统计词画,显然有统计,有词,有可视之图画。好的,铺垫完毕,正文开始。
每一位作者都有自己独特的风格,比如句子段落的长短、用词用语的习惯性等。在文学界,利用统计方法研究作者的文风,并对作品、作者进行分类、判别早就有了非常成功的案例,比如李贤平教授 [1] 在考证《红楼梦》前八十回和后四十回的作者归属问题时,统计了 120 章回中 47 个常用虚词的频率差异,并以此为据分析得到了很多有意思的结论,解决了几百年来悬而未决的作者疑案,令红学界学者们非常叹服。
词的内容是文本数据,我们的目的是从数量分析的角度出发,了解词人的风格、描写的意向等信息。但它属于非结构化数据,如何对其进行分析是一个难点,因此必须想办法从中提取指标使其容易度量。
词大都描写情感,短小精悍且多意象。存在着常用词的堆砌情况,比如 “千古”、“风流”、“寂寞”、“断肠”、“无情” 等;而这些高频词往往是体现词人风格、意象情感的重要指标,这类似于李贤平教授分析红楼梦时用的虚词。但是我们事先并不知道所有的高频意象词,一个自然的想法就是利用分词工具进行划分,然后找出高频意象词;但是词属于古文,目前的所有的分词字典中并不一定包含这些特点的关键词。因此为了进行数据结构化编码,必须另辟蹊径。邱怡轩 [2] 避开了传统中文分词的困难,用近乎“大巧若拙” 的方法统计出了词中的高频词汇,笔者形象地称之为 “组合沉淀” 方法。具体的方案是:
组合阶段:将词的每一句都打散成需要的组合方式,比如 “千古风流人物” 这句话,可能的二字组合是“千古”、“古风”、“风流”、“流人”、“人物”,三字组合是“千古风”、“古风流”、“风流人”、“流人物”,词的字数越多,可能的组合就越多。
沉淀阶段:将二字词组、三字词组出现的频率统计出来,可以预计无意义的词组会因为频数很小,必然难等大雅之堂而沉淀下去。而高频的词组则必然都是有意义的,会脱颖而出。
本节采用的数据共包含我国历史上 16 位词人现存的 3395 篇词,词人是:李煜、 苏轼、辛弃疾、黄庭坚、欧阳修、秦观、姜夔、李清照、柳永、晏几道、晏殊、周邦 彦、马钰、丘处机、谭处端、王处一。其中最后 4 位是我国宋末元初的道家 (全真教) 名人,也是金庸的小说《射雕英雄传》中 “全真七子” 中的四位;在历史上,“全真七子”留下了很多词作,也是非常著名的词人。
作者词风研究
首先根据高频词分析 16 位作者的作词风格:先统计出每位作者的前 20 高频词, 然后将这些高频词 (去重复后共 222 个) 作为指标,计算出每位作者的词中出现这 222 个双字词的频数矩阵,该矩阵共 16 列 222 行,输出部分数据如下:
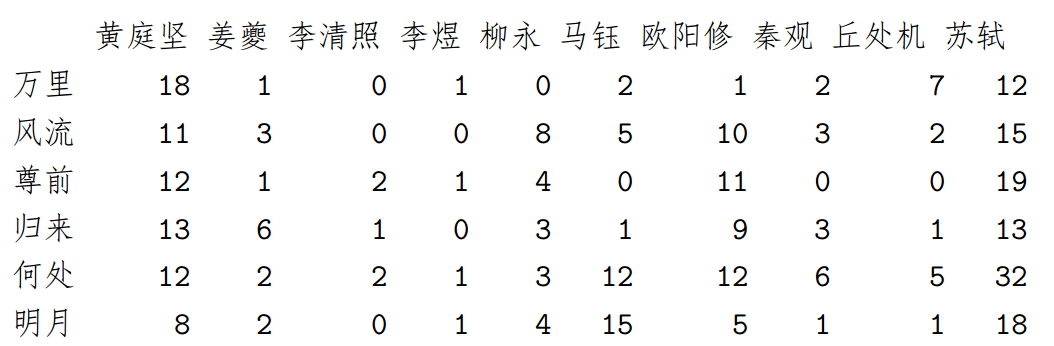
据此矩阵计算 16 位作者的词风相关矩阵 (采用皮尔逊相关系数),之后对结果进行系统聚类 (采用 complete 距离) 将作者聚为 4 类,再用 corrplot 包 [3] 进行矩阵重排序然后可视化得到图 1。
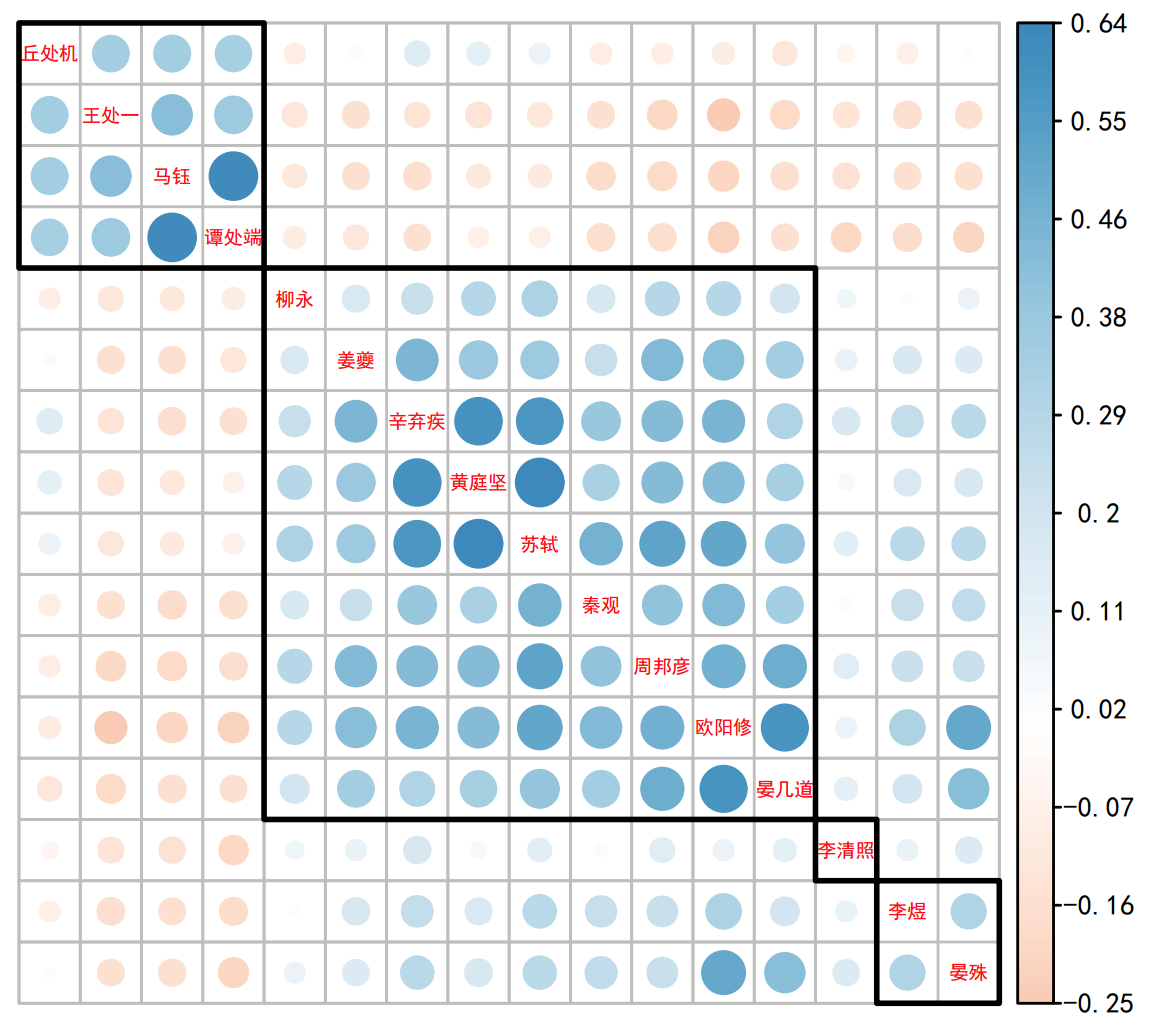
图 1: 词风相关矩阵图,主对角线上是对应作者的名字,两作者对应行列交叉的圆圈表示他们的词风相关系数。圆圈大小、颜色深浅和关系系数的绝对值正相关,蓝色、红色分别表示系 数的正负,如图右侧颜色图例所示。图中作者顺序依照聚类结果排序,黑框表示系统聚类得到的 4 类。 观察图 1 可以一目了然地看到词人之间风格的相似程度。词人被划分为 4 类,如图中方框所示。可以看出,全真四子的词风非常接近,和其他词人风格差别较大,毫无疑问,他们是可以共醉明月之人;而全真四子中,只有丘处机和苏轼、辛弃疾、黄庭坚等人的词呈正相关,而其他三子和另外 12 位作者相关系数都为负数。金庸武侠小说中写到,丘处机侠骨热肠,多行走江湖,而他的师兄弟们则执着于道;从这里词风分析来看,亦有相似的结果。柳永、姜夔、辛弃疾、黄庭坚、苏轼、秦观、周邦彦、欧阳修、晏几道属于第二类,该类中柳永和其他作者的关系系数较小,其他 8 位之间的相关系数都较大,尤其是辛弃疾、黄庭坚、苏轼之间,苏辛都是豪放派词人的代表,而黄庭坚是苏轼的第一弟子。第三类只包含了李清照一人,她和其他 15 位词人的关系都很弱,从图中看她是最为独特的词人。实际上,李清照词的与众不同是广为人知的。她的名作《词论》中,就对很多词人进行了评价:
李煜语虽甚奇,所谓 “亡国之音哀以思” 也。柳永词虽协音律,而词语尘下。张子野、宋子京兄弟、沈唐、元绛、晁次之辈,虽时时有妙语,而破碎何足名家!晏殊、欧阳修、苏轼学际天人,然皆句读不茸之诗尔,且常不协音律。王安石、曾巩,文章似西汉,若作一小歌词,则人必绝倒,不可读也。词别是一家,至晏几道、贺铸、秦观、黄庭坚出,始能知之。然晏苦无铺叙;贺苦少重典;秦即专主情致,而少故实;黄即尚故实而多疵病。
看来啊,易安居士孤家寡人矣,欲将心事付瑶琴,知音少,弦断有谁听?她只能月下独酌了。
最后一类是李煜和晏殊,他们之间的词风关系较强。此外,李煜和其他作者的关系也很弱。
晏殊和欧阳修、晏几道 (晏殊之子) 的词风相关系数也较大。晏殊是欧阳修仕途中的伯乐,他们的词风也较为接近,后人曾一并评价他们 “晏元献,欧阳文忠公,风流蕴藉,一时莫及,而温润秀洁,亦无其比”。这和我们从图中得到的信息是完全一致的。此外,除了图 1 ,corrplot 包还支持以其他方式来展示相关矩阵,读者不妨一试。
图 1 中最重要的信息就是作者两两之间的相关系数,选择不同的相关系数作者两两的相关强度会有所不同;词人的聚类信息可以随着聚类方法的不同而变动,这些信息是变动的,这对那些所属类群不太明显的作者尤其敏感。因此,对聚类结果的分析应该慎重而不能绝对化。比如,图 1 中,我们设置了聚类个数为 4。如果系统聚类用 ward 距离,设置为 6 类的话,得到的是图 2 这样的,在该图中,可以看到更为细致的类。大家可以自行观摩解释。
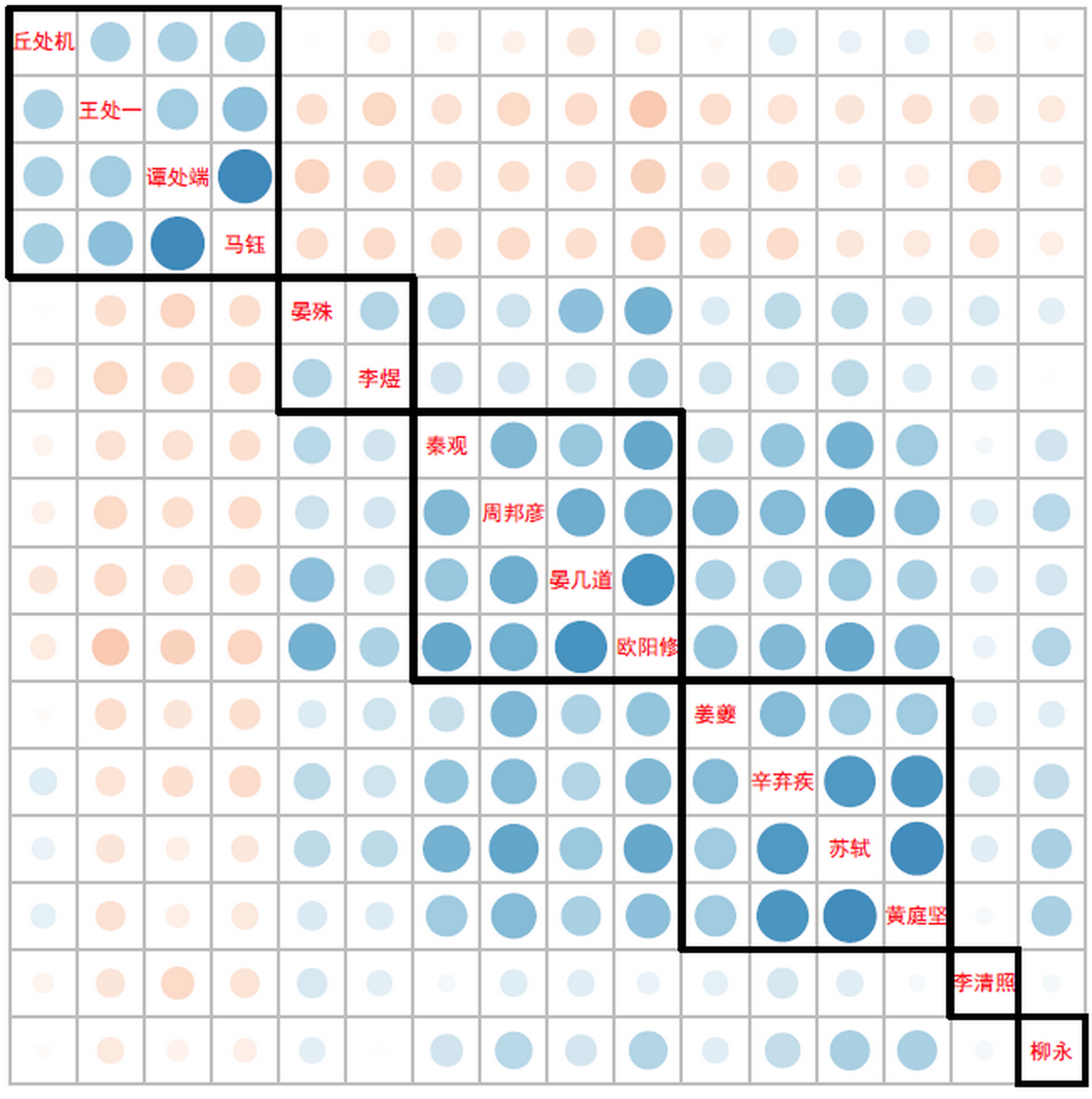
图 2: 词风相关矩阵图,黑框表示系统聚类得到的 6 类。 从以上的可视分析结果可以看出,结合统计分析和可视化可以在浩如烟海的卷帙中迅速挖掘并展示出很多有用的信息;这在信息爆炸的时代无疑是很有应用价值的。
高频词关系研究
很多高频词都是词作中常用的意象,分析它们之间的联系可以得到词的特点以及情感、意象的联系。接下来,我们分析这 16 位作者中前 100 高频词的相互联系。首先定义两高频词 i 和 j 的关系系数 R:同时出现高频词 i 和 j 的词的数目和出现高频词 i 和 j 任意一个的词的数目的比值。
显然当高频词 i 和 j 总是同时出现时,关系系数为 1;当它们从来不同时出现在同一首词时,关系系数为 0。据此可以得到一个 100*100 的矩阵。利用 igraph 包 [4] 画出这 100 个词的关系网络图 (图 3)。为抓住重点、简化网络,我们忽略了小于 0.05 的关系,并将关系系数划分为 4 个等级,然后据此分配边的粗细和颜色,节点的布局算法采用的是 FR 算法。
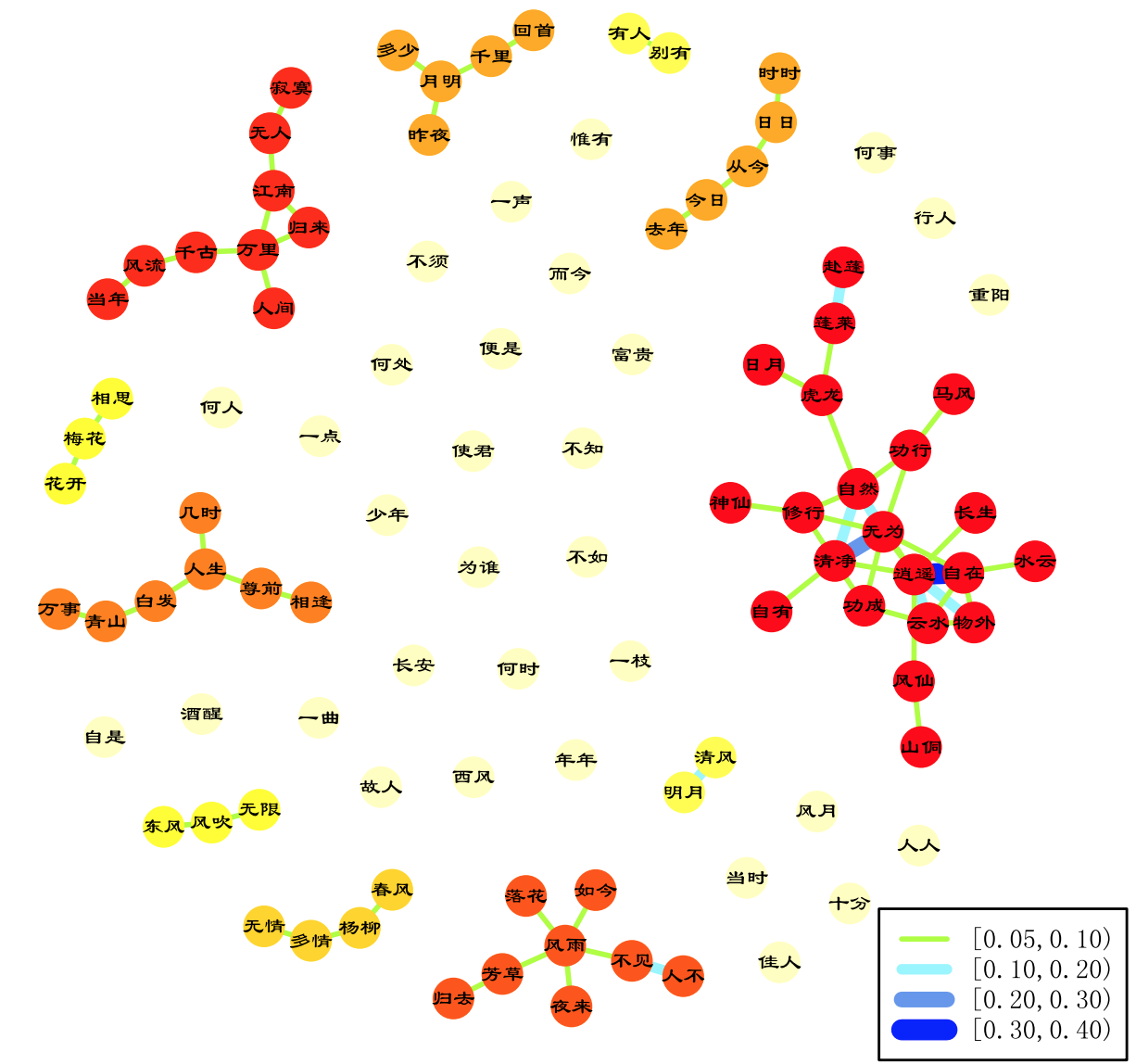 图 3: 前 100 高频词的关系网络图,规模越大的类中节点的颜色越深,节点间连线的粗细颜色对应不同的关系系数,具体参见右下角图例。
观察图 3,可以发现这一百个高频词被划分为多个类,有些类包含多个节点,是个大家族;而有些类仅有一个节点,是典型的孤魂野鬼。将包含两个节点以上的类整理如下:
图 3: 前 100 高频词的关系网络图,规模越大的类中节点的颜色越深,节点间连线的粗细颜色对应不同的关系系数,具体参见右下角图例。
观察图 3,可以发现这一百个高频词被划分为多个类,有些类包含多个节点,是个大家族;而有些类仅有一个节点,是典型的孤魂野鬼。将包含两个节点以上的类整理如下:
- 第一类 (21 个节点,图右侧) : 自然、逍遥、物外、无为、蓬莱、修行、清净、山侗、 长生、功成、云水、自在、马风、神仙、水云、风仙、自有、日月、赴蓬、功 行、虎龙
- 第二类 (9 个节点,图左上) : 人间、风流、无人、归来、江南、万里、千古、当年、寂寞
- 第三类 (8 个节点,图正下) : 归去、落花、风雨、如今、芳草、不见、人不、夜来
- 第四类 (7 个节点,图左侧) : 尊前、万事、白发、相逢、人生、青山、几时
- 第五类 (5 个节点,图正上): 千里、多少、回首、月明、昨夜
- 第六类 (5 个节点,图右上) : 今日、去年、时时、日日、从今
- 第七类 (4 个节点,图左下) : 春风、多情、无情、杨柳
- 第八类 (3 个节点,图左下) : 东风、风吹、无限
- 第九类 (3 个节点,图左侧) : 相思、梅花、花开
- 第十类 (2 个节点,图右下) : 明月、清风
第一类颇具清修悟道之味,经查证全真四子的大多数词都是这个主题和路数,反反复复出现这些字眼,因此这些词之间形成了一个大类。其他几类也都有各自的特色,比如第二类寂寥,第三类凄凉,第四类沧桑,第五类哀思,第六类时间,第七类怀春等等。当然各个类都具有自己独特的拓扑结构,同一个类内节点的关系也是不一样的。
高频词之间的关系强弱在图中用不同颜色、粗细的线条表示,比如逍遥和自在关系系数最大,超过了 0.3;清静和无为次之,在 0.2 和 0.3 之间;清风和明月、自然和清静、自然和无为、逍遥和云水、逍遥和物外的关系系数也较大,在 0.1 和 0.2 之间。 这相比关系系数的中位数 (0.007874) 、平均数 (0.010280)、上四分位数 (0.015380) 来说已经非常大了。
从图 3 中可以清楚地看出高频词之间的联系,对词感兴趣的读者肯定可以挖掘到更多有意思的信息。需要说明的是,这里仅仅用设定阈值的粗糙方法来划分高词频的类,igraph 包中提供了很多算法对网络进行聚类,比如 fastgreedy、walktrap、 spinglass 等方法,读者可以自行尝试。此外,由于本节中的分词手法的局限性,出现了一些意外的高频词,比如 “赴蓬” 和“人不”,它们本来应该是 “赴蓬莱”、“人不寐”、“人不见” 等三字词语中的一部分。对于双字词来说,这些都是噪音,但对整体分析的影响并不大。
本文主要以词频为依据,对词风关系、高频词关系进行了可视分析。在词频统计阶段,针对宋词的特点,使用了 “组合沉淀” 的巧妙方法。图形主要用了相关矩阵图和关系网络图两种;它们都是展示关系的典型方法,可以广泛适用于各种领域中多变量的关系研究,比如蛋白质相互作用网络、社交圈子网络、动植物生存关系网络等。
矩阵图和网络图在展示关系数据时各有所长:网络图更直观易懂,但仅局限于较为稀疏的关系矩阵,当关系矩阵比较稠密时连线太多会导致图形杂乱无章 (图 3 中,我们仅选取了大于 0.05 的关系系数,且进行了离散化处理;而图 1 和图 2 则是完全展示)。矩阵图对关系矩阵是否稀疏不敏感,并且可以更精准地表达更多形式的关系系数 (比如带正负的、更多水平的),但它没有网络图直观,且在变量较多时占地面积较大。
两种方法的共同特点是都以具体统计、数学模型为基础来探求相关关系,且这些关系发掘算法有很多是可以互通的。可视分析是数据分析和图形展示的有机结合,显然前期的数据分析是最终图形的基础,比如本节中系统聚类的应用以及词风、高频词关系系数的定义等都是极其重要的。在实践中,我们应该根据具体问题和需求选择恰当的数据分析方法和最终的可视化方式。
本文有统计、有词、有可视化,还必须有什么?朋友和酒!唤起一天明月,照我满怀冰雪,浩荡百川流。鲸饮未吞海,剑气已横秋。因此,我们以稼轩《水调歌头 和马叔度游月波楼》上阙来结尾:
客子久不到,好景为君留。西楼着意吟赏,何必问更筹?唤起一天明月,照我满怀冰雪,浩荡百川流。鲸饮未吞海,剑气已横秋。
[1] 李贤平.《红楼梦》成书新说. 复旦大学学报社科版, 5:3–16, 1987.
[2] 邱怡轩. 统计词话(一). 统计之都, 2011-3. URL /2011/03/statistics-in-chinese-song-poem-1/
[3] Taiyun Wei. corrplot: visualization of a correlation matrix, 2010. URL https://CRAN.R-project.org/package=corrplot R package version 0.30.
[4] Gabor Csardi and Tamas Nepusz. The igraph software package for complex network research. InterJournal, Complex Systems:1695, 2006. URL http://igraph.sf.net
魏太云,毕业于中国人民大学统计学院,感兴趣的领域是统计建模、机器学习、数据可视化。此外,魏太云还曾担任统计之都理事会主席(2011-2016),参与多届中国 R 语言会议的组织工作,合作翻译出版了《ggplot2:数据分析与图形艺术》、《R 数据可视化手册》等书籍。

敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:[email protected]),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK