

【论文2018】【推荐算法】Alibaba Embedding
source link: https://www.guofei.site/2020/02/08/alibaba_embedding.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论文名:《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba(kdd 2018)》
模型是做什么的?
模型输入是用户点击流+物品属性
模型输出是每个item对应的低维向量
abstract&introduction
Taobao是国内最大的C2C平台,推荐系统面临3个问题:
- scalability
- sparsity
- cold start
本论文解决这个问题,基于 graph embedding 方法。
two-stage recommending framework
2 stage 分别是
- matching :生成candidate
- ranking :用DNN做个排序
本文专注 matching 问题,核心问题是基于用户行为计算出物品的两两相似度( pairwise similarities between all items based on users’ behaviors)
以前的方法是 CF 方法(collaborative filtering),但CF的缺点是只考虑物品在用户行为中同时出现这种情况。CF based methods only consider the co-occurrence of items in users’ behavior history
本文的方法规避了这种不足。
但仍然存在 冷启动 的问题,为了解决这个问题,使用 side information 去增强 embedding 过程。
例如,同一品牌、品类的商品,应该更近一点。
但是,Taobao 的 side information 有几百种,而且直觉能想到,不同的 side information 权重肯定不同
Alibaba graph-embedding
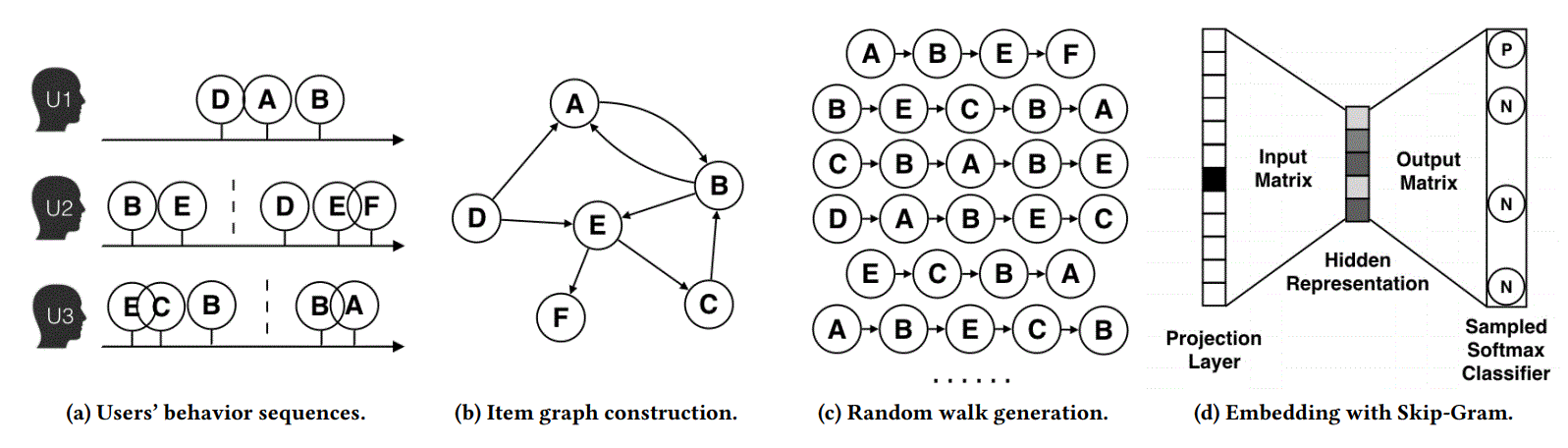
构造图的策略
CF 策略只考虑了 co-occurrence,没考虑 sequential information
- 将每个用户浏览序列sequence,做session分隔,1个sequence->n个sessions,每个session 构成一个sequence
- 将所有sequence构成有向有权图,
- 权重是次数之和
- 该步骤需要过滤掉:
- 少于1秒的点击:可能不是用户有意点的
- 点击量太多,或购买量太多的用户,可能是 spam user
- 同样的ID,可能实际商品变了,这也要移除。
DeepWalk
在 graph 上做随机游走。
Graph Embedding with Side Information
为了解决 “cold-start” 问题
side information 指的是品类、店铺、价格等。
例如,同一个店铺的两个羊毛衫,应当较近。Nikon lens和Canon Camera应该很近(品类和品牌接近)
模型做法是把 side information 作为特征,然后求均值(GES模型)
现实中,特征的权重肯定是不一样的。例如,买iPhone的人,更可能买mac,这里品牌权重大。买衣服的,可能买同一家店铺的另一个品牌的衣服,为了优惠,这里店铺特征权重大。所以引入EGES模型。
这个模型给每个item的每个side information 特征,加一个权重。
- 权重值形如 exex,而不是x,这是为了保证权重为正)
- 引入item对field weights: 建立一个MxN的大权重矩阵,学习每个item在各个标签field上的权重
- 新item的表示: item将由其本身的id特征、其他标签特征、特征权重共同表达,如果新item没有id特征,则只用标签特征做加权平均模拟,加到向量模型
算法流程

实验
离线
在亚马逊和阿里的数据上进行了实验。
- 随机选择1/3的边,作为test set,并且移除,剩下的作为训练集
- test set 中,相同数量的 node paris(不相互连接的),作为test set 的负例。
Taobao 数据,按经验选了12个比较重要的 side information
在线AB test
使用CTR指标
模型部署
离线+在线的形式,不多写了。
Airbnb word2vec
另有一片 airbnb 的文章,大体类似,细节不同
- reference《Real-time Personalization using Embeddings for Search Ranking at Airbnb(kdd 2018)》
- 提出了自己的冷启动策略
- 通过修改采样模式来优化word2vec的策略
采样策略
global context:
- 如果用户点击了 like/share,那么这个session内,这个条目与每个浏览都形成点击对(窗口无限大)
-
另一个做法(美图秀秀)做了借鉴。他们有dislike这个行为,那么条目作为负例。
- 用session分割点击序列:将用户点击序列过滤再分段成n个sessions,一个session指的是相邻item时间间隔≤30mins的”有效”行为序列
- 局部负例采样:提出要额外从同属一个cluster的其他item里抽负样本
- 付费行为强化:点击序列中若有付费行为,则将这个 item 强制纳入该序列每个item的上下文窗口
冷启动策略
- airbnb并没有做end2end的学习属性的embedding,而是直接把new item按主要属性检索到最相似的top3个已知的item,取3个item向量的平均值初始化new item embedding
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK