

Redis原理 —— ziplist 压缩列表
source link: http://blog.ponder.work/2021/05/22/redis-soure-code-data-structure-ziplist/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

压缩列表(ziplist)是列表和哈希的底层实现之一,是为尽可能地节约内存而设计的特殊编码双端链表。 当一个列表只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。
压缩列表的优点是节省内存,缺点是插入元素的复杂度较高平均O(N)最坏O(N^2), 但是在小数据量的情况下,这种复杂度也是可以接受的。
ziplist 结构
压缩列表是由一系列entry组成的结构。entry记录了当前节点的大小和前置节点的大小,所以可以双向插入和遍历。
ziplist 又4个主要部分组成
- zlbytes: 4字节,表示整个列表占用内存大小
- zltail: 4字节,表示列表尾节点相对列表第一个字节的偏移量
- zllen: 2字节,表示列表元素个数,如果节点个数超出2^16-1则需要遍历列表求出元素个数。
- zlend: 1字节
0xFF, 表示列表末尾
ziplist 结构示例图
area |<---- ziplist header ---->|<----------- entries ------------->|<-end->|
size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte
+---------+--------+-------+--------+--------+--------+--------+-------+
component | zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
+---------+--------+-------+--------+--------+--------+--------+-------+
^ ^ ^
address | | |
ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END
|
ZIPLIST_ENTRY_TAIL
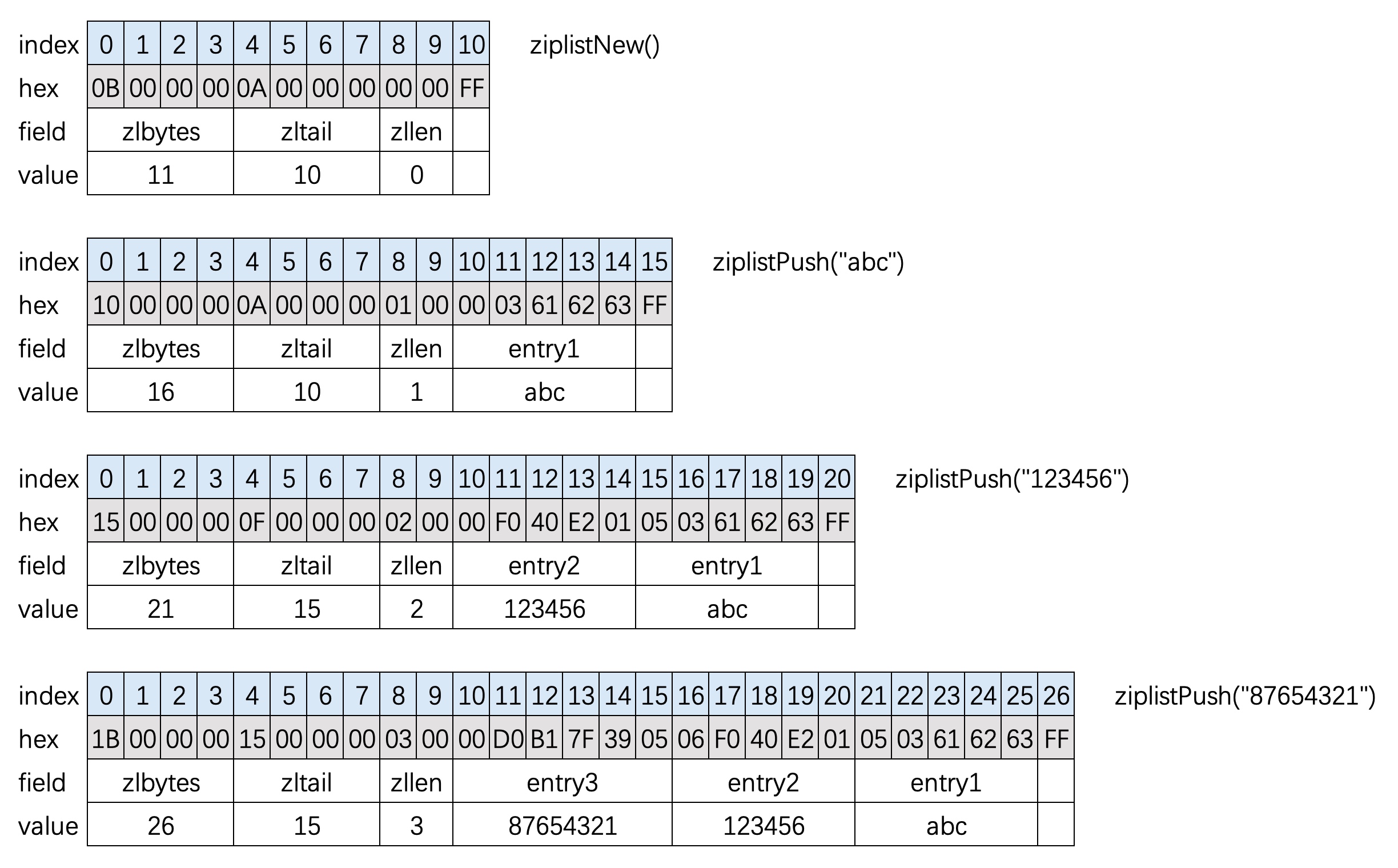
上图我们向ziplist添加了3个entry元素,向list头部插入(redis内部使用时一般向尾部插入),后面会详细解析这些元素。
ziplist 节点元素
每个ziplist节点由一下3个部分组成
- prelen: 前一个节点长度,单位为字节
- encoding: 节点的编码类型,
- content: 节点内容,可能是字节数组(c语言字符串去除末尾的\0)或者数组
之前的3个节点的二进制详情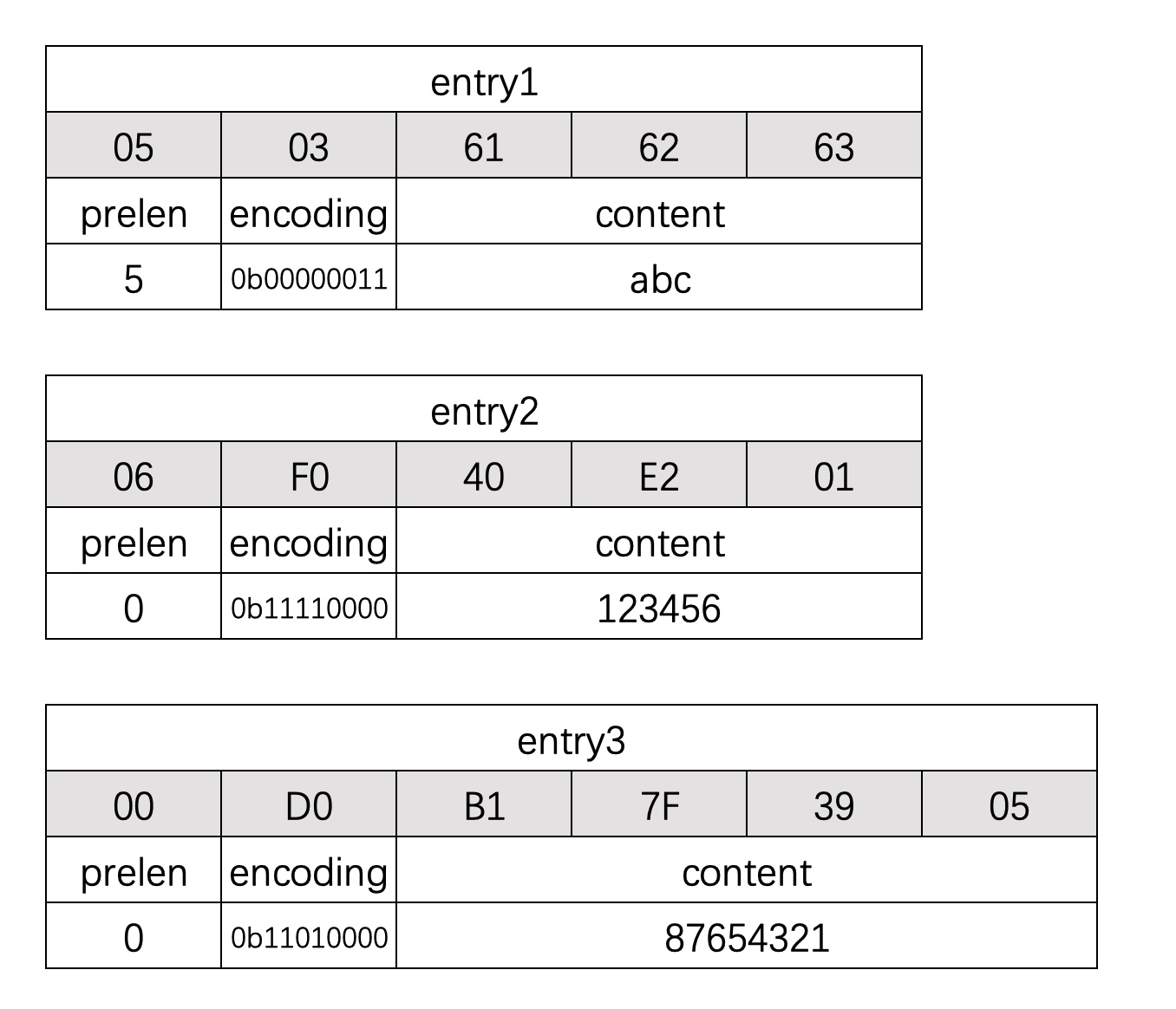
节点迭代器结构体 zlentry
typedef struct zlentry {
unsigned int prevrawlensize; // 编码 prevrawlen 所需的字节大小
unsigned int prevrawlen; // 前置节点的长度
unsigned int lensize; // 编码 len 所需的字节大小
unsigned int len; // 当前节点值的长度
unsigned int headersize; // 当前节点 header 的大小, 等于prevrawlensize + lensize
unsigned char encoding; // 当前节点值所使用的编码类型
unsigned char *p; // 指向当前节点的指针,也就是内存entry的prelen字段
} zlentry;
注意:zlentry结构体和ziplist中实际存储的entry结构是不一样的,zlentry只是为了遍历时操作entry时便利一些,类似序列化和反序列化。在需要对entry操作时,把对应位置的信息取出存到zlentry结构体中
prelen
prelen 记录了以字节为单位的前一个节点长度,有两种情况
- 默认占用1字节空间,表示0到253
- 如果节点长度大于253,则这个字节就设置为254(0xFE)作为标志位, 随后的4个字节存储实际长度。
255这个数字为啥舍弃不用呢?因为255已经作为列表结束的标志位,避免出现误导。
encoding
encoding 记录了当前节点的编码类型,编码时先尝试将内容转成数字,失败则当做字符串处理。
个人觉得ziplist的精华就在entry的encoding,对让内存的每一个bit都重复表示了信息。
可以看到ziplist为了节省内存空间,表示信息时真是细扣到每一个bit,非常高效。
但是也有个不足,就是代码变得复杂了。
由于prelen和encoding和content这3个部分都是变长的,每一次插入和删除元素都得计算列表内存长度的变化。
而且由于prelen的变长,可能会触发后面所有节点连锁更新prelen的值.
本来节点插入时只需要复制一次该节点以后所有节点的内存,这时复杂度为O(n), 触发连锁更新之后,这时候列表的插入复杂度就会变为O(n^2)。
list插入
当list底层实现为ziplist时,插入原始的逻辑
主要涉及到各种长度和偏移量的计算,比较繁琐
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
// 记录当前 ziplist 的长度
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; // 默认值,megic num, 便于debug
zlentry entry, tail;
if (p[0] != ZIP_END) {
// 列表非空,并且 p 正指向列表的其中一个节点
// 取出 p 所指向节点的信息,并将它保存到 entry 结构中;用 prevlen 变量记录前置节点的长度
entry = zipEntry(p);
prevlen = entry.prevrawlen;
} else {
// 列表为空,或者列表不为空且p正好指向表尾
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
// 列表不为空且p正好指向表尾,取出表尾节点的长度
prevlen = zipRawEntryLength(ptail);
}
}
// 尝试将s转换为数字类型,并给出content的长度
if (zipTryEncoding(s,slen,&value,&encoding)) {
// 转换成数字成功,结果会保存在value中
reqlen = zipIntSize(encoding);
} else {
// 转换失败
reqlen = slen;
}
// 计算prelen的长度
reqlen += zipPrevEncodeLength(NULL,prevlen);
// 计算encoding和content的长度
reqlen += zipEncodeLength(NULL,encoding,slen);
// 只要新节点不是被添加到列表末端,就需要确认 p 所指向的节点的prelen是否足够大
// nextdiff 保存了新旧编码之间的字节大小差,如果大于 0,需要进行扩展
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
// 因为重分配空间,该可能会改变 zl 的地址,p指针可能会失效,需要记录 zl 到 p 的偏移量
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
if (p[0] != ZIP_END) {
// 新元素之后还有节点,因为新元素的加入,需要对这些原有节点进行调整
// 移动现有元素,为新元素的插入空间腾出位置
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
// 将新节点的长度编码至后置节点
zipPrevEncodeLength(p+reqlen,reqlen);
// 更新到达表尾的偏移量,将新节点的长度也算上
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
// 更新zltail
tail = zipEntry(p+reqlen);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
// 新元素是新的表尾节点, 更新zltail
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
// 当 nextdiff != 0 时,需要级联地更新后续的节点
if (nextdiff != 0) {
offset = p-zl;
// T = O(N^2)
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
// 一切搞定,将前置节点的长度写入新节点的 header
p += zipPrevEncodeLength(p,prevlen);
// 将节点值的长度写入新节点的 header
p += zipEncodeLength(p,encoding,slen);
// 写入节点值
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
// 更新zllen
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
list底层转换为链表
判断是不是要把list转换为链表
void listTypeTryConversion(robj *subject, robj *value) {
// 确保 subject 为 ZIPLIST 编码
if (subject->encoding != REDIS_ENCODING_ZIPLIST) return;
if (sdsEncodedObject(value) &&
// 看字符串是否过长
sdslen(value->ptr) > server.list_max_ziplist_value)
// 将编码转换为双端链表
listTypeConvert(subject,REDIS_ENCODING_LINKEDLIST);
}
- redis 3.0 源码
- redis 设计与实现
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK