

mostlymaths.net
source link: https://mostlymaths.net/2021/05/data-pipelines-alloy.html/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Modelling data pipelines with Alloy
Finding test cases without actually implementing the thing May 15, 2021 9 minutes read | 1783 words by Ruben BerenguelIn which I write some easy Alloy code for a data model.

Alloy is a programming language and analysis tool for software modeling. I learnt of it 3 years ago, when I was starting with TLA+ (a language focused on how systems evolve over time). Alloy has a particularly clean syntax (see for instance this blog post) which I liked way more than TLA+, but I couldn’t find any interesting use cases.
A few days ago I was watching this pair programming between Chelsea Troy and Hillel Wayne, where they apply structural (formal) verification to a problem she had. A lightbulb moment later I realised I could use Alloy for far more than I thought (which was close to nothing at the moment).
I can write a model and see what properties I need to make sure my implementation satisfies. These properties will then become (possibly unit) tests.
This may sound duh to you. To be fair, it sounds duh to me as well, but I think it is worth exploring.
The problem
At work we have a pattern repeated over several pipelines:
- Process some data in an “engine” (EMR, Databricks, Redshift…),
- Dump the resulting data in S3,
- Load this data in our analytics warehouse (a different Redshift).
Note:
Yes, I know about dbt. Every time I have checked (and tried to implement something similar to the above) it doesn’t fit our use case well enough without passing through too many strange hoops. Someday, maybe.
Over time, as we have written some of these pipelines we have hit several facepalm moments that should have been detected by automated tests but weren’t. Most we detected in our alpha environment (I think one didn’t because of some obscure reason), but these should be rules we check every time we write one of these pipelines. Ideally, these problems should be unit-testable. On purpose I’m not mentioning what the problems were. I’ll reveal them at the end.
Writing one of these is relatively time consuming (a few days), and the bulk of the complexity is in the first step, where the process has some “meat”. The rest is just plumbing, and is where most of this model work can help.
The question
Could we create a model in Alloy in a small fraction of the time and find possible pitfalls we should test for?

Calvin & Hobbes, by Bill Waterson
Building and exploring a model
You can get Alloy from here and the best documentation is available here. Start it up and then you can paste as we explore the model space.
Meh
The syntax highlighter in Hugo (chroma) does not have Alloy support, so the code boxes won’t have syntax highlighting active.
sig Pipeline {}
This is the first Alloy snippet. With sig you declare something, which in this case is empty. You can press execute (or show) to explore the universe satysfing these definitions, and while in the visualizer window, you can press next to keep exploring the universe (by default it will have 4 of each maximum). This universe will start with no pipeline and have up to 4 pipelines:

Since we are not concerned with having multiple pipelines, we can actually do
one sig Pipeline {}
Now the universe contains one and exactly one Pipeline. Other quantifiers would be some (at least one), lone (at most one).
This is not particularly useful: we need pipelines to contain the stages mentioned above. We can create them as additional signatures. Again, since we are only concerned with one pipeline and its stages (and there is only one stage of each) we can add the one quantifier to the signatures.
one sig Pipeline {}
one sig Process {}
one sig Dump {}
one sig Load {}
Note:
For empty signatures you can actually arrange them all together, like
one sig foo, bar {}
but here I want to add stuff eventually to each.
We can now add the steps to the pipeline as attributes:
one sig Pipeline {
process: Process,
dump: Dump,
load: Load,
}
one sig Process {}
one sig Dump {}
one sig Load {}
It is not very interesting now, but it has some structure.
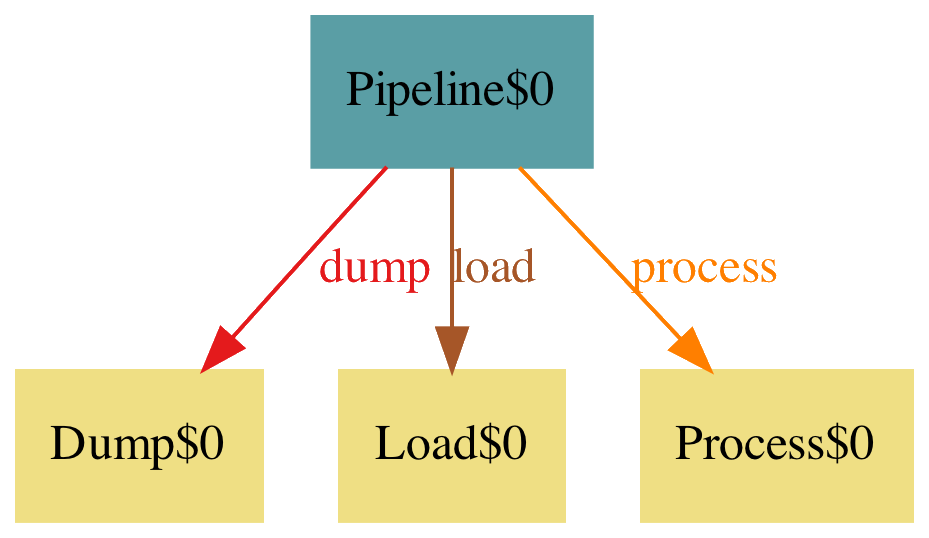
We could stop here and say: implement this. And this is basically what happens when you defined it as a set of user stories, you go straight to implement the trees while you are missing the forest.
Let’s enrich the model a bit and see where this leads us. Let’s go in order, and write the first things that are pretty obvious:
- Process: this uses an engine and generates an output.
- Dump: this takes some input and writes an output (from somewhere) in some format.
- Load: this takes some input (from somewhere) with some format.
Okay, let’s add all these things to the model. It’s not clear what output may mean in the process step: I’ll assume it’s a Location, like what defines all those somewhere. This sounds generic enough, we can use Location then as inputs and outputs.
one sig Pipeline {
process: Process,
dump: Dump,
load: Load,
}
sig Engine, FileFormat {}
sig Location {}
one sig Process {
engine: one Engine,
output: one Location,
}
one sig Dump {
input: one Location,
outputFormat: one FileFormat,
output: one Location,
}
one sig Load {
input: one Location,
inputFormat: one FileFormat,
}
A first pass looks like this, and one execution of the model gives this diagram:
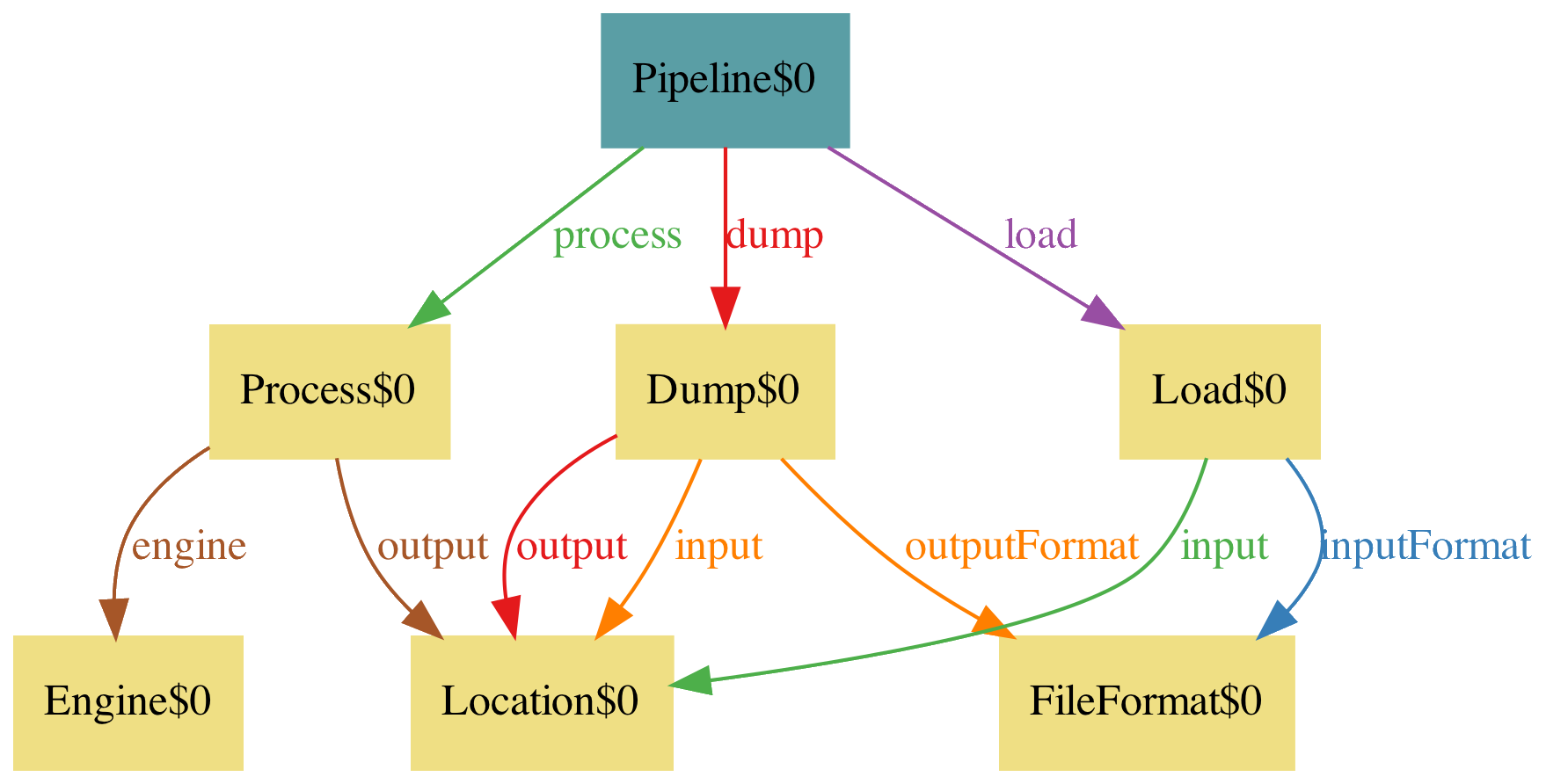

Of course when writing the above you may have thought the inputs and outputs need to match, you moron. And indeed, it’s obvious seeing the diagram above as well… but we actually missed testing for it, and it failed in a real run. DUH!
We can restrict our world to have this predicate: this predicate would be a test we need to add to our real implementation. The test is for input-output consistency.
/* [no changes from previous] */
pred ConsistentProcessDump[p: Pipeline]{
p.process.output = p.dump.input
}
pred ConsistentDumpLoad[p: Pipeline]{
p.dump.output = p.load.input
p.dump.outputFormat = p.load.inputFormat
}
run {
all p: Pipeline {
ConsistentProcessDump[p]
ConsistentDumpLoad[p]
}
} for 4
A predicate is some property you establish, and in the run statement you request your universe to contain only pipelines satisfying these. When you pressed execute without an explicit run statement Alloy was actually running a default one.
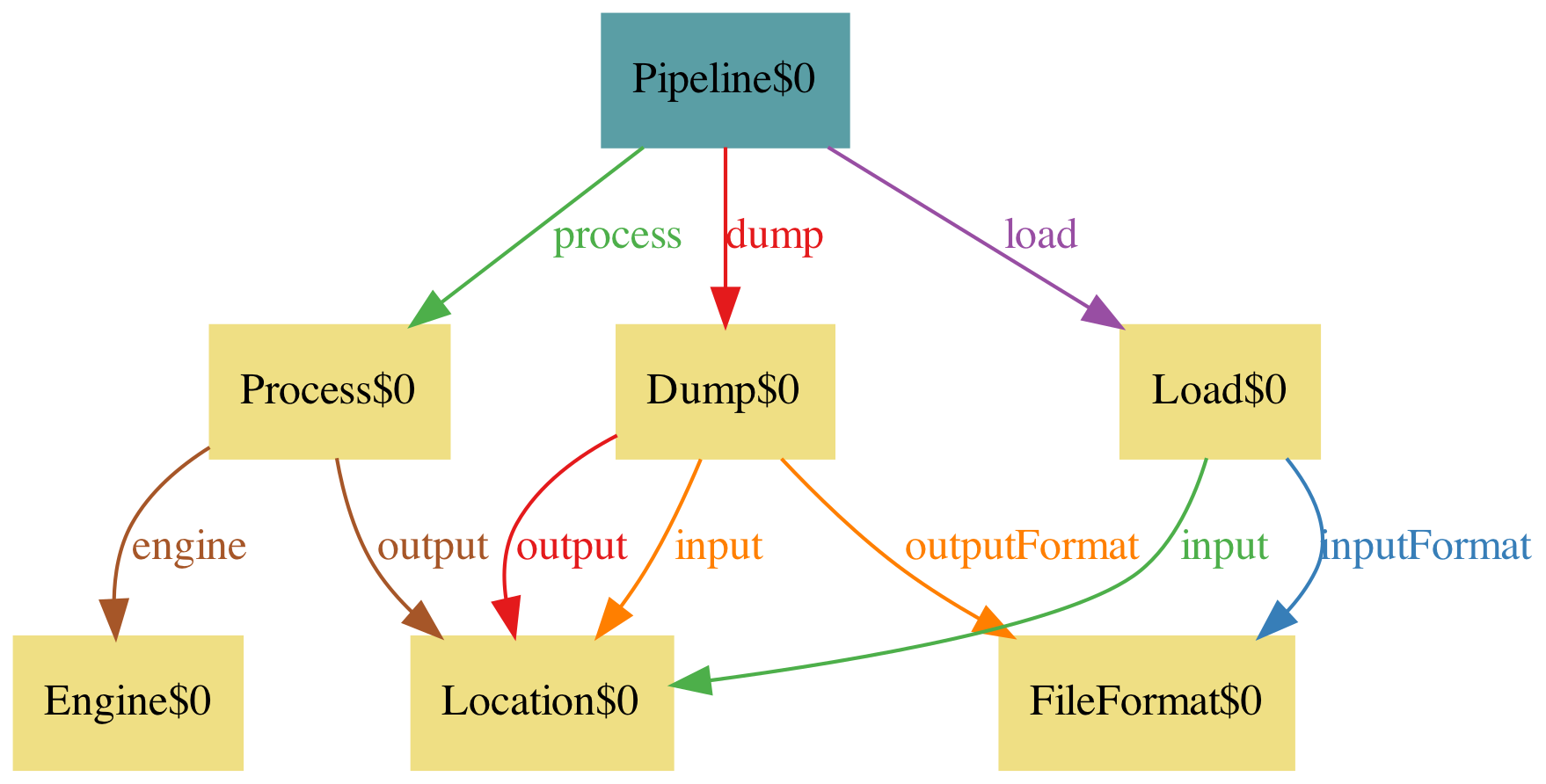
Okay, this looks better, except that Dump is reading and writing from the same location!
pred ConsistentDump[p: Pipeline]{
p.dump.input != p.dump.output
}
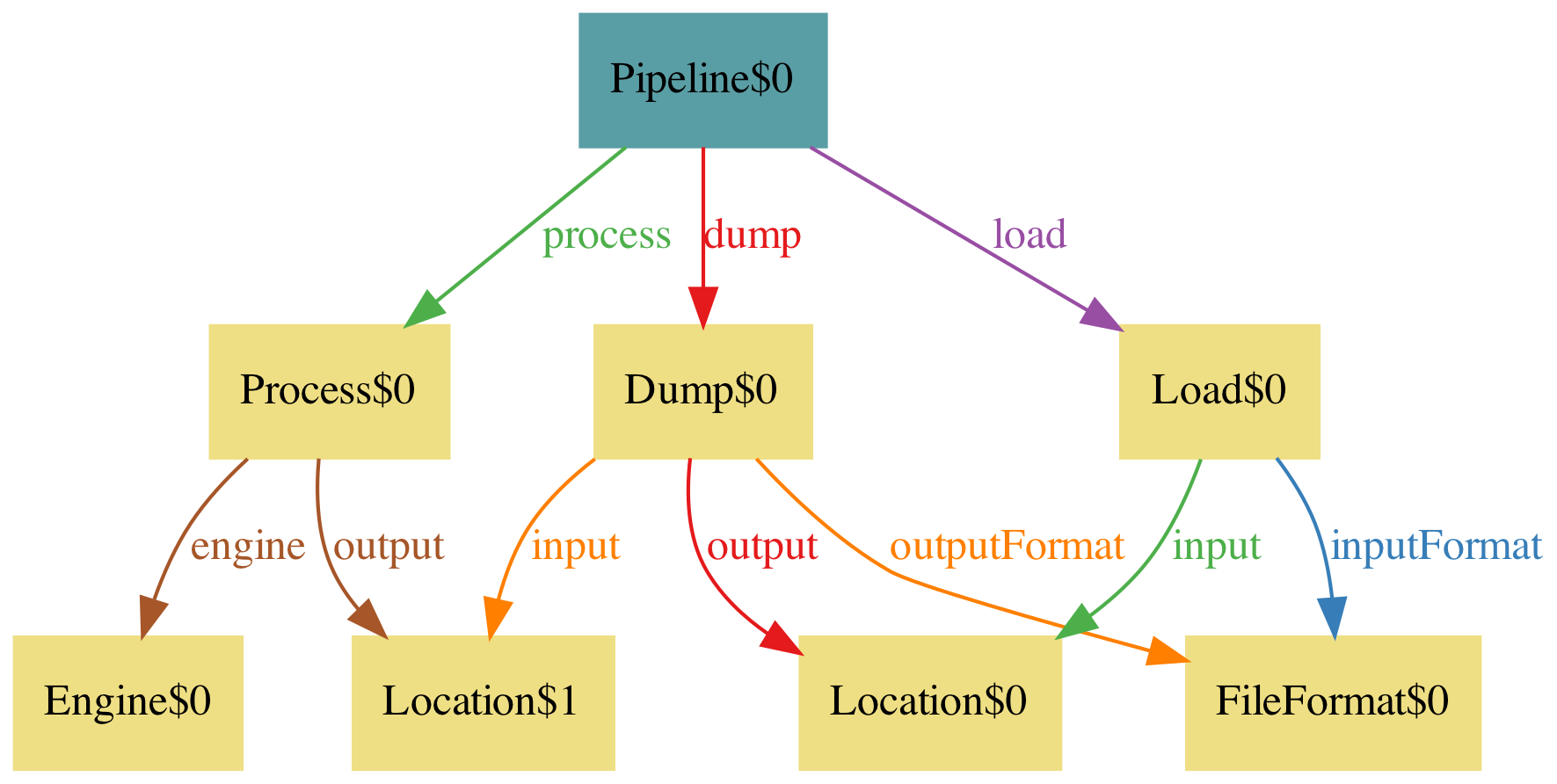
This looks better. You can tweak the settings in the theme to make it look better, since the file format can be an attribute instead of an arc (click Theme and press on the relevant relations, then uncheck show as arcs and check instead show as attribute, then in the type FileFormat select Hide unconnected nodes).
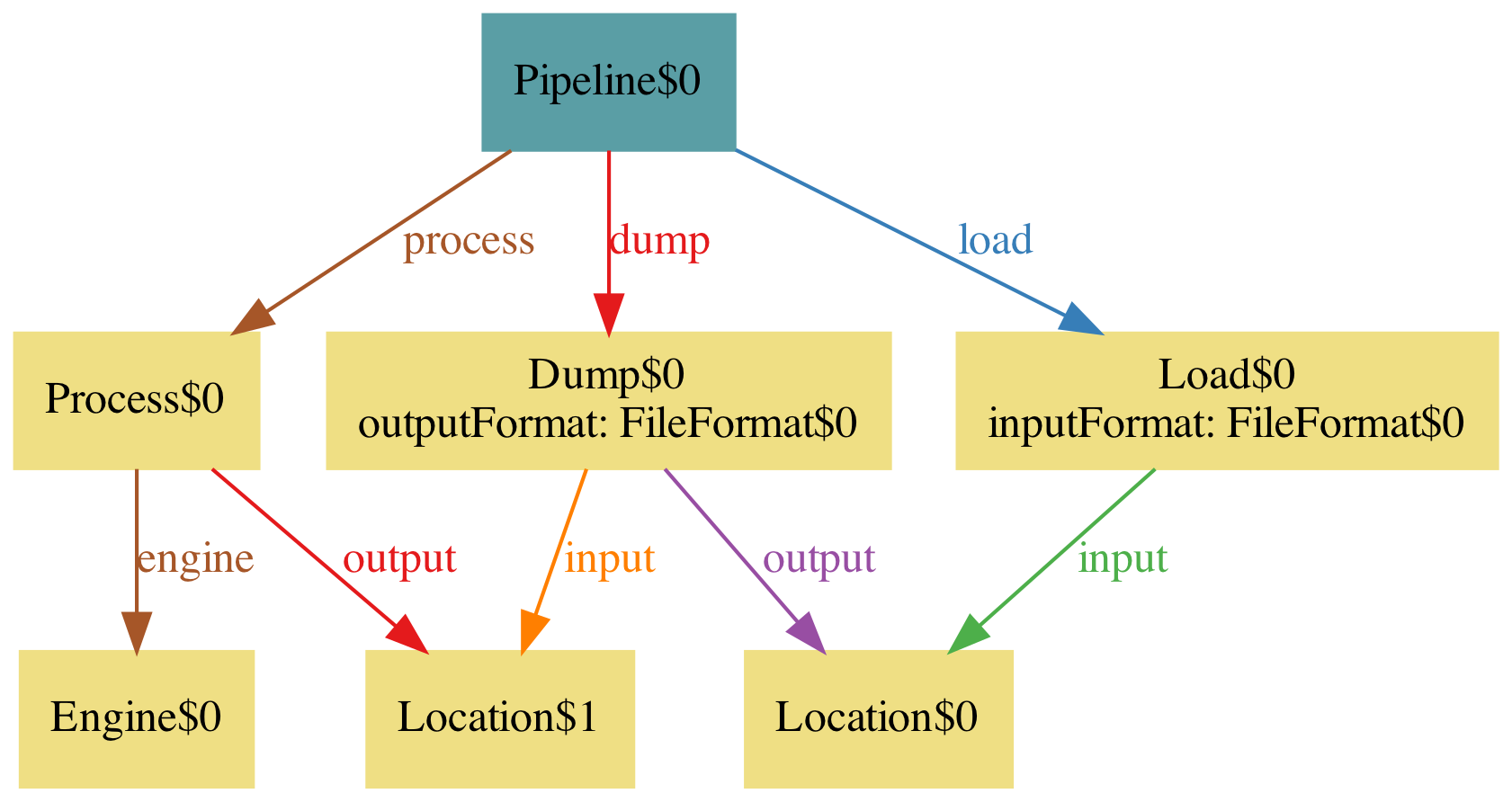
With this model we have avoided the facepalm of forgetting to test that the input and output formats match, and that the locations match. In other words, in your tests you should check this. In our case, this pipeline lives in Airflow and has a test suite that confirms that the Jinja variables used for all these match.
Is our job finished?
A model is not a full pipeline, and can always be extended a bit more. If you dig down a bit into what each step does, you can find things that are easy to add to the model and raise issues. For example, the Load step is loading a file into/as a table in Redshift. What happens with the schema? We can enrich the model thus with
sig Name, Type {}
sig Column {
name: one Name,
type: one Type,
}
sig Schema {
// We could have avoided defining Schema and just
// have set Column for the schema attributes, but
// having it as a sig makes the fact simpler.
def: set Column,
}
one sig Dump {
input: one Location,
outputFormat: one FileFormat,
output: one Location,
outputSchema: one Schema,
}
one sig Load {
schema: one Schema,
input: one Location,
inputFormat: one FileFormat,
}
fact InterestingSchemasOnly {
all s: Schema | # s.def > 1
}
Facts are properties that are true regardless of any other consideration or needing any tweaks. In this case, I want to force the universe to have no empty tables, or tables with just one column, and this is just because it makes the model richer to explore.
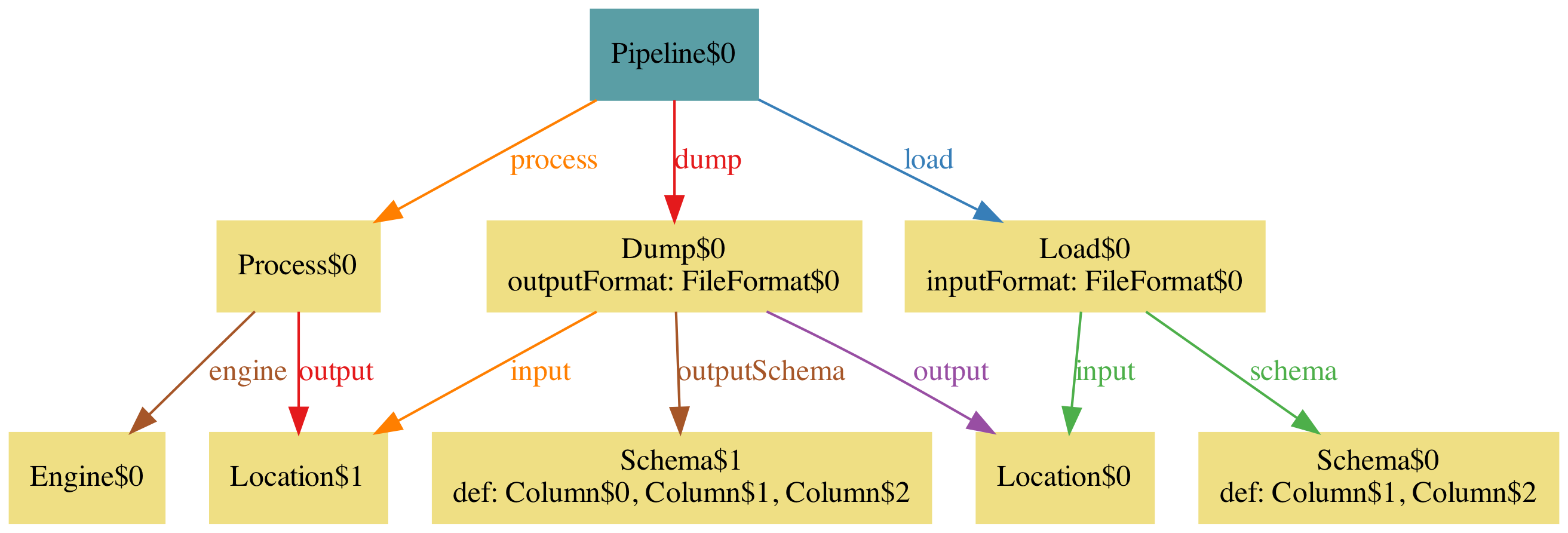
And it’s obvious you want schemas to be the same.
pred ConsistentSchemas[p: Pipeline]{
p.dump.outputSchema.def = p.load.schema.def
}
With this predicate, a model instance looks like this:
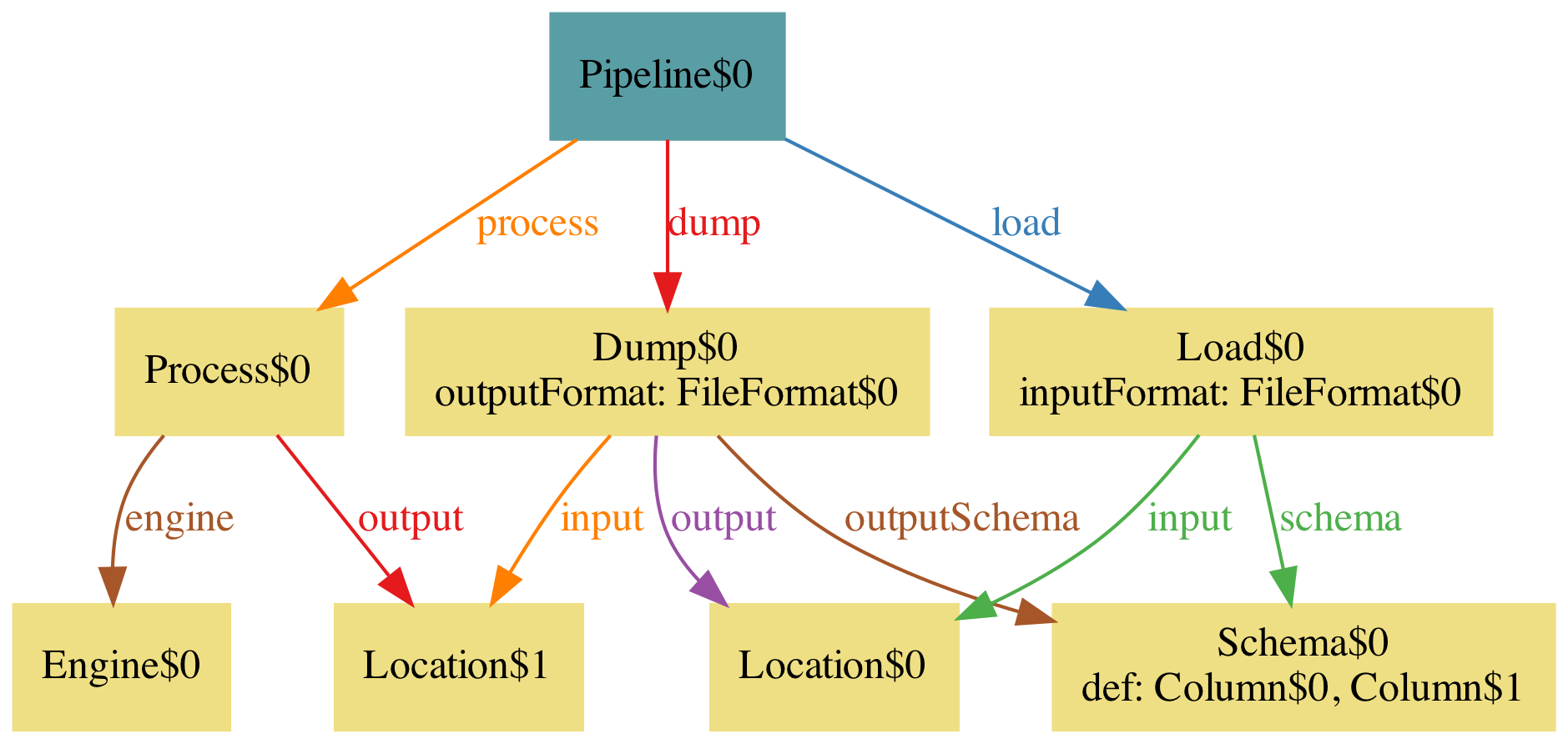
You can keep enriching the model until you are confident it covers your problem well enough. Right now I think there is only one area I’d like to explore… but it’s the matter of the info box below.
Pipelines and global state: idempotency
Taking into account that a pipeline after having run modifies the global state of the world (like the intermediate storage, or the destination tables) will be the subject of another post. Handling stuff that changes over time in Alloy is a bit tricky.
The next version (Alloy 6) will have enhanced capabilities for time-based models. I’m still not sure if the next post will be using the development version of Alloy (which you can easily build locally), or the standard way of modelling time-based problems before version 6.
How many models must a person walk down?
I have written a model for “this” pipeline 3 times from scratch already:
- To see how interesting it was as a problem,
- Explaining it to a coworker to bounce back ideas,
- The one here.
Each time the model has turned out slightly different and interesting in its own way.
In summary
Writing a model like the one above takes significant less time than writing a full pipeline (for context, this whole post has been less than 3 hours, and includes fighting with GraphViz to generate the graphs, as well as editing images and checking some documentation). Finding the interesting areas to test to avoid stupid mistakes seems to be well worth it for the small time investment. Also, depending on the problem it’s clearly a do once and benefit forever situation.
By the way, the problems that we have faced (and that I collected as a list of you should test this) are:
- Dumping via
SELECT *, which causes schema violations onCOPYwhen there are schema changes on one side, - Different formats or locations between dump and load,
- Properties that require sequences of events and will be the topic of another post 😎.
You can get the full model from here.
Thanks
Alberto Cámara for rubber ducking and challenging this model approach for data problems.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK