

阿里林俊旸:大模型对很多人来说不够用,打造多模态Agent是关键 | 中国AIGC产业峰会
source link: https://www.qbitai.com/2024/05/139379.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

阿里林俊旸:大模型对很多人来说不够用,打造多模态Agent是关键 | 中国AIGC产业峰会

智能模型应融入对视觉/语音的理解
编辑部 整理自 AIGC峰会
量子位 | 公众号 QbitAI
在过去一年中,通义千问系列模型持续开源。
不仅频繁放出多种版本,涉及不同的规模和模态,成绩在大模型竞技场中也名列前茅。
比如目前最大的72B模型,表现就胜过了Llama 2-70B和MoE开源模型Mixtral。
而纵观整个大模型行业,开源开放也正促进着AIGC新应用的涌现。
过去一年,通义千问团队都做了什么,又有哪些经验值得开源模型开发者参考?
中国AIGC产业峰会上,阿里高级算法专家林俊旸给出了他的答案。

林俊旸参与了通义千问大模型的研发、开源、与外部系统融合等探索工作,还曾参与超大规模预训练模型系列M6、通用统一多模态预训练模型OFA等大模型的打造。
为了完整体现林俊旸的思考,在不改变原意的基础上,量子位对演讲内容进行了编辑整理,希望能给你带来更多启发。
中国AIGC产业峰会是由量子位主办的行业峰会,20位产业代表与会讨论。线下参会观众近千人,线上直播观众300万,获得了主流媒体的广泛关注与报道。
- 开源大模型要更深地融入整个生态,才能给用户带来便捷的使用体验。
- 除了基础模型Benchmark之外,多语言、长序列和Agent能力,也是衡量大模型表现的关键指标。
- 大语言模型发展下去,终将变成多模态模型,因为一个非常智能的模型,不仅要有语言能力,还应该融入对视觉语音方面的理解。
以下为林俊旸演讲全文:
融入生态,让大模型使用更加便捷
相信国内朋友都听说过通义千问的开源模型,我们从去年8月份开始一直开源,到现在我们开源的系列模型已经非常多了,刚开始先从7B、14B开始开源,直到现在1.5系列的72B版本,用户使用下来的感觉还不错。
当然,我们的1.5系列模型,涵盖的规模非常全,除了72B还有0.5B、1.8B这样的小规模版本,最新还有一个小的MoE的模型,大概是14B的参数量,激活参数量大概是2.7B。
我们的模型现在在LMSYS chatbot Arena,也就是人工评测上面取得比较不错的成绩,在刚开始登榜的时候,我们是开源的第一名,刚刚才被千亿参数的Command-R-Plus给超越。
如果只在相同规模中比较,那么截止到现在(4月17日),我们的72B模型还是最好的。
除此之外,我们也听从了开发者的建议,发布了32B模型,因为开发者反馈说72B模型太大,14B又好像还不够用。
最新推出的这个32B模型也取得了比较不错的成绩,跻身到了前15的行列,表现非常接近72B的模型,跟MoE架构的Mixtral相比也具有一定优势。
而除了不断提高模型的表现,最近几个月我们还做了一些不太一样的事情,就是让千问系列模型更好地去融入大模型生态,让用户使用起来更加便捷。

具体的举措有这样几点,第一是千问的代码已经融入了Hugging Face的官方代码当中,大家使用通义千问1.5的模型时就不需要再用Transformer code来调用了。
除此之外,我们很多三方框架都做了比较好的支持,包括LLama.cpp、vLLM,现在还有像Ollama也非常方便,都可以一键使用我们的模型。
如果你用LM Studio,也可以从中使用我们的GGUF的模型。如果想对我们模型进行微调的话,其实可以用到比如说Axolotl以及国内的LlaMA-Factory等工具。
多语言和长文本能力是关键指标
接下来我会给大家详细介绍一下我们模型的构成以及模型当前表现水平。
首先要看Base Language Model是一个什么样的水平,因为只有基础语言模型的表现好了,才能实现对齐,去进一步做一个比较好的模型。
我们各个Size都做了对比,其中72B的模型在各个Benchmark上的表现都比较有竞争力。
当然,我们现在开源模型跟GPT-4还会有差距,但是相比于此前的Llama2-70B以及Mixtral,都有比较明显的优势。
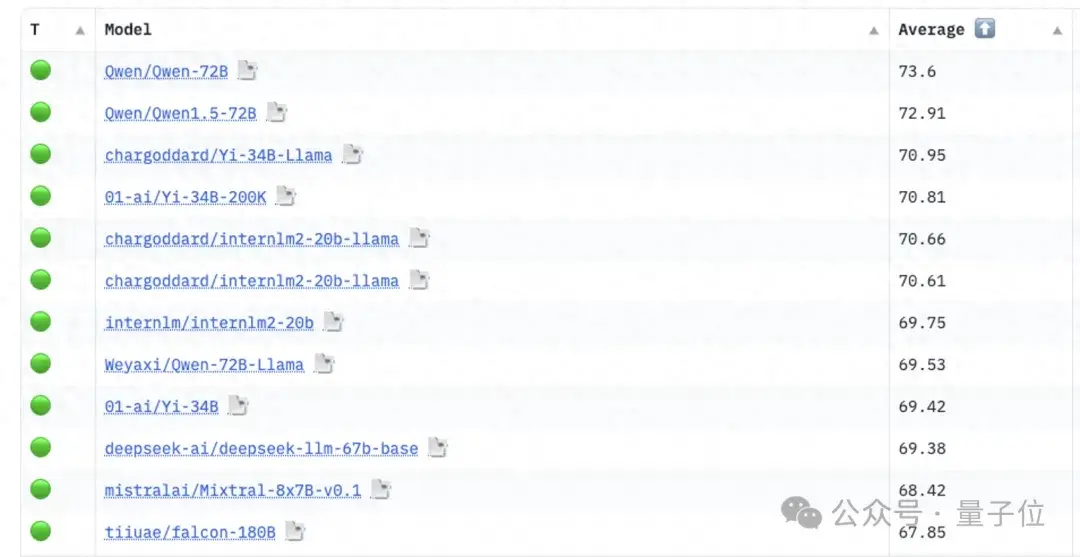
很长一段时间,如果大家关注Hugging Face Open LLM Leaderboard,会发现其实有很多模型是基于我们的72B模型微调出来的,因为海外朋友很多非常喜欢微调这个模型,然后登到这个榜上去。
同时我们不仅仅有7B及以上的大模型,也有小一些的模型,又叫做Small Language Model这一块,我们最小的模型参数量是0.5B,也就是5亿。
我们还有像1.8B、4B这些规模的模型,跟Phi-2、Gemma-2B等模型相比的话,我们的模型都非常有竞争力。
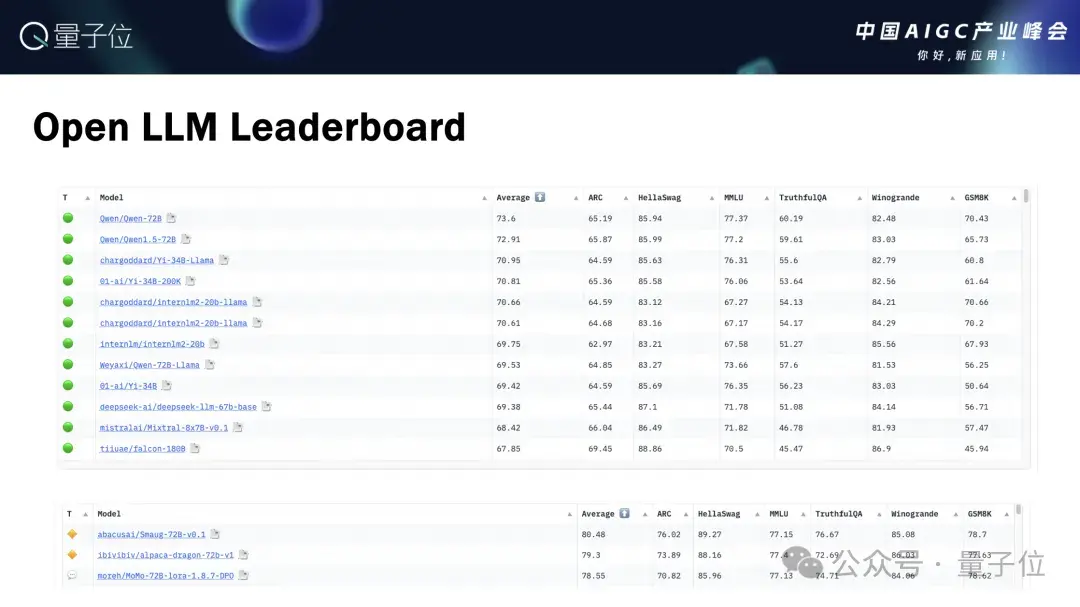
另外一个方面是多语言的能力,我们此前的模型在Qwen1的时候,没有对多语言进行检测,但本质上是多语言的模型。
大家可能会有一些想法,比如说阿里训出来的模型就是中文的模型,或者是中英双语的模型,其实不是这样,我们最近对多语言能力做一些检测,发现它的表现还不错,所以我们进一步在这个基础上做了多语言方面的对齐。
在12个比较大的语言上面去跟GPT-3.5相比,我们的模型表现都比较有竞争力。
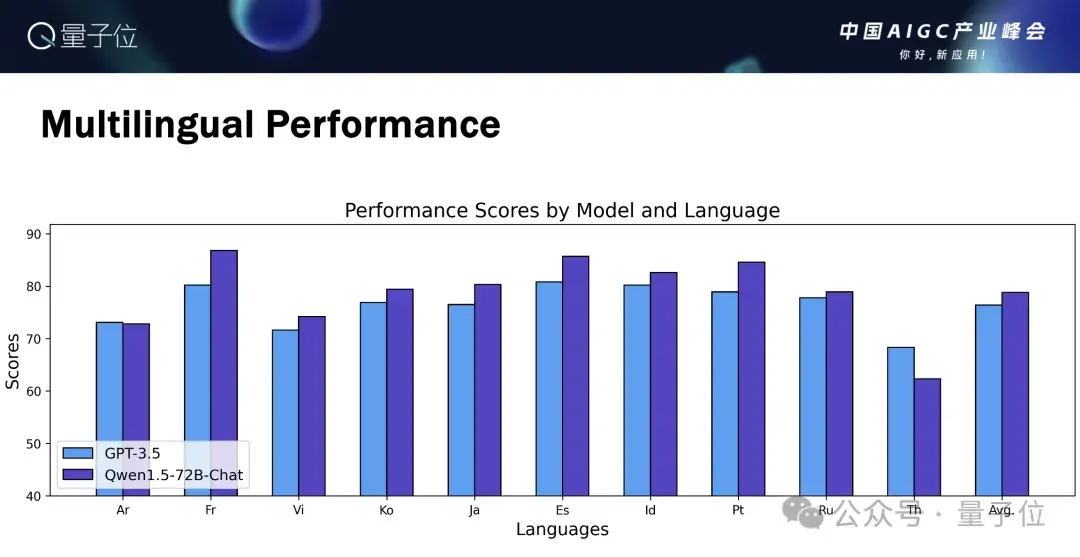
如果大家关注社交媒体,会看到有很多朋友在使用我们的多语言的能力。
从目前收到的一些反馈来看,它的越南语能力还不错,还有人跟我说,孟加拉语也还可以。
最近还出现了一个模型东南亚语言模型Salior,它是基于Qwen1.5继续训练然后微调出来的。
而在小模型方面,有反馈说在法语上的表现不错,家如果看ChatBot Arena法语榜上,Qwen1.5表现也是非常有竞争力的。
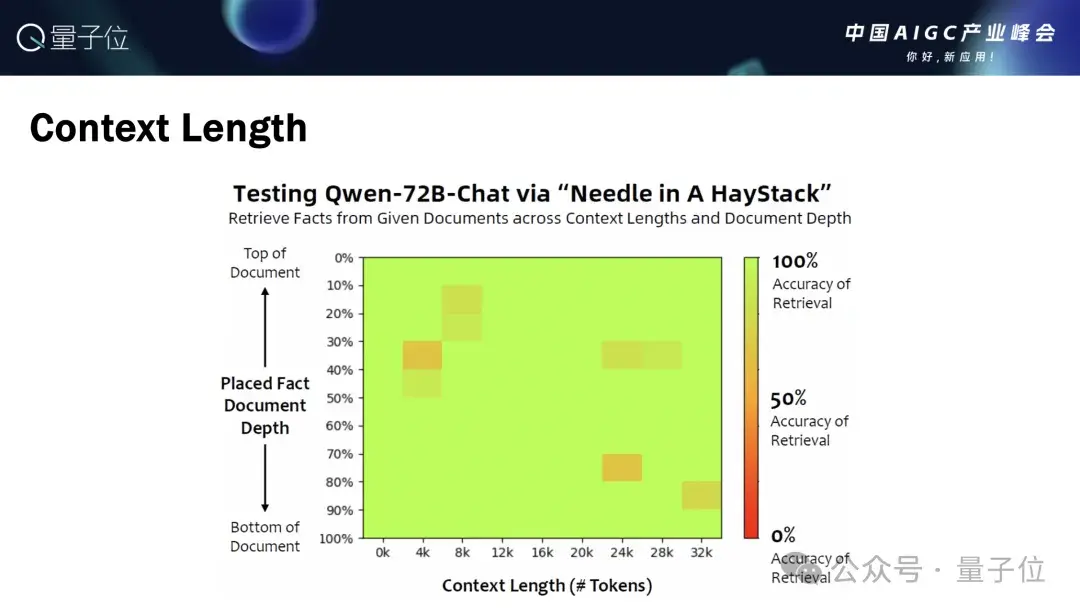
在长序列方面,目前我们看32K长度上的表现是比较稳定的,有些模型Size甚至可以通过外推的方式推的更长,接下来的版本也会有更长的上下文窗口。
我们除了做简单的大海捞针的实验之外,也对一些针对序列评测的榜单做评估,发现我们的Chat模型在长序列方面,是可以做一些使用方面的东西。
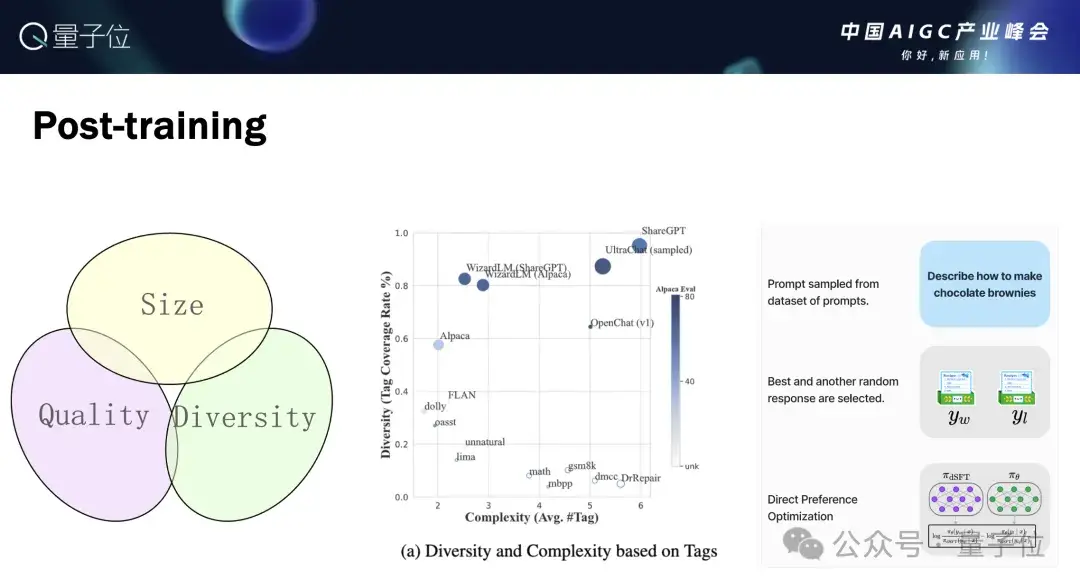
下一个部分就是常说的Post-training,今天大家对大模型感兴趣,主要也是因为Post-training让大模型的潜力爆发出来,能够成为一个Assistant来帮助我们。
我们在Post-training做了非常长时间的工作,包括SFT(指导监督微调),主要是在数据方面做了一些比较扎实的工作。
我们最近在DPO方面也做了比较多的工作,之后如果有机会会通过技术报告的方式跟大家分享更多相关的细节。我们做完这些之后,会发现模型在一些评测上面的表现更有竞争力。
除了人工评测之外,还有像MT-Bench和Alpaca-Eval这样的测试,我们模型的表现也都非常有竞争力,尤其是Alpaca-Eval。
另一方面我们讲Agent方面的能力,这是我们一直非常关心的。
但我们刚开始给Qwen系列模型做SFT的时候,发现模型不太具备Agent相关的能力。
解决的方式是做更多的数据标注,时间长了之后,经验越来越丰富,就可以做一些Agent相关的任务了。
下一站是多模态Agent
今天我们还会关心另外一个问题,就是“大”模型对于很多人来说是不够用的。
因为大模型发展下去,终将变成多模态的模型,因为一个非常智能的模型,应该能够融入对视觉语音方面的理解。
过去几年的时间里,我们在多模态领域也做了比较多的工作,再把之前的一些经验融入进来,就有了Qwen-VL系列模型。
Qwen-VL系列模型的训练方法也相对来说比较简单,分为三个阶段。
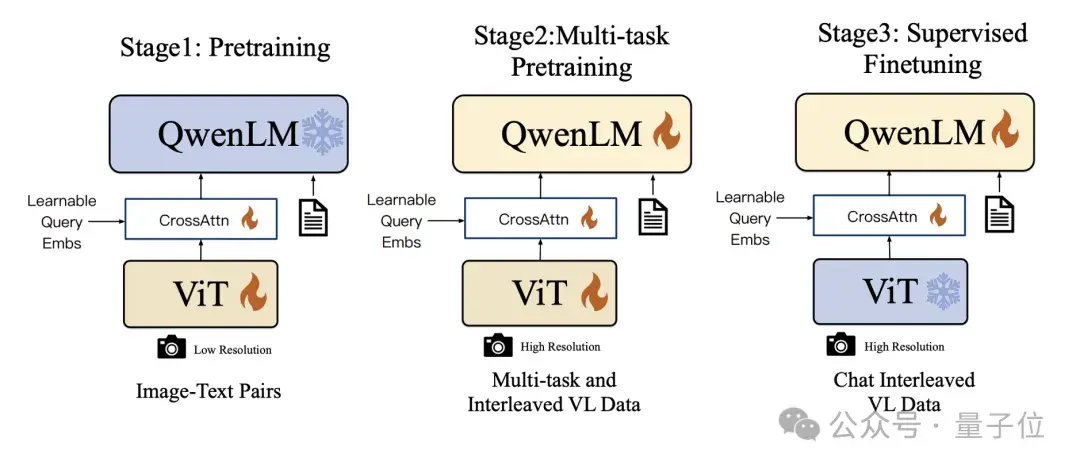
首先是非常扎实对齐的预训练,实现视觉和语言模型的对齐,让我们的语言模型能够睁开双眼看世界,能够理解视觉方面的信息。
接下来是能力的注入和对齐,我们VL核心开发同学,他有一天刚好去医院,对医院密密麻麻拍了一个照问它说肚子疼去哪里,模型把相关信息都能准确识别出来。

这是今天VL模型跟过去不一样的点,今天对OCR的识别比以往做的好很多。
在这个基础上我们想做更加冒险的事情,比如说打造VL方面的Agent,如果能成功的话,将会非常有吸引力。
比如说,如果想对手机屏幕进行操作,如果看到的是一堆代码,那么操作起来将会非常困难,而对人来说不管怎么看、不管颜色、Logo怎么变我们都能理解,屏幕上面有哪些东西我们都能做出正确选择。
所以我们也让模型进行了一些尝试,发现它能准确识别出来这些位置,所以我相信随着VL模型水平不断提升,在Agent方面的潜力会越来越大。
如果让我们模型看见世界,能不能让它听见呢?方法也非常简单,简单说就是把Audio Encoder接入我们的模型,再基于刚才所说的几个阶段进行训练,就能得到非常好的效果。
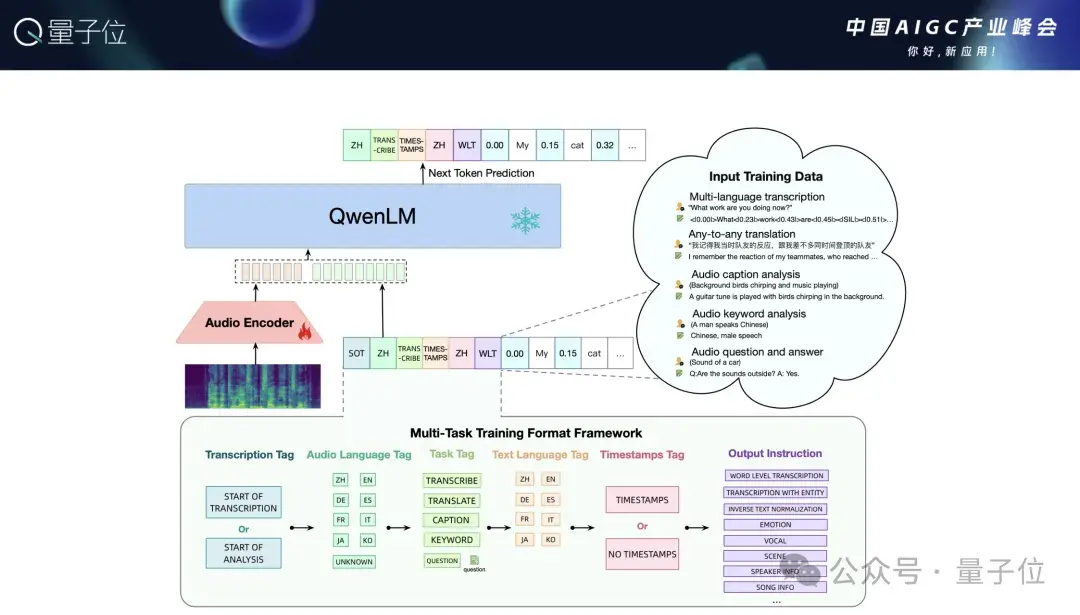
而能够听见声音的大模型,可以做的事情非常多。
比如我在海外旅游,到了某个国家去,不太会说当地的语言,希望有一款产品能帮我进行翻译。
而在这种产品背后需要解决几个问题,需要先对语音进行识别,然后再进行机器翻译,这个过程其实非常麻烦。
但有了大模型之后,这样的任务只需要一个prompt就能解决,并且还能翻译成不同的语言,只需要跟模型交互就可以了。
除此之外,还有对自然声音和音乐的理解,ASR模型只能理解人的说话并转成文字,但现实中的声音包括自然声音以及音乐等多种类型。
而我们的模型可以做音乐的赏析,听到一段声音就能写出一首诗,可以看到大语言模型在多模态方面潜力十足。

另外,今年非常重要的一个趋势是大模型与视频的结合,我们下一步会做出更多模态,其中视频就是一个重点。
最后我做一个简单的总结,我们现在的Base模型和Chat模型每一次都会推出几个版本,最新的模型就在几个小时前,还推出了code专项模型,叫做CodeQwen 1.5,是一个7B规模的模型,在代码方面的Benchmark表现比较突出,大家可以去尝试。
接下来我们会去做进一步的Scaling,包括模型本身和数据的scaling,接下来还有模态方面的scaling,也就是接入更多的模态。
我们最终的目标是实现一个非常强大的大预言模型,能够理解各种模态的信息,甚至实现不同模态的输入和输出。所以,接下来大家可以持续关注我们的进展。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK