

基于 LLaMA 和 LangChain 实践本地 AI 知识库
source link: https://blog.yuanpei.me/posts/practice-local-ai-knowledg-base-based-on-llama-and-langchain/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

基于 LLaMA 和 LangChain 实践本地 AI 知识库

有时候,我难免不由地感慨,真实的人类世界,本就是一个巨大的娱乐圈,即使是在英雄辈出的 IT 行业。数日前,Google 正式对外发布了 Gemini 1.5 Pro,一个建立在 Transformer 和 MoE 架构上的多模态模型。可惜,这个被 Google 寄予厚望的产品并未激起多少水花,因为就在同一天 OpenAI 发布了 Sora,一个支持从文字生成视频的模型,可谓是一时风光无二。有人说,OpenAI 站在 Google 的肩膀上,用 Google 的技术疯狂刷屏。此中曲直,远非我等外人所能预也。我们唯一能确定的事情是,通用人工智能,即:AGI(Artificial General Intelligence)的实现,正在以肉眼可见的速度被缩短,以前在科幻电影中看到的种种场景,或许会比我们想象中来得更快一些。不过,等待 AGI 来临前的黑夜注定是漫长而孤寂的。在此期间,我们继续来探索 AI 应用落地的最佳实践,即:在成功部署本地 AI 大模型后,如何通过外挂知识库的方式为其 “注入” 新的知识。
从 RAG & GPTs 开始
在上一期博客中,博主曾经有一个困惑,那就是当前阶段 AI 应用的最佳实践到底是什么?站在 2023 年的时间节点上,博主曾经以为未来属于提示词工程(Prompt Engineering),而站在 2024 年的时间节点上,博主认为 RAG & GPTs 在实践方面或许要略胜一筹。在过去的一年里,我们陆陆续续看到像 Prompt Heroes、PromptBase、AI Short…等等这样的提示词网站出现,甚至提示词可以像商品一样进行交易。与此同时,随着 OpenAI GPT Store 的发布,我们仿佛可以看到一种 AI 应用商店的雏形。什么是 GPTs 呢?通常是指可以让使用者量身定做 AI 助理的工具。譬如,它允许用户上传资料来丰富 ChatGPT 的知识库,允许用户使用个性化的提示词来指导 ChatGPT 的行为,允许用户整合各项技能(搜索引擎、Web API、Function Calling)…等等。我们在上一期博客中提到人工智能的 “安卓时刻”,一个重要的契机是目前产生了类似应用商店的 GPT Store,如下图所示:
OpenAI 推出 GPT Store
如果你觉得 OpenAI 的 GPT Store 离我们还稍微有点距离的话,不妨了解一下 FastGPT 这个项目,它以更加直观的方式展示了一个 GPTs 是如何被创造出来的。如图所示,博主利用我的博客作为知识库创建了一个博客助手,而这一切只需要选模型、编写提示词、上传资料三个步骤即可。感兴趣的朋友可以从 这里 进行体验:
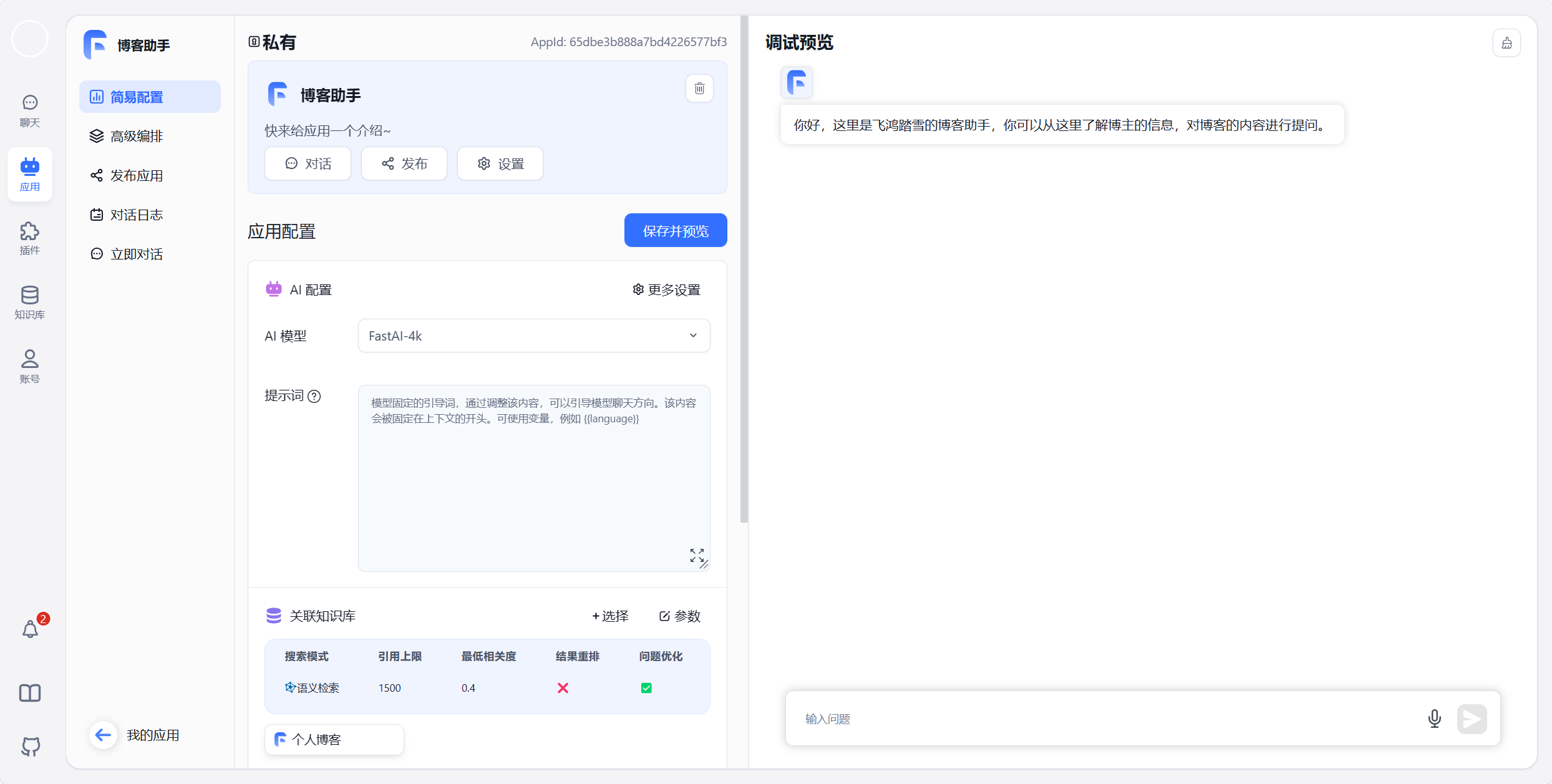
通过 FastGPT 创建 AI 应用
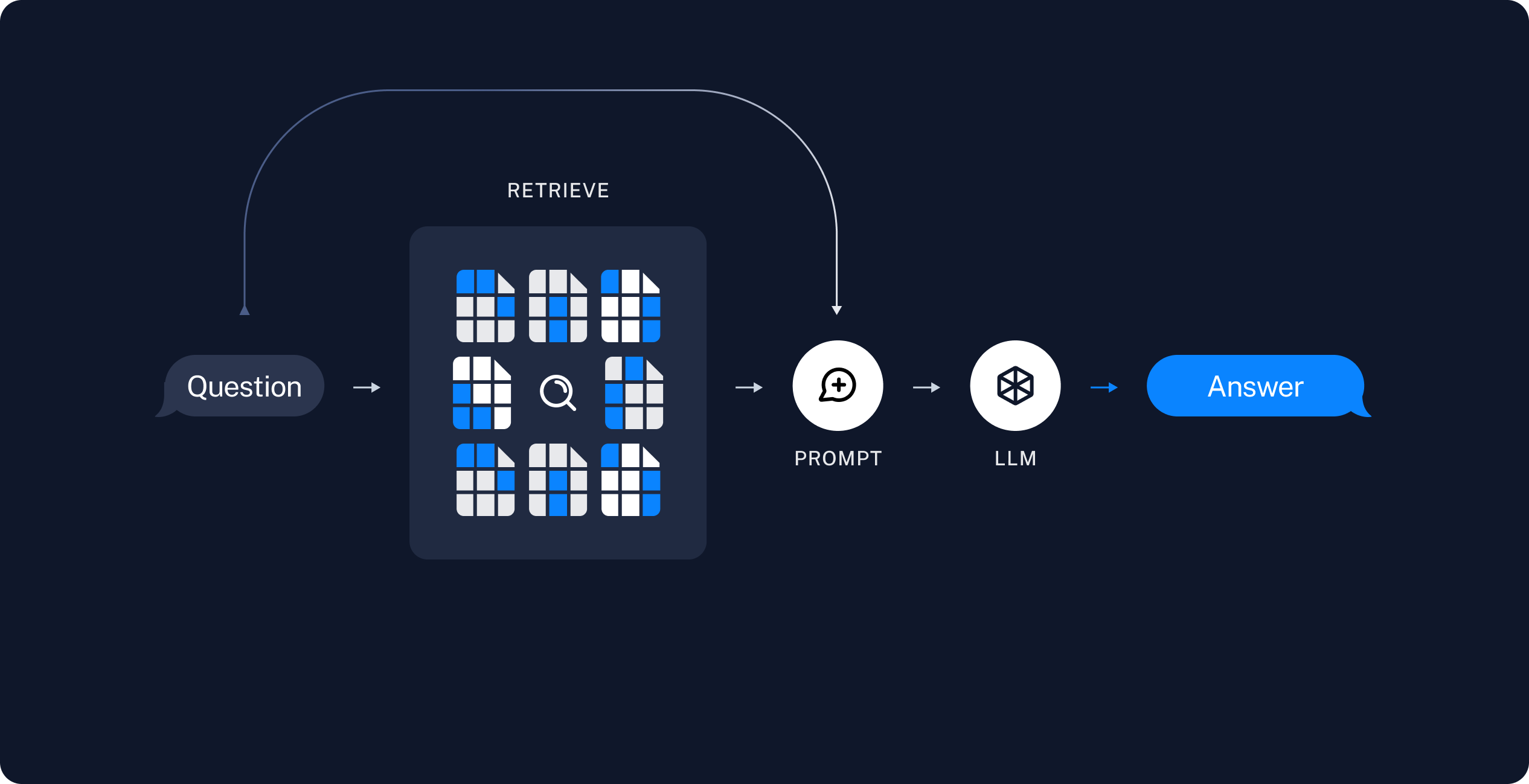
由此,我们就可以得出一个结论,目前 AI 应用落地主要还是围绕大模型微调(Fine Tuning)、提示词工程(Prompt Engineering) 以及知识增强展开,并且 GPTs 里依然有提示词参与,两者并不冲突。考虑到,大模型微调这条线存在一定的门槛,我们暂且将其放在一旁。此时,提示词工程和知识增强就成为了 AI 应用落地的关键。知识增强,专业术语为检索增强生成,即:Retrieval-Augmented Generation,RAG,其基本思路就是将大语言模型和知识库结合起来,通过外挂知识库的方式来增强大模型的生成能力。比如微软的 New Bing 是 GPT-4 + 搜索引擎的方案,而更一般的方案则是 LLM + 向量数据库的思路,下图展示了 RAG 运作的基本原理:
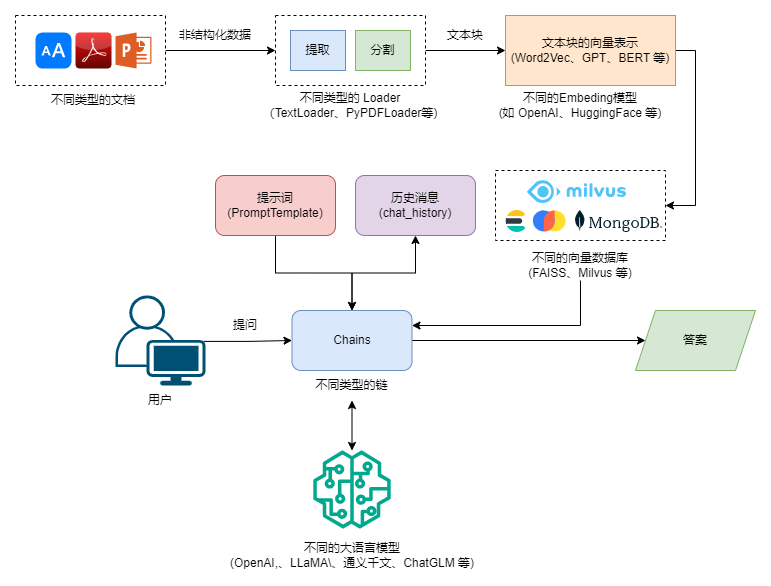
RAG 运作的基本原理
从这个角度来看,LangChain 及其衍生项目 AutoChain、Embedchain,甚至 FastGPT 等项目解决的本质都是 RAG 和 Agent 的问题。其中,Agent 不在本文的讨论范围内,这里博主不打算详细展开。接下来的内容,博主会按照这个思路进行阐述,并且以 LangChain 为例来对其中的细节进行说明。
知识库构建
如你所见,RAG 由 LLM 和 知识库两部分组成。首先,我们来构建知识库,通常,这个过程可以划分为下面四个步骤,即:载入文档(Loader)、拆分文本(Splitter)、文本向量化(Embeddings)、向量存储(VectorStore)。
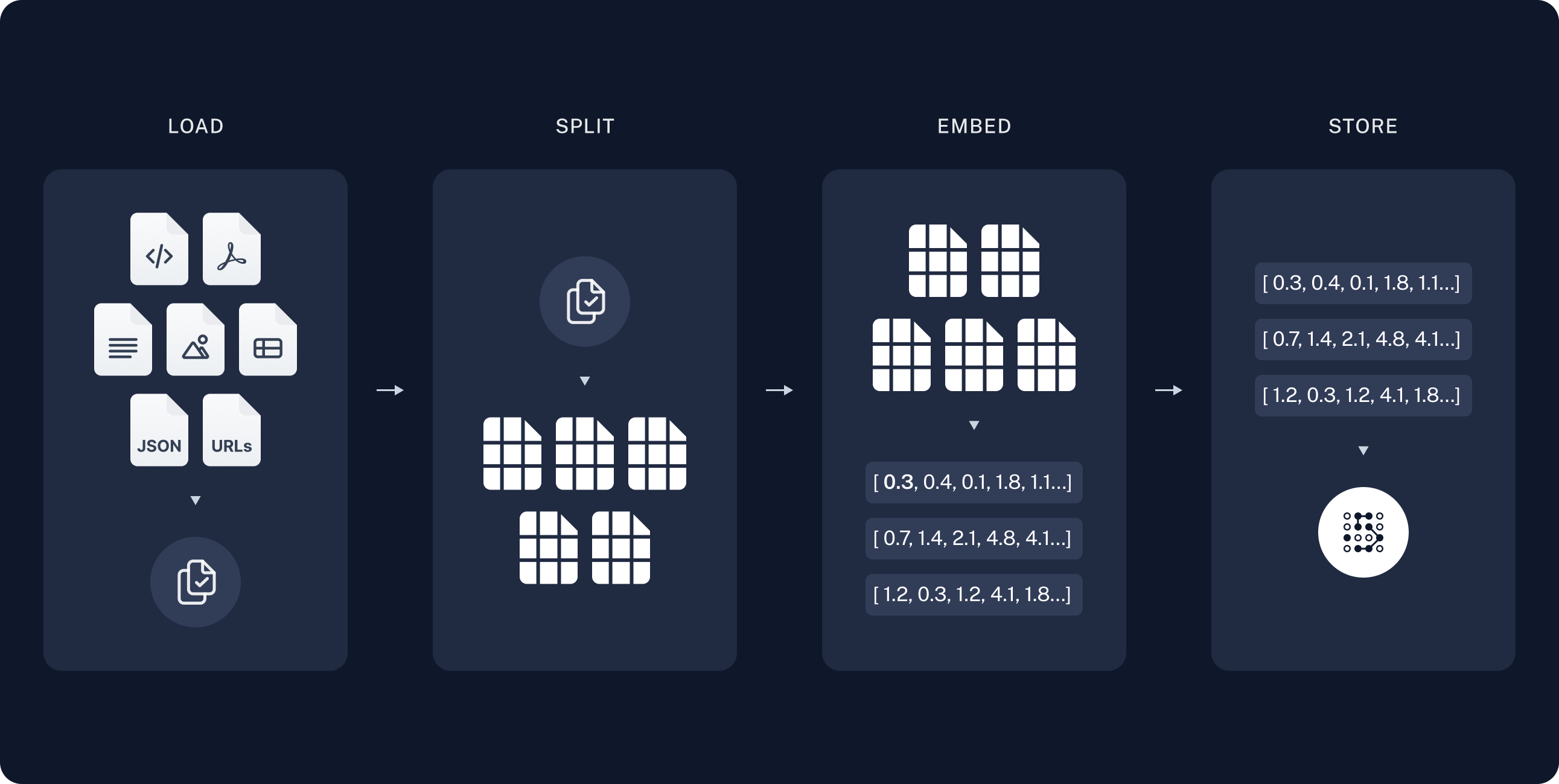
构建知识库的步骤
Loader
你会注意到,博主在文章中加粗显示了这四个步骤的英文描述,事实上,这代表了 LangChain 中的一部分概念,以 Loader 为例,它负责从各种文档中载入内容,下面展示了从文本文件、PDF 文件以及网页中载入内容:
from langchain_community.document_loaders import DirectoryLoader, TextLoader, PyPDFLoader, WebBaseLoader
# TextLoader
# 指定编码
loader = TextLoader("./input/金庸武侠小说全集/射雕英雄传.txt", encoding="utf-8")
loader.load()
# 自动推断
# python -m pip install chardet
loader = TextLoader("./input/金庸武侠小说全集/射雕英雄传.txt", autodetect_encoding=True)
loader.load()
# PyPDFLoader
# python -m pip install pypdf
loader = PyPDFLoader("./input/文学作品/追风筝的人.pdf")
loader.load()
# WebBaseLoader
# python -m pip install beautifulsoup4
loader = WebBaseLoader(web_paths=('https://blog.yuanpei.me',), bs_kwargs={})
loader.load()
当然,现实中通常会有很多文档,此时,我们可以使用 DirectoryLoader 来一次性载入多个文档:
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("./posts/", glob="*.md", loader_kwargs={}, show_progress=True, silent_errors=True)
默认情况下,DirectoryLoader 使用 UnstructuredFileLoader 这个通用的 Loader 来兼容各种格式的文件,不过,你依然可以使用 loader_cls 参数来指定 Loader 类型:
from langchain_community.document_loaders import DirectoryLoader, TextLoader
loader = DirectoryLoader("./posts/", glob="*.md", loader_cls=TextLoader, loader_kwargs={}, show_progress=True, silent_errors=True)
Splitter
调用 Loader 的 load() 方法,返回的是一组 Document 的集合。此时,我们可以将这些 Document 交给 TextSplitter 来对分本内容的分割,因为我们最终需要对文本块做向量化处理:
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
text_splitter = CharacterTextSplitter(separator = "\n\n", chunk_size = 600, chunk_overlap = 100, length_function = len)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
这里,博主先后使用了 CharacterTextSplitter 和 RecursiveCharacterTextSplitter 两种 Splitter,两者的区别是:CharacterTextSplitter 会将文本按照单个字符进行分割,而 RecursiveCharacterTextSplitter 则会将文本按照连续的多个字符进行分割。不过,经过博主的测试,两种分割方式最终对 LLM 的影响微乎其微,大家可以参照官方文档中的说明,选择符合个人预期的分割方法:
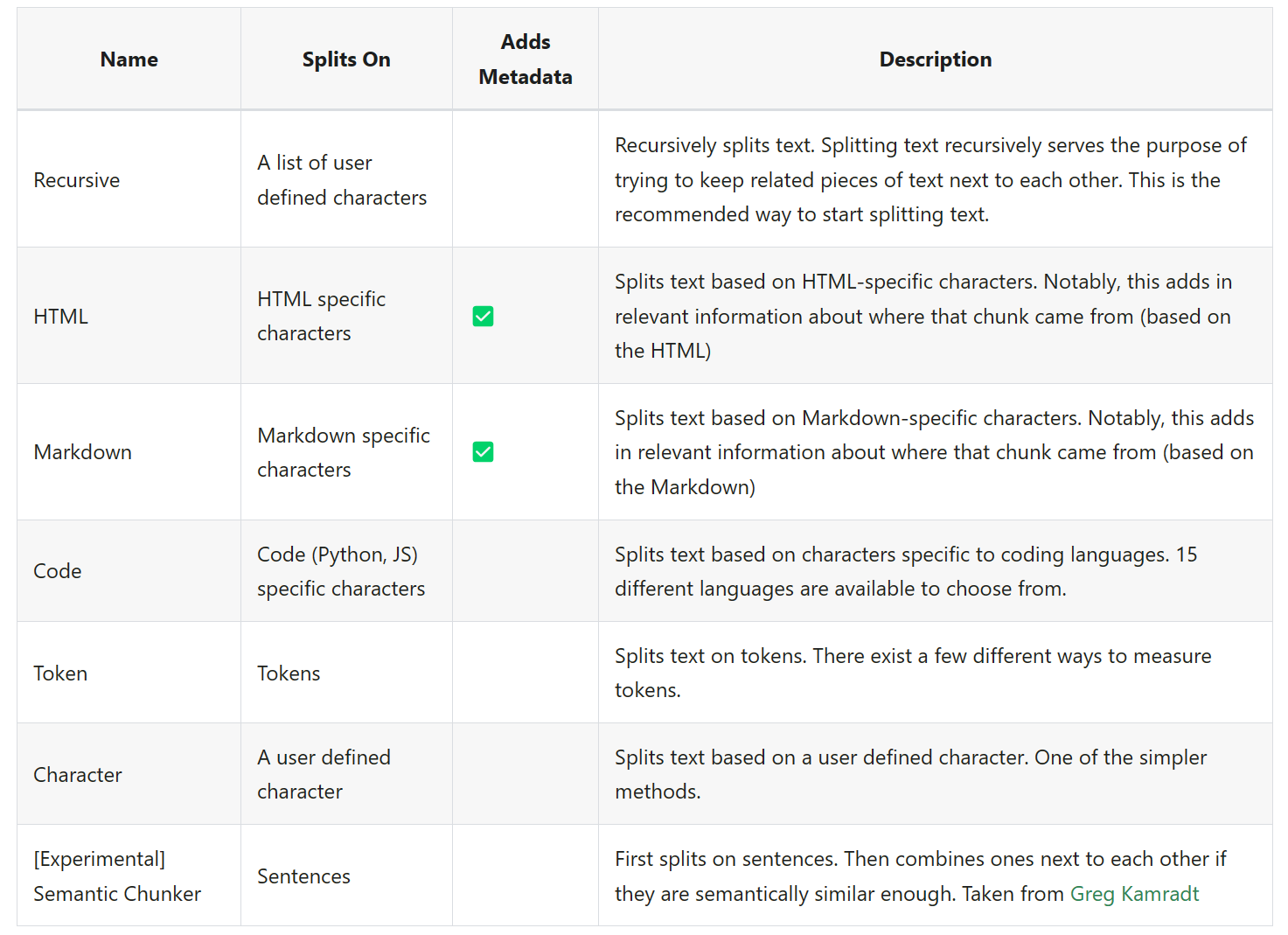
LangChain 中不同的 TextSplitter
按照一般的流程,我们只需要按下面的方式,即可完成文档的分割:
documents = loader.load()。
text_splitter.split_documents(documents)
不过,实际操作中更推荐使用 load_and_Split() 方法,两步合并为一步,更简洁一点:
documents = loader.load_and_split(text_splitter)
Embeddings
经过 Splitter 处理以后,我们将得到一系列文本块,它依然是一组 Document 集合。此时,便轮到 Embeddings 出场,它将负责将文本块向量化。这里,博主使用的是 HuggingFaceEmbeddings,首次运行它会自动下载模型文件。当然,我天朝上国自有国情在此,从 Hugging Face 下载模型的问题在 AI 的道路上可谓是阴魂不散。因此,下面演示的是,通过镜像站来下载模型的方法。考虑到,默认的 sentence-transformers/all-mpnet-base-v2 模型是英文模型,我们引入一个对中文更友好的 GanymedeNil/text2vec-large-chinese 模型:
import os
from langchain_community.embeddings import HuggingFaceEmbeddings
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
embeddings = HuggingFaceEmbeddings(model_name="GanymedeNil/text2vec-large-chinese")
# 单个句子
print(embeddings.embed_query("人生若只如初见,何事秋风悲画扇"))
# 多个句子
print(embeddings.embed_documents(["人生若只如初见,何事秋风悲画扇","等闲变却故人心,却道故人心易变"]))
当然,从最终向量化以后的结果来看,前者的向量维数只有 768,而后者则可以达到 1024。至此,我们就完成文本内容的向量化。一旦所有的文本信息都被转换为向量数据,此时,信息检索就完完全全地变成了一道数学题,由向量的余弦公式,我们可以非常容易地计算出两个向量间的夹角,这个夹角越小,则表明两个向量越相近。这就是向量相似性检索的基本原理,在此前的文章《视频是不能 P 的系列:使用 Milvus 实现海量人脸快速检索》一文中,博主曾经尝试利用这种思路来优化人脸识别效率,不知道大家是否还留下印象🙃…
VectorStore
OK,当我们将文本信息转化为向量以后,就需要考虑如何储存这些向量信息,如上文中给出的图片所示,LangChain 中支持诸如 FAISS、Milvus、Pinecone、Chroma…等多种向量数据库,以及像 Elasticsearch、PostgreSQL 这样的具备向量存储能力的传统数据库,我们可以根据自己的需求选择合适的存储方案。为了方便演示,这里我们使用 Facebook 出品的 FAISS,它不需要像 Milvus 那样准备额外的环境,使用体验上更接近 SQLite 这种嵌入式的数据库。当然,如果你比较中意于 Chroma,一切行止由心,LangChain 在自由度上拉满:
from langchain_community.vectorstores.faiss import FAISS
import pickle
# python -m pip install faiss-cpu
vector_store = FAISS.from_documents(documents, embeddings)
with open('./output/<Your-Persistence-Path>', "wb") as f:
pickle.dump(vector_store, f)
FastGPT 中创建知识库的过程,原理完全相同,它支持从文档或者网址构建知识库,最终将向量化数据存储在 MonggoDB 中,目前,这个项目使用的 FastAI 4K 模型来源不明,而 Embedding-2 模型则是来自于 OpenAI。所以,FastGPT 这个网站最大的资金消耗主要来自 FastAI,目测是一个独立训练出来的私有模型。下图展示了博主在本地构建知识库的过程,如你所见,博主使用了 263 篇博客的内容来构建这个知识库:
本地知识库构建过程
LLaMA 的再度整合
坦白讲,纯 CPU 环境下的知识库非常花时间,譬如,博主使用 1024 个维度的向量来储存金庸先生的 15 部小说,经序列化后的文件体积高达 1.2G。果然,大模型相关的一切事物都非常庞大,这或许能帮大家理解类似 7B、13B、60B…等等的大模型的本质,因为它们同样是由大量的高精度的、浮点型的向量数据构成。可偏偏就是这些对人类来说毫无意义、宛如天书一般的数字,能够从你的只言片语中“理解”你的意图,回应你的各种输入,难道你还能笃定,这一切不是某种魔法,而提示词不过是施展魔法时吟唱的咒语?从这个角度来看,RAG 是什么呢?RAG 更像是你在吟唱咒语时随手拿一本魔法书在手里,你随时可以从这本魔法书里查询资料完善咒语。
RAG 如何工作
RAG 与 Prompt
现在,我们顺着这个思路,将 LLaMA 和 LangChain 结合起来,这里的 LLaMA 指的是 llama.cpp + Qwen-1_8B-Chat,这个方案我们在上一期博客已经介绍过了,这里不再赘述。我们先来看看 Retrieve 的过程,即:如何从向量数据库中找到问题相关的内容,显然,这是 RAG 里的第一步:
with open("./output/个人博客.pkl", "rb") as f:
vectorstore = pickle.load(f)
query = 'Envoy 在微服务中的应用场景有哪些'
topK = 3
# 普通的相似性检索
result = vectorstore.similarity_search(query=query, k=topK)
# 带有分数的相似性检索
result = vectorstore.similarity_search_with_relevance_scores(query=query, k=topK)
# 最大边界相关性检索
result = vectorstore.max_marginal_relevance_search(query=query, k=topK)
这里,博主例举出了常用的向量相似性检索的方法,大家可以参考 官方文档 选择合适的方法,通常情况下,使用 similarity_search() 方法即可;可有时候向量数据库会检索出与问题相关性不强的内容,此时,就需要使用 similarity_search_with_relevance_scores() 配合某个阈值进行处理;第三种方法,我个人感觉,其返回结果的相关性不如前两种方法。还是那句话,目前博主的 AI 道路还在摸索阶段,大家酌情使用即可。
from langchain.prompts.prompt import PromptTemplate
# 定义提示词模板
PROMPT_TEMPLATE = """
You are a helpful AI bot. Your name is {name}.
Please answer the question only based on the following context:
{context}
If the question is about your identity or role or name, answer '{name}' directly, no need to refer to the context.
If the context is not enough to support the generation of an answer, Please return "I'm sorry, I can't answer your question." immediately.
You have an opportunity to refine the existing answer (only if needed) with current context.
You must always answer the question in Chinese.
Queation: {question}
"""
# 根据问题做相似性检索
question = "Envoy在微服务中都有哪些应用场景"
documents = vector_store.similarity_search(question, k=3)
context = '\n\n'.join([document.page_content for document in documents])
# 从模板创建提示词并填充模板
prompt = PromptTemplate.from_template(PROMPT_TEMPLATE)
query = prompt.format(question=question, name="ChatGPT", context=context)
RAG 中的 A 是指 Augmented,表示增强的,这个增强体现在哪里呢?答案是提示词。如图所示,在这段提示词里面,博主试图让大语言模型假扮 ChatGPT,同时告诉它按照给定的上下文来回答问题,并且要求它必须使用中文进行回答。通过这段代码,我们就可以产生符合我们预期的输入,而接下来,我们只需要将其传递给大语言模型即可。除了这种方式以外,我们还可以按 OpenAI 的规范,使用 ChatPromptTemplate 来组织提示词:
from langchain_core.prompts import ChatPromptTemplate
# 定义提示词模板
PROMPT_TEMPLATE = """
You are a helpful AI bot. Your name is {name}.
Please answer the question only based on the following context:
{context}
If the question is about your identity or role or name, answer '{name}' directly, no need to refer to the context.
If the context is not enough to support the generation of an answer, Please return "I'm sorry, I can't answer your question." immediately.
You have an opportunity to refine the existing answer (only if needed) with current context.
You must always answer the question in Chinese.
"""
# 根据问题做相似性检索
question = "Envoy在微服务中都有哪些应用场景"
documents = vector_store.similarity_search(question, k=3)
context = '\n\n'.join([document.page_content for document in documents])
# 从模板创建提示词并填充模板
prompt = ChatPromptTemplate.from_messages([
("system", PROMPT_TEMPLATE),
("user", "{question}"),
])
query = prompt.format(question=question, name="ChatGPT", context=context)
显而易见,第二种更好一点,因为它可以将问题和上下文显著地区分开来。当然,为了让 LLM 确信它就是 ChatGPT,博主在提示词工程上可没少下功夫。这其实佐证了博主一开始的观点:2023 年的提示词工程,2024 年的 GPTs,这两者并不冲突,而是一种相辅相成的关系。RAG 中的 Retrieve 和 Augmented 现在都已先后登场, 最后这个 G 自然是指 Generation,理论上剩下的工作交给 LLM 即可。可是如何你仔细想想,就会发现这里隐含着两个问题,其一是从向量数据库中检索到的信息,有一定的可能性超过 LLM 的上下文长度;其二是对上下文的约束越严格,LLM 就越显得 “弱智”,你必须要在发散和收敛中做出选择。以一言蔽之,LLM 有幻觉固然不好,可如果缺乏想象力,一切只怕是会变得更糟糕!不知大家是如何考虑这个问题的呢?
LangChain 中的 Chain
在 LangChain 的诸多概念中,Chain 或许是最抽象、最重要的哪一个,因为它就像一个管道一样,可以讲我们这篇文章中提到的各种组件串联起来。譬如, LLMChain 可以将一个LLM 和 Prompt 串联起来,RetrievalQA 可以配合 LLM 和知识库实现简单的 Q&A,ConversationalRetrievalChain 可以配合 LLM、知识库和聊天历史实现对话式检索。起初,我对于 RetrievalQA 这个类是极其排斥和反感的,因为它不论是看起来还是用起来,都像极了一个 Chain,可它就偏偏不是一个 Chain,真是奇哉怪也!
from langchain.chains import LLMChain
from langchain_community.llms import OpenAI
from langchain_core.prompts import PromptTemplate
prompt_template = "Tell me a {adjective} joke"
prompt = PromptTemplate(
input_variables=["adjective"],
template=prompt_template
)
llm = LLMChain(llm=OpenAI(), prompt=prompt)
刚刚提到,我们大体上有两种方式来将 LLM 和 LangChain 结合起来,一种是基本的 Q&A,一种是对话式检索。其中,streaming 参数用于支持流式返回,return_source_documents 参与用于控制是否返回引用的文档信息,ConversationBufferMemory 组件用于处理对话历史。下面给出具体的实现代码:
# 基本的 Q&A
def get_basic_qa_chain(baseUrl='', apiKey='', storeFilePath=''):
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0.75,
openai_api_base=baseUrl,
openai_api_key=apiKey,
streaming=True
)
retriever = load_retriever(storeFilePath)
chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
)
return chain
# 对话式检索
def get_conversational_retrieval_chain(baseUrl='', apiKey='', storeFilePath=''):
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0.75,
openai_api_base=baseUrl,
openai_api_key=apiKey,
streaming=True
)
retriever = load_retriever(storeFilePath)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
input_key="question",
output_key="source_documents"
)
chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
return_source_documents=True,
)
return chain
现在,我们就可以调用 Chain 来和大语言模型及知识库进行交互:
# 构造 Chain,使用本地模型
chain = get_conversational_retrieval_chain_("http://localhost:8080/v1/", 'sk-1234567890', './output/个人博客.pkl')
# 根据问题做相似性检索
question = "Envoy在微服务中都有哪些应用场景"
documents = vector_store.similarity_search(question, k=3)
context = '\n\n'.join([document.page_content for document in documents])
# 从模板创建提示词并填充模板
prompt = ChatPromptTemplate.from_messages([
("system", PROMPT_TEMPLATE),
("user", "{question}"),
])
query = prompt.format(question=question, name="ChatGPT", context=context)
# 方式一: 同步调用
result = chain.invoke(query)
# 方式二: 流式调用
result = chain.stream(query)
如下图所示,在经过反复地调试和优化以后,我们可以针对博客中的内容进行提问,并且程序会返回与问题相关的文档信息,这个结果整体而言还是挺不错的。当然,距离 FastGPT 这种相对完善的产品还是挺遥远的,使用 CPU 进行推理的 llama.cpp 除了生成速度慢以外,还会出现缓存 kv cache 不足的问题。庆幸的是,在折腾 LangChain 的过程中,逐渐理解了 RAG 以及 LangChain 的整体思路。在 LangChain 的 官方文档 中,官方提供了使用 LangChain 落地 AI 应用的示例,这篇文章主要参考了 RAG 这一篇,大家可以特别关注一下。
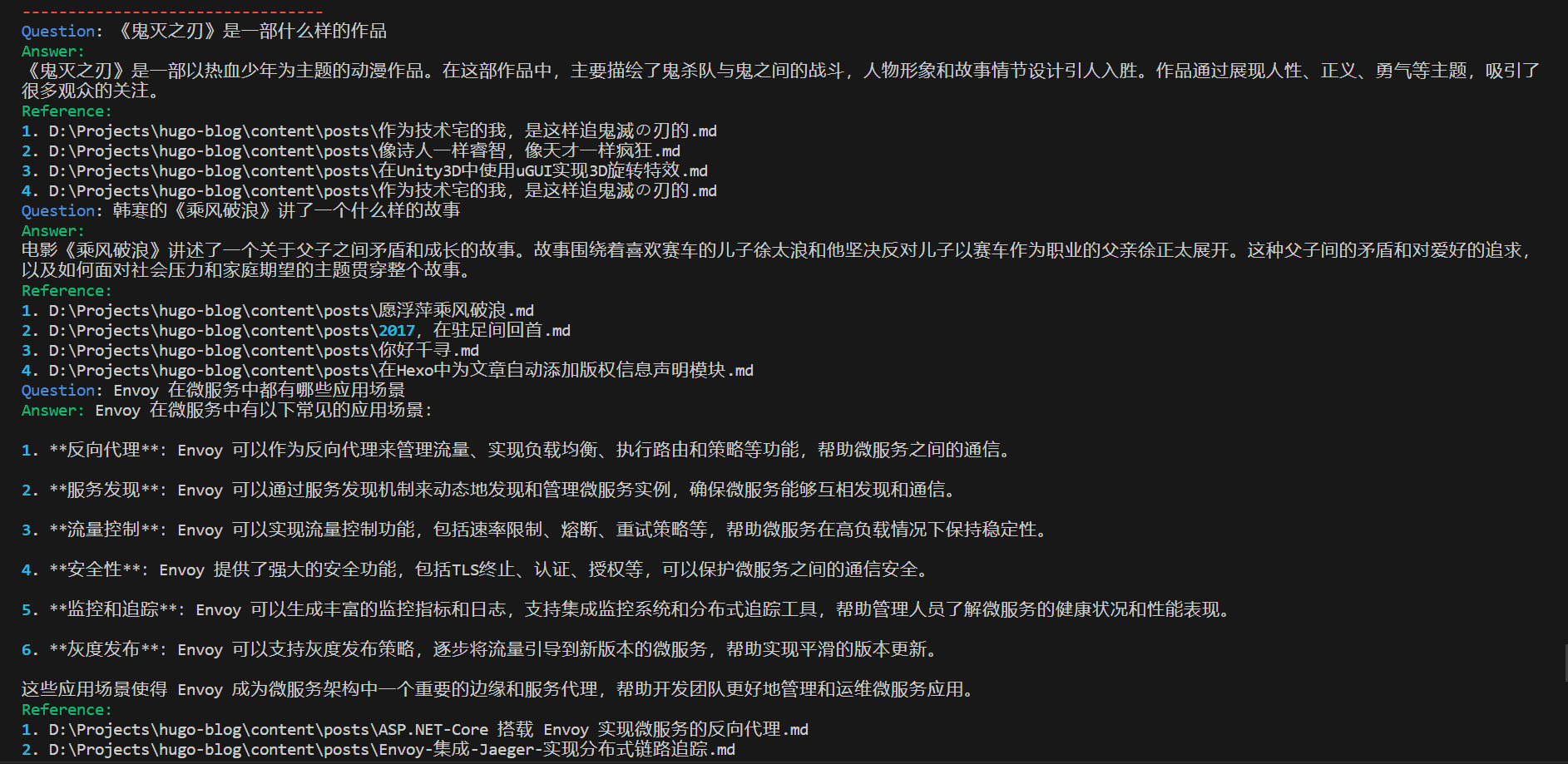
本地 AI 知识库运行结果展示
LangChain 除了概念多以外,API 变动非常频繁,经常出现破坏性的变更,而且官方现在主要在推 LangChain Expression Language(LCEL),所以,网络上的资料经常都是过期的,建议大家有时间还是去看纯英文的官方文档。当然,大家有兴趣的话,可以考虑下 LangChain 的替代品,譬如 AutoChain 和 Embedchain,它们的 API 毫无疑问都比 LangChain 简单,实际使用情况,只有靠各位自己去体验啦,哈哈!
在探索 AI 的过程中,一个令人难过的事实是:为了创作这篇大约1.5万字的文章,博主先后花了一周左右的时间来做实验,然后花了两天的时间来形成文字,而在将这些博客内容 “投喂” 给 AI 以后,它可以迅速 “描摹” 出我的轮廓。你不得不承认,这个世界的信息实在多到爆炸,以致于我们绝无可能构建出一个无穷大的知识库。AI 更像是这个复杂时代地观察者,可以帮助我们更快、更好地去理解这个世界,虽然这个代价是 AI 可能会产生更多噪音,这有一点像什么呢?就像你在看视频时开启倍速播放,或许你节省了时间、提升了节奏,可终究失去了某种身体力行的体验感,正如在这篇文章里,我使用 LLaMA 和 LangChain 实现 RAG 的过程,于屏幕前的你而言,不过是互联网海洋里鼠标轻轻掠起的浪花。对我而言,写作的整个过程,与 RAG 更是何其的相似,我在输出这篇文章的同时,查阅大量的资料,最终,它们成为了我认知、感悟以及价值观的一部分,而这,便是自我的增强。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK