

Sora「翻车」:猴子长出鹦鹉尾巴,物体学会「穿墙术」
source link: https://www.geekpark.net/news/331820
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Sora「翻车」:猴子长出鹦鹉尾巴,物体学会「穿墙术」

扭曲的翅膀,出错的数量,鹦鹉的尾巴跑到猴子身上……
「一只鹦鹉飞过青翠的哥斯达黎加丛林,然后降落在树枝上与一群猴子一起吃一块水果的俯视图;黄金时段,35毫米胶片。」这是彭博社给到 OpenAI 研究人员的提示词,后者使用这些提示词在 Sora 上创建了场景。
23日,彭博社联系 OpenAI 对 Sora 进行了测试,从结果来看, Sora还未到「黄金时段」。
在给到的四句提示语中,由于时间限制,Sora 团队只将其中两句提示词生成了视频。
问题出现了。
在时长仅有10秒的视频中,一只鹦鹉在丛林中飞翔,乍看正常,细看就会发现,鹦鹉的翅膀在飞过猴子时会扭曲,并且,提示语中之要求「一只鹦鹉」, Sora 输出的视频里却出现了好几只,并且,视频中一只猴子的臀部似乎还有一条鹦鹉的尾巴。这么看,似乎有点「翻车」即视感。
Sora生成的鹦鹉与猴子|视频来源:彭博
对此,OpenAI 研究科学家 Bill Peebles (比尔·皮布尔斯)也对彭博承认了这一点,「确实片段中到一些奇怪的动作。」
在The Verge 截取发布在TikTok上的这段由 Sora 生成的视频片段中同样可以看到一些不合理的情况,包括物体相互穿过、变形,这背后反映的是 Sora 在还不能够准确理解和呈现物体的物理特性:篮球穿过篮筐的侧面,狗在走路时相互穿过,手的形状也有点奇怪。
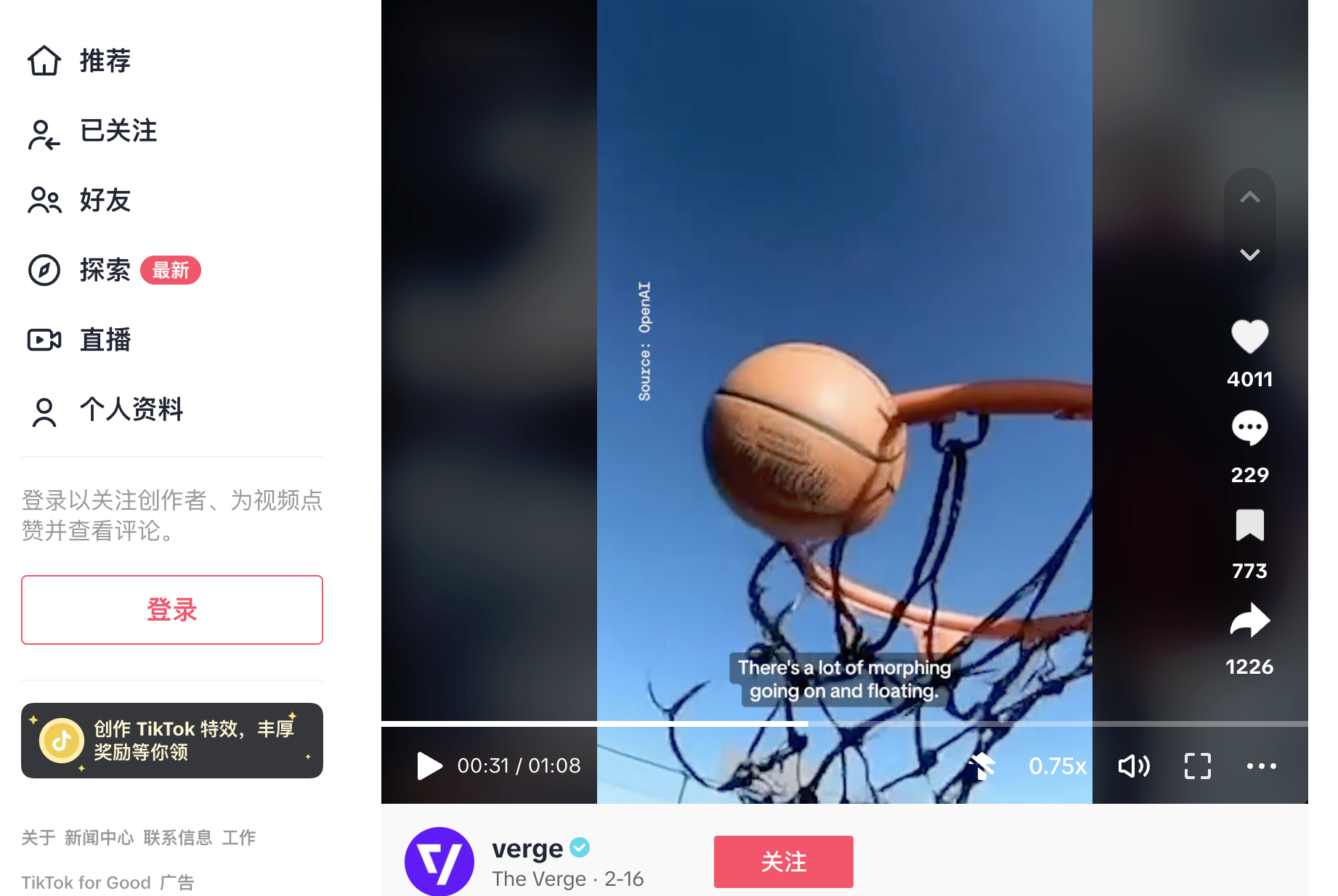
篮球穿过篮筐的侧面|图片来源:TikTok
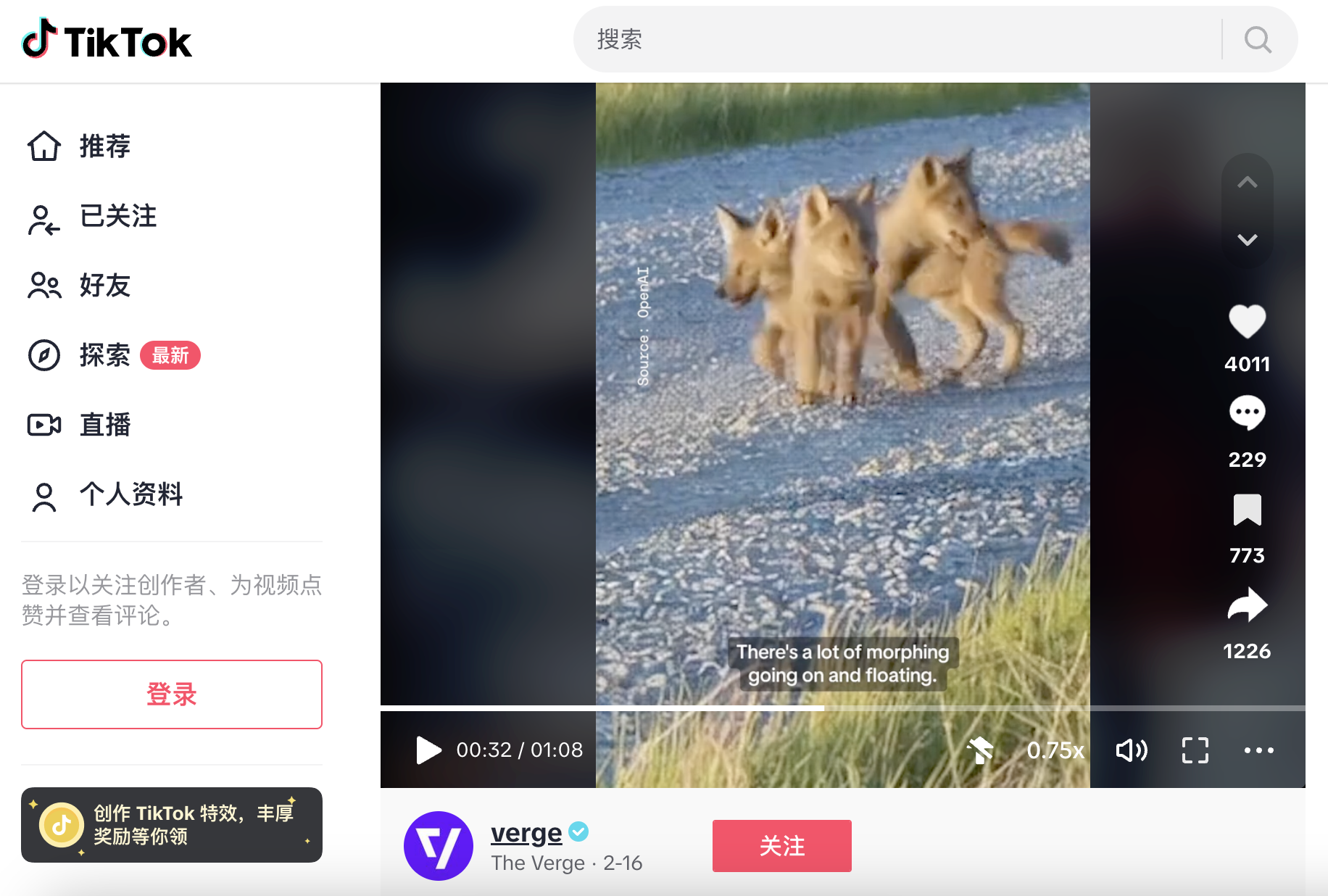
狗在走路时相互穿过|图片来源:TikTok
YouTube上也有一位博主更为详细地解析了 Sora 产出的视频中存在的问题,与The Verge展现的类似,除了狗狗似乎在互相穿过身体的那支视频,在一只柯基犬的 vlog 里,有一只海鸥飞到了相机前却又突然消失,随后画面里又出现了另一只,以怪异的方式在行走;在一个建筑工地的视频里,一辆叉车似乎可以不受周围物体的影响轻松通过。此外还有一个生日派对的场景,参与者的表情和动作看起来都有种说不出的诡异感。
看起来,虽然 Sora 可以生成出色的视频,但当场景复杂时,它可能会给出一些不符合现实场景的动作。OpenAI 官方也表示,Sora 还有很长的路要走,有很多技术挑战需要解决——包括前面提到的身体部位的杂乱问题和对物理学的理解水平。
OpenAI 在 Sora 的技术报告中指出,Sora 作为视频生成模型在模拟现实世界时面临一系列挑战和局限性。具体来讲,Sora 在技术层面存在以下主要局限:
- 物理交互的准确性:Sora 在模拟一些基本的物理交互现象时存在不足,例如无法准确模拟玻璃破碎等物理现象。
- 对象状态变化的一致性:在模拟如进食等交互时,Sora 可能无法产生正确的物体状态变化,导致视频中出现不连贯的视觉效果。
- 长期样本的连贯性:在生成较长时间跨度的视频样本时,Sora 可能会出现连贯性问题,导致视频中出现不自然的过渡或物体的突然变化。
- 物体的自发出现:Sora 有时会在视频中自发地生成物体,这些物体可能与场景不匹配或在逻辑上不合理。
- 手部和身体部位的处理:Sora 在处理手部和身体部位时存在问题,如手部可能表现得不自然或与其他物体发生不真实的交互。
- 计算资源的需求:Sora 生成视频需要较多的计算资源和时间,这限制了其在实时或快速响应场景中的应用。
- 模型的泛化能力:尽管 Sora 在某些特定场景下表现出色,但它在泛化到新场景和处理多样化输入方面可能还有待提高。
- 视频编辑和扩展的能力:虽然 Sora 能够执行一些视频编辑任务,如扩展视频或改变场景设置,但这些功能可能在复杂场景中表现不佳。
由于上述技术局限,在让外界惊鸿一瞥后,Sora 的短暂「翻车」似乎也并不令人意外。
作为一款文本转视频模型,Sora 采用了Diffusion transformer技术(包括特征提取、编码、序列组合等多个步骤)。
与大模型处理文本的原理类似,Sora将视频内容分解成一系列patch(视觉编码块),这些patch类似于视频的视觉词汇,然后,它会对这些patch进行降维处理,以便于分析和理解,在这一过程中,Sora通过去噪技术,从带有噪声的patch中预测出清晰的原始图像信息,最终合成为连贯的视频。换句话说,Sora 的训练过程类似于人类的认知过程,这一点让它极大地优化了视频生成的效果。
随着技术的突破,问题会解决。对于推新飞快的 OpenAI 来说,应该用不了很久。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK