

智能座舱算法基础之语音识别篇
source link: https://www.woshipm.com/pd/5993364.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

智能座舱算法基础之语音识别篇
近年来人工智能技术快速发展,比较引人注目的包括智能语音技术、计算机视觉技术和自动语音识别技术等。其中,自动语音识别(ASR),简称语音识别,是重要的组成部分。其主要目标是把语音信号转变为相应的文字,从而让机器具有听觉功能,能够直接接收人的口语命令,实现人机自然的交互。

语音识别是一门交叉学科,所涉及的领域有音频信号处理、声学、语言学、模式识别、人工智能等。其应用领域也非常广,涉及工业、军事、通信、消费电子等多个领域。在高度信息化的今天,语音识别技术及其应用已成为信息社会不可或缺的AI基础设施。
语音识别过程是个复杂的过程,但其最终的任务归结为:找到对应观察序列O的最可能的词序列W。主流的语音识别系统理论是建立在统计模式识别基础之上的,在统计模型框架下可以用贝叶斯公式来描述语音识别问题。
根据贝叶斯决策理论,我们的任务就是找到一个最有的单词序列W,使得它在语音观察序列O上的后验概率P(W/O)最大,即:
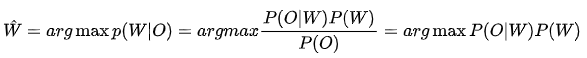
上式中,P(O|W)是声学模型概率,它描述的是一段语音信号对应的声学特征0和单词序列W的相似程度;P(W)是语言模型概率,它描述的是单词序列W可能出现的概率。
寻找最优的单词序列,即在所有可能的单词序列候选中寻找W,使其声学模型和语言模型的概率乘积P(O|W)P(W)最大。这中间包含三个问题:第一是如何遍历所有可能的单词序列;第二是如何计算声学模型概率;第三是如何计算语言模型概率。
为了解决这三个问题,典型的大词表连续语音识别(VCSR)系统采用如下图所示的主流框架:
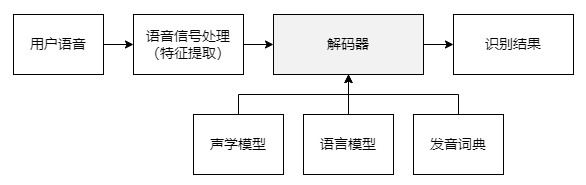
用户语音输入后,首先经过前端处理提取声学特征,得到一系列的观察向量;然后将声学特征送到解码器中进行搜索,完成所有可能的单词序列W的遍历,得到识别结果。解码器在搜索过程中,需要使用声学模型和词典计算概率P(Om),使用语言模型计算概率P(W)。
声学模型和语言模型由大量数据训练而成;发音词典根据语言学知识定义了每个单词到发音单元的映射关系。整个系统的链路比较长,模块众多,需要精细调优每个组件才能取得比较好的识别效果。
一、声学模型
人耳接收到声音后,经过神经传导到大脑分析判断声音类型,并进一步分辨可能的发音内容。
人的大脑从出生开始就不断在学习外界的声音,经过长时间潜移默化的训练,最终才听懂人类的语言。机器和人一样,也需要学习语言的共性和发音的规律,建立起语音信号的声学模型(AcousticModel,AM),才能进行语音识别。声学模型是语音识别系统中最为重要的模块之一。声学建模包含建模单元选取、模型状态聚类、模型参数估计等很多方面。

音素是构成语音的最小单位,它代表着发音的动作,是最小的发音单元。按照国际音标准则可以分为元音和辅音两大类。其中元音是由声带周期性振动产生的,而辅音是气流的爆破或摩擦产生的,没有周期性。
英语中有48个音素,包含20个元音和28个辅音;汉语普通话包含32个音素,其中有10个元音和22个辅音。普通话汉语拼音的发音体系一般分为声母和韵母。汉语拼音中原本有21个声母和36个韵母,为了建模方便,经过扩充和调整后,一般包含27个声母和38个韵母(不带声调)。另外,普通话是带调语言,共包含四声和额外的轻声。按照这五种声调,以上的38个韵母又可扩增为190个带声调的韵母。
音节是听觉能感受到的最自然的语音单位,由一个或多个音素按照一定的规律组合而成。英语音节可单独由一个元音构成,也可以由一个元音和一个或多个辅音构成。汉语的音节由声母、韵母以及声调构成,其中声调信息包含在韵母中。因此,汉语音节结构可以简化为声母+韵母,汉语中共有409个无调音节,大约1300个有调音节。
声学建模单元的选择可以采用多种方案,比如采用音节建模、音素建模或者声韵母建模等。汉语普通话比较合适采用声韵母进行声学建模,因为不存在冗余,所以不同音节之间可以共享声韵母信息,如“tā”和“bā”均有韵母“ā”。这种建模单元方案可以充分利用训练数据,使得训练出来的声学模型更加稳健。如果训练数据足够多,则建议采用带声调的声韵母作为声学模型的建模单元。对于英文来讲,因为没有声调,可以采用音素单元来建模。为了表述方便,很多文献也常常把普通话的声韵母归为音素级别。
音素的上下文会对当前中心音素的发音产生影响,使当前音素的声学信号发生协同变化,这与该音素的单独发音有所不同。单音素建模没有考虑这种协同发音效应,为了考虑该影响,实际操作中需要使用上下文相关的音素(也被称为“三音子”)作为基本单元进行声学建模,即考虑当前音素的前一个音素和后一个音素,使得模型描述更加精准。
对三音子进行精细建模需要大量的训练数据,而实际上对于某些三音子而言数据很难获得,同时精细建模导致模型建模单元数量巨大,例如,音素表有50个音素,则需要的三音子总数为:50x50x50=125000,模型参数显然急剧增加。因此,严格意义上的三音子精细建模不太现实,往往通过状态绑定策略来减小建模单元数目,典型的绑定方法有模型绑定、决策树聚下面将着重介绍三类声学模型,包括基于GMM-HMM的声学模型、基于DNN-HMM的声学模型以及端到端模型。
1)基于GMM-HMM的声学模型HMM是一种统计分析模型,它是在马尔可夫链的基础上发展起来的,用来描述双重随机过程。HMM的理论基础在1970年前后由Baum等人建立,随后由CMU的Baker和IBM的Jelinek等人应用到语音识别中,L.R.Rabiner和S.Young等人进一步推动了HMM的应用和发展。HMM有算法成熟、效率高、易于训练等优点,自20世纪80年代开始,被广泛应用于语音识别、手写字识别和天气预报等多个领域,目前仍然是语音识别中的主流技术。
2)基于DNN-HMM的声学模型尽管GMM具有拟合任意复杂分布的能力,但它也有一个严重的缺陷,即对非线性数据建模效率低下。因此,很久以前相关研究人员提出采用人工神经网络代替GMM,建模HMM状态后验概率。但是由于当时计算能力有限,很难训练两层以上的神经网络模型,所以其带来的性能改善非常微弱。21世纪以来,机器学习算法和计算机硬件的发展使得训练多 隐层的神经网络成为可能。实践表明,DNN在各种大型数据集上都取得了远超过GMM的识别性能。因此,DNN-HMM替代GMM-HMM成为目前主流的声学建模框架。
3)端到端模型传统语音识别系统的声学建模一般通过发音单元、HMM声学模型、词典等信息源,建立从声学观察序列到单词之间的联系。每一部分都需要单独的学习、训练,步骤较为烦琐。端到端(End-to-End,E2E)结构使用一个模型把这三个信息源囊括在一起,实现从观察序列到文字的直接转换。最新的一些进展甚至把语言模型的信息也囊括进来,取得了更好的性能。自2015年以来,端到端模型日益成为语音识别的研究热点。
二、语言模型
主流语言模型一般采用基于统计的方法,通常是概率模型。计算机借助于模型参数,可以估计出自然语言中每个句子出现的可能性。统计语言模型采用语料库训练得到,强调语料库是语言知识的源泉,通过对语料库进行深层加工、统计和学习,获取自然语言文本中的语言学知识,从而可以客观地描述大规模真实文本中细微的语言现象。
1)N-gram模型
N-gram统计语言模型由于其简单、容易理解等优点在很多领域得以广泛使用。
2)基于神经网络的语音模型
包括三种常见的语言模型:前馈神经网络语言模型、循环神经网络语言模型以及长短期记忆的循环神经网络语音模型。
三、解码器
语音识别的最终目的是在由各种可能的单词序列构成的搜索空间中,寻找最优的单词序列。这在本质上属于搜索算法货解码算法的范畴,即解码器要完成的任务。
1)搜索空间
语音识别寻找最优的单词序列,所有可能的单词序列候选构成了解码过程中的搜索空间。
解码的搜索空间有多种构成方式,可以分为动态编译解码空间和静态编译解码空间两大类。动态编译只是预先将发音词典编译成状态网络构成搜索空间,其他知识源在解码过程中根据活跃路径上携带的历史信息动态集成。而静态编译解码空间,是把所有知识源统一编译在一个状态网络中,在解码过程中根据节点间的转移权重获得概率信息。
2)动态搜索空间解码算法
语音识别寻找最优单词序列的问题可以转化为:在树形词典构成的搜索空间中,寻找最优状态序列的问题。这个问题一般使用维特比(Viterbi)算法解决。它的基本思想是,如果一个路径集合A中的最大概率大于另外一个路径集合B中的最大概率,则A的路径概率和也大于B的路径概率和。这个假设只能在一定程度上成立,因此会带来一定的精度损失,但是却能大大降低运算量。
3)基于加权有限状态机(WFST)的解码器
有AT&T提出的加权有限状态转换器是一种有效编译静态搜索空间并消除冗余信息的算法,它在单一网络中实现了从输入序列到输出序列的转换,现已成为语音识别中最高效的解码方法。
本文由 @ALICS 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK