

Is the "modern data stack" still a useful idea?
source link: https://roundup.getdbt.com/p/is-the-modern-data-stack-still-a
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Is the "Modern Data Stack" Still a Useful Idea?
My vote: no.

In my last issue, Thoughts Going Into a New Year, I said:
We continue to be in the deployment phase for the MDS
The modern data stack that we’ve all come to love over the past decade isn’t going anywhere; its categories are getting increasingly mature and increasingly well-integrated. Its technologies and best practices are getting more widely deployed, both to more companies and more broadly inside of companies.
This is the phase of any cycle where the real work gets done and where the real value gets created. It’s the phase for getting living in the trenches and solving real problems. The MDS was the future five years ago and it’s still the future today, but we actually have to roll up our sleeves to make the replatforming happen.
Over the last month this has been bugging me. I don’t know if you’ve ever had that nagging feeling after writing something that just doesn’t feel right, but writing this knocked something loose in my head. Since then, I’ve become a little obsessed with the question: what’s going on with the modern data stack?
I became increasingly confident that something had changed. Sure, it was easy to point to the superficial changes. But I felt like there was a more interesting narrative to tell, and as both a historian of this technology wave and a founder responsible for navigating it, I wanted to nail this down. I caught up with a bunch of folks I respect, from founders to practitioners to VCs, and want to use this newsletter as a way to share my current thinking. I can’t share all of my datapoints on the current state of the world (many of them are proprietary) but I’ll share as much as I can.
Let’s start at the beginning.
The Modern Data Stack was an idea…
In 2016, the modern data stack was a well-defined idea.
It was never an industry or a software category or a Gartner Magic Quadrant. When the data community started using this term it simply meant a set of products that a) redesigned the analytics workflow to take advantage of the cloud and b) all interacted with one another via SQL.
Looker was one of the classic examples. BI built for Redshift, taking advantage of the inherent performance and scalability improvements native to that platform. The idea that you could have a mature BI solution without any local processing or caching was novel in 2013.
Fivetran and dbt are also classic examples. The cloud meant that ETL should be rebuilt as ELT, which created a dramatically new, lower-cost, lower-friction, more accessible way of doing this critical, but traditionally very painful, data work.
The MDS: analytics products, designed to take advantage of the cloud, interacting via SQL.
In 2016, when I started talking about this, the fact that a product had been designed to take advantage of the cloud was important. It created massive differentiation for those products—many ran circles around pre-existing products because they were built from scratch with totally different priors.
When I was a consultant, helping small companies build analytics capabilities, I would only work with MDS tooling. It was so much better that I simply wouldn’t take on a project if the client wanted to use pre-cloud tools. I, and others like me, needed a way to talk about this preference, to differentiate between these new products and all of the other ones that we didn’t want to use. The term actually conveyed important information.
…that has now outlived its usefulness.
Today, most data products are built for the cloud. Either they have been built in the past ten years and therefore baked in cloud-first assumptions, or they have been re-architected to do so.
Another of my posts from 2016 compares Looker and Tableau, and criticizes Tableau for not being able to effectively process certain types of data (particularly clickstream data). This was true…in 2016. Tableau’s Redshift integration back then was quite bad; the SQL that it wrote was not at all performant on large datasets. This should not be surprising because nearly all data processing in Tableau happened via local extracts at the time. Tableau on top of clickstream data wasn’t really a thing, as prior to Redshift almost no BI tech could handle clickstream data and users didn’t expect this.
So: in 2016, differentiating between Looker (MDS) and Tableau (pre-MDS) was useful. But 8 years later, with the explosion of data processing happening in the cloud, Tableau has evolved. I’m sure it wasn’t easy for the Tableau team to go on its cloud journey, but it is one that most pre-cloud data companies have gone through. I have talked to the founders of so many of these companies and “migrating to the cloud” is almost always this harrowing bet-the-company march through the desert. But it’s so existential that everyone does it anyway (or dies trying).
So—does that mean that Tableau “joined the modern data stack” once it improved its cloud-native capabilities? Not…really? I don’t think anyone would say “Tableau is a modern data stack company.” But then…what information is the MDS designation really conveying at this point? The useful information content that existed in 2016 is no longer present.
Of course, as with many ideas, we didn’t stop using the term just because it stopped conveying the same information content. Instead, the MDS morphed from a descriptive term into a meme.
The meme-ification of “modern data stack”
I worried we had hit peak MDS when I went to big investment banker conference and a very senior banker said something like “the market can’t get enough of all of these modern data stack companies!” I was confused, because a) I was in the community that coined that term, and b) there were no publicly-traded MDS companies I knew of aside from Snowflake. So, I asked him what companies he was referring to. He mentioned Mongo, Datadog, and Confluent.
Now, all of these are great companies that I look up to and respect. But…these are not “modern data stack” companies as far as I understood the term.
What had happened here is that, circa 2021, the MDS had officially jumped the shark. From 2020 to 2022, the meteoric rise of Snowflake and Databricks and a few other companies had caused (mostly private market) investors to go all-in on this market trend in a way that very rarely happens. And so being a “modern data stack” company was valuable. Just like an index fund needs to hold a certain % in each stock in the index, every VC needed exposure to the MDS trend. And this euphoria bled into public market investors who sought out whatever exposure they could get.
But it wasn’t just about investor sentiment. Investor sentiment was driven by real adoption trends, and in turn drove press interest, and then further customer awareness and adoption. The number of enterprise CDOs who woke up to the MDS in that 3-year period was incredible, and it was driven by this cycle of early-adopters > investors > press coverage > more adopters.
This is not a bad thing! This is just how enterprise tech works. But along the way, the phrase lost its attachment to the underlying information it was conveying. It was no longer describing some specific trait that products like Looker and Fivetran and dbt had and others didn’t, it was just…a meme. A market trend.
And once a trend gains momentum, it can become self-fulfilling.
Eventually: an ecosystem
Imagine it’s 2021, peak MDS, and you meet the CDO of a large bank. “Oh cool,” she says, “you’re the CEO of a tech company. What does your product do?” What do you say?
“We build a tool that leverages the power of the cloud to apply standard SQL and software engineering best practices to the historically mundane (but critical!) job of data transformation.”
“We’re the standard for data transformation in the modern data stack.”
I will tell you that, empirically, option #2 is more effective. And that wasn’t just true for me, it was likely true for every founder building products in the space. Investors and buyers both understand what you meant faster and better if you relate your product to trends they are already familiar with.
So once the MDS had become a part of the lexicon for VCs and CDOs and bankers, founders had every reason to claim the moniker for their own products. This isn’t a problem (or a conspiracy!), this is just how capitalism and ideas work.
This is when the vendor ecosystem in the modern data stack reached peak collaboration. The end-to-end problem was far too big for any one startup to solve, and so swim lanes were established and partnership ruled the day.
There was a lot of valuable co-marketing, partnership deals, co-sponsored events, and co-selling. This had real value for everyone involved—customers and vendors alike. Companies voluntarily integrated their products together, cross-promoted each other publicly, and built partnerships that made owning and operating these technologies far easier for customers.
And, with clearly defined swim lanes and a need to create ‘better together’ stories to sell a complete solution, companies had a real route to market for their products as a part of this industry trend. If you built something great that solved problems for both partners and customers, you could get initial traction with partner-led sales pretty easily.
This was a beautiful thing. Private capital fueling founders, who not only built their own products but were consciously coming together to build an ecosystem, leading to the rapid buildout of interoperable products all taking advantage of a new technology platform (the cloud).
But eventually the party stopped, and it stopped for two reasons:
The changing market environment impacted both buyer and investor behaviors
AI crowds out the MDS as the primary industry trend in data
The market shifts
The market shifted in two ways: investor behavior changed and buyer behavior changed. Simultaneously. One of these things changing is disruptive; both of them changing at the same time is enough to reshuffle the whole deck.
On investor behavior: modern data stack companies were getting epic valuations up through EOY2021 / into early 2022. dbt Labs was certainly a part of this! At the peak, valuations reached 100x forward ARR. Investors said: estimate what your annual recurring revenue will be in 12 months, multiply that by 100, and that’s how we’ll value the company. That is historically aggressive. It reflects not only the belief in the MDS market trend on the part of investors, but also the very real search for growth on the part of investors during the zero interest rate era (ZIRP).
As inflation climbed and interest rates adjusted upwards very quickly during 2022, the market reset. Private multiples are now more like 10-20x forward revenue, so dropping 80%+.
Basically all MDS companies were/are VC-backed. And when valuations are high, companies have the capital to invest in sales, marketing, R&D, community teams, everything. With plenty of capital, partnership teams are large, everyone has bandwidth to do comarketing events, and there are engineers to build integrations.
As capital becomes scarce and efficiency is in the crosshairs, companies cut all but the most essential activities. Even if every MDS company were long-term healthy, much of the ecosystem dynamic dies without these investments. Companies put their heads down and focus on the fundamentals.
Changes in buyer behavior are at least as impactful. CFOs took a scalpel to data budgets, looking to save money on both headcount and software spend. The euphemism “cloud optimization” has been used extensively over the past ~18 months on earnings calls to describe this behavior, and it’s often the smallest companies with the most nascent products that get cut first. Even in customer relationships that lasted through this period, many experienced reduced contract sizes as layoffs impacted many, many data teams.
All of this hurt growth for all software companies, and it hurt the smallest ones the most. These companies had the smallest balance sheets, smallest customer lists, just generally the least resources to weather the storm. Some of these companies have gone away already; some live on but are shells of their former selves.
Companies in the top quartile are still significantly impacted. Where they may have all once felt they had a clear path to long-term independence, many are now questioning that. They’re doing fine, but wondering what their 5 year path looks like.
Even the most financially successful few companies in the MDS (and I’d count us as one of them) likely had a challenging year last year amidst all of these changes. All of us have retooled for growth in a different environment but are fortunate to have strong product-market fit in important categories—this has allowed us to make these adjustments and come out the other side strong.
Finally, as a result of all of this pressure on data spend, buyers developed a strong preference to buy integrated solutions rather than to buy many tools to construct a stack. Buyer willingness to construct a stack from 8-12 vendors has declined significantly. Companies are much more likely today to expect to buy 2-4 products as the core of their analytics infrastructure. This creates yet more pressure for consolidation, and will likely drive more M&A activity and competition across the vendor landscape.
Overall: what once was a collaborative modern data stack ecosystem full of startups and growth and comarketing and event sponsorships has been supplanted by a bunch of companies focused on executing and where partnerships are still important but only when they have clearly-demonstrated ROI.
This is all very natural, and long-term for the best! But the vibes, they are a-changin’.
AI becomes the new hot thing
A market trend is only as relevant as the attention it commands and the investor behavior it drives.
The MDS was a big, important market trend. But AI is bigger. A lot bigger. And it’s hard for data investors and data buyers to focus on too many trends at once.
This means that, even though AI and the MDS are highly complimentary, the massive attention being paid to AI right now detracts from the MDS as an industry trend. This is just a fact. You can likely see this in your own experience over the last couple of years, and it shows up in a million ways in my day-to-day.
And you know what? I’m more than ok with that. It’s fun to be at the center of the world for a little while. But at the end of the day what matters isn’t your Google Trends ranking, it’s whether or not you’re impacting real people, whether you’re building a lasting business. Being out of the spotlight is helpful: it’s grounding, focusing.
Moreover, this ‘turning point’ is a core feature in the process of developing new technologies. From Carlota Perez’s framework that I cite frequently:
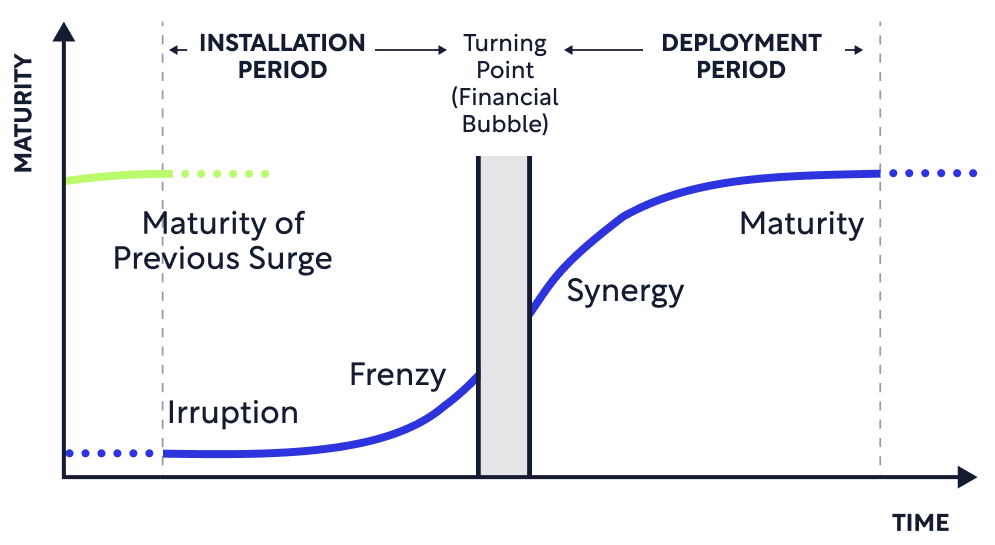
I won’t go through a review of the entire framework and the role of the ‘financial bubble’ in the process (this post is already long!) but IMO what we’ve experienced over the past year is pretty classic.
The lifecycle of “modern data stack”
Over the course of ~7 years, “modern data stack” went through a cycle: from descriptive technical term to meme / market trend to ecosystem. Today, IMHO, it’s no longer useful in any of those roles. Today, I’m swearing off using the term “modern data stack” and I think you probably should too.
It turns out, you just don’t need it.
dbt still does data transformation. Fivetran still does data ingestion. Looker still does BI. Each of these products (and more) are all leading players in the analytics stack.
See? Not so hard! We help people do analytics. Our products are bought from analytics budget lines. Analytics is both a profession and a source of business value creation.
Calling our ecosystem the “modern data stack” is continually fighting the last war. But the cloud has won; all data companies are now cloud data companies. Let’s move on. Analytics is how I plan on speaking about and thinking about our industry moving forwards—not some microcosm of “analytics companies founded in the post-cloud era.”
There are some interesting implications of this reframing, and they’re healthy. For one: it makes the pond bigger. It makes it clear that, whenever you were founded, you’re competing with the leaders in your space, new or old. If you do BI, you’re competing with Tableau and PowerBI, and you need to win on that stage.
It also grounds us all more firmly in the history of the analytics space. Yes, the cloud changes a lot about the way we work with data, but it doesn’t blow up everything from the pre-cloud era. Many practitioners who have started their careers in the past decade (and many vendors!) have some very pre-cloud lessons to (re-)learn. I’ve already started to revisit/refine some of my long-held beliefs and it’s been a very productive headspace. More on that in a future issue.
My goal in writing this isn’t to spark some linguistic change throughout our little community. I’m not going to become some anti-MDS grump on Linkedin. The point isn’t the words, really, it’s the fact that the underlying reality has changed. So: whether or not you continue to say “modern data stack”—the world in which that phrase rose to prominence just doesn’t exist any more.
That’s ok! All of this is really a side story to the very real benefits that a set of technologies and workflows have created for very real practitioners and their employers. But I as a long-time observer of this space, I find it fascinating.
This newsletter is sponsored by dbt Labs. Discover why more than 30,000 companies use dbt to accelerate their data development.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK