

中文创意写作能力超GPT-4,「最会写」的中文大模型Weaver来了
source link: https://www.51cto.com/article/781083.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

中文创意写作能力超GPT-4,「最会写」的中文大模型Weaver来了
ChatGPT 等通用大模型支持的功能成百上千,但是对于普通日常用户来说,智能写作一定是最常见的,也是大模型最能真正帮上忙的使用场景之一。尽管大模型经常能写出看起来像模像样的文字,但是大多数情况下内容的创意程度和文风都经不起深究。尤其是在创作领域,大模型常见的 “GPT 文风” 更是让利用大模型进行创意写作看起来简单,实际却困难重重。
近日,波形智能的大模型团队发布了一款专精 AI 写作的专业大模型 Weaver。通过写作领域专业预训练和一套创新性的数据生成和 Alignment 算法,Weaver 在写作领域的各种任务上均取得了领先 GPT-4 和众多中文通用大模型的效果,尤其是在生成内容的创意性和文风质量上大幅领先,是一款更能写出 “人话” 的大模型。

- 论文地址:https://arxiv.org/pdf/2401.17268.pdf
- 在线 Demo:https://www.wawawriter.com/
ChatGPT 等大模型在通用指令跟随和问答任务中效果出色,但是将大模型应用于专业写作,尤其是需要创造性和个性化文风的创意写作领域却依然面临重重阻碍。其中最大的问题就是大模型生成内容风格过于平淡,或者说文风过于 “GPT”,缺少创造性。
为了解决这个问题,训练出更适合专业写作的大模型,波形智能的研究团队分析了为什么 GPT 和其他通用大模型都做不好创意写作类任务。首先,通用大模型的预训练过程,因为希望让模型在更多的数据中自监督学习,预训练的数据集中常常会包含非常多的低质量内容,真正由专业作家和内容创作者写作的高质量文本内容可能只占预训练数据总量的 0.1% 不到。因此,经过预训练后的语言模型在建模了整个互联网的文本分布之后,自然会倾向于输出较为普通的内容。而在模型的对齐阶段,OpenAI 等公司众包标注指令微调数据集的过程中的标注员的教育 / 写作水平有限,没有对标注者的写作 / 创作能力进行筛选。另外标注的过程中的标准也主要强调回答的无害性 (harmlessness) 和有效性 (helpfulness),而没有考虑回答内容的创造性和语言 / 写作风格。因此,经过指令微调的语言模型反而更容易生成平庸无趣的文字。最后,在 RLHF/DPO 等 alignment 算法中,模型的训练数据和 Reward Model 均由经过指令微调后的模型生成或训练得到,因此对于文风和创造性上,RLHF/DPO 的过程也只能是 “矮子里拔将军”,无法强化出真正擅长写作的大模型。
基于此观察,波形智能的大模型团队提出了一个尤其适合创意写作领域的垂域专业模型训练 pipeline,并基于此方案训练了 Weaver,一个全球领先的创意写作大模型。该方案覆盖了模型的 (持续) 预训练,指令微调 (instruction tuning),和对齐 (RLHF/DPO) 阶段。在预训练阶段,团队进行了非常仔细的数据筛选和过滤,利用人工 + 规则 + 机器学习模型协同的方案,从开源预训练数据集中找到了高质量的小说 / 短故事 / 创意文案等类别的文本内容,舍弃掉了大量的低质量内容和代码 / 广告等数据,并下采样了一部分高质量的新闻数据,同时结合了大规模的私有创作领域数据 (小说,短故事等),构建出了超过 200B 的可以让模型专注学习创作能力的预训练数据。
在指令微调阶段,波形智能的数据生成团队参考并改进了 Meta 提出的 LongForm 和 HumpBack 方案,构建了一套可以基于一段高质量内容,自动生成各种写作相关任务指令和对应的高质量输出的 Instruction Backtranslation 流水线。团队总结并定义了 “写内容”,“写大纲”,“扩写”,“润色”,“精简”,“风格迁移 (仿写)”,“审校”,“头脑风暴”,“起标题”,和 “写作相关对话” 十个类别的任务。对于一类任务,如 “润色”,标注 Prompt 中首先解释任务的定义和几个输入输出样例,之后给出一个从一段文本中自动挖掘润色任务指令 / 输入 / 输出的例子和标注的思考过程: “首先在文本中找到一段写的很好的句子,假设这句话是经过一次润色而来的,之后猜测在润色之前这句话会是什么样子,最后分析润色前后的变化,推理出润色的指令会是什么样子。” 之后标注的 Prompt 中输入需要标注的例子并指示大模型按照例子中的标注流程进行输出,最后 parse 出模型输出中标注的 “指令 / 输入 / 输出” 部分,组合成一条写作指令数据。
相比 OpenAI 等公司的标准众包标注指令数据的流程,波形智能的标注策略更高效 (众包标注者只需要挑选特定领域高质量的内容即可,后续标注流程由 AI 完成),而众包标注和目前常用的 self-instruct 类的全自动标注流程相比,波形智能的标注流程能够生成更高质量的数据 (因为输出是手工挑选的高质量内容或其中的一部分)。基于这个策略,波形智能的大模型团队收集了涵盖小说写作,创意写作,专业写作,营销文案写作这四大领域中高质量的内容并进行了自动化标注,产出了 100 万 + 高质量的写作领域指令微调数据集。
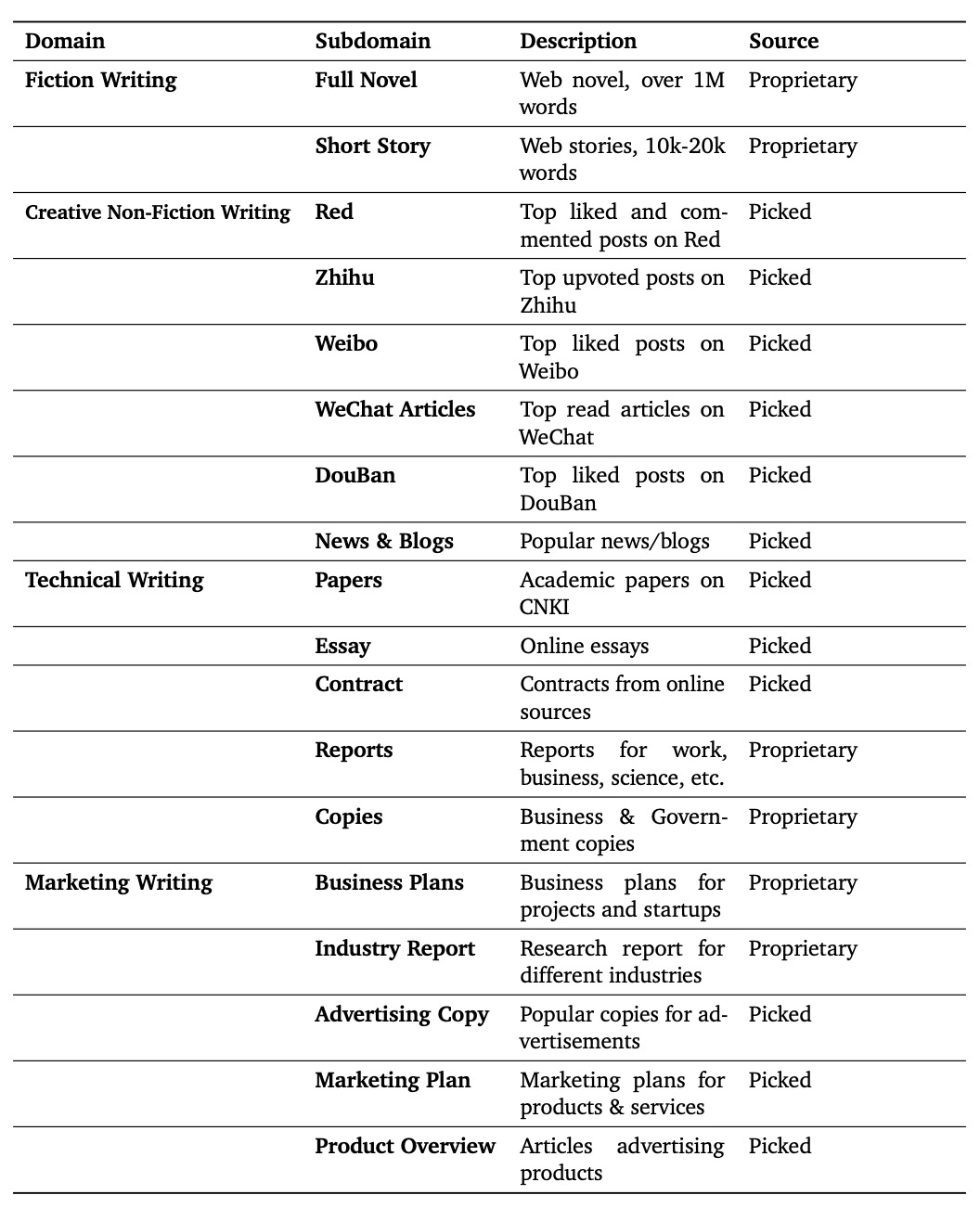
图 1: Weaver 训练数据分布和来源
接下来,在对齐 (Alignment) 阶段,波形智能的数据生成团队提出了 Constitutional DPO, 一套全新的,基于原则高效将模型和专业作家 / 创作者对齐的方案。和以往基于模型输出 + 人类 / 大模型评估的对齐策略不同。Constitutional DPO 以人类创作者创作的高质量的输出作为正样本,利用人类作家 / 编辑整理提炼出的各个领域写作的 “原则 (Principles)”,用这些原则去生成能够教会模型更好地遵守这些原则的负样本。具体来说,专业作家 / 编辑首先整理出四大领域十个任务中,好的内容需要遵循的共 200 余条原则。对于每一个原则,编辑总结出原则的详细解释和一对符合 / 违背该原则的例子,并用几句话解释出符合 / 违背原则的原因。之后,对于每一个正样本,负例生成的 prompt 中首先展示出领域 - 任务上的原则集合和原则对应的例子和解释,之后展示出正样本,要求大模型分析出正样本最符合哪几条原则,并推理出如何修改能够在作出较少改变的情况下让正样本转而违背这个原则,从而变成一条质量没那么好的输出。团队精选了各个领域高评分 / 高阅读量 / 高点赞评论数的内容作为正样本,通过 Consitutional DPO 的流水线生成出了数万条偏好数据 (preference data),并利用这些数据对模型利用 DPO 进行了对齐训练。
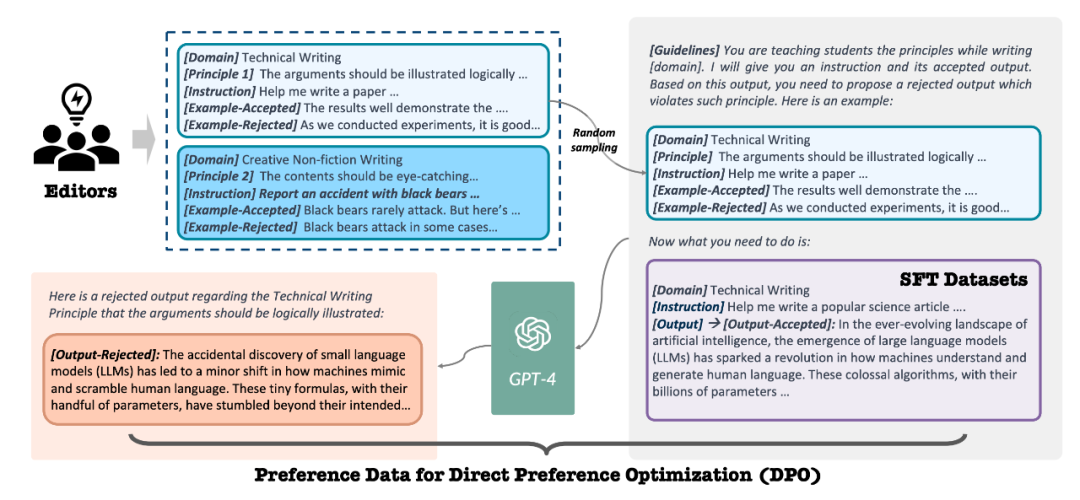
图 2 - Constitutional DPO 方法示意图
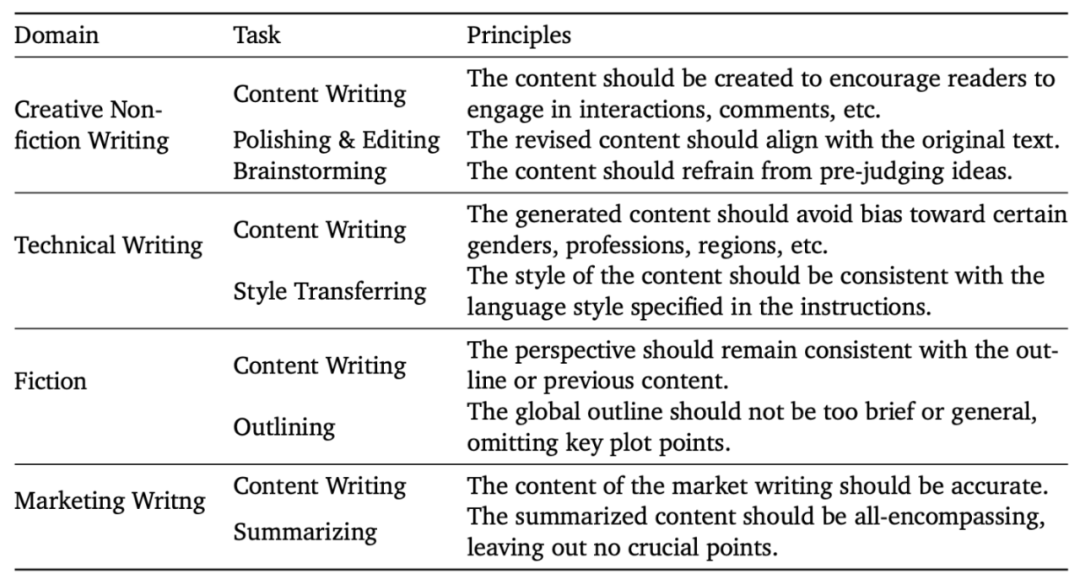
图 3 - 专家标注的写作原则
除此之外,波形智能的数据生成团队还设计了一套支持 RAG-aware training 的数据生成方案,过滤 / 精选出了一系列输出内容明显基于其他内容的样本,通过 10 余个常用的 RAG 模版,构造出了 10 万余条的 RAG 训练数据,使得 Weaver 模型能够原生支持 RAG,能够结合参考文献和范文进行高质量的创作 / 仿写。除此之外,团队还设计了一套让 Weaver 支持 Function Calling 的数据生成方案。最终 Weaver 的微调数据量总和达到了 100 万 + 量级。
Weaver 模型家族一共包括四个不同大小的模型,名字叫做 Weaver-mini/base/pro/ultra, 分别包括 18 亿,60 亿,140 亿和 340 亿参数。为了评估 Weaver 模型和通用大模型的写作能力,波形智能的模型评估团队构建了一个新的用户大模型专业写作能力评估的 Benchmark。Benchmark 中精选了涵盖四大写作领域 30 余个子领域的十项写作任务的有代表性指令,共包含 2000 + 条指令。团队收集了 Weaver 和 10 余个有代表性的开源 + 闭源模型在 Benchmark 上的输出,并分别进行了人工对比评估和基于 GPT4 的自动评估。
评估结果显示,Weaver Ultra 在 Benchmark 中对生成内容的新颖度和文风的评估中对比包括 GPT-4 在内的通用大模型均有显著领先,在生成内容的流畅性和切题程度上也和行业领先的 GPT-4 相当,领先其他开源 / 闭源模型。而其他较小的 Weaver 模型也都在各项指标中相比大 2-3 倍的通用大模型有明显优势。
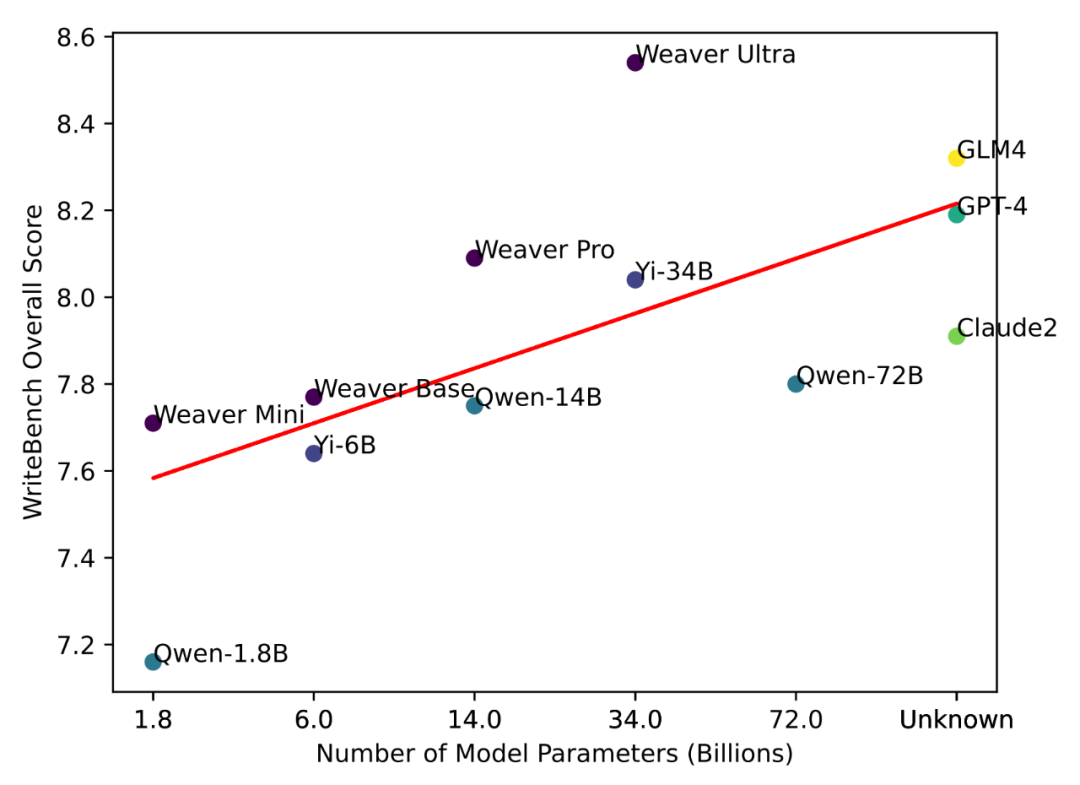
图 4: Weaver 在 WriteBench 的评测结果
除了标准 Benchmark 的人工和自动评估以外,波形智能的模型评估团队还在包含人机交互的实际应用场景中对 Weaver Ultra 和 GPT-4 进行了用户体验测评。由 4 位人类写手在同样的 Chat Interface 分别使用 Weaver Ultra 和 GPT-4,以相同的主题分别创作一个短故事,一个小红书文案,一个商业计划书,和一个课程论文。测评结果显示,人类写手利用 Weaver 进行创作的效率相比使用 GPT-4 提升了约 40%,而专业编辑对创作内容的质量评比中也以 9:3 的比分更倾向于采用 Weaver 创作的文案。分析显示,Weaver 带来的效率提升主要来自于生成内容的文风更得体,需要的后编辑更少,以及创作过程中 Weaver 交互更加直接,不会输出无用的废话和疑问。而来自专业编辑的反馈主要集中在基于 Weaver 创作的作品风格往往更符合实用标准,以及创作的内容个新颖程度更高,不死板。
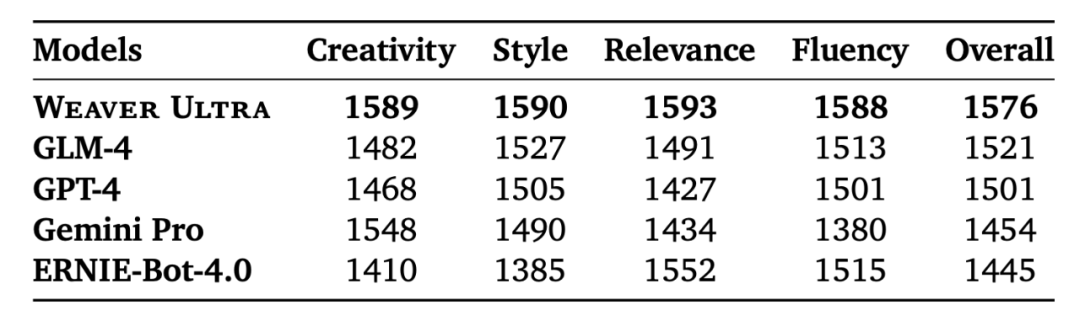
图 5: Weaver 和其他大模型在人工评测中的 ELO Rating
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK