

基于RAG架构搭建医疗智能问答系统(一)
source link: https://www.woshipm.com/pd/5989372.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

LLM大语言模型的出现,让许多系统或产品都有了更大的构建空间。这篇文章里,作者就介绍了自己基于主流的RAG架构搭建一个医学智能问答系统的过程,一起来看看本文的梳理和解读。

医疗智能问答是一个比较经典的医疗应用场景,在该场景下用户首先在对话系统中描述自己的症状,然后问答系统会根据输入的信息回复初步的医学建议。
传统实现方法如规则引擎和知识图谱等由于缺乏对语境和语义的深层理解,导致无法处理过于复杂的问题。随着大语言模型(LLM)的出现,医疗智能问答系统处理更加复杂的语境以及更加准确的结果输出有望实现,所以笔者决定尝试基于当前主流的RAG架构搭建一个医学智能问答系统。
一、产品目标
打造一个基于智能问答系统的“数字全科医生”
这里“全科医生”不是“全能医生”的意思,全科医生一般是指在基层医疗机构(如社区卫生服务中心、乡村诊所等)工作的医生,全科医生通常承担着基层的基础医疗服务,笔者对这个系统的定位是可以提供一些初步的诊断、患者教育和科普功能,而不是用它提供治疗方案(能力边界)。
具体可以拆分以下几个子目标:
- 能根据用户输入的信息,初步诊断是否存在病理性的因素以及可能的病因;
- 能提供非治疗方案的建议,如生活方式干预、引导去医院做进一步的检查等;
- 尽量降低错误率,做到“宁缺毋滥”;
- 尽量避免提供直接的用药方案指导或者治疗方案。
二、RAG架构及其工作流程
RAG(Retrieval Augmented Generation)通常翻译为检索增强生成,所以它的核心是“检索”,用户在使用LLM回答问题之前先“检索”外挂知识库的信息,然后将检索到的信息提交给LLM,LLM在“学会”匹配的知识库的内容之后再去生成回答,这样就可以有效减少LLM“幻觉”现象。

RAG工作流程大致如下:
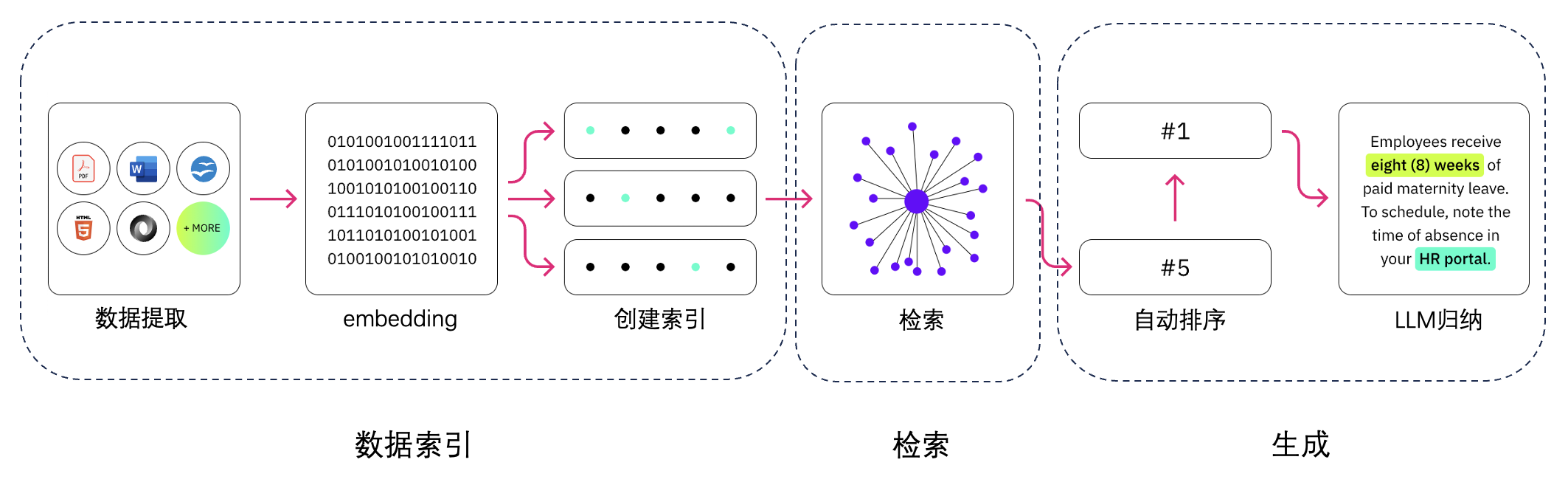
第一步:创建知识库
- 首先要对获取的数据做基础的清洗保证质量;
- 然后系统对数据进行“分块”(Chunk)处理,通常较小的文本片段可以使RAG系统更快、更准确地发现相关上下文;
- 再进一步就是将这些Chunks转换成计算机可以理解的数据也就是向量化(Embedding);
- 最后将获取的向量信息存储在向量数据库(Vector DB)中备用。
第二步:检索信息
当用户输入问题时,首先会对输入的“问题”向量化,然后在向量数据库中查询匹配的结果,通过排序规则对结果进行再次排序(Rerank),最后返回最匹配的结果。
第三步:生成结果
系统将匹配的Chunks数据通过设计好的提示(Promopt)模板传递给LLM,LLM基于基于输入的Chunks润色加工后返回问题的答案。
PS:这里只是简单的介绍一下RAG架构的工作流程,实际项目中每一步都包含很多优化策略和配置参数,比如Chunk的大小选择,Embedding模型的选择以及Rerank的规则等,在后面介绍模型优化环节时,将会结合具体问题分享自己的优化思路。
三、基于FastGPT搭建基础问答系统
FastGPT是一个开源的、基于 LLM 的知识库问答系统,相对于langflow,我们可以方便的查看模型各个环节的运行数据(比如知识库的引用情况、token使用等),也支持支持可视化工作流编排,比较适合做调试和扩展应用。
1. 在线搭建
FastGPT提供了线上直接使用的方式,使用流程比较简单,大致分为4步:
- 账号注册登录;
- 创建自己的知识库;
- 创建自己的应用;
- 选择应用关联的数据库。
建议大家自行到官网查看操作手册,非常容易上手,访问地址如下:https://fastgpt.run
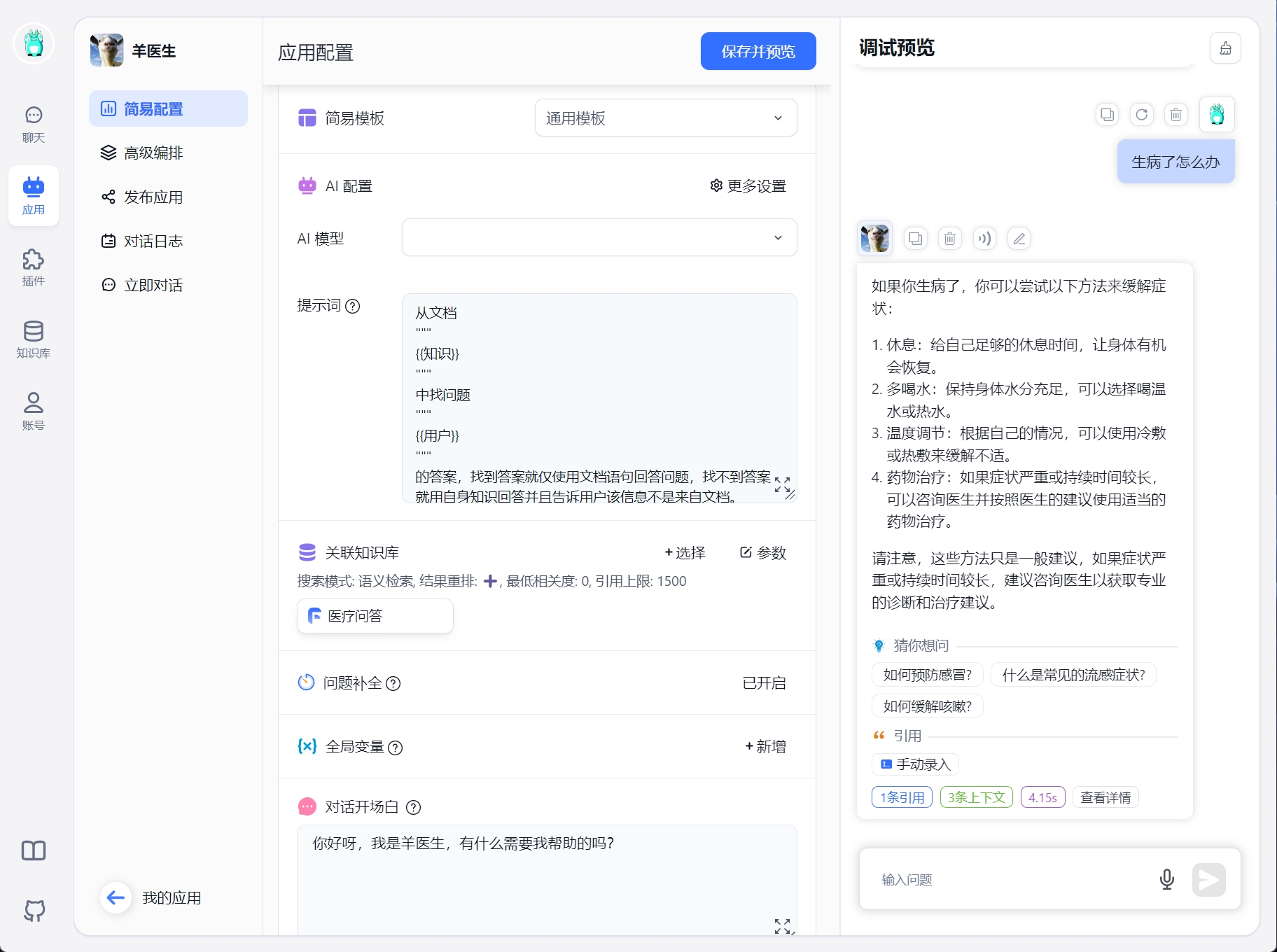
以上一个使用示例,我们可以查看每一次对话引用的知识库内容、上下文信息以及运行时间等。
但是需要注意的是,模型的调用都是需要收费的,虽然注册后就会赠送5块钱的额度,但是基本也只够体验一下,要搭建一个完整的项目是远远不够的,所以前期尽量先用小样本数据创建知识库(Embedding也是要花钱的)体验整个流程。
2. 本地部署
FastGpt也提供了多种本地部署的方法,推荐使用 docker-compose 进行部署,官方文档如下 https://doc.fastgpt.in/docs/development/docker/, 需要一点编程基础,大部分步骤跟着文档操作就没有问题。
在FastGPT中我们需要用到2个模型,分别是LLM和Embedding model,FastGPT默认采用的是LLM是chagGPT,Embedding model是openAI的Embedding-2,这两个模型调用都是要收费的,我们可以用更便宜的国产大模型替换使用。
现在基座大模型正处于激烈竞争阶段,平台都会送一些赠送token额度,建议大家如果只是想自己尝试做一个demo可以采取这种低成本的方式,FastGPT也提供了通过接入OneAPI的方式来实现对不同大模型的支持。
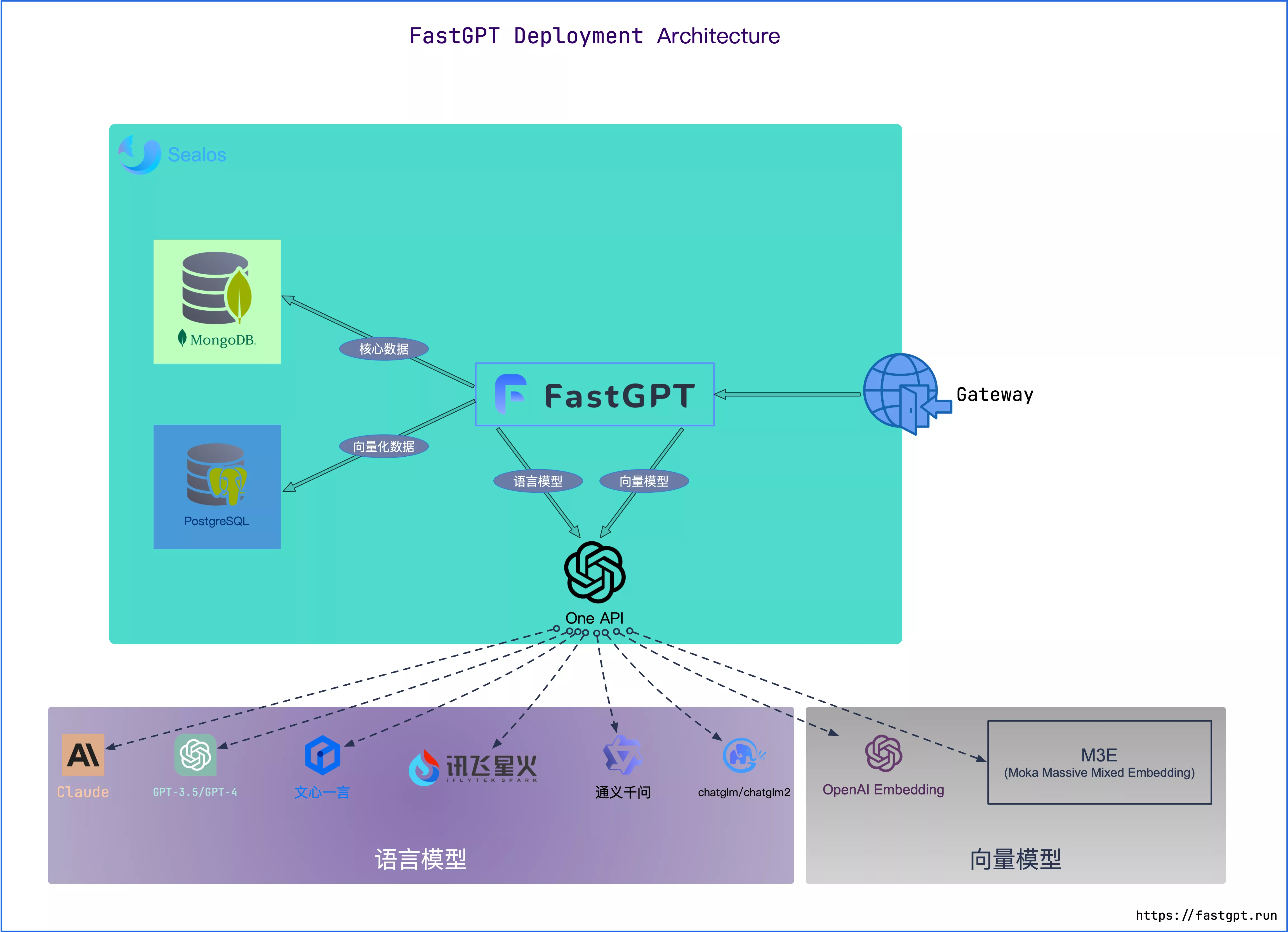
笔者选用的LLM是ChatGLM,Embedding model是M3E,大概的操作的方法是首先在one API平台分别创建国产LLM和Embedding的模型渠道;
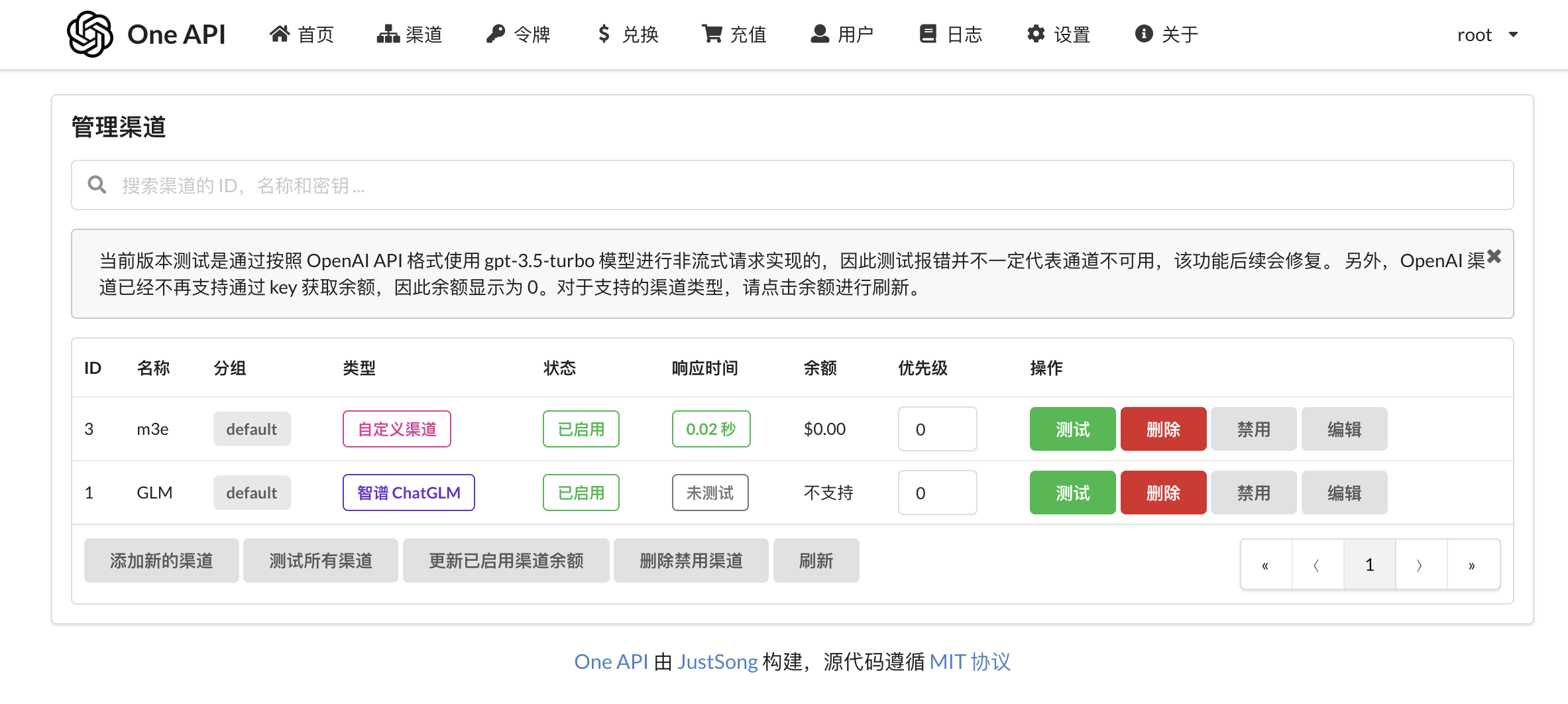
然后在FastGPT的配置文件加入我们要使用的模型,示例如下:
“qaModels”: [
“model”: “gpt-3.5-turbo-16k”,
“name”: “GPT35-16k”,
“maxContext”: 16000,
“maxResponse”: 16000,
“inputPrice”: 0,
“outputPrice”: 0
//新增chatglm
“model”: “chatglm_pro”,
“name”: “GLM”,
“maxContext”: 16000,
“maxResponse”: 16000,
“inputPrice”: 0,
“outputPrice”: 0
最后,更新运行就可以在界面上选择我们添加的模型来使用了。
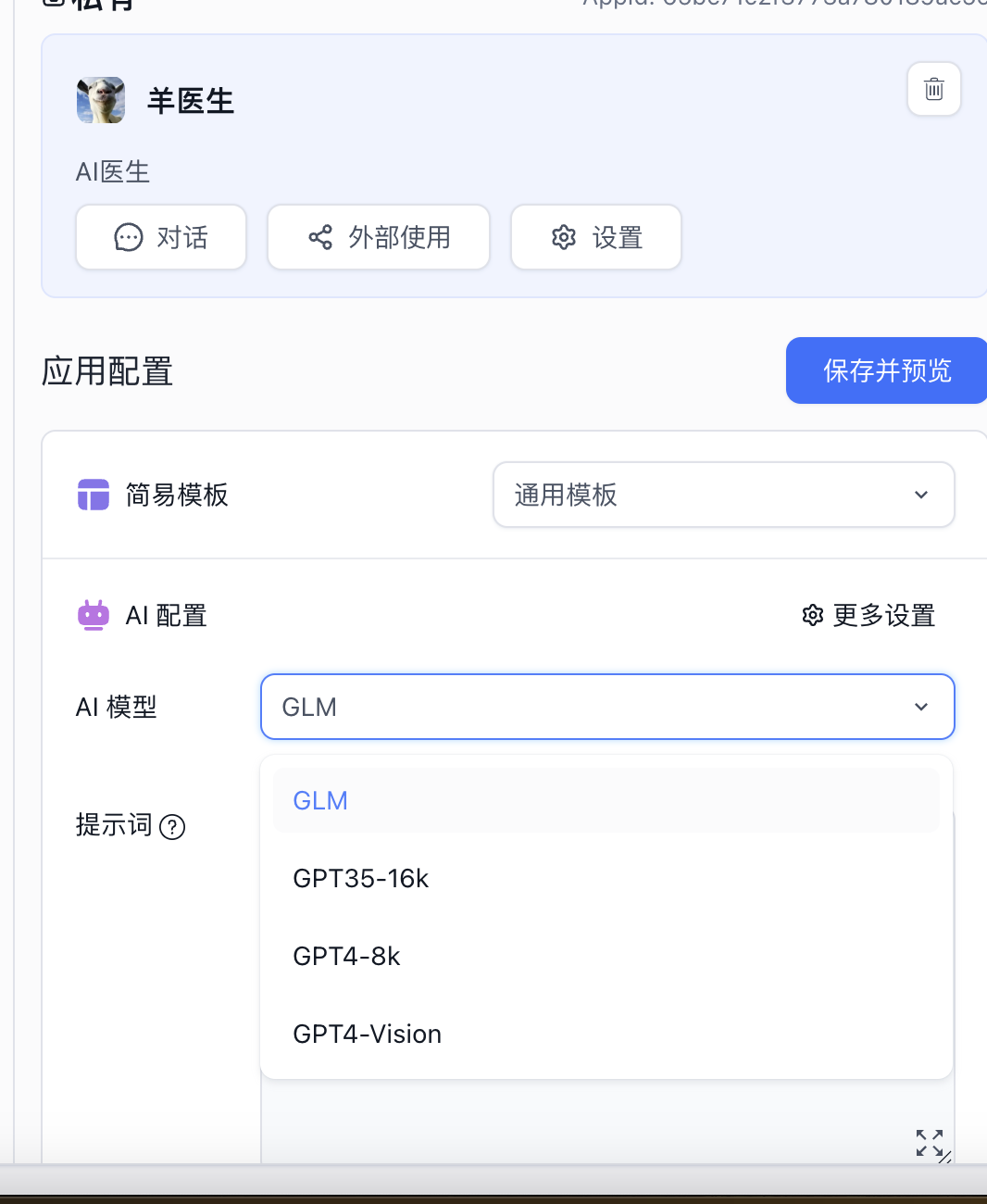
当然,这边没有介绍非常详细的部署细节上,大家感兴趣的可以去官网或者B站上搜索相关教程,这边强烈建议没有任何编程经验产品同学先使用在线的环境去体验整个应用流程,毕竟发掘工具的价值、寻找好的应用场景才是我们核心能力。
本文介绍了笔者基于RAG架构搭建一个医疗智能问答系统的背景和预期产品目标,以及RAG的基础概念和基于FastGpt快速搭建问答系统的方法。
搭建完成只是第一步,在实际使用过程中笔者发现了大量的问题,后面将围绕实际应用中出现的问题,分享一些自己优化的思路和效果评测的方法,欢迎对LLM应用感兴趣的同道来一起交流。
本文由 @FrenzyGoat 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK