

从20亿数据中学习物理世界,基于Transformer的通用世界模型成功挑战视频生成
source link: https://www.qbitai.com/2024/01/117103.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

从20亿数据中学习物理世界,基于Transformer的通用世界模型成功挑战视频生成

支持多种视频合成或处理任务
允中 发自 凹非寺
量子位 | 公众号 QbitAI
建立会做视频的世界模型,也能通过Transformer来实现了!
来自清华和极佳科技的研究人员联手,推出了全新的视频生成通用世界模型——WorldDreamer。
它可以完成自然场景和自动驾驶场景多种视频生成任务,例如文生视频、图生视频、视频编辑、动作序列生视频等。

据团队介绍,通过预测Token的方式来建立通用场景世界模型,WorldDreamer是业界首个。
它把视频生成转换为一个序列预测任务,可以对物理世界的变化和运动规律进行充分地学习。
可视化实验已经证明,WorldDreamer已经深刻理解了通用世界的动态变化规律。
那么,它都能完成哪些视频任务,效果如何呢?
支持多种视频任务
图像生成视频(Image to Video)
WorldDreamer可以基于单一图像预测未来的帧。
只需首张图像输入,WorldDreamer将剩余的视频帧视为被掩码的视觉Token,并对这部分Token进行预测。
如下图所示,WorldDreamer具有生成高质量电影级别视频的能力。
其生成的视频呈现出无缝的逐帧运动,类似于真实电影中流畅的摄像机运动。
而且,这些视频严格遵循原始图像的约束,确保帧构图的显著一致性。

文本生成视频(Text to Video)
WorldDreamer还可以基于文本进行视频生成。
仅仅给定语言文本输入,此时WorldDreamer认为所有的视频帧都是被掩码的视觉Token,并对这部分Token进行预测。
下图展示了WorldDreamer在各种风格范式下从文本生成视频的能力。
生成的视频与输入语言无缝契合,其中用户输入的语言可以塑造视频内容、风格和相机运动。

视频修改(Video Inpainting)
WorldDreamer进一步可以实现视频的inpainting任务。
具体来说,给定一段视频,用户可以指定mask区域,然后根据语言的输入可以更改被mask区域的视频内容。
如下图所示,WorldDreamer可以将水母更换为熊,也可以将蜥蜴更换为猴子,且更换后的视频高度符合用户的语言描述。

视频风格化(Video Stylization)
除此以外,WorldDreamer可以实现视频的风格化。
如下图所示,输入一个视频段,其中某些像素被随机掩码,WorldDreamer可以改变视频的风格,例如根据输入语言创建秋季主题效果。

基于动作合成视频(Action to Video)
WorldDreamer也可以实现在自动驾驶场景下的驾驶动作到视频的生成。
如下图所示,给定相同的初始帧以及不同的驾驶策略(如左转、右转),WorldDreamer可以生成高度符合首帧约束以及驾驶策略的视频。

那么,WorldDreamer又是怎样实现这些功能的呢?
用Transformer构建世界模型
研究人员认为,目前最先进的视频生成方法主要分为两类——基于Transformer的方法和基于扩散模型的方法。
利用Transformer进行Token预测可以高效学习到视频信号的动态信息,并可以复用大语言模型社区的经验,因此,基于Transformer的方案是学习通用世界模型的一种有效途径。
而基于扩散模型的方法难以在单一模型内整合多种模态,且难以拓展到更大参数,因此很难学习到通用世界的变化和运动规律。
而当前的世界模型研究主要集中在游戏、机器人和自动驾驶领域,缺乏全面捕捉通用世界变化和运动规律的能力。
所以,研究团队提出了WorldDreamer来加强对通用世界的变化和运动规律的学习理解,从而显著增强视频生成的能力。
借鉴大型语言模型的成功经验,WorldDreamer采用Transformer架构,将世界模型建模框架转换为一个无监督的视觉Token预测问题。
具体的模型结构如下图所示:
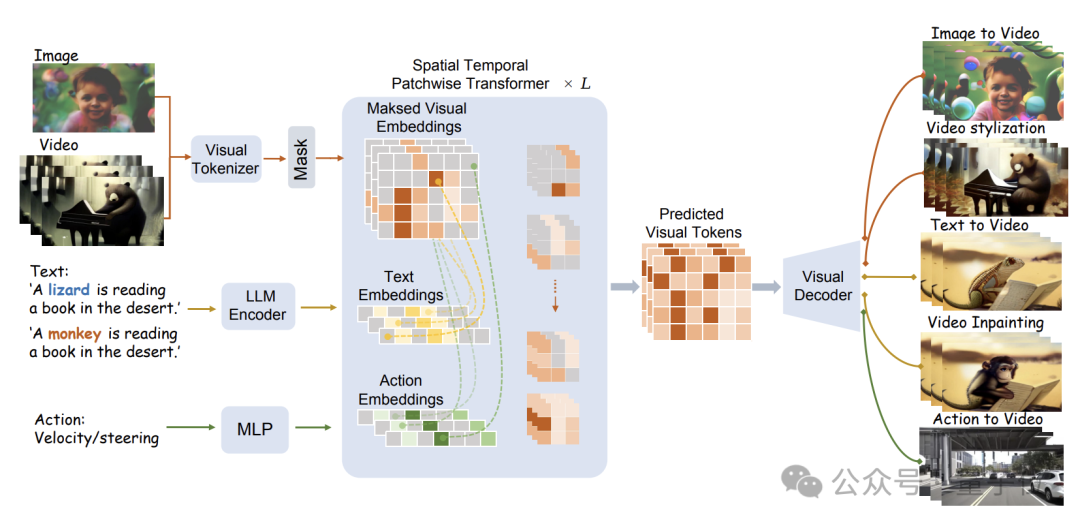
WorldDreamer首先使用视觉Tokenizer将视觉信号(图像和视频)编码为离散的Token。
这些Token在经过掩蔽处理后,输入给研究团队提出的Sptial Temporal Patchwuse Transformer(STPT)模块。
同时,文本和动作信号被分别编码为对应的特征向量,以作为多模态特征一并输入给STPT。
STPT在内部对视觉、语言、动作等特征进行充分的交互学习,并可以预测被掩码部分的视觉Token。
最终,这些预测出的视觉Token可以用来完成各种各样的视频生成和视频编辑任务。
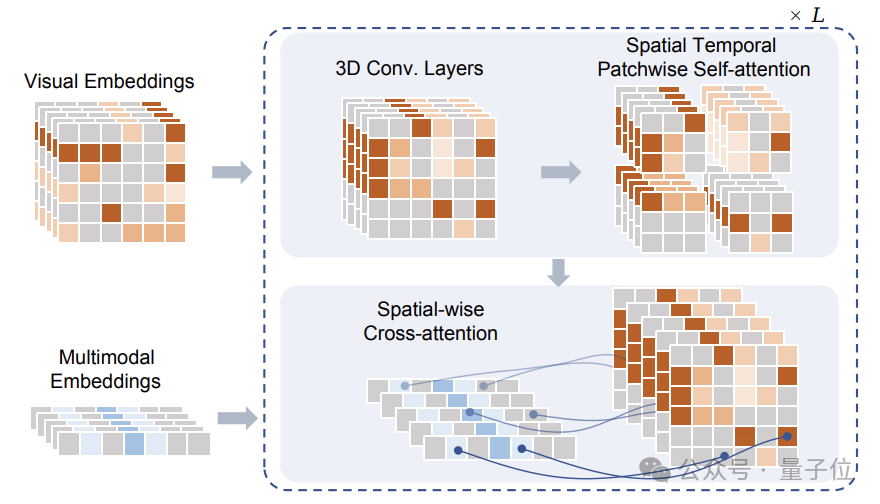
值得注意的是,在训练WorldDreamer时,研究团队还构建了Visual-Text-Action(视觉-文本-动作)数据的三元组,训练时的损失函数仅涉及预测被掩蔽的视觉Token,没有额外的监督信号。
而在团队提出的这个数据三元组中,只有视觉信息是必须的,也就是说,即使在没有文本或动作数据的情况下,依然可以进行WorldDreamer的训练。
这种模式不仅降低了数据收集的难度,还使得WorldDreamer可以支持在没有已知或只有单一条件的情况下完成视频生成任务。
研究团队使用大量数据对WorldDreamer进行训练,其中包括20亿经过清洗的图像数据、1000万段通用场景的视频、50万段高质量语言标注的视频、以及近千段自动驾驶场景视频。
团队对10亿级别的可学习参数进行了百万次迭代训练,收敛后的WorldDreamer逐渐理解了物理世界的变化和运动规律,并拥有了各种的视频生成和视频编辑能力。
论文地址:
https://arxiv.org/abs/2401.09985
项目主页:
https://world-dreamer.github.io/
Recommend
-
48
大量的产业是基于物理世界运作的,例如建筑设计施工、交通管控、通讯基站建设等。对于这些产业来说,通常需要大量的人力进行现场勘查、测绘、分析等。 如果将“真实物理世界”转化为一个“虚拟数字模型”,或许能将此类工作效率大大提升。
-
38
在日常的繁忙业务中,项目更多会偏向于 2D 或 2.5D 的视觉风格,因为 2D 项目无论在设计或是开发的周期都会更短,但 2D 缺少 3D 那样的空间感、真实感,正好最近参与了 3D 项目的开发,过程中也遇到了不少问题,通过这篇文章将关于 Three....
-
33
新浪科技讯北京时间12月18日消息,据国外媒体报道,目前,《物理世界》杂志最新评选出2019年十大发现,其中科学家拍摄黑洞照片排名第一,以下是该媒体评选的2019年十大发现:1、直接观测黑洞及其“影子”图中显示距离地球5500万光年的星系中
-
6
还原物理世界 AIRLOOK以空间大数据推动行业数智化变革 作者:李祥敬 【原创】 2021-06-01 13:00:43关键字: 大数据...
-
3
-
4
麻省理工科技评论-专访世界高分子物理领军人物程正迪院士:利用精确设计的 “巨型分子”,在固体中构筑超分子晶体专访世界高分子物理领军人物程正迪院士:利用精确设计的 “巨型分子”,在固体中构筑超分子晶体“程正迪是世界高分子物理领军...
-
3
WAIC 2022 旷视: AIoT让物理世界变得更美好
-
5
未来10年最大的机会就在于云、AI与物理世界机器融合 行业动态 2023年5月4日 14:09...
-
5
麻省理工科技评论-如何朝着物理世界的“奇点”迈进?MIT团队为实验科学家打造科研AI助理如何朝着物理世界的“奇点”迈进?MIT团队为实验科学家打造科研AI助理CRESt 系统的操作非常简单,实验科研人员只需要用自然语言,就能够掌控...
-
5
AI新浪潮观察6min read长了眼睛和嘴,ChatGPT 开始入侵物理世界2023/09/26
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK