

八分钟了解一致性算法 -- Raft算法
source link: https://www.51cto.com/article/779130.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

八分钟了解一致性算法 -- Raft算法
图片
分布式一致性
在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性。
分布式一致性算法
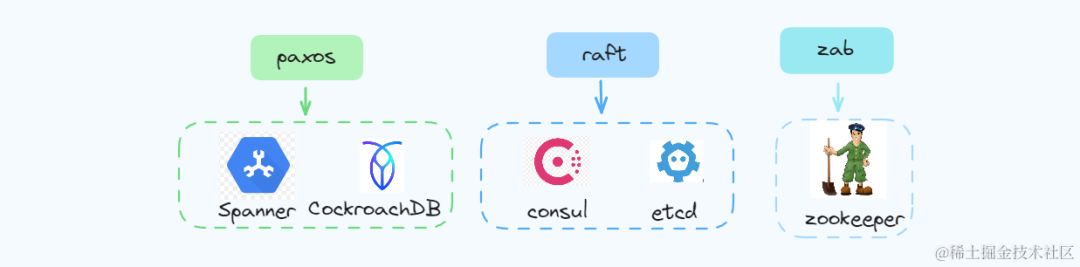
比较常见的一致性算法包括Paxos算法,Raft算法,ZAB算法等
- • Paxos是Leslie Lamport提出的一种基于消息传递的分布式一致性算法。很多分布式一致性算法都由Paxos演变而来,但是最大特点就是难,不仅难以理解,更难以实现。
- • Raft 是一种相对较新的分布式一致性算法,是一种更易于理解和实现的算法,在选主的冲突处理等方式上它都选择了非常简单明了的解决方案。
- • ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议),是为 Zookeeper 设计的分布式一致性协议!
图片
Raft算法使用场景
一般用作两种场景:
元数据管理:比如etcd,特点是数据规模小,主要保证数据一致性和集群的高可用(raft选主),所以一套raft集群就够了。
分布式数据库:这种会用partition group,每个group有一个raft集群,当数据变大的时候会做扩展。
🚩 Raft只是个共识算法来保证数据的一致性,与数据库、客户端、事务没有关系
Raft算法基础
Raft把算法流程分为三个子问题:领导选举(Leader election)、日志复制(Log replication)、安全性(Safety)。
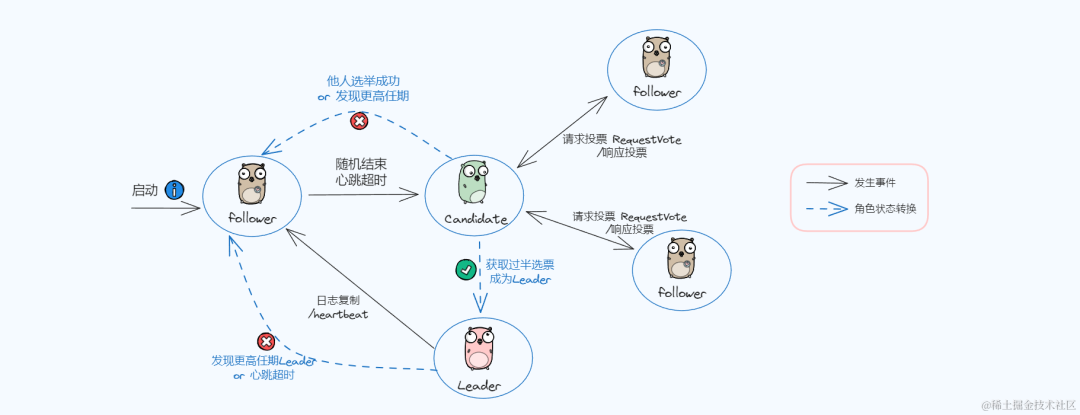
- • 领导者 Leader:接收处理客户端请求、向Follower进行日志同步、同一时刻最多只能有一个可行的 Leader
- • 追随者 Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志,处在完全被动状态
- • 候选人 Candidate:临时角色,处于 Leader 和 Follower 之间的暂时状态

图片
Raft算法中在任意时刻最多只有一个Leader,正常工作期间只有Leader和Followers。
图片
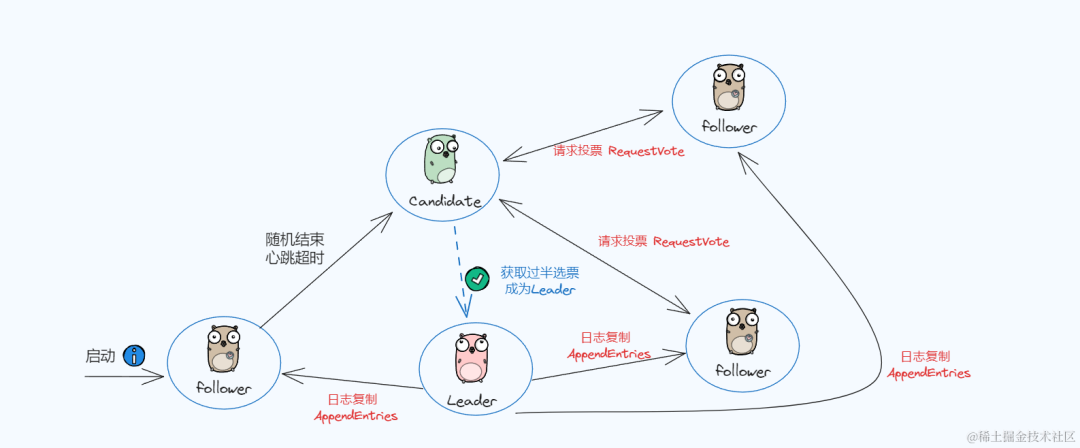
状态切换流程:
- 1. Raft刚启动的时候,所有节点初始状态都是Follower
- 2. 超时时间内如果没有收到Leader的请求则转换为Candidate角色并发起Leader选举
- 3. 如果Candidate收到了多数节点的选票则转换为Leader
- 4. 如果在发起选举期间发现已经有Leader了,或者收到更高任期的请求则转换为Follower
- 5. Leader在收到更高任期的请求后转换为Follower
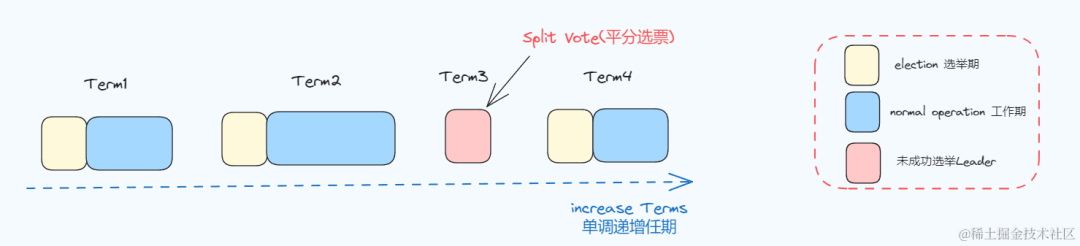
任期:可以理解为是节点担任Leader职务的时间期限。
Raft 将时间划分为一个一个的任期(term),每个任期由单调递增的数字(任期编号)标识,工作期可长可短也可能不存在
🚩 任期时间 = 选举时间 + 正常运行时间
图片
Raft 中服务器节点之间通信通过两个 RPC 调用:
- • 请求投票 RequestVote:候选人(Candidate) 选举期间发起
- • 日志复制 AppendEntries:领导人(Leader)发起,用于复制 log 和发送心跳
图片
Leader选举
初始状态时,每个节点的角色都是 Follower(跟随者),Term任期编号为 1(假设任期编号从1开始)
图片
不过这两种情况会触发选举:
- • Raft 初次启动时,不存在Leader,这时候会触发Leader选举
- • Follower在自己的超时时间内没有接收到Leader的心跳heartBeat,触发选举超时,从而Follower的角色切换成Candidate,Candidate会发起选举
既然有两种情况下会触发选举,一个是初次启动,一个是Leader故障未发送心跳给Follower,那么我们假设有五个节点,然后分别用图来看下是如何选举的!
🚩为了画图是不会显得很占空间,暂时用三个节点表示, 并且用 ‘...’表示剩余节点
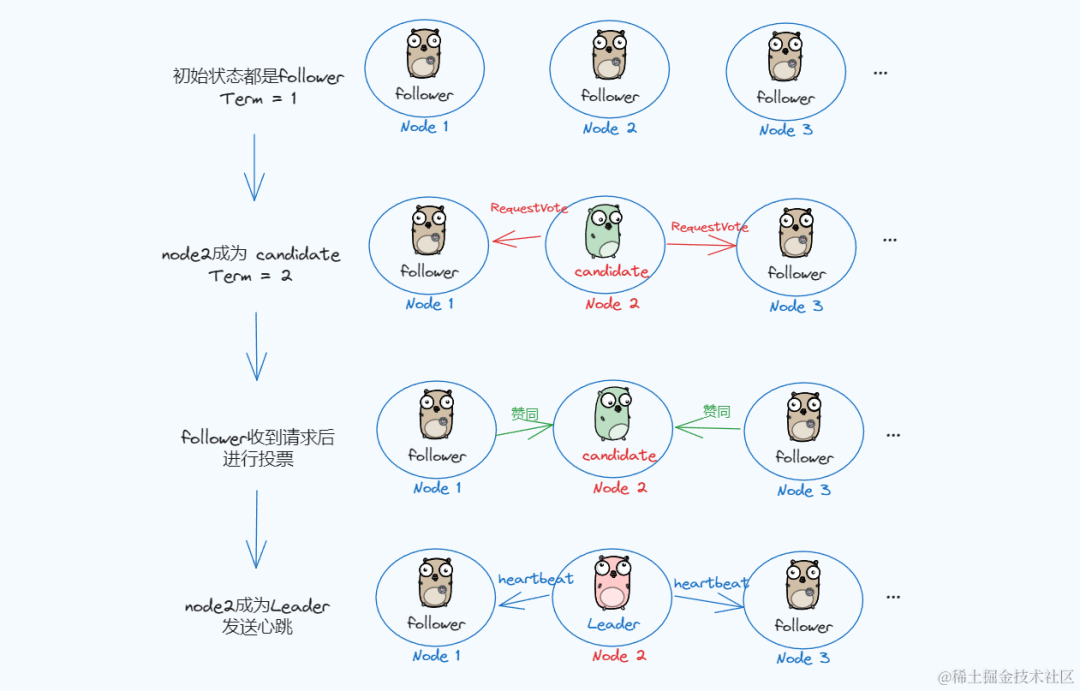
初次启动时:
初次启动节点都是正常流程如下:
图片
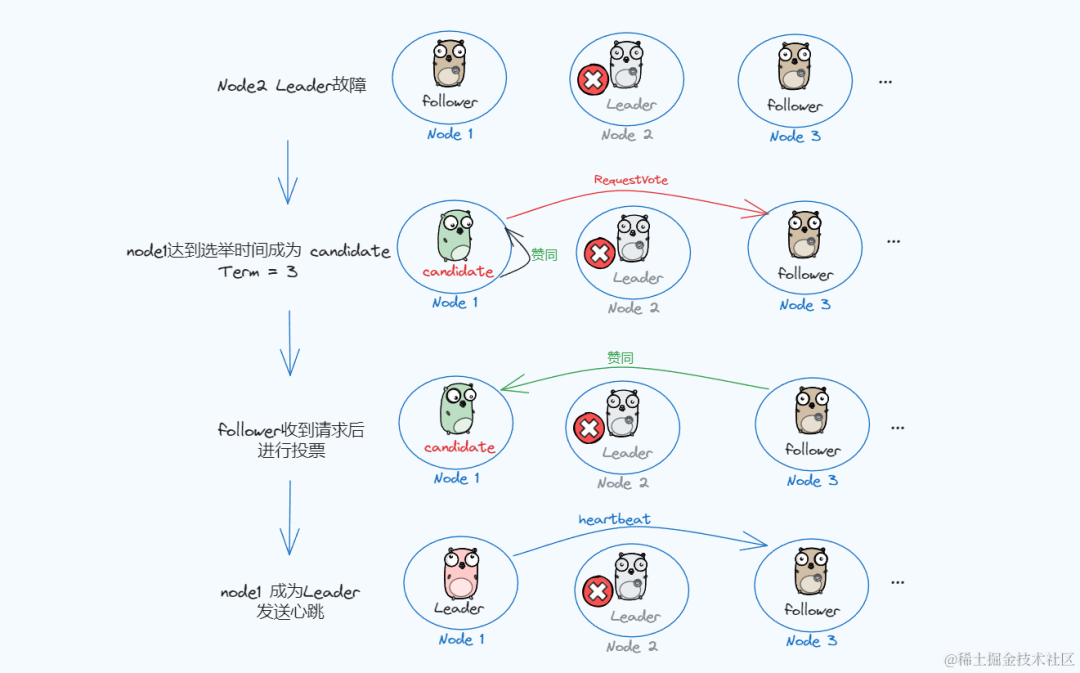
Leader故障时:
Node2此时是Leader 节点,结果故障了,剩下四个节点参与选举。
图片
在一个任期(Term)内只可以投票给一个结点,得到超过半数的投票才可成为 Leader,从而保证了一个任期内只会有一个 Leader 产生。
概括成一句话就是:保证Leader上日志能完全相同地复制到多台Follower服务器上。
OK!我们看下是如何进行同步的
Raft算法中,每个节点维护着一份日志,其中包含了系统中所有状态变更的记录,每一次状态变更被称为一个日志条目。
我们先看日志结构和右侧说明:
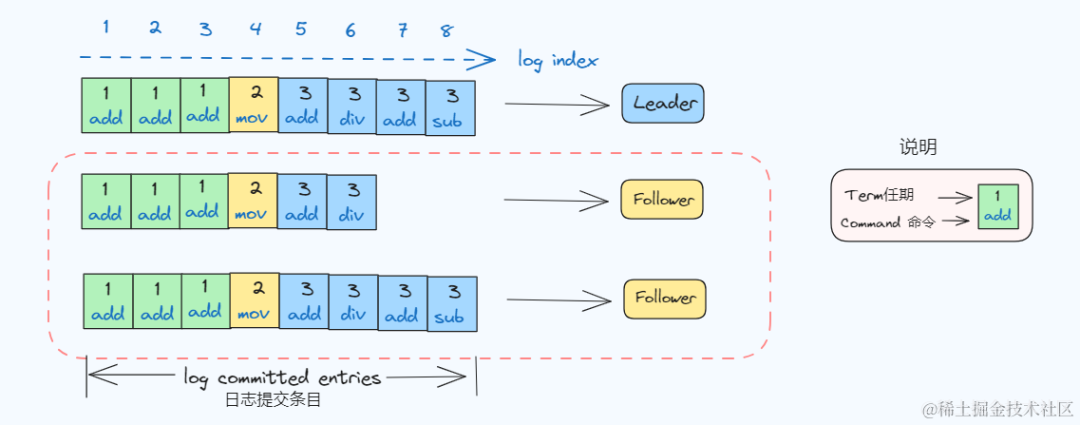
图片
图中每个节点存储自己的日志副本(log),每条日志记录包含:
• 索引 (log index):记录在日志中的位置,是一个连续单调递增整数
• 任期号 (term):日志记录被创建时Leader的任期号,上图中有三个任期
• 命令 (command):客户端请求指定的、状态机需要执行的指令
了解完日志结构后,我们来看日志是如何发起同步的。
日志持久化存储的条件
Follower节点必须先将记录安全写到磁盘,才能向Leader节点返回写入成功响应。
如果一条日志记录被存储在超过半数的节点上,我们认为该记录已提交(committed)——这是 Raft 非常重要的特性!如果一条记录已提交,意味着状态机可以安全地执行该记录
流程如下图:
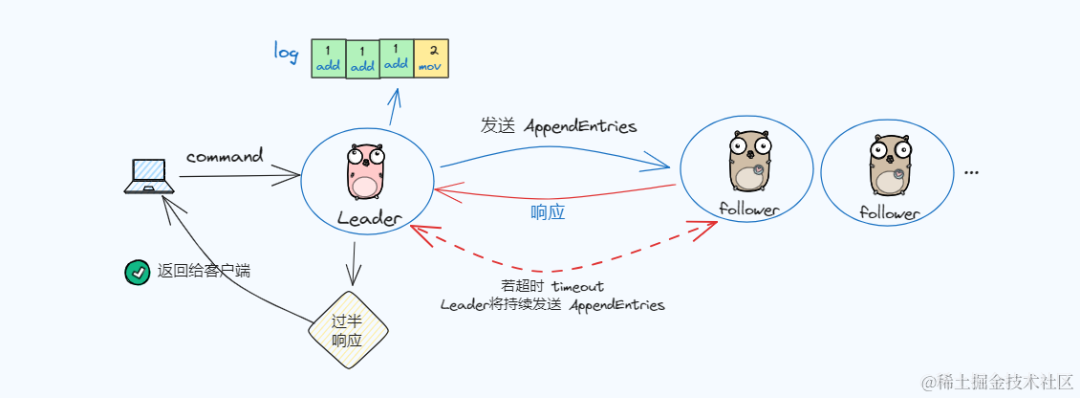
图片
- 1. 客户端向 Leader 发送命令,希望该命令被所有状态机执行;
- 2. Leader 先将该命令追加到自己的日志中;
- 3. Leader 并行地向其它节点发送AppendEntries RPC,等待响应;
- 4. 收到超过半数节点的响应,则认为新的日志记录是被提交的:
- 5. Leader 将命令传给自己的状态机,然后向客户端返回响应
- 6. 此外,一旦 Leader 知道一条记录被提交了,将在后续的AppendEntries RPC中通知已经提交记录的 Followers
- 7. Follower 将已提交的命令传给自己的状态机
- 8. 如果 Follower 宕机/超时:Leader 将反复尝试发送 RPC;
🚩 注:Leader 不必等待每个 Follower 做出响应,只需要超过半数的成功响应(确保日志记录已经存储在超过半数的节点上),一个很慢的节点不会使系统变慢,因为 Leader 不必等待
一致性检查
Raft 通过 AppendEntries RPC 消息来检测。
- • 每个AppendEntries RPC包含新日志记录之前那条记录的索引 (prevLogIndex) 和任期 (prevTerm);
- • Follower接收到消息后检查自己的 log index 、 term 与 prevLogIndex 、 prevTerm 进行匹配
- • 匹配成功则接收该记录,添加最新log,匹配失败则拒绝该消息
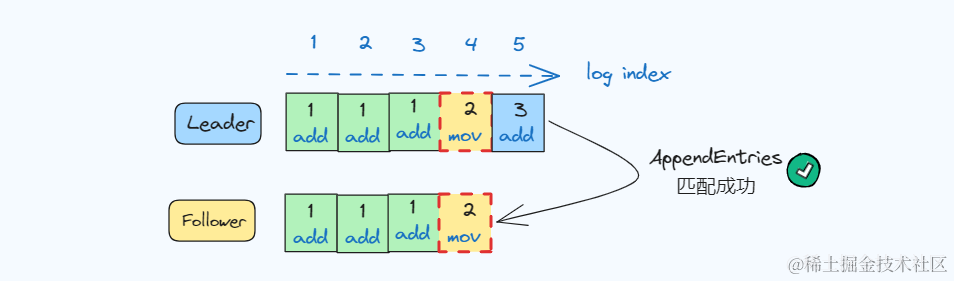
图片
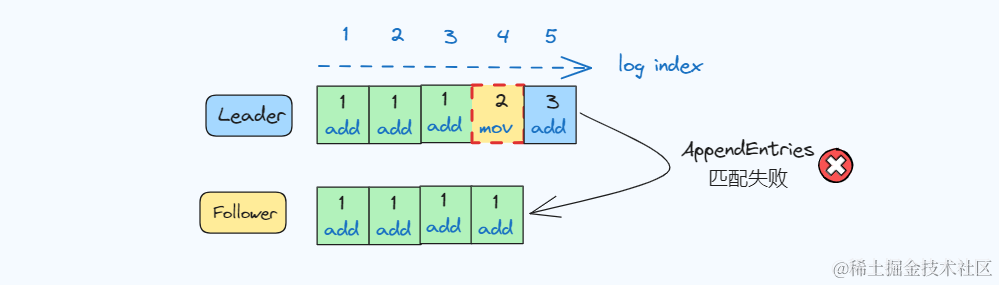
图片
日志一致性
Raft算法的目的是保证所有节点的一致性,即一个日志条目在某个节点被提交,那么这个日志条目也必须在所有节点上被提交。
🚩 通过【一致性检查】就保证了日志一致性的这两点内容。
- • 如果两个节点的日志在相同的索引位置上的任期号相同,则认为他们具有一样的命令,从头到这个索引位置之间的日志完全相同
- • 如果给定的记录已提交,那么所有前面的记录也已提交
Raft算法是一种简洁而高效的分布式一致性算法,通过引入Leader选举和日志复制的机制,确保了分布式系统的共识和一致性。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK