

LLM外挂知识库
source link: https://qiankunli.github.io/2023/09/25/llm_retrieval.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

RAG(Retrieval-Augmented Generation),LLM相比传统算法最重要的就是zero shot能力,最重要的是从海量的文档中找到和问题相关的片段。找到后使用LLM生成回答其实很鸡肋,尤其是针对技术问题的回答,不需要LLM 去造答案,LLM 就帮我找到相关文档就行了。RAG 的主要目标是通过利用检索的优势来增强生成过程,使 NLG 模型能够生成更合理且适合上下文的响应。通过将检索中的相关信息纳入生成过程,RAG 旨在提高生成内容的准确性、连贯性和信息量。
引入外部知识 的几个示例
大语言模型的原理,就是利用训练样本里面出现的文本的前后关系,通过前面的文本对接下来出现的文本进行概率预测。如果类似的前后文本出现得越多,那么这个概率在训练过程里会收敛到少数正确答案上,回答就准确。如果这样的文本很少,那么训练过程里就会有一定的随机性,对应的答案就容易似是而非。
LLM 擅长于一般的语言理解与推理,而不是某个具体的知识点。如何为ChatGPT/LLM大语言模型添加额外知识?
- 通过fine-tuning来和新知识及私有数据进行对话,OpenAI 模型微调的过程,并不复杂。你只需要把数据提供给 OpenAI 就好了,对应的整个微调的过程是在云端的“黑盒子”里进行的。需要提供的数据格式是一个文本文件,每一行都是一个 Prompt,以及对应这个 Prompt 的 Completion 接口会生成的内容。
{"prompt": "<prompt text>", "completion": "<ideal generated text>"} {"prompt": "<prompt text>", "completion": "<ideal generated text>"} {"prompt": "<prompt text>", "completion": "<ideal generated text>"} ...有了准备好的数据,我们只要再通过 subprocess 调用 OpenAI 的命令行工具,来提交微调的指令就可以了。
subprocess.run('openai api fine_tunes.create --training_file data/prepared_data_prepared.jsonl --model curie --suffix "ultraman"'.split())微调模型还有一个能力,不断收集新的数据,不断在前一个微调模型的基础之上继续微调我们的模型。
- 通过word embeddings + pinecone数据库来搭建自己私有知识库。 chatgpt预训练完成后,会生成一个embeddings向量字典,比如我们可以将我们的私有知识库各个章节通过openai的相关api获取到对应的embeddings,然后将这些embeddings保存到向量数据库(比如 Facebook 开源的 Faiss库、Pinecone 和 Weaviate),当用户要对某个领域后者问题进行语义查询时,则将用户的输入同样通过openai的相关api来获取相应的embeddings向量,然后再和向量数据库pinecone中的我们的私有知识库类型做语义相似度查询,然后返回给用户。PS: 内容向量化
- 比如判断某一段文本 是积极还是消极,向chatgpt 查询目标文本的向量,然后计算其与“积极” “消极” 两个词 embedding 向量的“距离”,谁更近,说明这段文本更偏向于积极或消极。
- 过几天openAI的模型版本升级了,这些保存的embedding会失效吗?特定模型也有带日期的快照版本,选取那些快照版本就好了。
- 向量是基于大模型生成的,因此对两段文本向量相似度计算必须基于同一个模型,不同的模型算出来的向量之间是没有任何关系的,甚至连维数都不一样。不过你可以把基于A 模型来算向量相似度进行检索把文本找出来,然后把找到的文本喂给B模型来回答问题。
- 通过langchain这个chatgpt编程框架来给chatgpt赋能。 langchain可以将不同的工具模块和chatgpt给链接(chain)起来。
- chatgpt 插件,比如有一个提供酒旅租车信息的插件
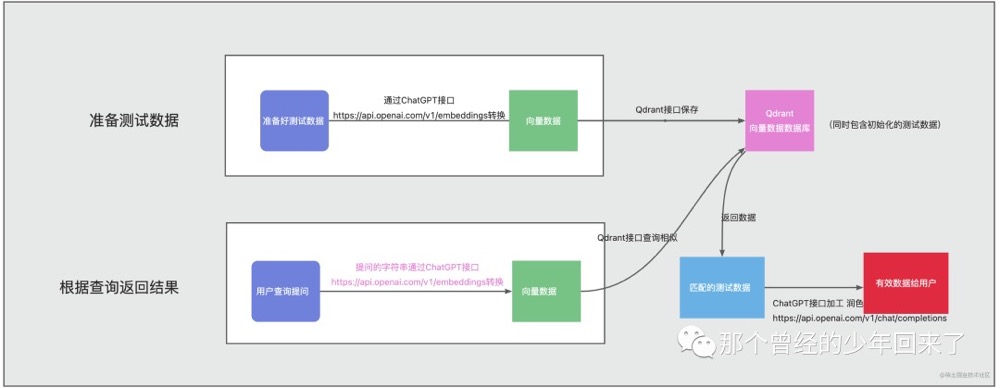
比如针对问题:鲁迅先生去日本学习医学的老师是谁。因为 LLM(大语言模型)对上下文长度的限制,你不能将《藤野先生》整体作为提示语然后问“鲁迅在日本的医学老师是谁?”。 先通过搜索的方式,找到和询问的问题最相关的语料。可以用传统的基于关键词搜索的技术。也可以先分块存到向量数据库中(向量和文本块之间的关系),使用 Embedding 的相似度进行语义搜索的技术。然后,我们将和问题语义最接近的前几条内容,作为提示语的一部分给到 AI(使用检索结果作为 LLM 的 Prompt)。然后请 AI 参考这些内容,再来回答这个问题。

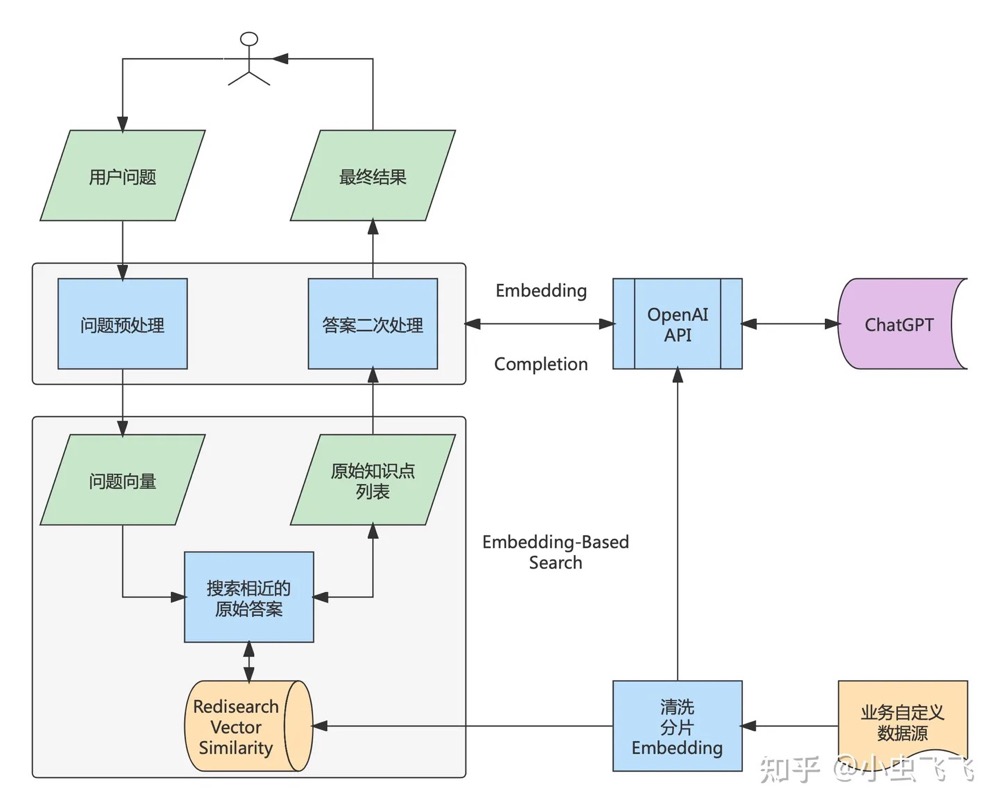
这也是利用大语言模型的一个常见模式(这个模式实在太过常用了,所以有人为它写了一个开源 Python 包,叫做 llama-index)。因为大语言模型其实内含了两种能力。PS:有点像推荐的粗排和精排,纯向量化的召回在一些Benchmark上表现还不如关键字搜索。
- 海量的语料中,本身已经包含了的知识信息。比如,我们前面问 AI 鱼香肉丝的做法,它能回答上来就是因为语料里已经有了充足的相关知识。我们一般称之为“世界知识”。
- 根据你输入的内容,理解和推理的能力。这个能力,不需要训练语料里有一样的内容。而是大语言模型本身有“思维能力”,能够进行阅读理解。这个过程里,“知识”不是模型本身提供的,而是我们找出来,临时提供给模型的。如果不提供这个上下文,再问一次模型相同的问题,它还是答不上来的。
Embedding 生成向量使用的模型 跟最后prompt 调用的模型可以不是同一个,因此有的向量数据库也包含Segment 和 Embedding,通过自然语言就能直接和向量数据库交互。也就是说,我们可以直接把文档扔给数据库,大段文本的切分,以及文本向量化,向量数据库 会帮我们处理。我们也可以直接把问题扔给数据库,请他来查询相似度较高的文本块,问题向量化以及检索的细节,向量数据库会帮我们处理。
- 传统搜索系统基于关键字匹配,在面向:游戏攻略、技术图谱、知识库等业务场景时,缺少对用户问题理解和答案二次处理能力。
- 领域知识不在预训练的数据集中,比如:
- 较新的内容。同一个知识点不断变更:修改、删除、添加。如何反馈当前最新的最全面的知识。比如对于 ChatGpt 而言,训练数据全部来自于 2021.09 之前。
- 未公开的、未联网的内容。
- 基于 LLM 搭建问答系统的解决方案有以下几种:
- Fine-Tuning
- 基于 Prompt Engineering,比如 Few-Shot方式。将特定领域的知识作为输入消息提供给模型。类似于短期记忆,容量有限但是清晰。举个例子给 ChatGPT 发送请求,将特定的知识放在请求中,让 ChatGPT 对消息中蕴含的知识进行分析,并返回处理结果。
- 与普通搜索结合,使用基础模型对搜索结果加工。在做问答时的方式就是把 query 转换成向量,然后在文档向量库中做相似度搜索。
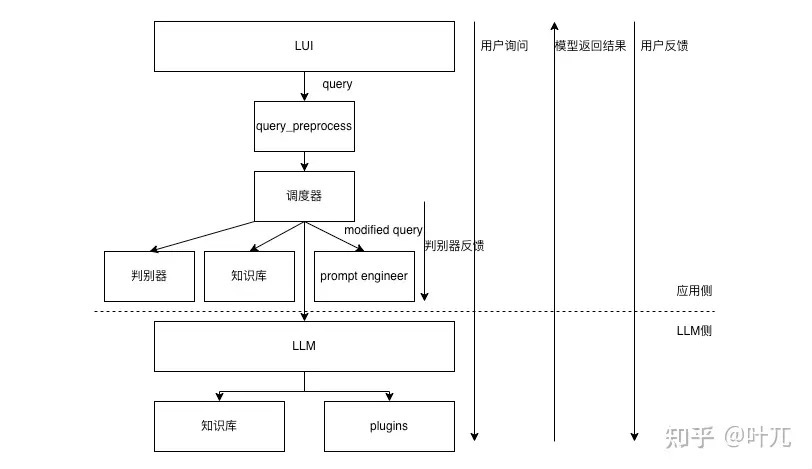
- 用户输入query之后,首先先从知识库搜索到结果,然后基于搜索到的结果进行解析构造,生成新的prompt,然后调用LLM,LLM根据输入的prompt自行进行知识库的检索与plugins的调用
多文档问答难点
上下文注入,即不修改LLM,专注于提示本身,并将相关上下文注入到提示中,让模型参考这个提示进行作答,但是其问题在于如何为提示提供正确的信息。目前我们所能看到的就是相关性召回,其有个假设,即问题的答案在召回的最相似的文档里。
单文档问答,即类似ChatPDF的需求,ChatPDF的目标是尽可能全面地总结出整篇文档的信息。这个需求以目前ChatGPT可接受的16K上下文而言,不少文档可以直接丢进去问答,不需要使用召回工具先做知识检索。PS:慢慢随着技术进步不成问题。
如果我们看一下RAG系统中的流程链:
- 将文本分块(chunking)并生成块(chunk)的Embedding
- 通过语义相似度搜索检索数据块
- 根据top-k块的文本生成响应 我们会看到所有的过程都是有信息损失的,这意味着不能保证所有的信息都能保存在结果中。如果我们把所有的限制放在一起,重新考虑一些公司即将推出的基于RAG的企业搜索,我真的很好奇它们能比传统的全文搜索引擎好多少。
RAG探索之路的血泪史及曙光 值得细读。
深入剖析开源大模型+Langchain框架智能问答系统性能下降原因常规方案中对智能问答系统准确率影响最大的几个因素如下:
- embedding 在 Retrieval 任务中 TopK 的准确率 (受 embedding 模型自身能力、Retrieval 算法、K等三个因素影响)
- K 的大小,K 原则越大越好,但是 LLM 的 tokens 限制导致 K 由不能太大。(上述 1、2 的都是为了从数据库海量 chunks 中选择出包含正确答案的 chunks)
- LLM 自身阅读理解与总结推理能力。
如何让LLM简要、准确回答细粒度知识?如何让LLM回答出全面的粗粒度(跨段落)知识?QA 的难度主要在于回答这个问题所依赖的信息在长文档中的分布情况,具体可以大致分为下面三种情况:
- 相关信息可以出现在不超过一个固定上下文长度(512)限制的 block 以内
- 相关信息出现在多个 block 里,出现的总数不超过 5-10 个,最好是能在大模型支持的有效长度内。
- 需要考虑多个片段,并综合结合上下文信息甚至全部内容才能得到结果。 PS: 可能要知识图谱帮一点忙。
受限于数据集的大小和规模以及问题的难度,目前主要研究偏向于 L1 和 L2 。能比较好的整合和回答 L1 类问题,L2 类问题也有比较不错的结果,但对于 L3 类问题,如果所涉及到的片段长度过长,还是无法做到有效的回答。了解RAG能做什么和不能做什么,可以让我们为RAG寻找最适合的领域,避免强行进入错误的地方。
召回的输入(不一定是用户原输入)?召回的输出(不一定是Vectordb原输出)?召回的方式(不一定直接查vectordb,微调embedding)?
- 经常遇到一些复杂文档的情况,这些文档中可能有表格,有图片,有单双栏等情况。尤其是对于一些扫描版本的文档时候,则需要将文档转换成可以编辑的文档,这就变成了版面还原的问题。具体的,可以利用ppstructrue进行文档版面分析,在具体实现路线上,图像首先经过版面分析模型,将图像划分为文本、表格、图像等不同区域,随后对这些区域分别进行识别。
- 如何将文档拆分为文本片段。主要有两种,一种就是基于策略规则,另外一种是基于算法模型。
- 如何保证文档切片不会造成相关内容的丢失?一般而言,文本分割如果按照字符长度进行分割,这是最简单的方式,但会带来很多问题。例如,如果文本是一段代码,一个函数被分割到两段之后就成了没有意义的字符。因此,我们也通常会使用特定的分隔符进行切分,如句号,换行符,问号等。可以使用专门的模型去切分文本,尽量保证一个chunk的语义是完整的,且长度不会超过限制。
- 文档切片的大小如何控制? 太小则 容易造成信息丢失,太大则不利于向量检索命中。此外还要考虑LLM context 长度的限制,GPT-3.5-turbo 支持的上下文窗口为 4096 个令牌,这意味着输入令牌和生成的输出令牌的总和不能超过 4096,否则会出错。为了保证不超过这个限制,我们可以预留约 2000 个令牌作为输入提示,留下约 2000 个令牌作为返回的消息。这样,如果你提取出了五个相关信息块,那么每个片的大小不应超过 400 个令牌。最详细的文本分块(Chunking)方法——可以直接影响基于LLM应用效果
- 基于算法模型,主要是使用类似 BERT 结构的语义段落分割模型,能够较好的对段落进行切割,并获取尽量完整的上下文语义。需要微调,上手难度高,而且切分出的段落有可能大于向量模型所支持的长度,这样就还需要进行切分。
- 文档召回过程中如何保证召回内容跟问题是相关的? 或者说,如何尽可能减少无关信息? 召回数据相关性的影响方面很多,既包括文档的切分,也包括文档query输入的清晰度,因此现在也出现了从多query、多召回策略以及排序修正等多个方案。
- Finetune 向量模型。embedding 模型 可能从未见过你文档的内容,也许你的文档的相似词也没有经过训练。在一些专业领域,通用的向量模型可能无法很好的理解一些专有词汇,所以不能保证召回的内容就非常准确,不准确则导致LLM回答容易产生幻觉(简而言之就是胡说八道)。可以通过 Prompt 暗示 LLM 可能没有相关信息,则会大大减少 LLM 幻觉的问题,实现更好的拒答。大模型应用中大部分人真正需要去关心的核心——Embedding 分享Embedding 模型微调的实现 ,此外,原则上:embedding 所得向量长度越长越好,过长的向量也会造成 embedding 模型在训练中越难收敛。
- 利用 LLM 对知识语料进行增强和扩充。将用户问题采用多个不同的视角去提问,然后 LLM 会得出最终结果。大多数人在问问题的过程中,如果不懂 prompt 工程,往往不专业,要么问题过于简单化,要么有歧义,意图不明显。那么向量搜索也是不准确的,导致LLM回答的效果不好。所以需要 LLM 进行问题的修正和多方位解读。MultiQueryRetriever 。PS: 对一篇文档/chunk生成知识点、问题、短摘要,当根据query 进行匹配时,可能先匹配到知识点、问题、短摘要,再找到原始chunk。MultiVectorRetriever/ParentDocumentRetriever 。使用RAG-Fusion和RRF让RAG在意图搜索方面更进一步
- 同时使用了es 和向量召回。 EnsembleRetriever。 |倒排召回|向量召回|知识图谱召回| |—|—|—| |检索速度更快||| |精确匹配能力强,比如一些专有名词、人名、产品名、缩写、id、低频词等|考虑语义相似性,更加智能|实体-关系检索| |没有语义信息,对”一词多义”现象解决的不好|不理解专有词汇,容易出现语义相似但主题不相似的情况|
- 如果一篇文档与查询非常相关,但与已经呈现给用户的文档非常相似,那么这篇文档的边际收益可能就不大。MMR 是一种广泛应用于信息检索和自然语言处理领域的算法。MMR 的主要目标是在文档排序和摘要生成等任务中平衡相关性和新颖性。换句话说,MMR 旨在为用户提供既相关又包含新信息的结果。
- 许多向量存储支持了对元数据的操作。LangChain 的 Document 对象中有个 2 个属性,分别是page_content和metadata,metadata就是元数据,我们可以使用metadata属性来过滤掉不符合条件的Document。元数据过滤的方法虽然有用,但需要我们手动来指定过滤条件,我们更希望让 LLM 帮我们自动过滤掉不符合条件的文档。SelfQueryRetriever
- 训练一个排序模型的方式对Topk 进行进一步相关性打分。建议以上游打分 Topk 作为训练数据,特别是结合真实的用户反馈数据。
- 文档重排:LLM 对位置是相对比较敏感的,得分好的放在首或尾,LLM会重点关注。LongContextReorder 。Rerank——RAG中百尺竿头更进一步的神器,从原理到解决方案
- 用户的问题完全不相关怎么处理?
上述一些方法是以时间换效果,并且query改写成多个,多个容易漂移,而且选项太多对于排序也有影响,这个提分不明显,是优化阶段要做的事,重点要放在文本切割上。因此,如何增强大模型自身的知识,或许才是正道?但这明显十分漫长。
- 缓存
- LangChain 提供了 CacheBackedEmbeddings , 可以提高 embedings 的二次加载和解析的效率,首次正常速度,后续有一个 3倍效率的提升。
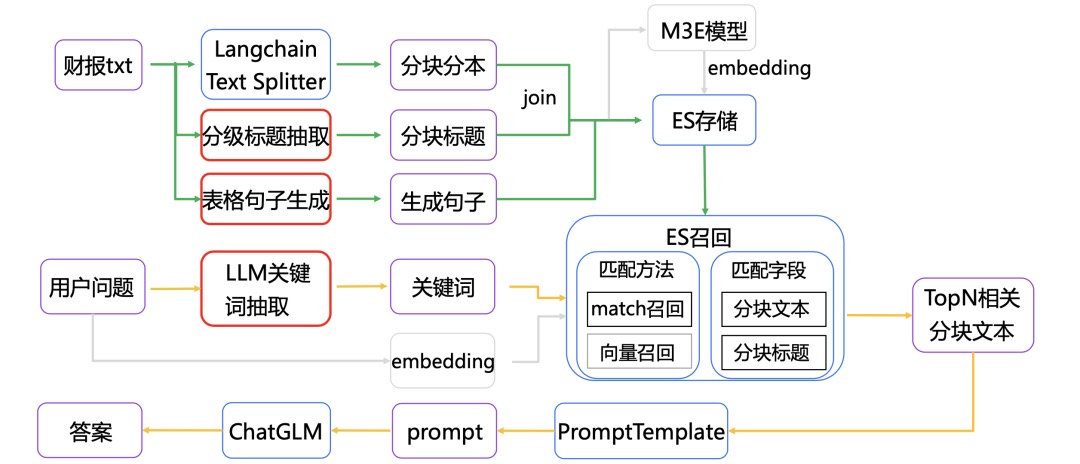
- 基于LLM的关键词抽取 再看RAG在真实金融文档问答场景的实践方案:SMP2023 金融大模型挑战赛的两种代表实现思路
- 采用In-Context Learning的关键词抽取方案。通过构造history,模拟多轮对话的方式进行,让模型能稳定输出json,对于异常json通过调整temperature=1加上retry多次,使其更稳定输出。PS:有点意思,带有历史记录的 icl

- 有监督方案
在专业的垂直领域,待检索的文档往往都是非常专业的表述,而用户的问题往往是非常不专业的白话表达。所以直接拿用户的query去检索,召回的效果就会比较差。Keyword LLM就是解决这其中GAP的。例如在ChatDoctor中会先让大模型基于用户的query生成一系列的关键词,然后再用关键词去知识库中做检索。ChatDoctor是直接用In-Context Learning的方式进行关键词的生成。我们也可以对大模型在这个任务上进行微调,训练一个专门根据用户问题生成关键词的大模型。这就是ChatLaw中的方案。

- 采用In-Context Learning的关键词抽取方案。通过构造history,模拟多轮对话的方式进行,让模型能稳定输出json,对于异常json通过调整temperature=1加上retry多次,使其更稳定输出。PS:有点意思,带有历史记录的 icl
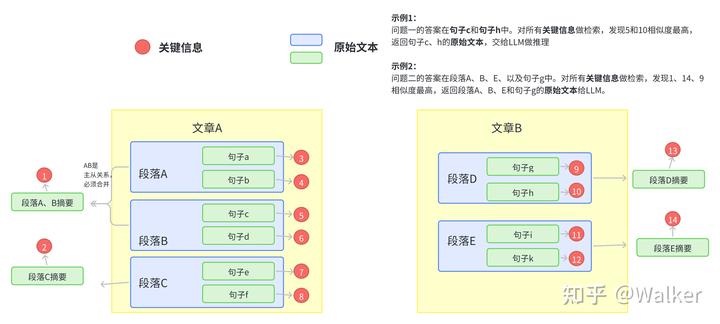
文档切片最好是按照语义切割。
- 将包含主从关系的段落合并,保证每一段在说同一件事情。
- 可以利用NLP的篇章分析(discourse parsing)工具提取出段落之间的主要关系,或利用BERT等模型来实现语义分割。BERT等模型在预训练的时候采用了NSP(next sentence prediction)的训练任务,因此BERT完全可以判断两个句子(段落)是否具有语义衔接关系。这里我们可以设置相似度阈值t,从前往后依次判断相邻两个段落的相似度分数是否大于t,如果大于则合并,否则断开。
- 合并后的段落提取关键信息。
- 利用NLP中的成分句法分析(constituency parsing)工具和命名实体识别(NER)工具提取,前者可以提取核心部分(名词短语、动词短语……),后者可以提取重要实体(货币名、人名、企业名……)。
- 可以用语义角色标注(Semantic Role Labeling)来分析句子的谓词论元结构,提取“谁对谁做了什么”的信息作为关键信息。
- NLP的研究中本来就有关键词提取工作(Keyphrase Extraction)。一个工具是 HanLP ,中文效果好,但是付费,免费版调用次数有限。还有一个开源工具是KeyBERT,英文效果好,但是中文效果差。
- 垂直领域建议的方法。以上两个方法在垂直领域都有准确度低的缺陷,垂直领域可以仿照ChatLaw的做法,即:训练一个生成关键词的模型。ChatLaw就是训练了一个KeyLLM。
- 对关键信息做embedding
- 问题查询时,先query 向量检索到关键信息,再由关键信息找到段落文本
LangChain+LLM大模型问答能力搭建与思考一般通用分段方式,是在固定max_length的基础上,对出现。/;/?/....../\n等等地方进行切割。但这种方式显然比较武断,面对特殊情况需要进一步优化。比如1.xxx, 2.xxx, ..., 10.xxx超长内容的情况,直接按这种方法切割就会导致潜在的内容遗漏。对于这种候选语料”内聚性“很强的情况,容易想到,我们要么在切割语料时动手脚(不把连续数字符号所引领的多段文本切开);要么在切割时照常切割、但在召回时动手脚(若命中了带连续数字符号的这种长文本的开头,那么就一并把后面连续数字符号引领的多段文本一起召回)。笔者目前只想到了这两种方法且还没具体做实验,只是凭空想来,前者方案有较明显瑕疵,因为这样会
- 相对于更短文段而言,长文段的语义更丰富,每个单独的语义点更容易被淹没,所以在有明确语义query的召回下这种长文段可能会吃亏;
- 长文段一旦被召回,只要不是针对整段文本的提问,那么也是引入了更多的噪声(不过鉴于LLM的能力,这可能也无伤大雅,就是费点显存or接口费用了) 但后者就显得更灵活些,不过确实也不够聪明。暂时没想到其他办法,有好想法的人可以来交流一下~此外,有研究表明,长文本作为输入LLM输入时,LLM倾向于更关注长文本的开头、结尾处,然而中间部分的语义可能会被忽略。
对于两个不同检索方式(关键词检索、矢量检索)得到的召回数据,分数范围不一致,一个比较直接的想法就是对分数做归一化,然后把归一化后的数据做权重加和,得到最终分数。
- RRF,比单独的lexical search和单独的semantic search的效果要好,RRF存在两个问题:
- RRF只是对召回的topk数据的顺序进行近似排序计算,并有真正的对数据顺序计算。
- RRF只关注topk数据的位置,忽略了真实分数以及分布信息。
Self-RAG
Self-RAG 框架:更精准的信息检索与生成 未读 也看引入自我反思的大模型RAG检索增强生成框架:SELF-RAG的数据构造及基本实现思路 未读
Self-RAG 及其实现 Self-RAG 主要步骤概括如下:
- 判断是否需要额外检索事实性信息(retrieve on demand),仅当有需要时才召回
- 平行处理每个片段:生产prompt+一个片段的生成结果。PS: query + chunk ==> 带有反思标记(relevant/supported/partital/inrelevant)的chunk
- 使用反思字段,检查输出是否相关,选择最符合需要的片段;
- 再重复检索
- 生成结果会引用相关片段,以及输出结果是否符合该片段,便于查证事实。
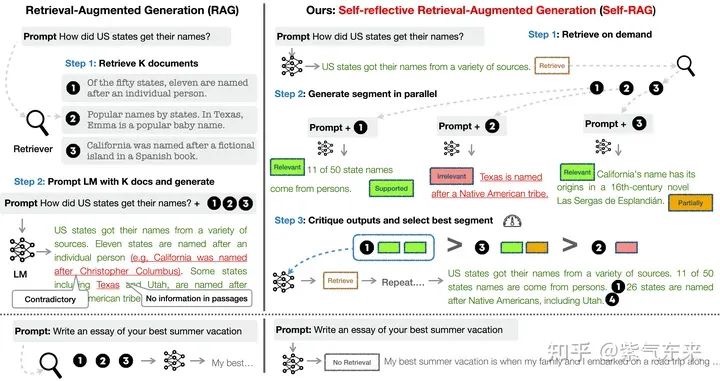
Self-RAG 的一个重要创新是 Reflection tokens (反思字符):通过生成反思字符这一特殊标记来检查输出。这些字符会分为 Retrieve 和 Critique 两种类型,会标示:检查是否有检索的必要,完成检索后检查输出的相关性、完整性、检索片段是否支持输出的观点。模型会基于原有词库和反思字段来生成下一个 token。
要不要微调
如何权衡对需求prompt、continue pretrain 、sft?实时性强的知识以外挂知识库为主,专业的较为稳定的领域知识去微调模型:continue pretain 更多微调领域知识(比如知道感冒是什么),sft 更多是微调领域指令(比如能听懂“给我开个药方”,“下游任务”)。
一般指令数据集都是手工构造的,
目前去评价整体的 QA 系统是有相关测试数据集可以评价的,但是对于 LLM 生成的回答用机器的方法去评价会有遗漏的地方,还是需要人工介入更好。建议整体上对效果的评价分三步走,第一步选出最好的向量模型,第二步选择一个最优的基座 LLM 模型,第三步优化提示词。
- 对于向量模型的效果,可以使用专门用于检索的数据去评价,也可以自己制作相关的数据集去评选出最优的向量模型。
- 使用相同的问题和检索的上下文构建提示词,分别对不同的 LLM 模型输出的结果进行盲审,评选出最优的LLM 模型。
- 使用向量模型召回的 context 和人工筛选出的 context 去利用 LLM 生成回答,并对回答的结果进行验证,定位效果瓶颈。如果人工筛选的 context 结果明显好于向量模型的,则瓶颈在向量召回上,应该去优化向量模型。如果人工筛选的 context 和向量召回的 context 效果差距不大,则瓶颈在 LLM,应该去使用更好的 LLM 或者尝试优化提示词。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK