

vivo 容器平台资源运营实践
source link: https://server.51cto.com/article/777159.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

vivo 容器平台资源运营实践

在Kubernetes中,容器申请资源有request和limit概念来描述资源请求的最小值和最大值。
- requests值在容器调度时会结合节点的资源容量(capacity)进行匹配选择节点。
- limits表示容器在节点运行时可以使用的资源上限,当尝试超用资源时,CPU会被约束(throttled),内存会终止(oom-kill)。
总体而言,在调度的时候requests比较重要,在运行时limits比较重要。在实际使用时,容器资源规格 request 和 limit 的设置规格也一直都让Kubernetes的用户饱受困扰:
- 对业务运维人员:希望预留相当数量的资源冗余来应对上下游链路的负载波动,保障线上应用的稳定性。
- 对平台人员:集群的资源装箱率高,节点利用率低,存在大量的空闲资源无法调度,造成算力浪费。
2.1 vivo容器平台介绍
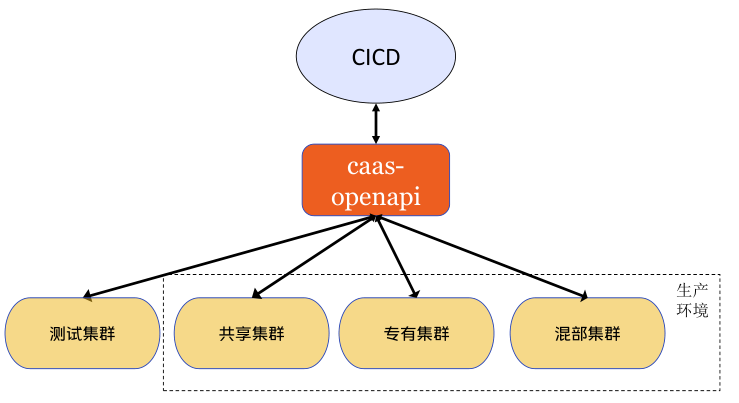
vivo容器平台基于Kubernetes技术对内部业务提供容器服务。内部业务统一在CICD平台部署和管理容器资源,容器平台自研的caas-openapi组件提供restful接口与CICD交互。
平台通过标签,从资源维度逻辑上可以分为测试池、共享池、专有池、混部池。
- 测试池:为业务部署容器测试,一般非现网业务,为业务测试提供便利。
- 共享池:为业务不感知物理机,类似公有云全托管容器服务。
- 专有池:为业务独享物理机,类似公有云半托管容器服务,业务方独占资源,容器平台维护。
- 混部池:为业务独享物理机,在专有池基础上,混部离线业务,缓解离线资源缺口,提升整机利用率。
2.2 资源部署现状和问题
vivo容器平台的所有在线业务部署均要求设置request和limit,且request <= limit,默认情况request等于limit。在共享池中,常见业务request设置会出现如下情况:
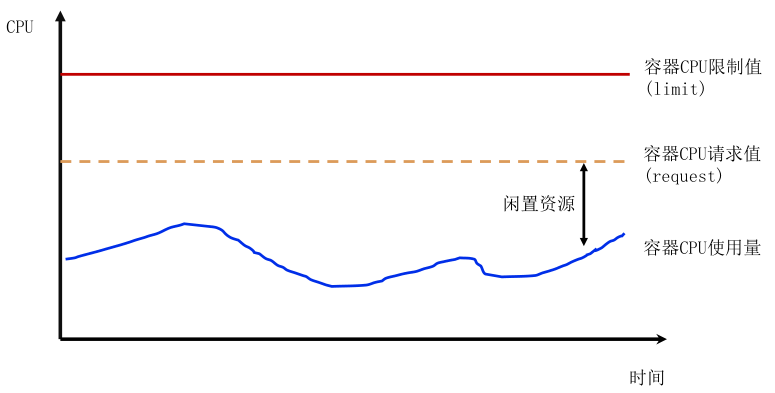
(1) 较少情况,业务设置较低的 request 值,而实际使用资源远大于它的 request 值,若大量pod调度一个节点,加剧节点热点问题影响同节点其他业务。
(2)大多情况,业务按最大资源需求设置较高的 request 值,而实际使用资源长期远小于它的 request 值。业务侧账单成本高(按request计费),且容器异常退出时,重调度时可能因为平台空闲资源碎片,导致大规格容器无法调度。这会导致,平台侧可调度资源少,但平台整体节点资源利用率偏低。
对平台和用户方,request值设置合理很重要,但平台无法直接判断用户设置request值合理性,所以无法首次部署时硬限制。
图片
2.3 资源规格合理性思考
2.3.1 request怎么样才是合理设置
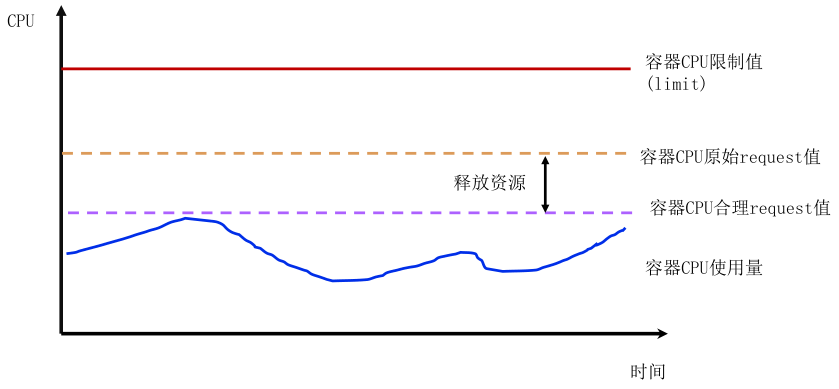
request值接近业务实际使用量,例如用户申请request为2核,limit为4核,实际真实使用量最多1核,那么合理request值设置为1核附近。但是业务真实使用量只有运行一段时间后才能评估,属于后验知识。
2.3.2 保障资源最大使用量
不修改limit值就能保障业务最大使用量符合业务预期。
三、解决方案探索
3.1 静态超卖方案
静态超卖方案是将CICD用户申请规格的request按一定比例降低,根据平台运营经验设置不同集群不同机房不同环境的静态系数,由caas-openapi组件自动修改。如下图:
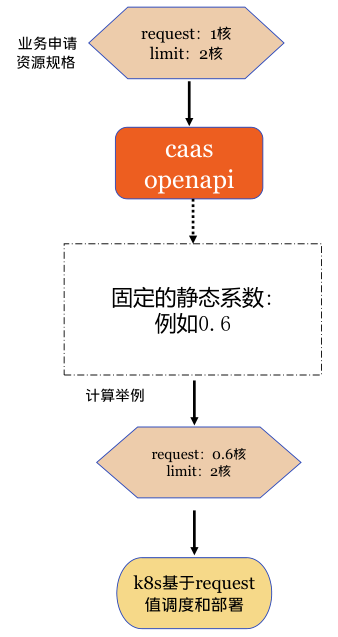
首次部署时可以应用,实现简单。
生产环境系数设置保守,导致request依然偏大,且由于内存是不可压缩资源,实际实施时为避免业务实例内存oom-kill,静态超卖只开启了cpu维度,未开启内存静态超卖。
3.2 动态超卖方案
3.2.1 方案思路
开发caas-recommender组件,基于业务监控数据的真实资源用量来修正业务request值。
- 从监控组件拉取各个容器资源的真实使用量。
- 通过算法模型得到业务申请量的推荐值。
- 业务重新部署时,使用推荐值修改业务request值。
3.2.2 半衰期滑动窗口模型
结合容器业务的特点,对推荐算法有如下要求:
- 当workload负载上升时,结果需要快速响应变化,即越新的数据对算法模型的影响越大;
- 当workload负载下降时,结果需要推迟体现,即越旧的数据对算法结果的影响越小。
半衰期滑动窗口模型可以根据数据的时效性对其权重进行衰减,可以满足上述要求。
详细描述参考:google Borg Autopilot的moving window模型,参看原论文>>
公式如下:
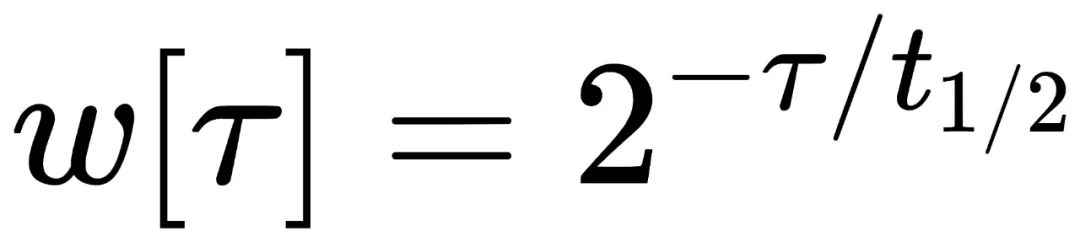
图片
其中 τ 为数据样本的时间点,t1/2 为半衰期,表示每经过 t1/2 时间间隔,前一个 t1/2 时间窗口内数据样本的权重就降低一半。
核心理念:在参考时间点之前的数据点,离的越远权重越低。在参考时间点之后的数据点权重越高。
半衰期halfLife:经过时间halfLife后,权重值降低到一半。默认的halfLife为24小时。
数据点的时间timestamp:监控数据的时间戳。
参考时间referenceTimestamp:监控数据上的某个时间(一般是监控时间最近的零点00:00)。
衰减系数decayFactor:2^((timestamp-referenceTimestamp)/halfLife)
cpu资源的固定权重:CPU 使用量数据对应的固定权重是基于容器 CPU request 值确定的。当 CPU request 增加时,对应的固定权重也随之增加,旧的样本数据固定权重将相对减少。
memory资源的固定权重:由于内存为不可压缩资源,而内存使用量样本对应的固定权重系数为1.0。
数据点权重 = 固定权重*衰减系数
例如现在的数据点的权重为1,那么24小时之前的监控数据点的权重为0.5,48小时前的数据点的权重为0.25,48小时后的数据权重为4。
3.2.3 指数直方图计算推荐值
caas-recommender每个扫描周期(默认1min)从 metrics server 或 prometheus 中获取带时间戳的样本数据,如 container 维度的 CPU、Memory 资源使用等。样本数据结合权重值,为每个workload构建指数直方图,指数直方图中每个桶的大小以指数速率逐步提升。指数直方图的样本存储方式也便于定期checkpoint保存,可以显著提升程序recover性能。如下图:
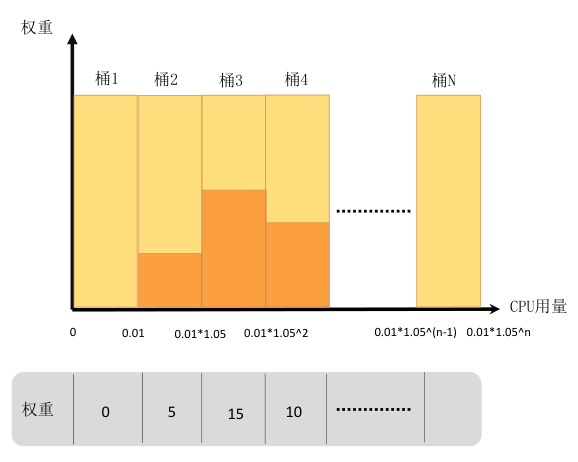
- 指数直方图的横轴定义为资源量,纵轴定义为对应权重,资源量统计间隔以5%左右的幅度增加。
- 桶的下标为N,桶的大小是指数增加的bucketSize=0.01*(1.05^N),下标为0的桶的大小为0.01,容纳范围为[0,0.01),下标为1的桶的大小为0.01*1.05^1=0.0105,容纳范围[0.01-0.0205)。[0.01,173]只需要两百个桶即可完整保存。
- 将每个数据点,按照数值大小丢到对应的桶中。
- 当某个桶里增加了一个数据点,则这个桶的权重增加固定权重*衰减系数,所有桶的权重也增加固定权重*衰减系数。
- 计算出W(95)=95%*所有桶的总权重,如上图仅考虑前4个桶,总权重为20,w(95)权重为19。
- 从最小的桶到最大桶开始累加桶的权重,这个权重记为S,当S>=W(95)时候,这个时候桶的下标为N,那么下标为N+1桶的最小边界值就是95百分位值,如上图N=3时,S>=W(95),95百分位值即为0.01*1.05^2。
比如CPU波动较大且可压缩,采用95%分位值(P95),内存采用99%分位值(P99)。最终得到workload的资源推荐值。
3.2.4 caas-recommender组件流程图
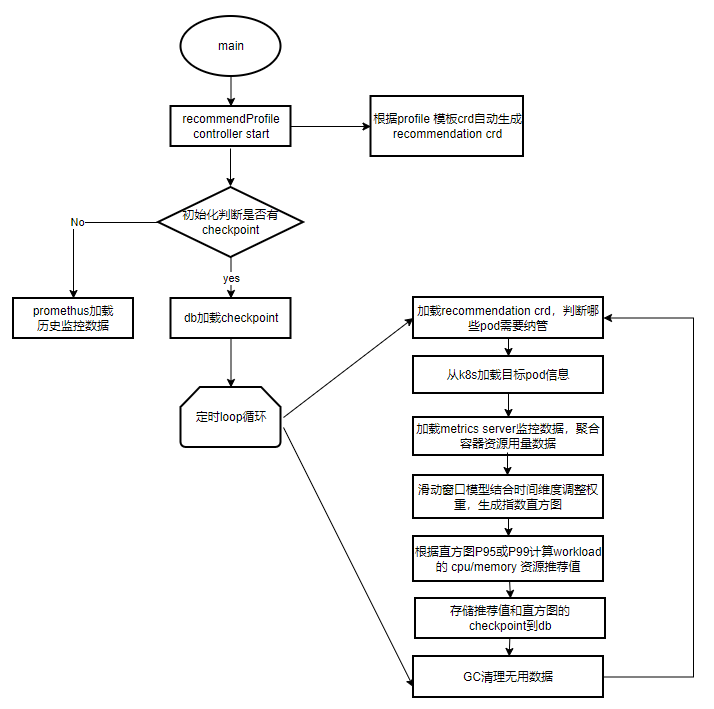
1. 启动controller:profile Controller监听profile template crd,根据profile crd创建相应维度的recommendation crd,可支持namepace\
workload\pod维度。
2. 初始化:
判断是否有checkpoint,若无,可以选择从prometheus拉取数据构建直方图。若有,由checkpoint直接recover。
3. loop循环:
- 从recommendation crd中判断哪些pod需要纳管(pod labels)
- 根据pod label从Kubernetes获取pod信息
- 根据pod的namespace从metrics server拉取监控数据,由container数据汇聚成pod用量数据。
- 构建指数直方图,填充pod用量数据和权重值。
- 根据直方图的分位值计算推荐值
- 存储推荐值和直方图chekpoint
- gc需要删除的recommendation crd或者直方图内存等无用数据。
4.支持原生workload常用类型,拓展支持了OpenKruise相关workload类型。
3.2.5 推荐值校正规则
- 推荐值 = 模型推荐值 * 扩大倍数(可配置)
- 推荐值 < 原生request值:按照推荐值修改
- 推荐值 > 原始request值: 按照原始request修改
- 内存是否修改可以通过配置
- 不修改workload的limit值
3.3 HPA利用率计算逻辑改造
Pod 水平自动扩缩(Horizontal Pod Autoscaler, 简称 HPA)可以基于 CPU/MEM 利用率自动扩缩workload的Pod数量,也可以基于其他应程序提供的自定义度量指标来执行自动扩缩。
原生Kubernetes的HPA扩缩容利用率计算方式是基于request值。若资源超卖,request值被修改后,那么业务设置的HPA失灵,导致容器不符合预期扩缩容。
关于HPA是基于request还是基于limit,目前Kubernetes社区还存在争论,相关 issue 见72811。若需要使用limit计算利用率,可以修改kube-controller-manager源码,或者使用自定义指标来代替。
vivo容器平台兼容业务物理机利用率逻辑,规定内部统一监控系统的Pod利用率均基于limit计算。
HPA改造思路:通过修改kube-controller-manager源码方式实现基于limit维度计算。
- 在pod annotation中记录设置值信息(request值和limit值),以及维度信息(request或limit维度)。
- controller计算pod资源时,判断是否有指定annotation,若有,解析annotation记录值和维度信息计算利用率,若无,使用原生逻辑。
通过上述方式解耦HPA与pod request值,这样平台的资源超卖功能修改request不影响HPA自动扩缩预期。
3.4 专有池支持超卖能力
专有池物理机由业务自行运维管理,从平台角度,不应该随意修改业务的容器request规格。但是专有池业务也有降低容器规格,部署更多业务,复用资源,提高整机利用率的需求。平台默认所有共享池自动开启超卖能力,专有池可配置选择开启超卖能力。
- 可自定义开启超卖类型:静态、动态、静态+动态。
- 可自定义静态系数、动态超卖扩大系数。
- 可配置是否自动修改超卖值,当不自动生效可通过接口查询推荐值,由业务自行修改。
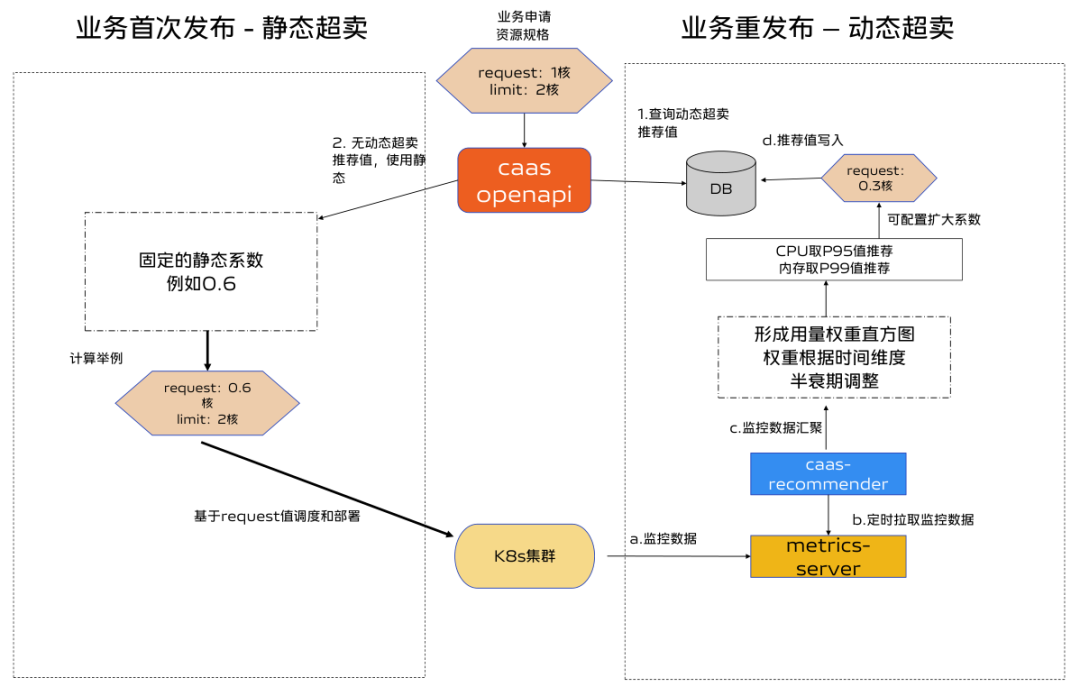
3.5 整体方案
首次部署:
根据先验知识评估,通过固定静态系数修改request值,再根据部署后各个pod监控用量数据,生成workload的request推荐值。
再次部署:
若有推荐值,使用推荐值部署。无推荐值或者推荐值未生效时,使用静态系数。
四、效果和收益
4.1 测试集群收益
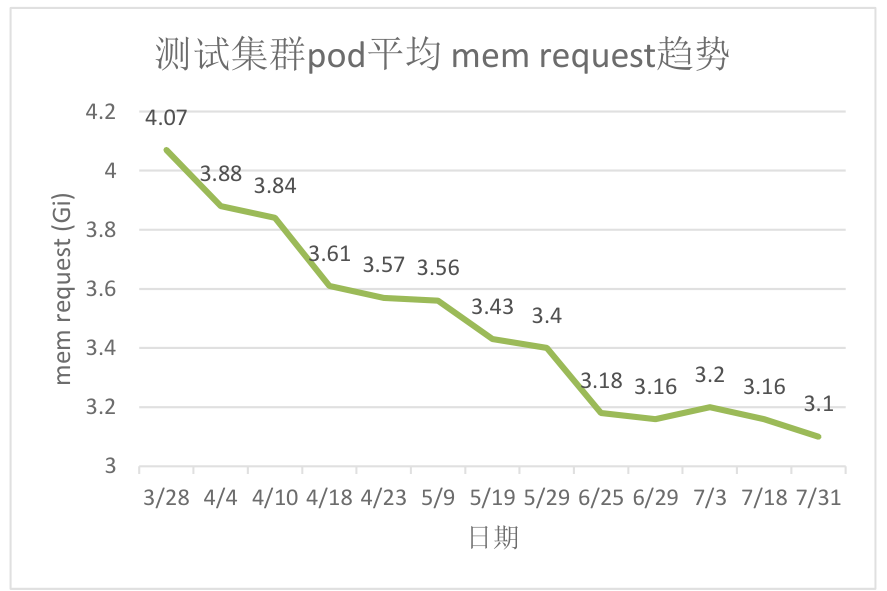
原测试机器的静态超卖系数很低,且只缩减cpu维度资源,导致集群内存成为资源瓶颈。
开启动态超卖能力4个月后,纳管90%的workload,节点pod平均内存request由4.07Gi下降到3.1Gi,内存平台装箱率降低10%,有效缓解集群内存不足问题。
4.2 共享池生产集群收益
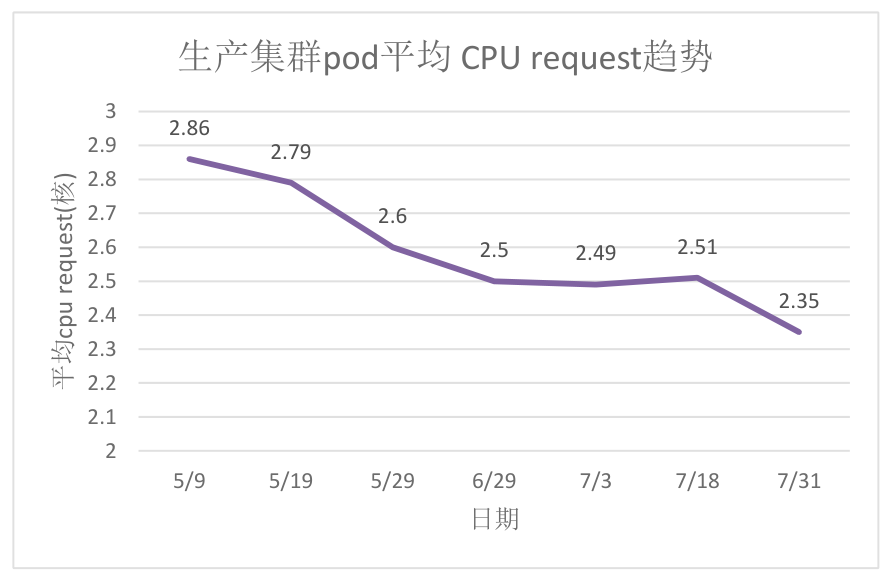
图片
原生产集群静态超卖系数较高,CPU资源装箱率高,导致集群的CPU成为瓶颈。
开启动态超卖能力3个月后,纳管60%的workload,节点pod平均cpu request由2.86降低为2.35,整体cpu利用率相比未开启前提升8%左右。
五、总结与展望
vivo容器平台通过资源超卖方案,将业务容器的request降低到合理值,降低业务使用成本,缓解了集群资源不足问题,达到了提升节点利用率目的。但是当前仅在生产集群开启了CPU资源超卖,规划近期开启内存资源超卖。
未来基于上述方法,可以纳管更多维度,比如GPU卡利用率再结合GPU虚拟化能力,从而提高GPU资源共享效率。根据动态超卖推荐值可以用于构建用户画像,区分业务是计算型或内存型,方便平台更好理解用户特性,辅助资源调度等。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK