

Gemini Pro还不如GPT-3.5,CMU深入对比研究:保证公平透明可重复
source link: https://www.qbitai.com/2023/12/107715.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Gemini Pro还不如GPT-3.5,CMU深入对比研究:保证公平透明可重复

选择题喜欢选D
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
谷歌Gemini实力到底如何?卡耐基梅隆大学来了场专业客观第三方比较。
为保证公平,所有模型使用相同的提示和生成参数,并且提供可重复的代码和完全透明的结果。

不会像谷歌官方发布会那样,用CoT@32对比5-shot了。
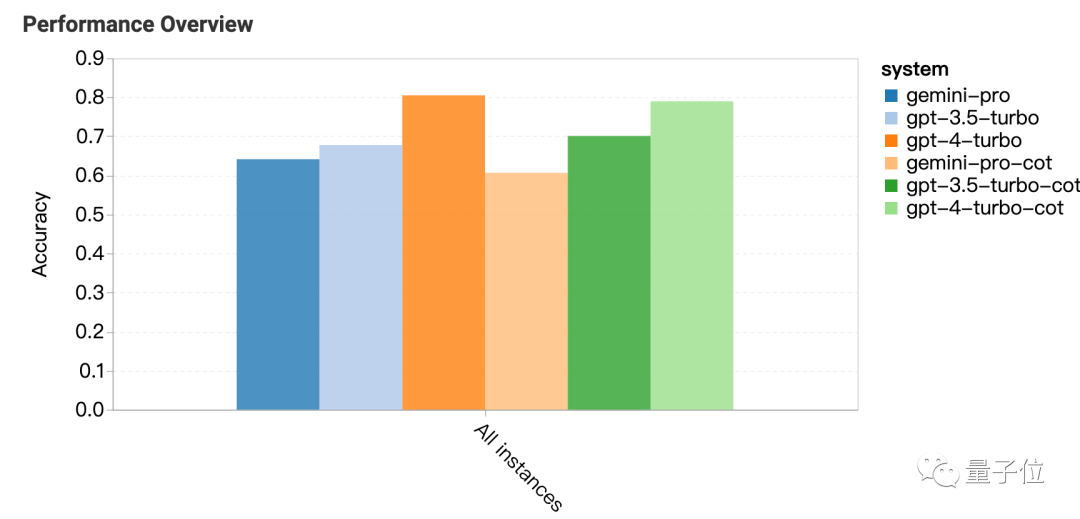
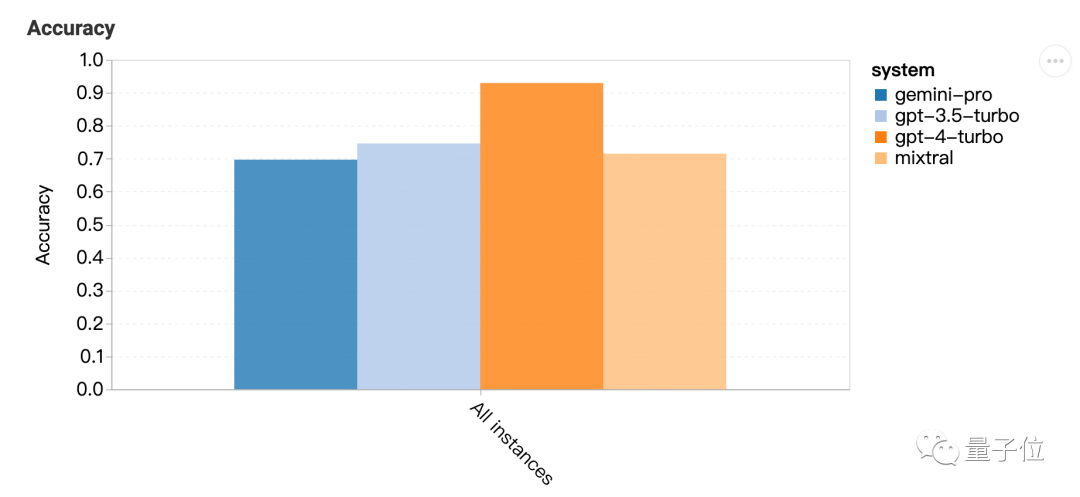
一句话结果:Gemini Pro版本接近但略逊于GPT-3.5 Turbo,GPT-4还是遥遥领先。
在深入分析中还发现Gemini一些奇怪特性,比如选择题喜欢选D……

不少研究者表示,太卷了,Gemini刚发布没几天就搞出这么详细的测试。

六大任务深入测试
这项测试具体比较了6大任务,分别选用相应的数据集:
- 知识问答:MMLU
- 推理:BIG-Bench Hard
- 数学:GSM8k、SVAMP、ASDIV、MAWPS
- 代码:HumanEval、ODEX
- 翻译:FLORES
- 上网冲浪:WebArena
知识问答:
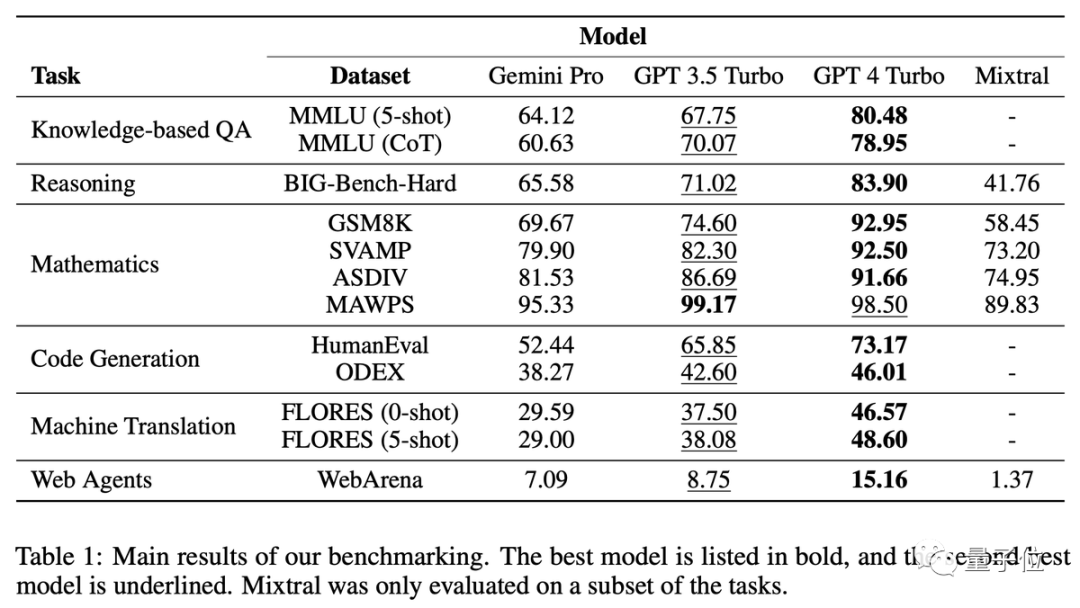
从结果可以看出,使用思维链提示在这类任务上不一定能带来提升。
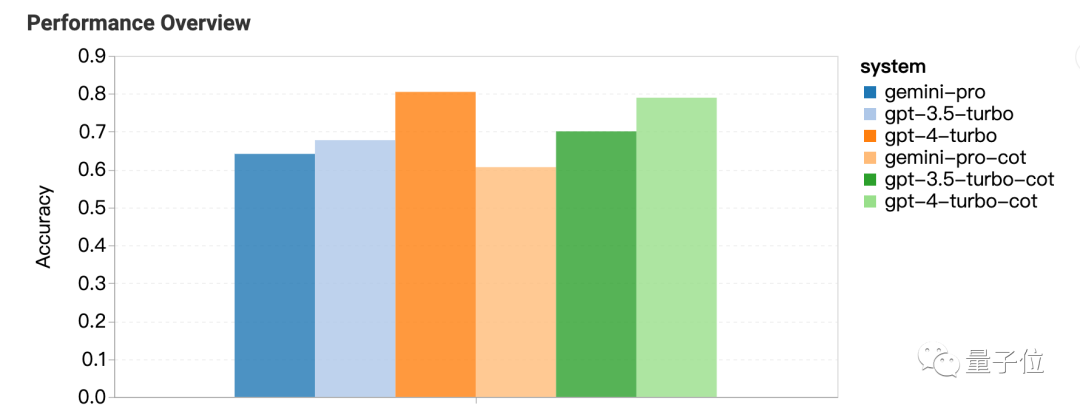
MMLU数据集里都是多选题,对结果进一步分析还发现奇怪现象:Gemini更喜欢选D。
GPT系列在4个选项上的分布就要平衡很多,团队提出这可能是Gemini没针对多选题做大量指令微调造成的。
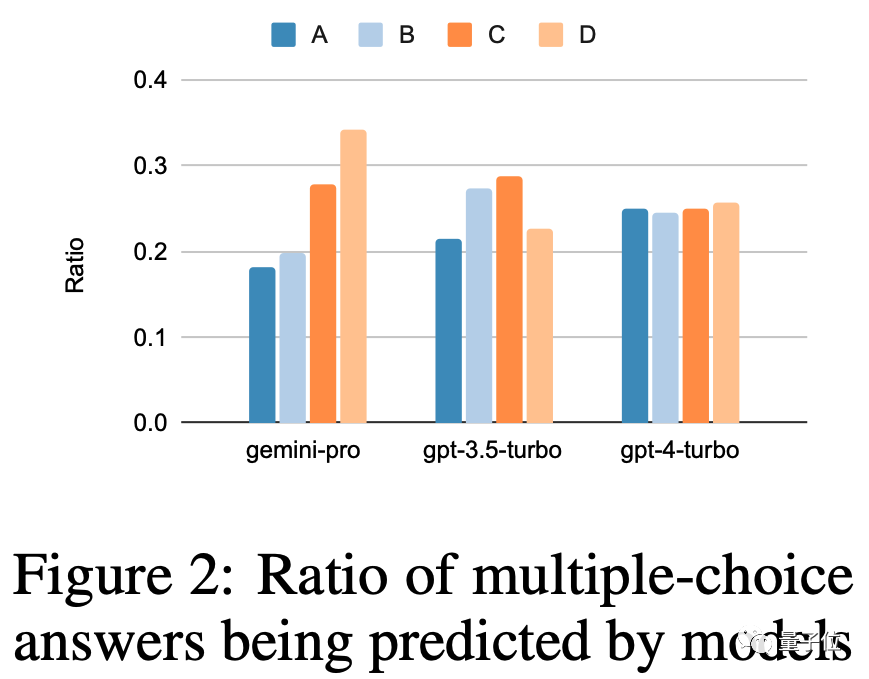
另外Gemini的安全过滤比较严重,涉及道德问题只回答了85%,到了人类性行为相关问题只回答了28%。
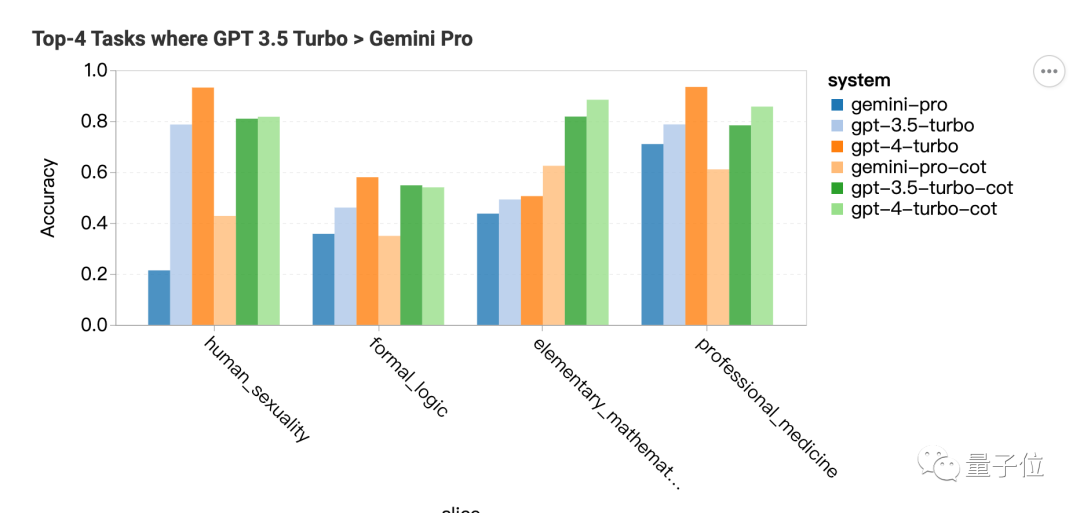
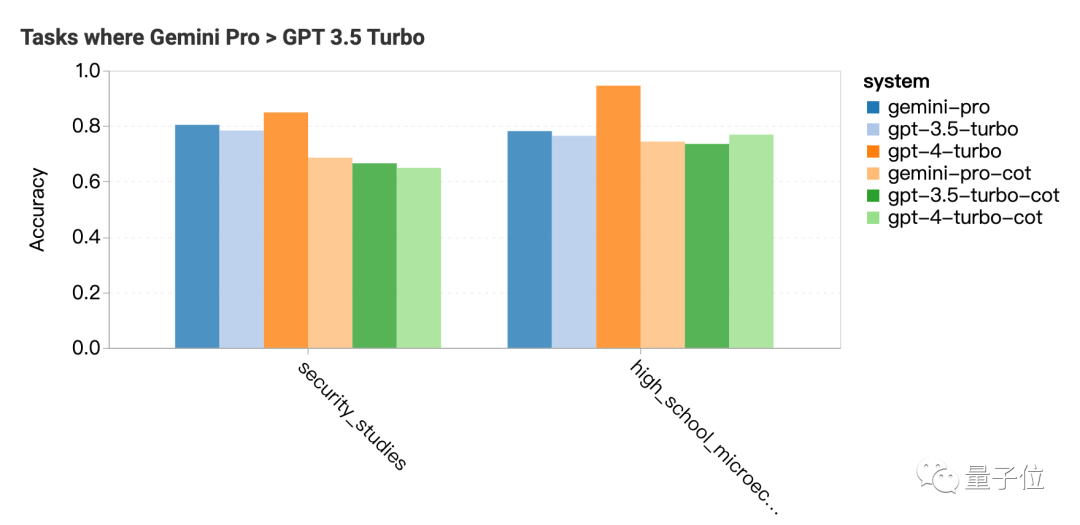
Gemini Pro表现超过GPT-3.5的两个科目是安全研究和高中微观经济学,但差距也不大,团队表示分析不出来什么特别的。
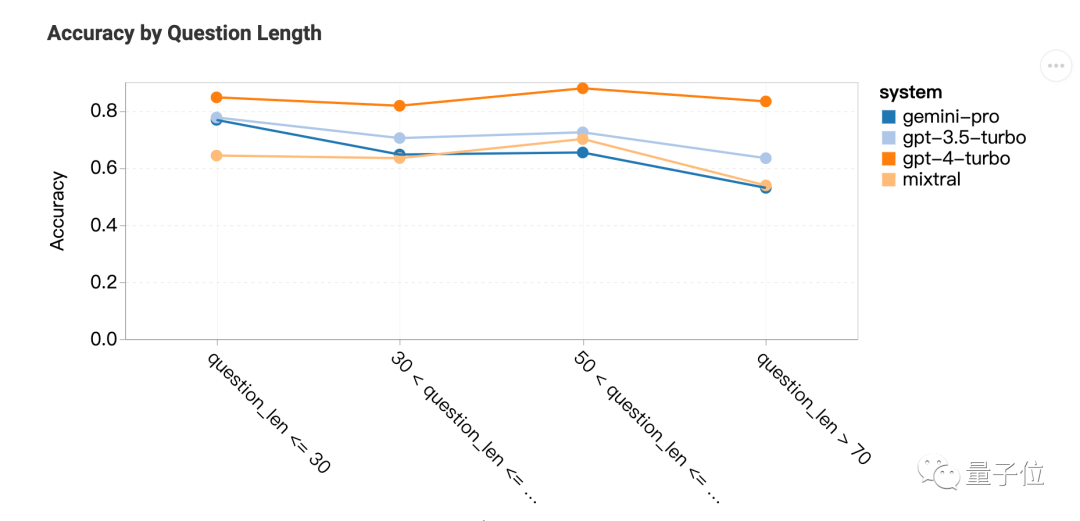
推理:长问题不擅长
Gemini Pro在更长、更复杂的问题上表现不佳,而GPT系列对此更稳健。
GPT-4 Turbo尤其如此,即使在较长的问题上也几乎没有性能下降,表明它具有理解复杂问题的强大能力。
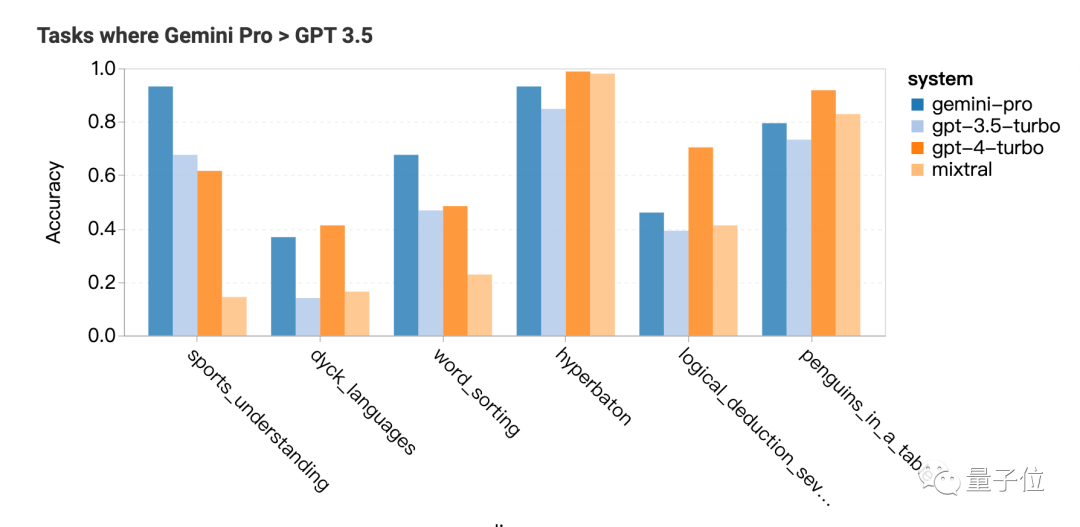
如果按问题类型来分析,Gemini特别不擅长“tracking_shuffled_objects”这类问题,也就人们交换物品,最后让AI判断谁拥有哪些物品。

Gemini比较擅长的任务是,需要世界知识的体育运动理解、操作符号堆栈、按字母顺序排序单词,解析表格。
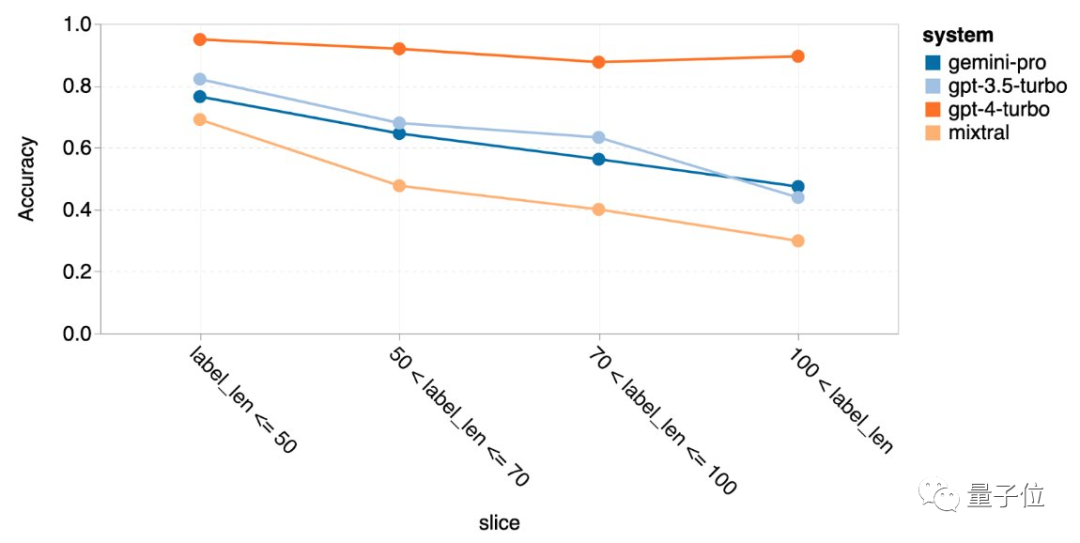
数学:复杂任务反超
这一次问题本身太长Gemini Pro和GPT-3.5表现就一起下降,只有GPT-4还能保持一贯水准。

但使用的思维链提示长度最长时,Gemini反超GPT-3.5。
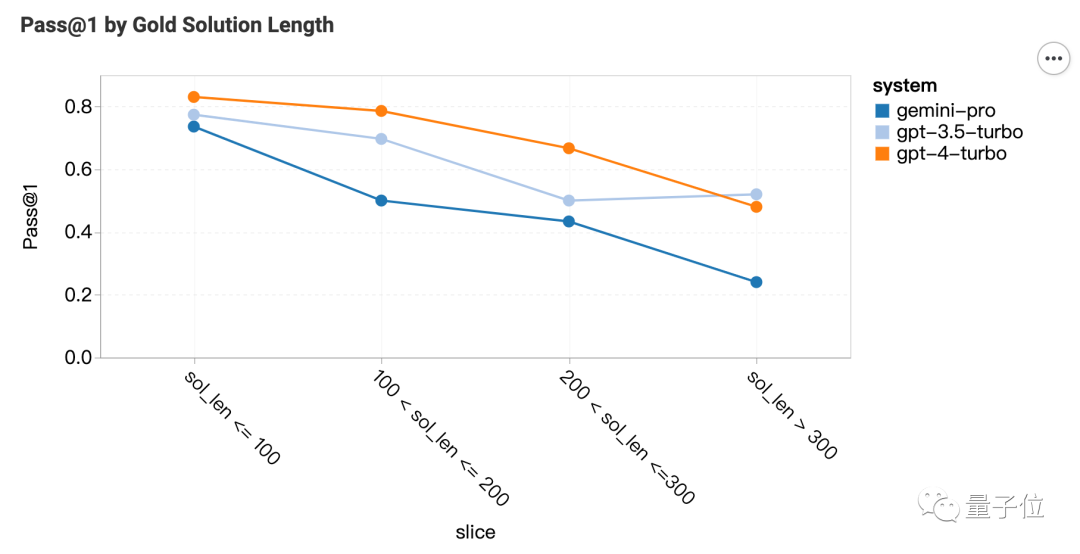
代码:擅长matplotlib
对于代码问题,Gemini在参考答案长的问题上表现很差。
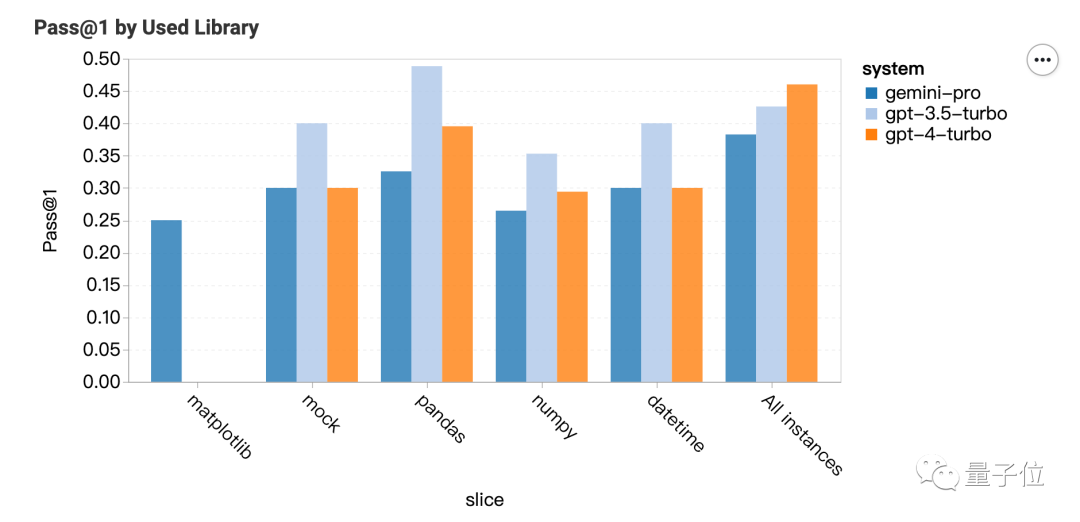
按调用的库来分类,GPT系列在大多数类型更强,但matplotlib就完全不行。
翻译:只要回答了,质量就很高
翻译任务上,有12种类型Gemini拒绝回答,但是只要回答了的翻译质量都很高,整体表现超过GPT-4。
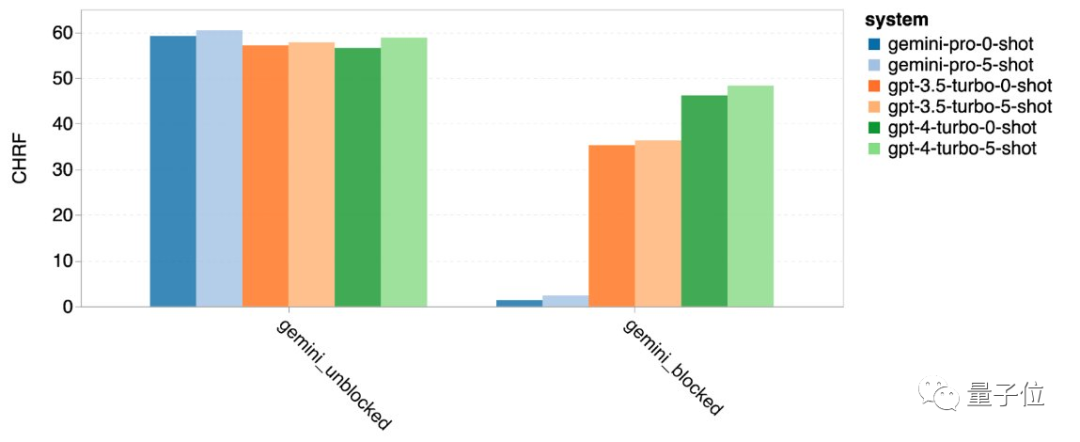
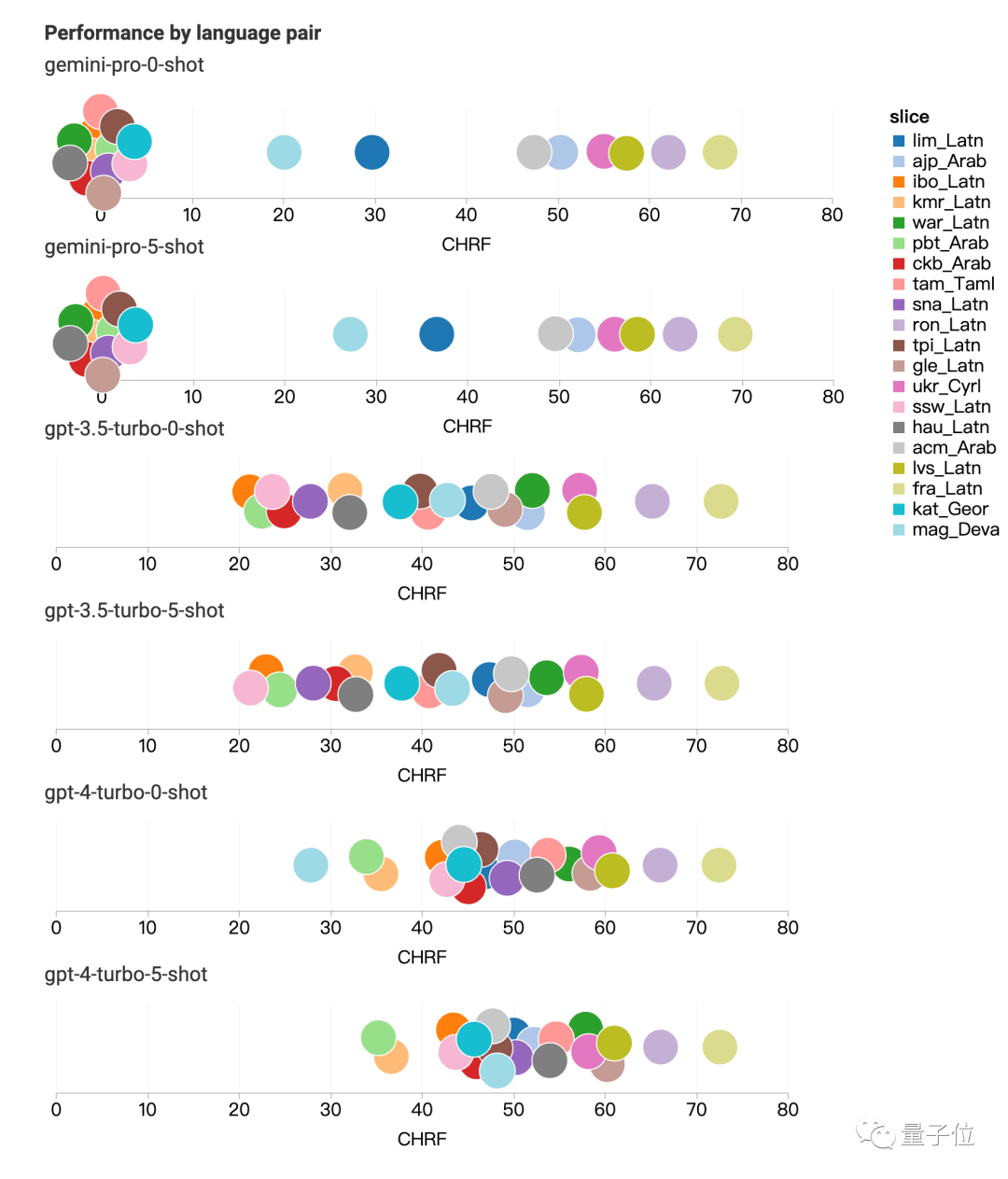
Gemini拒绝翻译的类型主要涉及拉丁语、阿拉伯语。
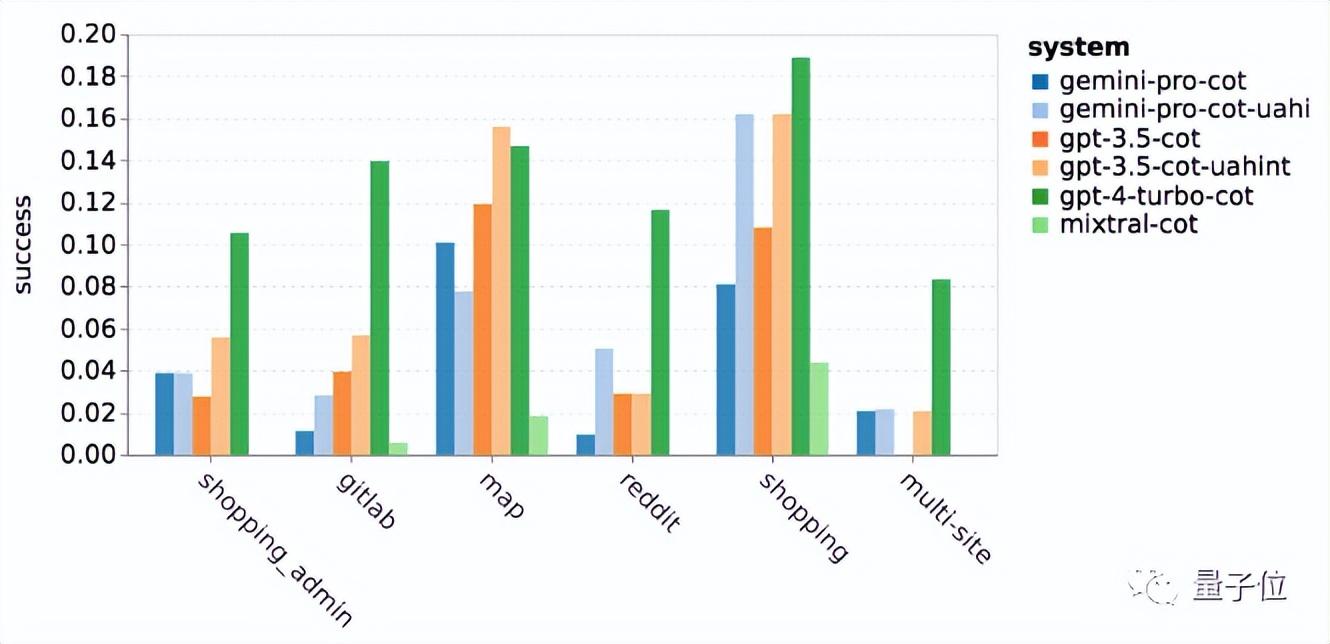
网络导航:擅长跨站点冲浪
WebArena给AI模拟了一个互联网环境,包括电子商务、社交论坛、GitLab协作开发、内容管理系统和在线地图等,需要AI查找信息或跨站点完成任务。
Gemini在整体表现不如GPT-3.5 Turbo,但在跨多个站点的任务中表现稍好。
网友:但是它免费啊
最后,CMU副教授Graham Neubig承认了这项研究的一些局限性。
- 基于API的模型行为可能随时变化
- 只尝试了有限数量的提示,对不同模型来说适用的提示词可能不一样
- 无法控制测试集是否泄露

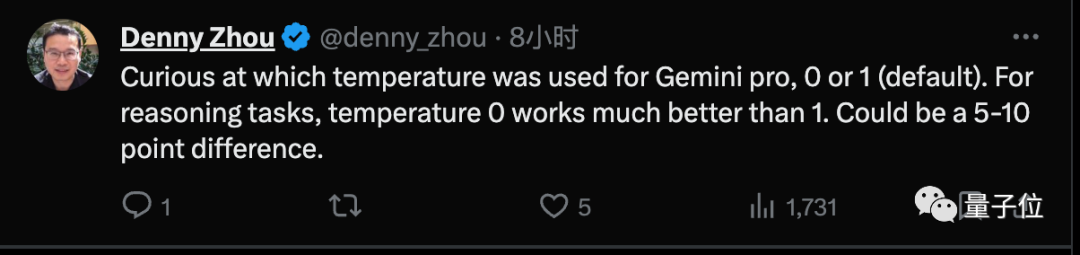
谷歌大模型推理团队负责人周登勇指出,对于推理任务把Gemini的温度设置为0可以提高5-10个百分点。
这项测试中除了Gemini与GPT系列,还搭上了最近很受关注的开源MoE模型Mixtral。
不过强化学习专家Noam Brown认为可以忽略其中Mixtral的结果,因为用的是第三方API而非官方实现。


Mistral AI创始人也来给团队提供了官方版调用权限,认为能得到一个更好的结果。
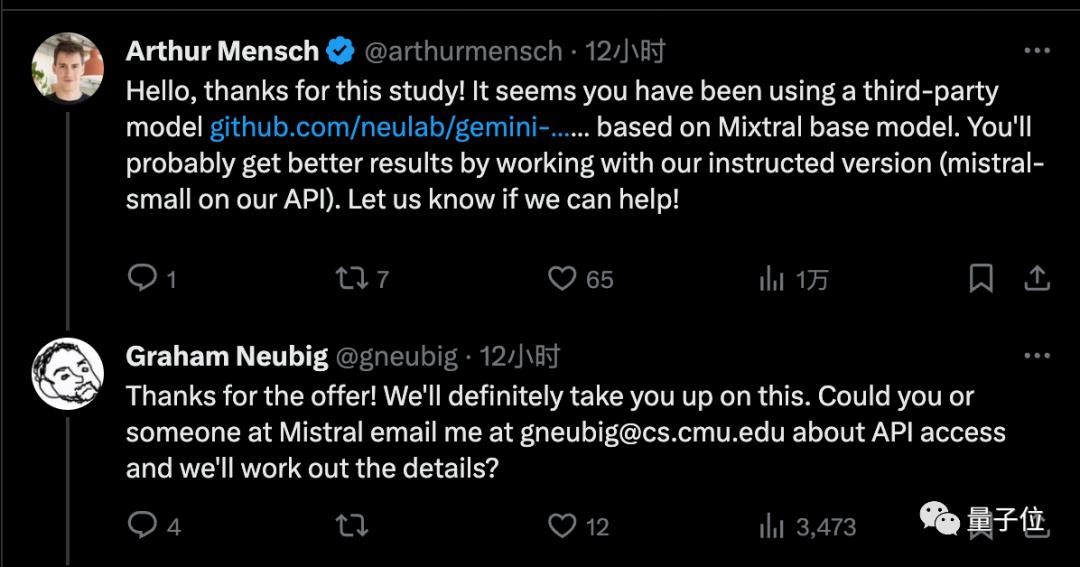
总得来,虽然Gemini Pro还是不如GPT-3.5,但是它胜在每分钟调用不超过60次就免费。
所以还是有不少个人开发者已经转换了阵营。

目前Gemini最高版本Ultra版尚未发布,到时CMU团队也有意继续这项研究。
你觉得Gemini Ultra能达到GPT-4水平么?
论文:
https://arxiv.org/abs/2312.11444
参考链接:
[1]https://twitter.com/gneubig/status/1737108977954251216
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK