

深度学习之目标检测中的常用算法
source link: https://www.51cto.com/article/776994.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
深度学习之目标检测中的常用算法
随着深度学习的不断发展,深度卷积神经网络在目标检测领域中的应用愈加广泛,现已被应用于农业、交通和医学等众多领域。
与基于特征的传统手工方法相比,基于深度学习的目标检测方法可以学习低级和高级图像特征,有更好的检测精度和泛化能力。
什么是目标检测?
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
计算机视觉中关于图像识别有四大类任务:
(1)分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
(2)定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
(3)检测-Detection:解决“在哪里?是什么?”的问题,即定位出这个目标的位置并且知道目标物是什么。
(4)分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
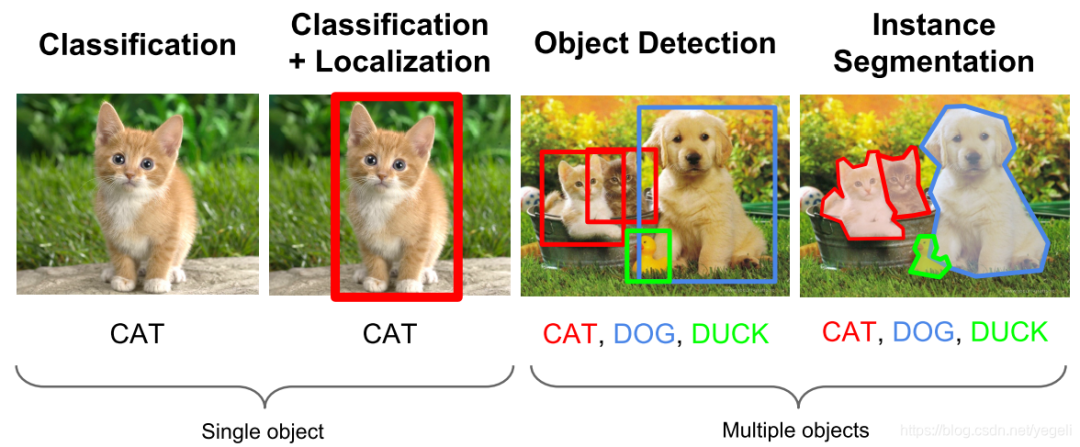
所以,目标检测是一个分类、回归问题的叠加。
目标检测的核心问题:
(1)分类问题:即图片(或某个区域)中的图像属于哪个类别。
(2)定位问题:目标可能出现在图像的任何位置。
(3)大小问题:目标有各种不同的大小。
(4)形状问题:目标可能有各种不同的形状。
目标检测应用
1)人脸检测:智能门控、员工考勤签到、智慧超市、人脸支付、车站、机场实名认证、公共安全
2)行人检测:智能辅助驾驶、智能监控、暴恐检测(根据面相识别暴恐倾向)、移动侦测、区域入侵检测、安全帽/安全带检测
3)车辆检测:自动驾驶、违章查询、关键通道检测、广告检测(检测广告中的车辆类型,弹出链接)
4)遥感检测:大地遥感,如土地使用、公路、水渠、河流监控;农作物监控;军事检测
目标检测算法分类
基于深度学习的目标检测算法主要分为两类:Two stage 和 One stage。
(1)Tow Stage
先进行区域生成,该区域称之为 region proposal(简称 RP,一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
任务流程:特征提取 --> 生成RP --> 分类/定位回归。
常见 tow stage 目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN 和 R-FCN 等。
(2)One Stage
不用 RP,直接在网络中提取特征来预测物体分类和位置。
任务流程:特征提取–> 分类/定位回归。
常见的 one stage 目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD 和 RetinaNet 等。
目标检测模型
1 R-CNN系列
R-CNN 系列算法指的是R-CNN、Fast-RCNN、Faster-RCNN 等一系列由 R-CNN 算法演变出的算法。
这类算法通常是采用两个步骤来实现对目标的定位及检测的,即定位+检测。定位算法通常在 R-CNN 算法中也与很多,详细参照主要包括滑动窗口模型、和选择性收索模型等。然后特征分类网络一般采用 ResNet 系列模型及 VGG 系列模型。当然我们也可尝试使用 GoogleNet 或者 Inception 系列模型进行训练,以提高发杂分类场景中的分类准确性。R-CNN系列模型也被称作为 Two Stage 模型。
(1)R-CNN
R-CNN(全称 Regions with CNN features) ,是 R-CNN 系列的第一代算法,其实没有过多的使用“深度学习”思想,而是将“深度学习”和传统的“计算机视觉”的知识相结合。比如 R-CNN pipeline 中的第二步和第四步其实就属于传统的“计算机视觉”技术。使用 selective search 提取 region proposals,使用 SVM 实现分类。
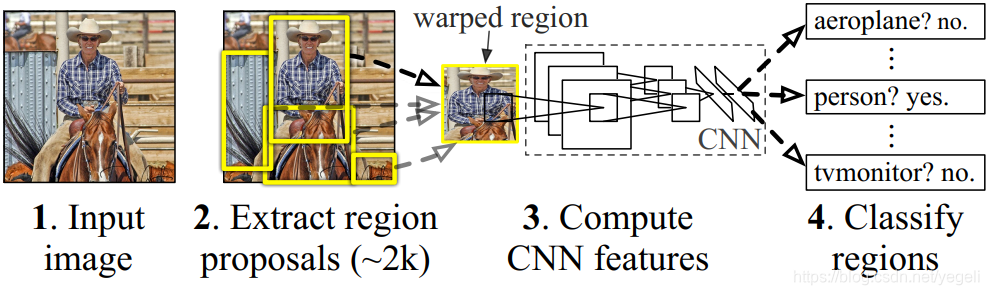
R-CNN 在 VOC 2007 测试集上 mAP 达到 58.5%,打败当时所有的目标检测算法。
- 重复计算,每个 region proposal,都需要经过一个 AlexNet 特征提取,为所有的 RoI(region of interest)提取特征大约花费 47 秒,占用空间。
- selective search 方法生成 region proposal,对一帧图像,需要花费 2 秒。
- 三个模块(提取、分类、回归)是分别训练的,并且在训练时候,对于存储空间消耗较大。
(2)Fast R-CNN
Fast R-CNN 是基于 R-CNN 和 SPPnets 进行的改进。SPPnets,其创新点在于只进行一次图像特征提取(而不是每个候选区域计算一次),然后根据算法,将候选区域特征图映射到整张图片特征图中。
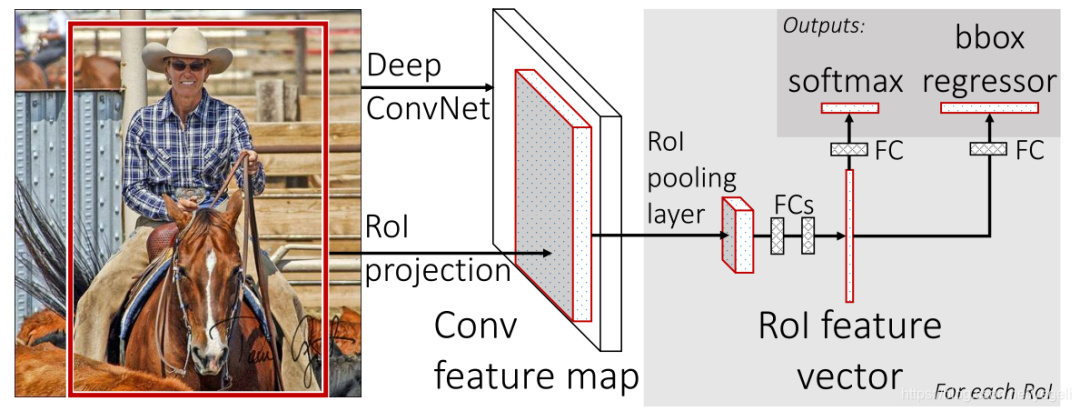
- 和 RCNN 相比,训练时间从 84 小时减少为 9.5 小时,测试时间从 47 秒减少为 0.32 秒。在 VGG16 上,Fast RCNN 训练速度是 RCNN 的 9 倍,测试速度是 RCNN 的 213 倍;训练速度是 SPP-net 的 3 倍,测试速度是 SPP-net 的 3 倍;
- Fast RCNN 在 PASCAL VOC 2007 上准确率相差无几,约在 66~67% 之间;
- 加入 RoI Pooling,采用一个神经网络对全图提取特征;
- 在网络中加入了多任务函数边框回归,实现了端到端的训练。
- 依旧采用 selective search 提取 region proposal(耗时 2~3 秒,特征提取耗时 0.32 秒);
- 无法满足实时应用,没有真正实现端到端训练测试;
- 利用了 GPU,但是 region proposal 方法是在 CPU 上实现的。
(3)Faster RCNN
经过 R-CNN 和 Fast-RCNN 的积淀,Ross B.Girshick 在 2016 年提出了新的 Faster RCNN,在结构上将特征抽取、region proposal 提取, bbox regression,分类都整合到了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
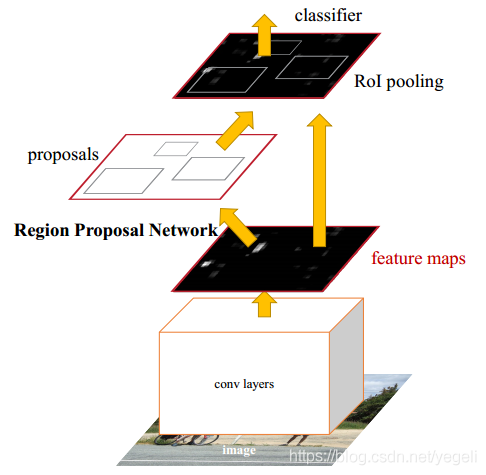
- 在 VOC2007 测试集测试 mAP 达到 73.2%,目标检测速度可达 5 帧/秒;
- 提出 Region Proposal Network(RPN),取代 selective search,生成待检测区域,时间从 2 秒缩减到了 10 毫秒;
- 真正实现了一个完全的 End-To-End 的 CNN 目标检测模型;
- 共享 RPN 与 Fast RCNN 的特征。
- 还是无法达到实时检测目标;
- 获取 region proposal, 再对每个 proposal 分类计算量还是较大。
2 YOLO 系列算法的介绍
YOLO 系列算法目前更新到 YOLOv8。
Yolo 系列算法是典型的 one stage 算法,同样,在算法设计上也注重目标区域的检测以及特征的分类,这里目标区域的检测采用的是和图像区域分类定位的方式实现的。
Yolo 系列算法是一种比较成熟的目标检测算法框架,基于这种框架的算法还在不断地迭代中,当然解决的问题也越来越细化,比如候选区精度、比如小尺度检测等。基本上 YoloV3 及以上版本的算法可以在很多场景下得到现实应用。

2023 年 1 月,目标检测经典模型 YOLO 系列再添一个新成员 YOLOv8,这是 Ultralytics 公司继 YOLOv5 之后的又一次重大更新。YOLOv8 一经发布就受到了业界的广泛关注,成为了这几天业界的流量担当。
首先带大家快速了解下 YOLO 的发展历史。YOLO(You Only Look Once,你只看一次)是单阶段实时目标检测算法的开山之作,力求做到“又快又准”。
2016 年,Joseph Redmon 发布了第一版 YOLO(代码库叫做 darknet),但他本人只更新到 YOLOv3,随后就将 darknet 库交给了 Alexey Bochkovskiy、Chien-Yao Wang 等人,即 YOLOv4 和 YOLOv7 作者团队负责。
2020 年,Ultralytics 公司发布了 YOLOv5 代码库,同年百度发布了 PP-YOLO,2021 年旷视发布了 YOLOX,2022年百度又发布了 PP-YOLOE 及 PP-YOLOE+,随后又有美团、OpenMMLab、阿里达摩院等相继推出了各自的 YOLO模型版本,就在今年年初 Ultralytics 公司又发布了 YOLOv8。同时这些系列模型也在不断更新迭代。
由此可见 YOLO 系列模型算法始终保持着极高的迭代更新率,并且每一次更新都会掀起业界的关注热潮。
此次 Ultralytics 从 YOLOv5 到 YOLOv8 的升级,主要包括结构算法、命令行界面、Python API 等,精度上 YOLOv8 相比 YOLOv5 高出一大截,但速度略有下降。
YOLO系列模型选型指南
为了方便统一YOLO系列模型的开发测试基准,以及模型选型,百度飞桨推出了 PaddleYOLO 开源模型库,支持YOLO 系列模型一键快速切换,并提供对应 ONNX 模型文件,充分满足各类部署需求。
此外 YOLOv5、YOLOv6、YOLOv7 和 YOLOv8 在评估和部署过程中使用了不同的后处理配置,因而可能造成评估结果虚高,而这些模型在 PaddleYOLO 中实现了统一,保证实际部署效果和模型评估指标的一致性,并对这几类模型的代码进行了重构,统一了代码风格,提高了代码易读性。下面的讲解内容也将围绕 PaddleYOLO 相关测试数据进行分析。
总体来说,选择合适的模型,要明确自己项目的要求和标准,精度和速度一般是最重要的两个指标,但还有模型参数量、FLOPs 计算量等也需要考虑。
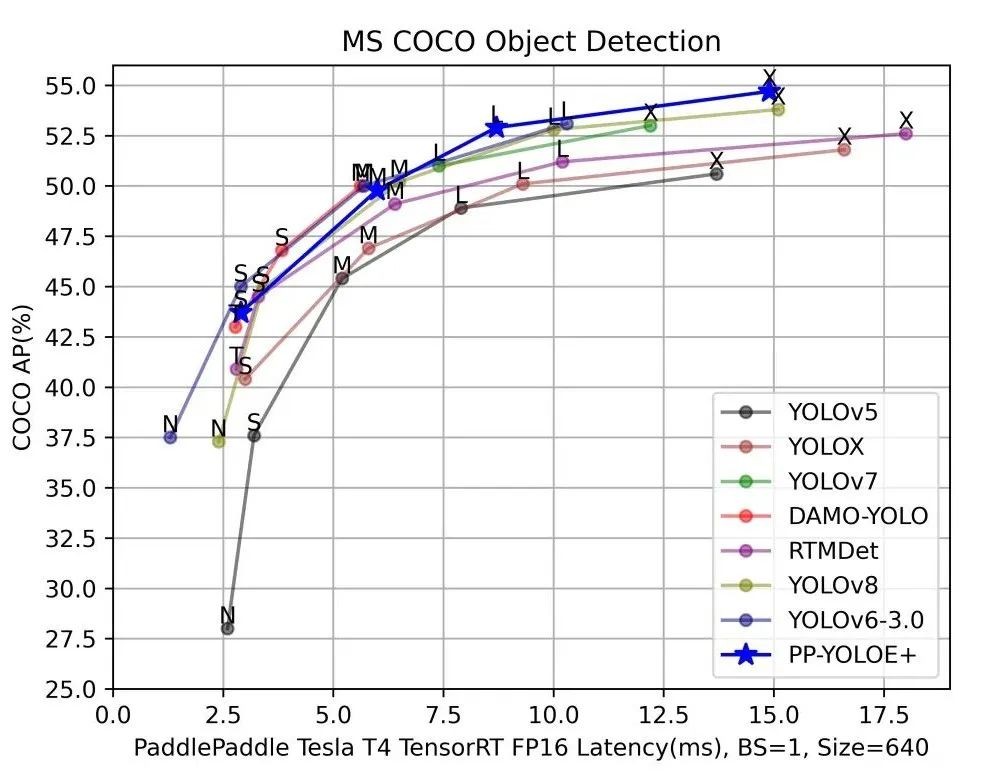
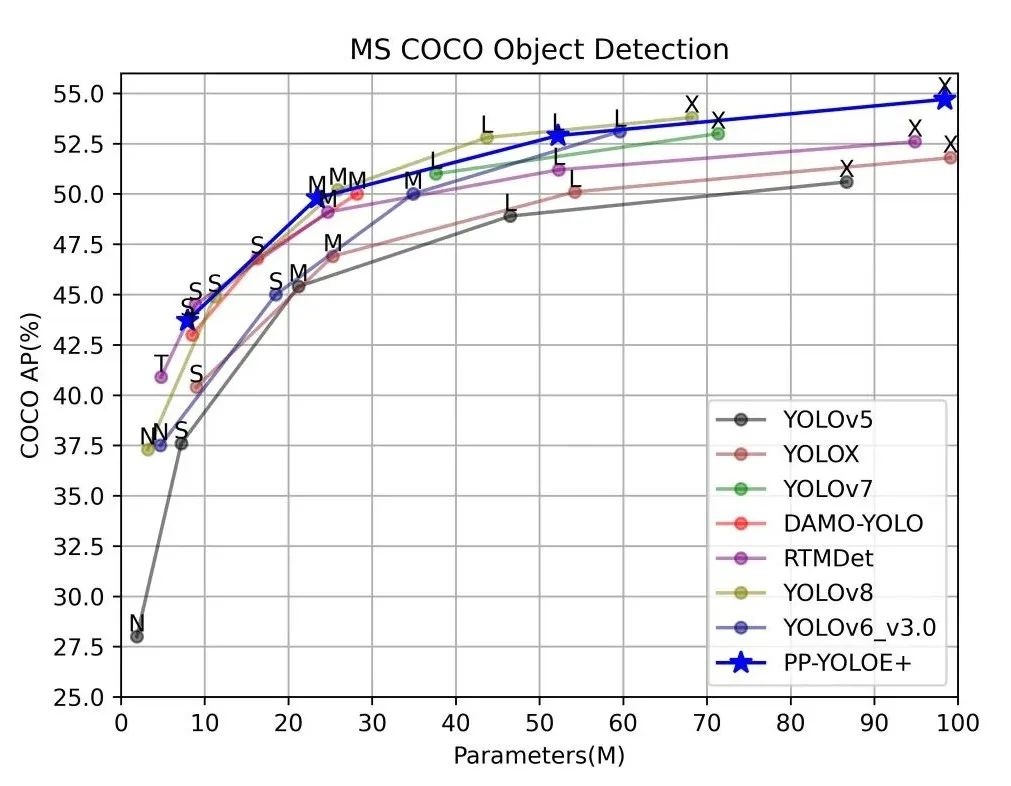
注:以上DAMO-YOLO、YOLOv6-3.0均使用官方数据,其余模型均为Paddle复现版本测试数据。
总之,在这YOLO“内卷时期”要保持平常心,无论新出来什么模型,都需要大致了解下改进点和优劣势后再谨慎选择,针对自己的需求选适合自己的模型。
3 RTMDet——实时目标检测
目标是设计一个高效的实时目标检测器,它超越了YOLO系列(yolov8,yolo-nas没比较),并且易于扩展到许多目标识别任务,如实例分割和旋转目标检测。
为了获得更高效的模型架构,上海人工智能实验室的研究团队研究探索了一种在主干和颈部具有兼容能力的架构,该架构由大内核深度卷积组成的基本构建块组成。在动态标签分配中计算匹配成本时进一步引入软标签以提高准确性。再加上更好的训练技术,最终的目标检测器(名为 RTMDet)在 NVIDIA 3090 GPU 上以 300+ FPS 的速度在 COCO 上实现了 52.8% 的 AP,优于当前主流的工业检测器。
RTMDet 不仅仅在目标检测这一任务上性能优异,在实时实例分割以及旋转目标检测这两个任务中也同样达到了 SOTA 的水平!
RTMDet 针对各种应用场景实现了tiny/small/medium/large/extra-large模型尺寸的最佳参数精度权衡,并在实时实例分割和旋转对象检测方面获得了最先进的性能。
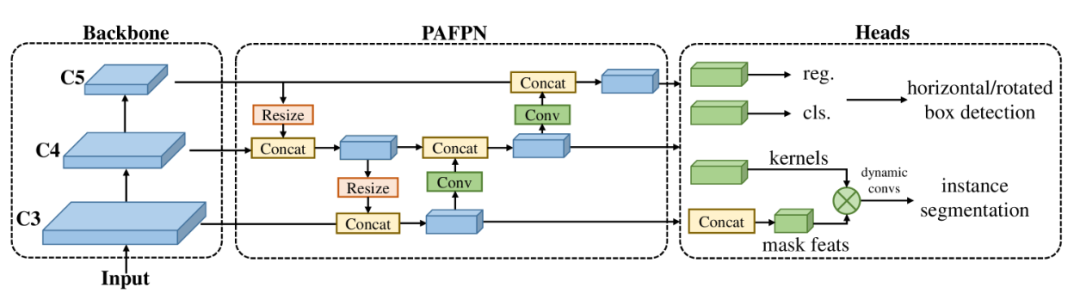
宏观架构。
该研究以《RTMDet: An Empirical Study of Designing Real-Time Object Detectors》为题,于 2022 年 12 月发布在预印平台 arXiv 上。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK