

Snowflake有什么问题及相关解决方案
source link: https://www.luozhiyun.com/archives/820
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Snowflake有什么问题及相关解决方案
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/820
有什么问题
以前写了一篇文章是关于 Snowflake 如何实现的文章,具体可以看这里:https://www.luozhiyun.com/archives/527 。它最早是twitter内部使用的分布式环境下的唯一ID生成算法。在2014年开源。开源的版本由scala编写,大家可以再找个地址找到这版本:https://github.com/twitter-archive/snowflake/tags
它有以下几个特点:
- 能满足高并发分布式系统环境下ID不重复;
- 基于时间戳,可以保证基本有序递增;
- 不依赖于第三方的库或者中间件;
其实它的实现原理也非常的简单,Snowflake 结构是一个 64bit 的 int64 类型的数据。如下:
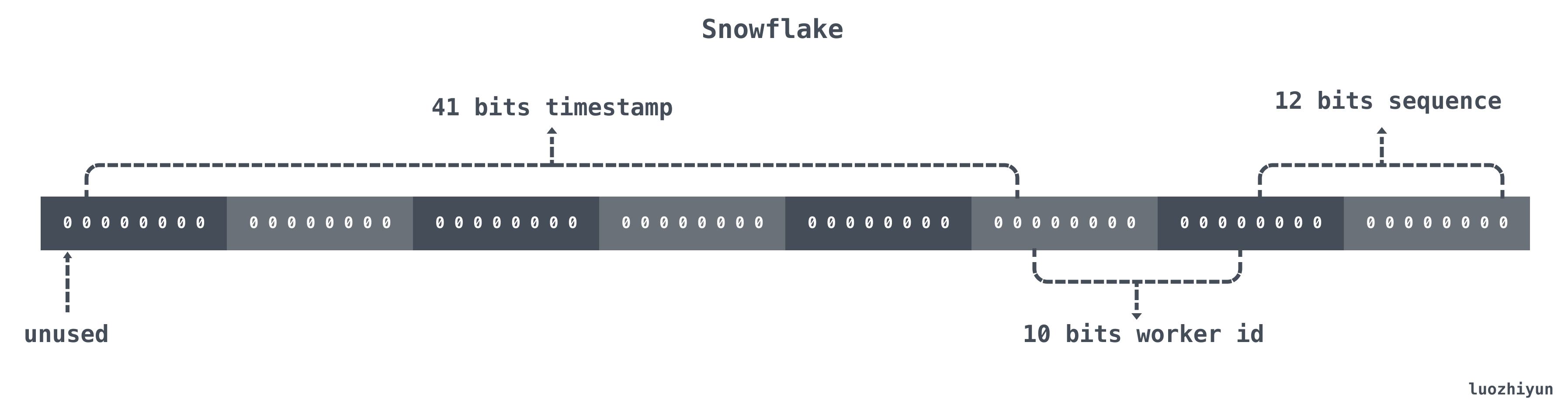
| 位置 | 大小 | 作用 |
|---|---|---|
| 0~11bit | 12bits | 序列号,用来对同一个毫秒之内产生不同的ID,可记录4095个 |
| 12~21bit | 10bits | 10bit用来记录机器ID,总共可以记录1024台机器 |
| 22~62bit | 41bits | 用来记录时间戳,这里可以记录69年 |
| 63bit | 1bit | 符号位,不做处理 |
如果直接使用它的话,也是有不少的缺点:
- 时间回拨问题,它是指系统在运行过程中,可能由于网络时间校准或者人工设置,导致系统时间主动或被动地跳回到过去的某个时间,那么会导致系统不可用,生成的时间戳重复;
- workerId(机器id)的分配和回收,原生算法中,该workerId的分配并没有特殊的处理,更多是人工添加处理;
有什么解决方案呢?
一般的情况,我们可以用当前时间和上一次的时间相对比,如果当前时间小于上一次的时间那么肯定是发生了回拨,发生回拨我们一般也有两种应对策略:
- 如果时间回拨时间较短,比如配置5ms以内,那么可以直接等待一定的时间,让机器的时间追上来;
- 如果时间的回拨时间较长可以添加扩展位,比如当这个时间回拨比较长的时候,我们可以不需要等待,直接在扩展位加1。4位的扩展位允许我们有15次大的时钟回拨,一般来说就够了;
下面举个例子,比如可以从序列号和机器ID里面分4个bit过来,组成 1 个 4 位的时钟 ID:
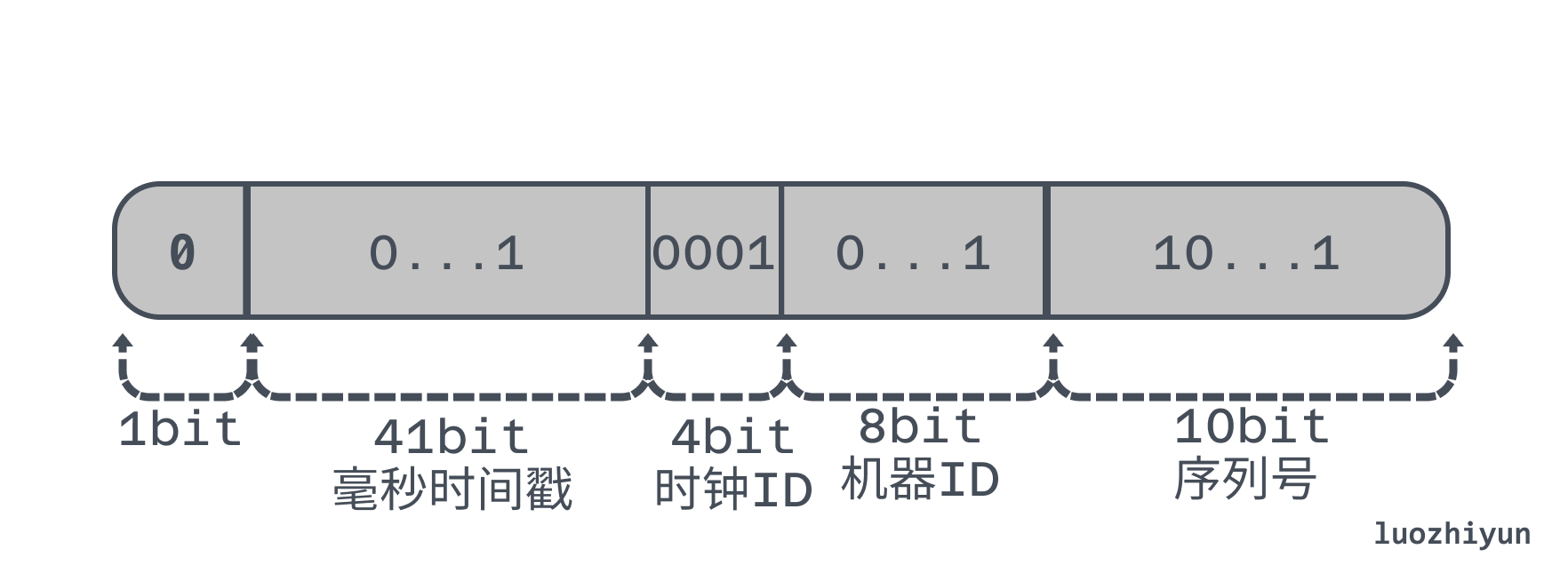
在具体的实现逻辑上,主要是在每次发现时间回拨(即之前最后一次生成 ID 的时间戳大于等于当前时间戳)的时候,便将时钟 ID 加 1,相当于创建一个新的序列号。
那么这样就解决了吗?其实不尽然,仍有一些无法避免的问题:
- 当时间回拨时,ID 递增性会被破坏,对于需要严格递增的场景,需要考虑其他解决方案;
- 如何保证获得全局唯一的机器 ID,也是一个复杂的问题,另外时钟 ID 的引入,会占用额外的比特位,需要综合考虑从哪些比特片段中腾出这些需要留给时钟 ID 的比特位;
- 多时钟雪花算法只是缓解了时钟回拨问题,端情况下的容错方案应该怎么解决;
除了上面这两种方案,还有一种方案就是 butterfly 方案,号称是绝对没有时间回拨问题的方案。主要改进点就是放弃使用机器的当前时间戳来做递增,而是采用历史时间,这是核心所在,具体做法是:
- 在进程启动后,我们会将当前时间(实际处理采用了延迟10ms启动)作为该业务这台机器进程的时间戳中的起始时间字段;
- 每次有数据请求,直接对序列号增加即可,序列号从0增加到最大,到达最大时,时间戳字段增加1,其实是时间增加1毫秒,序列号重0计算;
但是这样做也有个问题,就是分布式ID中的时间信息可能并不是这个ID真正产生的时间点,丢失了这部分信息,如果业务中有需要用到的话,该方法是不合适的。
再来就是 workId 分配的问题,一般有如下几种方案:
- zookeeper分配:一般是在ZK上寻找一个节点注册,然后获取到相应的 workid,然后每间隔一定时间定时上报一下,如果节点已过期表示可重用;
- db分配:db分配其实也差不多,建立一个表workerId分配表,每次分配节点的时候从最小的id开始查找,找到则获取workid,然后定时上报;
下面我还找了两个优秀的实现分别是美团的 Leaf-snowflake 、百度 UidGenerator 来看看它们是怎么实现的。
美团 Leaf-snowflake
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,没有对snowflake做什么改动,但是Leaf-snowflake 依赖 Zookeeper 持久顺序节点的特性自动对snowflake节点配置wokerID:
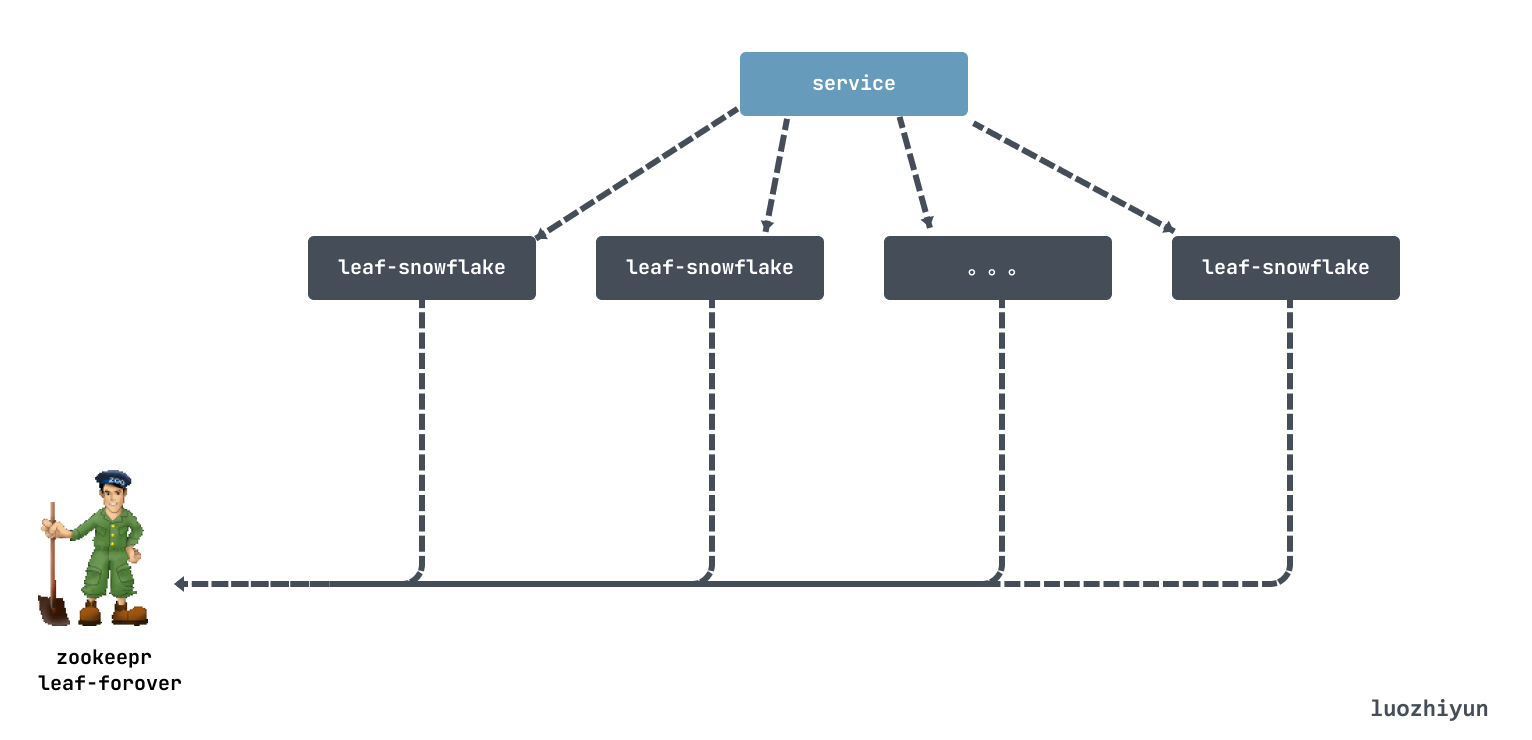
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过;
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务;
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务,拿取workerID后,会在本机文件系统上缓存一个workerID文件,即使ZooKeeper出现问题也能保证服务正常运行;
那么 Leaf-snowflake 是解决保证时钟回拨的问题呢,答案是不解决,直接抛错,这样可以避免递增性被破坏,做多也只是重新去获得一次 ID 而已。具体情况如下:
-
Leaf-snowflake 服务若写过 ZK ,那么会去和 ZK 自己上报过的
leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警; -
Leaf-snowflake 服务若没写过 ZK ,证明是新服务节点,直接创建持久节点
leaf_forever/${self}并写入自身系统时间。- 接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确;
- 取leaf_temporary下的所有临时节点,然后RPC请求获取所有节点的系统时间,计算
sum(time)/nodeSize; - 若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动并进行续约;
- 否则认为本机系统时间发生大步长偏移,启动失败并报警;
- 每隔3s会上报自身系统时间并写入ZK;
其实深度思考一下,美团的 Leaf-snowflake 问题还蛮多的,我随便说两个点:
-
这个问题是我朋友 @NianniaN 提出来的:3s上报一次ZK可能会有问题的。比如一个节点正在运行,它不知不觉地快了1s。由于某种原因,它突然挂起,在1s内重新启动。重新启动后,它的时间恢复到正常状态,因为上一个报告周期是3s前,因此系统有可能成功启动。是否有可能会重复的ID,leaf重启的时间校验也是非常粗狂的,直接判断一下时间就结束了:
private boolean checkInitTimeStamp(CuratorFramework curator, String zk_AddressNode) throws Exception { byte[] bytes = curator.getData().forPath(zk_AddressNode); Endpoint endPoint = deBuildData(new String(bytes)); //该节点的时间不能小于最后一次上报的时间 return !(endPoint.getTimestamp() > System.currentTimeMillis()); } -
这个问题是网友 @NotFound9 提出来的,依赖ZK可能也会有问题。如果启动时连接zookeeper失败,会去本机缓存中读取workerID.properties文件,读取workId进行使用,但是由于workerID.properties中只存了workId信息,没有存储上次上报的最大时间戳,所以没有进行时间戳判断,所以如果机器的当前时间被修改到之前,就可能会导致生成的ID重复;
百度 UidGenerator
百度的Snowflake算法的结构上做了一些改变:

- sign(1bit)
固定1bit符号标识,即生成的UID为正数。 - delta seconds (28 bits)
当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年 - worker id (22 bits)
机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。 - sequence (13 bits)
每秒下的并发序列,13 bits可支持每秒8192个并发。
它通过采取如下一些措施和方案规避了时钟回拨问题和增强唯一性:
- workerId在实例每次重启时初始化,它的ID是数据表的自增ID,保证了唯一性。由于workerId默认22位,那么所有实例重启次数是不允许超过4194303次(即2^22-1),否则会抛出异常;
- 内部利用了一个 RingBuffer 数据结构预先生成若干个分布式ID并保存,不需要每次都实时计算从而提升性能;
- UidGenerator 根据时间递增其实也是和 butterfly 方案一样,用的是历史时间来做的,UidGenerator的时间类型是 AtomicLong,且通过
incrementAndGet()方法获取下一次的时间,从而脱离了对服务器时间的依赖;
总体上看了几种实现可以说解决时间回拨的方案是比较固定的,一般来说就是:
- 如果时间回拨时间较短,比如配置5ms以内,那么可以直接等待一定的时间,让机器的时间追上来;
- 如果时间的回拨时间较长可以添加扩展位,比如当这个时间回拨比较长的时候,我们可以不需要等待,直接在扩展位加1;
- 或者出现时间回拨直接拒绝报错,类似Leaf-snowflake的实现;
- 再来就是可以像 butterfly 一样,使用历史时间,每次 sequence 用完之后直接在时间序列上自增1就好了;
再来就是 workId 分配的问题,一般有如下几种方案:
- zookeeper分配:一般是在ZK上寻找一个节点注册,然后获取到相应的 workid,然后每间隔一定时间定时上报一下,如果节点已过期表示可重用;
- db分配:db分配其实也差不多,建立一个表workerId分配表,每次分配节点的时候从最小的id开始查找,找到则获取workid,然后定时上报;
Reference
https://github.com/SimonAlong/Butterfly
https://tech.meituan.com/2017/04/21/mt-leaf.html
https://tech.meituan.com/2019/03/07/open-source-project-leaf.html
https://blog.hackerpie.com/posts/algorithms/snowflake/multiple-clocks-snowflake/
https://www.jianshu.com/p/b1124283fc43
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK