

每天5分钟复习OpenStack(九)存储发展史 - ALEX_li88
source link: https://www.cnblogs.com/alex0815/p/17822852.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

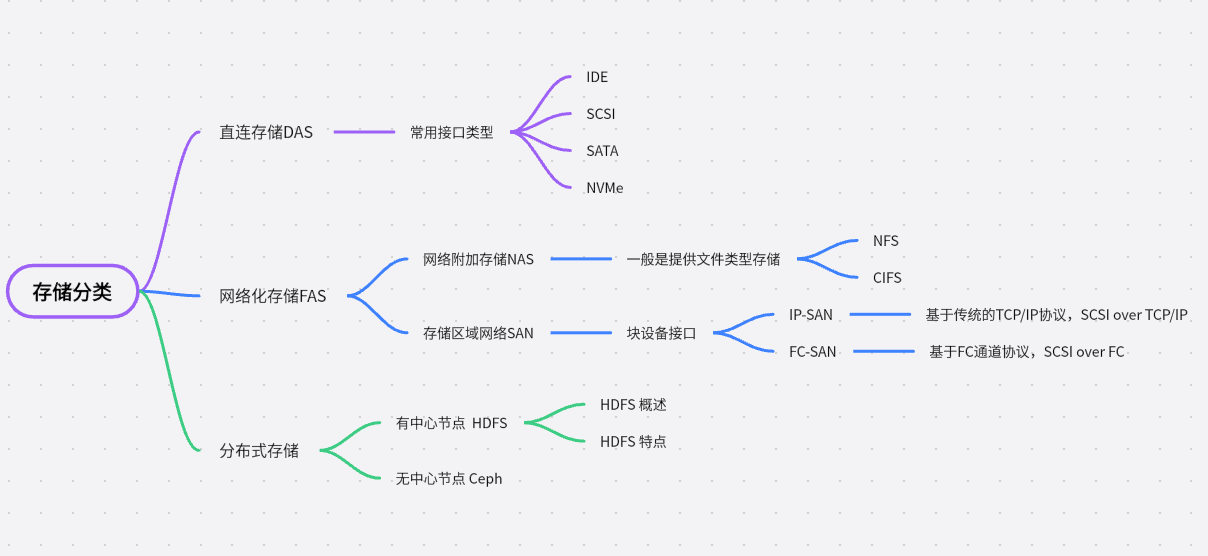
上一章节我们介绍了使用本地硬盘做kvm的存储池,这章开始将介绍下存储的发展历程,并介绍什么是分布式存储,为什么HDFS为有中心节点的分布式存储?
1、存储发展
- 在单机计算时代(大型机、小型机、微机),内部存储器可以理解为内存(即Memory),外部存储器可以理解为物理硬盘(包括本地硬盘和通过网络映射的逻辑卷.
外部存储根据连接方式不同,又可以分为DAS(Direct-attached Storage)直连存储或直接附加存储。网络化存储 Fabric-Attached Storage,简称FAS);
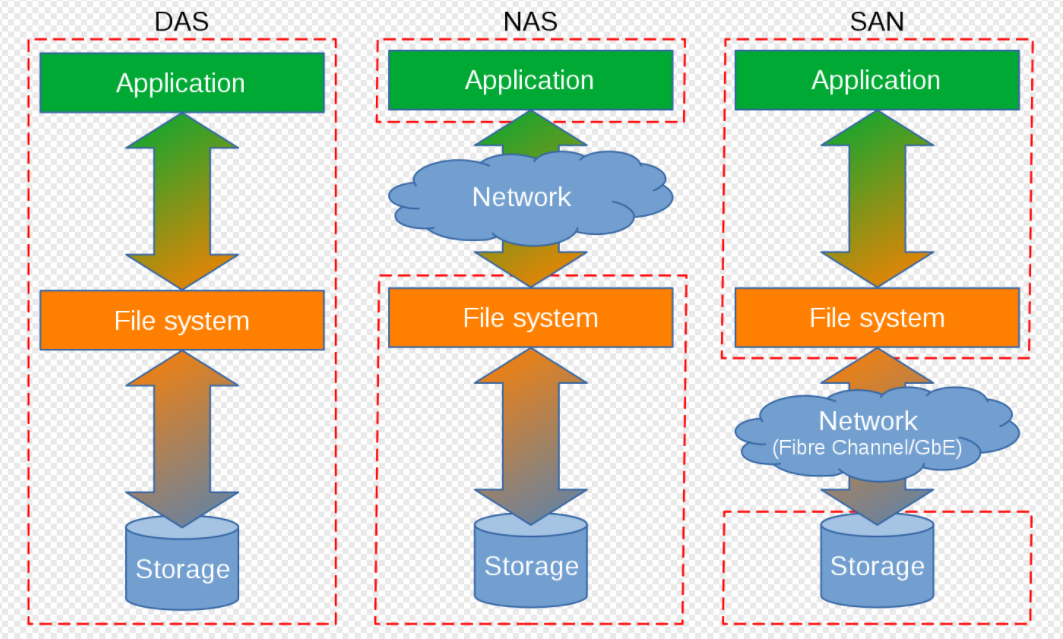
而网络化存储根据传输协议又分为:网络附加存储 NAS (Network-Attached Storage)和存储区域网络SAN(Storage Area Network)。 (此概念容易弄混,N对应network 网络, NAS 也可以理解为网络附加存储,即将存储协议在常用网络中传输。S 开头 storage 存储,存储区域网络其强调的是专用的网络)
其分类如下思维导图:
- 直接存储:(DAS)很好理解,一般是通过专用线缆如IDE 、SCSI线直接将外部存储连在服务器的内部总线上,可以理解为
存储设备只与一台主机互联。此时常用的接口类型有 IDE、SCSI、SATA、NVMe,如下图是VMware软件上添加磁盘时提供的接口选项。

-
网络化存储: 则是通过网络传输来提供的存储能力,如果提供的是文件类型的存储如NFS、CIFS,则其一般是NAS 存储。如果提供的是块设备的接口类型,则其是SAN存储。(通常是这样,但是其分类与提供的磁盘类型无关。)
-
FC-SAN: 而根据传输协议的不同,在数据链路层有专用的光纤通道协议,依赖存储设备组成单独的网络,大多利用光纤连接,采用
光纤通道协议(Fiber Channel,简称FC)。服务器和存储设备间可以任意连接,I/O请求也是直接发送到存储设备。光纤通道协议实际上解决了底层的传输协议,高层的协议仍然采用SCSI协议,所以光纤通道协议实际上可以看成是SCSI over FC -
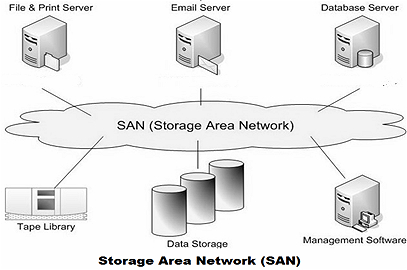
IP-SAN: 如果SAN是基于
TCP/IP的网络,实现IP-SAN网络。这种方式是将服务器和存储设备通过专用的网络连接起来,服务器通过“Block I/O”发送数据存取请求到存储设备。最常用的是iSCSI技术,就是把SCSI命令包在TCP/IP包中传输,即为SCSI over TCP/IP。
(注*在OpenStack 为主的IAAS场景中,IP-SAN和FC-SAN作为专业的存储设备与OpenStack进行对接是很常见的场景。了解其基本原理还是很有必要的。)
2、FC-SAN VS IP-SAN
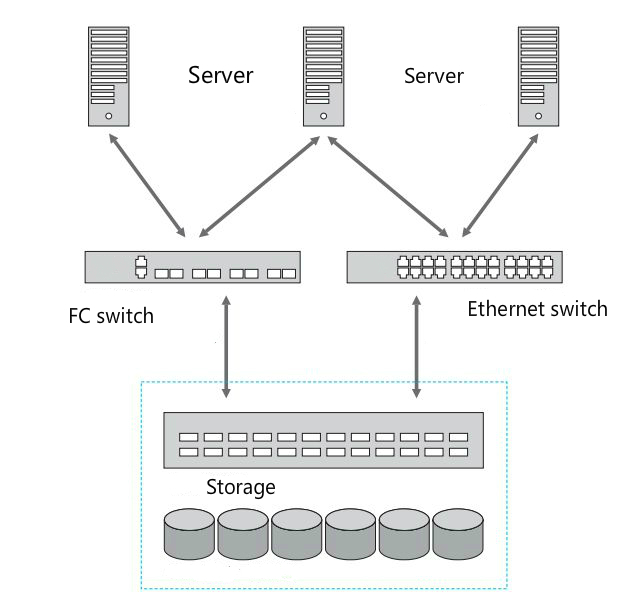
1、IP SAN 通常被认为比 FC SAN 成本更低、更易于管理。
2、FC SAN 需要特殊的硬件,如光纤交换机或主机总线适配器,而 IP SAN 只需要现有的以太网网络硬件。
3、FC SAN 是许多关键业务应用程序的理想存储平台。
4、IP SAN 是那些需要经济高效解决方案的组织的理想选择。
5、缺点 FC-SAN 和IP-SAN 其都是用的专业的存储设备,存储设备是集中在固定的几个存储服务器上的,这样的存储也称为集中式存储。集中式存储缺点也很明显,依赖专用的存储设备,无法快速的批量部署在普通服务器上。
3、 分布式存储
单块磁盘的性能是固定,如果我们能将数据分割成多块, 每块数据,选择一块硬盘去存储,这样在有N块硬件的条件下,理论上是可以达到N*单盘性能参数,这就是分布式存储的理论依据。而将存储功能和管理与硬件解耦,以软件的方式部署在普通服务器上,则是软件定义存储的思想。而软件定义存储是未来的存储的趋势。
分布式存储特点是将数据分散存储在多台计算机或服务器上的一种存储方式。它通过将数据划分为多个块,并将这些块分布存储在不同的节点上,实现了数据的并行处理和高可靠性。这种存储方式具有良好的扩展性、高吞吐量和可靠性,适用于处理大规模数据集。
Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)是一个开源的、高度可靠的分布式存储系统,被广泛应用于大数据领域。HDFS基于Google的GFS论文设计而来,旨在为大规模数据处理提供高效的存储解决方案。
HDFS的核心思想是将数据划分为多个块,并将这些块分布存储在集群中的多个节点上。每个块的默认大小为128MB,可以根据需要进行配置。这种划分方式使得数据可以在集群中并行处理,提高了数据处理的效率。
HDFS采用主从架构,包括一个主节点(NameNode)和多个从节点(DataNode)。NameNode负责管理文件系统的命名空间、记录文件的元数据信息(如文件名、文件目录结构、文件属性等),以及监控整个系统的状态。DataNode负责存储实际的数据块,并根据NameNode的指示完成数据的读写操作。

在ext系列的文件系统中,磁盘块被分为两部分数据区和元数据区,而文件在存储时,其inode信息就存放在元数据区。客户访问文件系统时,在文件系统树中表现应该一个路径如/usr/share/lib/file ,根据该路径的目录名去层层查找inode表,最后查找到file 文件对应的inode信息,而inode信息记录了当前数据块存放在哪些数据区。从这个角度来看元数据可以理解为是一张路由表,该表中记录我们怎么找到真正的数据存放位置。当然其也记录文件的属主、属组、权限等信息。在这样的一个分区或者磁盘中,如果我们想把一个大文件分成多个小文件,分散存储在多个节点上时,显示在这种数据和元数据在一起的架构上是无法实现的。
随之我们想到的是将元数据和数据分离,找一个单独的节点存放元数据,而将真正的数据,按一定大小分为固定的块,块分散的存放在不同的节点上。而让元数据去提供每个块数据的路由信息,例如当要存储一个256M大小的文件时,其先访问元数据节点,元数据节点按固定大小的块(如128M,则分为2块),每一块数据,当做一个独立的文件,然后进行路由和调度。从而完成所谓分散存储的目的。这样就能充分利用每一个存储节点的存储和网络能力,达到了分布式数据存储的效果。
当读数据时,也是先访问元数据节点,元数据节点记录了该文件被切了多少个文件块,块与块之间是如何偏移的,每个块是在哪个节点的哪个位置。通过这些信息组合,从而得到一个完整的文件信息,然后从各个数据节点并行读取所有分散的块,这也就达到了分布式读的效果。
而负责元数据服务的节点就称为NameNode ,而负责数据存放节点的称为DataNode.从上述描述中可以看到NameNode的角色是多么重要,如果宕机了,则文件都无法访问了,因此其需要高可用部署,其冗余的节点也称为 Secondary NameNode;
元数据是IO密集,但是IO量非常小的IO请求, 为了高效 ,一般都是在内存中的,还需要注意的是,磁盘IO的写一般都是随机的IO,随机写的IO是非常慢的,如何将一次随机的IO写变成有序的IO写请求呢?
我们可以像Mysql binlog 日志一样,不直接进行IO的写,而是记录写的操作,这样就是顺序写,这些写的操作就是binlog 日志,将来想要回滚时,只需要将日志回放即可。
可是即便是这样我们的元数据节点同时写操作也只能在一个NameNOde上进行,IO虽然小,但是在大量数据IO请求过来时,仍然有性能不足的风险。这种结构也称为有中心节点的分布式存储。其中心节点就是NameNode. 而Ceph是一个无中心节点的分布式存储,他们的最大差异点就在于此。
HDFS作为一个分布式存储,其具有分布式存储的所有特点;
-
高可靠性:HDFS通过数据冗余机制实现高可靠性。每个数据块默认会有三个副本,分别存储在不同的节点上,以防止单点故障对数据的影响。当某个节点失效时,系统会自动将其副本切换到其他健康的节点上,保证数据的可访问性。
-
高吞吐量:HDFS通过并行处理和数据本地性原则(Data Locality)来实现高吞吐量。数据本地性原则指的是尽可能地将计算任务调度到存储数据的节点上执行,减少数据传输开销。这种方式可以最大限度地利用集群的计算和存储资源,提高整体的处理效率。
-
扩展性:HDFS支持横向扩展,可以方便地增加新的节点来扩展存储容量和计算能力。当需要存储更多数据时,只需添加新的节点即可,而无需对已有的节点进行改动。
-
容错性:HDFS通过周期性地创建文件系统的快照(Snapshot)来实现容错性。快照是文件系统状态的一份拷贝,可以用于恢复数据或回滚到某个特定的时间点。当发生错误或数据损坏时,可以通过快照来恢复数据的完整性。
总之,HDFS是一个高度可靠、高扩展性和高吞吐量的分布式存储系统,它为大规模数据处理提供了一个稳定而高效的基础平台。在大数据领域中,HDFS被广泛应用于数据存储、数据管理和数据分析等方面,为用户提供强大的存储能力和数据处理能力。其与Ceph 都是分布式存储,两者最大的区别是Ceph是无中心节点的分布式存储。那Ceph是如何管理元数据的,我们在下一章将做详细介绍。


Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK